如何理解貪心演算法
我們先看一個例子
假設有一個可以容納100kg物品的背包,背包可以裝各種物品,我們有以下五種豆子,每種豆子的重量和總價值各不相同,為了讓背包中所裝物品的總價值最大,我們如何選擇在背包中裝哪些豆子?每種豆子又應該裝多少?
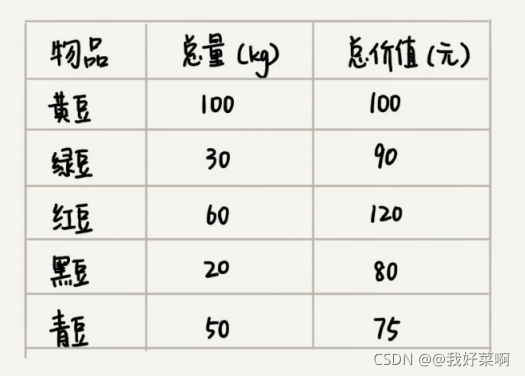
我們可以這樣想,我們只需要計算出每種豆子的單價,按照價格由高到低依次來裝豆子,先按單價最高的豆子裝,裝不滿的話,再裝價格相對較低的豆子,直到裝滿為止,
這個問題的解決思路就是用了貪心演算法的思想,我們先來看以下貪心演算法解決問題的步驟:
第一步:套用貪心演算法的問題模型:針對一組資料,事先定義了限制值和期望值,希望從中選擇幾個資料,在滿足限制的情況下,期望值最大,針對剛才的例子,限制值就是裝載背包中的豆子不能超過100kg,期望值就是裝在背包中的豆子的總價值,這組資料就是5種豆子,從中選出 一部分豆子,滿足重量不超過100kg,并且總價值最大,
第二步:嘗試用貪心演算法來解決:每次選擇對限制值同等貢獻量的情況下,對期望值貢獻最大的資料,針對剛才的例子,每次都從剩下的豆子里選擇單價最高的,也就是重量相同的情況下,對價值貢獻最大的豆子,
第三步:舉例驗證演算法是否正確:在大部分情況下,舉幾個例子驗證以下短發是否能得到最優解就可以了,
實際上,用貪心演算法解決問題,并不能給出最優解,
再來看一個例子,在一個有權圖中找一條從頂點S到頂點T的最短路徑(路徑中邊的權值最小),貪心演算法的解決思路:每次都選擇一條與當前頂點相連的權值最小的邊,也就是對總路徑長度貢獻最小的邊,直到找到頂點T,按照這種思路,我們求出的最短路徑是S->A->E->T,路徑長度是1+4+4 = 9,
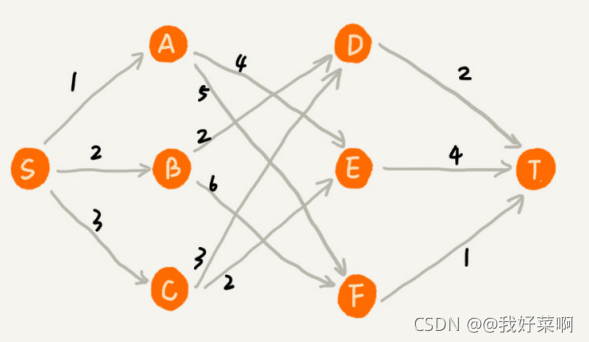
但是,基于這種貪心演算法,最終得到的路徑并非最短路徑,因為路徑S->B->D->T更短,長度為6,貪心演算法不能解決這個問題的主要原因是在貪心選擇程序中前面的選擇會影響后面的選擇,如果第一步從頂點S到頂點A,那么接下來面對的頂點和邊與第一步從頂點S到頂點B是完全不同的,因此,即便我們在第一步選擇最優的走法,也有可能因為這一步的選擇導致后面的每一步都很糟糕,
貪心演算法的應用示例
1.
分糖果
我們有 m 個糖果和 n 個孩子,我們現在要把糖果分給這些孩子吃,但是糖果少,孩子(m<n),所以糖果只能分配給一部分孩子,
每個糖果的大小不等,這 m 個糖果的大小分別是 s1,s2,s3,……,sm,除此之外,每個 孩子對糖果大小的需求也是不一樣的,只有糖果的大小大于等于孩子的對糖果大小的需求的 時候,孩子才得到滿足,假設這 n 個孩子對糖果大小的需求分別是 g1,g2,g3,……, gn,
我的問題是,如何分配糖果,能盡可能滿足最多數量的孩子?
我們可以把這個問題抽象成,從 n 個孩子中,抽取一部分孩子分配糖果,讓滿足的孩子的 個數(期望值)是最大的,這個問題的限制值就是糖果個數 m,
我們現在來看看如何用貪心演算法來解決,對于一個孩子來說,如果小的糖果可以滿足,我們 就沒必要用更大的糖果,這樣更大的就可以留給其他對糖果大小需求更大的孩子,另一方 面,對糖果大小需求小的孩子更容易被滿足,所以,我們可以從需求小的孩子開始分配糖 果,因為滿足一個需求大的孩子跟滿足一個需求小的孩子,對我們期望值的貢獻是一樣的,
我們每次從剩下的孩子中,找出對糖果大小需求最小的,然后發給他剩下的糖果中能滿足他 的最小的糖果,這樣得到的分配方案,也就是滿足的孩子個數最多的方案,
2.
錢幣找零
這個問題在我們的日常生活中更加普遍,假設我們有 1 元、2 元、5 元、10 元、20 元、 50 元、100 元這些面額的紙幣,它們的張數分別是 c1、c2、c5、c10、c20、c50、 c100,我們現在要用這些錢來支付 K 元,最少要用多少張紙幣呢?
在生活中,我們肯定是先用面值最大的來支付,如果不夠,就繼續用更小一點面值的,以此 類推,最后剩下的用 1 元來補齊,
在貢獻相同期望值(紙幣數目)的情況下,我們希望多貢獻點金額,這樣就可以讓紙幣數更 少,這就是一種貪心演算法的解決思路,直覺告訴我們,這種處理方法就是最好的,
3.
區間覆寫
假設我們有 n 個區間,區間的起始端點和結束端點分別是 [l1, r1],[l2, r2],[l3, r3], ……,[ln, rn],我們從這 n 個區間中選出一部磁區間,這部磁區間滿足兩兩不相交(端點相 交的情況不算相交),最多能選出多少個區間呢?
這個問題的處理思路稍微不是那么好懂,不過,我建議你最好能弄懂,因為這個處理思想在 很多貪心演算法問題中都有用到,比如任務調度、教師排課等等問題, 這個問題的解決思路是這樣的:我們假設這 n 個區間中最左端點是 lmin,最右端點是 rmax,這個問題就相當于,我們選擇幾個不相交的區間,從左到右將 [lmin, rmax] 覆寫 上,我們按照起始端點從小到大的順序對這 n 個區間排序,
我們每次選擇的時候,左端點跟前面的已經覆寫的區間不重合的,右端點又盡量小的,這樣 可以讓剩下的未覆寫區間盡可能的大,就可以放置更多的區間,這實際上就是一種貪心的選擇方法
如何用貪心演算法解決赫夫曼編碼
假設有一個包含1000個字符的檔案,每個字符占1B(1B = 8bit),存盤這1000個字符需要8000bit,那么有沒有更加節省空間的存盤方式呢?
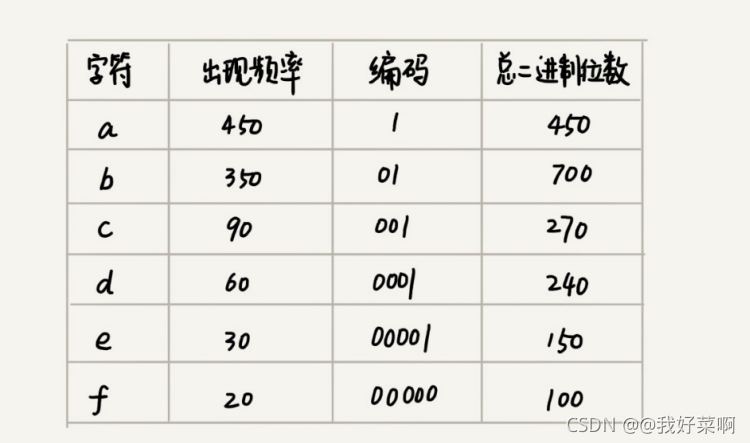
假設通過統計分析發現,這1000個字符中只包含六種不同的字符,假設分別是a,b,c,d,e,f,而三個二進制位(bit)就可以表示8個不同的字符,因此為了減少存盤空間,每個字符用三個二進制位來表示:a為000,b為001,c為010,d為011,e為100,f為101,那么,存盤這1000個字符只需要3000bit,比原來存盤方式節省了很多空間,還有沒有更加節省空間的方式呢?
此時就需要用到赫夫曼編碼了,他是一種非常有效的編碼方式,廣泛應用于資料壓縮中,其壓縮率通常為20%-90%,
霍夫曼編碼不僅會考察文本中有多少個不同字符,還會考察每個字符出現的頻率,根據頻率 的不同,選擇不同長度的編碼,霍夫曼編碼試圖用這種不等長的編碼方法,來進一步增加壓 縮的效率,如何給不同頻率的字符選擇不同長度的編碼呢?根據貪心的思想,我們可以把出 現頻率比較多的字符,用稍微短一些的編碼;出現頻率比較少的字符,用稍微長一些的編 碼.
對于等長的編碼來說,我們解壓縮起來很簡單,比如剛才那個例子中,我們用 3 個 bit 表 示一個字符,在解壓縮的時候,我們每次從文本中讀取 3 位二進制碼,然后翻譯成對應的 字符,但是,霍夫曼編碼是不等長的,每次應該讀取 1 位還是 2 位、3 位等等來解壓縮 呢?這個問題就導致霍夫曼編碼解壓縮起來比較復雜,為了避免解壓縮程序中的歧義,霍夫 曼編碼要求各個字符的編碼之間,不會出現某個編碼是另一個編碼前綴的情況,
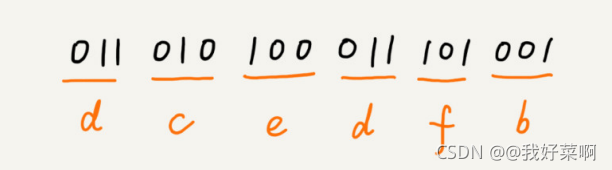
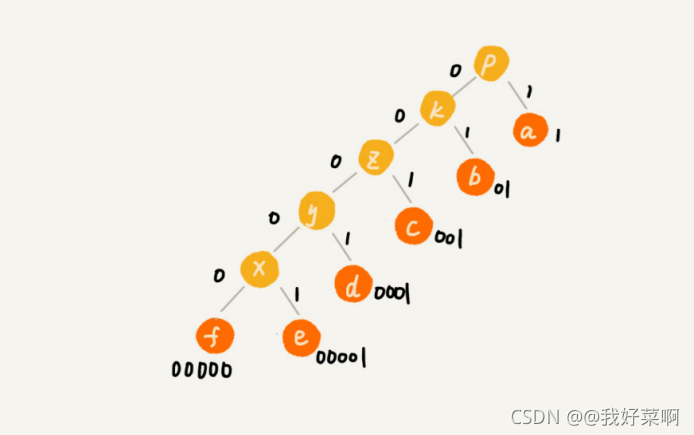
假設這 6 個字符出現的頻率從高到低依次是 a、b、c、d、e、f,我們把它們編碼下面這個 樣子,任何一個字符的編碼都不是另一個的前綴,在解壓縮的時候,我們每次會讀取盡可能 長的可解壓的二進制串,所以在解壓縮的時候也不會歧義,經過這種編碼壓縮之后,這 1000 個字符只需要 2100bits 就可以了
盡管霍夫曼編碼的思想并不難理解,但是如何根據字符出現頻率的不同,給不同的字符進行 不同長度的編碼呢?這里的處理稍微有些技巧,
我們把每個字符看作一個節點,并且輔帶著把頻率放到優先級佇列中,我們從佇列中取出頻 率最小的兩個節點 A、B,然后新建一個節點 C,把頻率設定為兩個節點的頻率之和,并把 這個新節點 C 作為節點 A、B 的父節點,最后再把 C 節點放入到優先級佇列中,重復這個 程序,直到佇列中沒有資料,
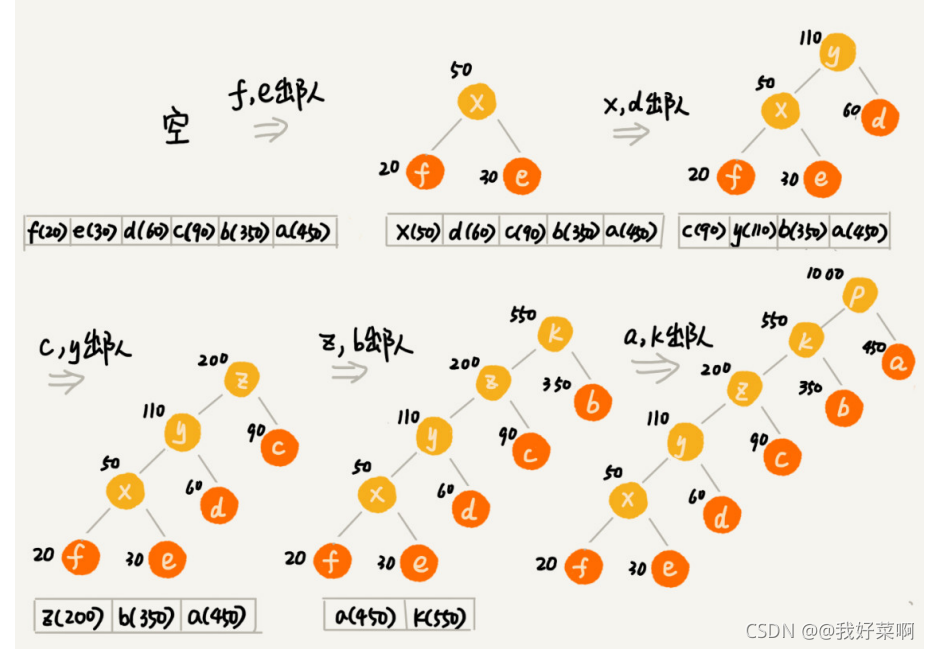
現在,我們給每一條邊加上畫一個權值,指向左子節點的邊我們統統標記為 0,指向右子節 點的邊,我們統統標記為 1,那從根節點到葉節點的路徑就是葉節點對應字符的霍夫曼編 碼