文章目錄
- 前言
- 一、卷積和核(Convolution and Kernels)
- 1.什么是卷積
- 2.什么是核
- 二、卷積層與全連接層的共同點
- 1.全連接層(Fully-connection)
- 2.卷積層1×1
- 三、U-Net
- 1.反卷積
- 2.U-Net結構
- 四、U-Net實戰(Pytorch)
- 1.專案描述
- 2.搭建U-Net
- 2.1卷積層
- 2.2上采樣層
- 2.3完成U-Net結構搭建
- 3.資料集定義
- 4.訓練
- 5.預測
- 參考鏈接
前言
因為畢設需要針對遙感影像進行語意分割,在這里記錄一下自己學習的心路歷程,
提示:以下是本篇文章正文內容,下面案例可供參考
一、卷積和核(Convolution and Kernels)
1.什么是卷積
??卷積和加法、乘法一樣,只是一種數學運算,選擇不同的內核,如“銳化”、“邊緣檢測”、“濾波”等,通過內核與原影像進行卷積,便能實作相應的功能,
??例如,讓我們找下圖A的輪廓(邊緣),

??給出一個內核如下:
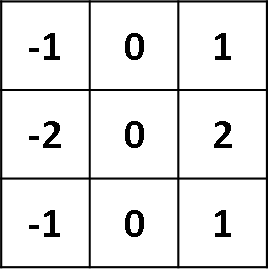
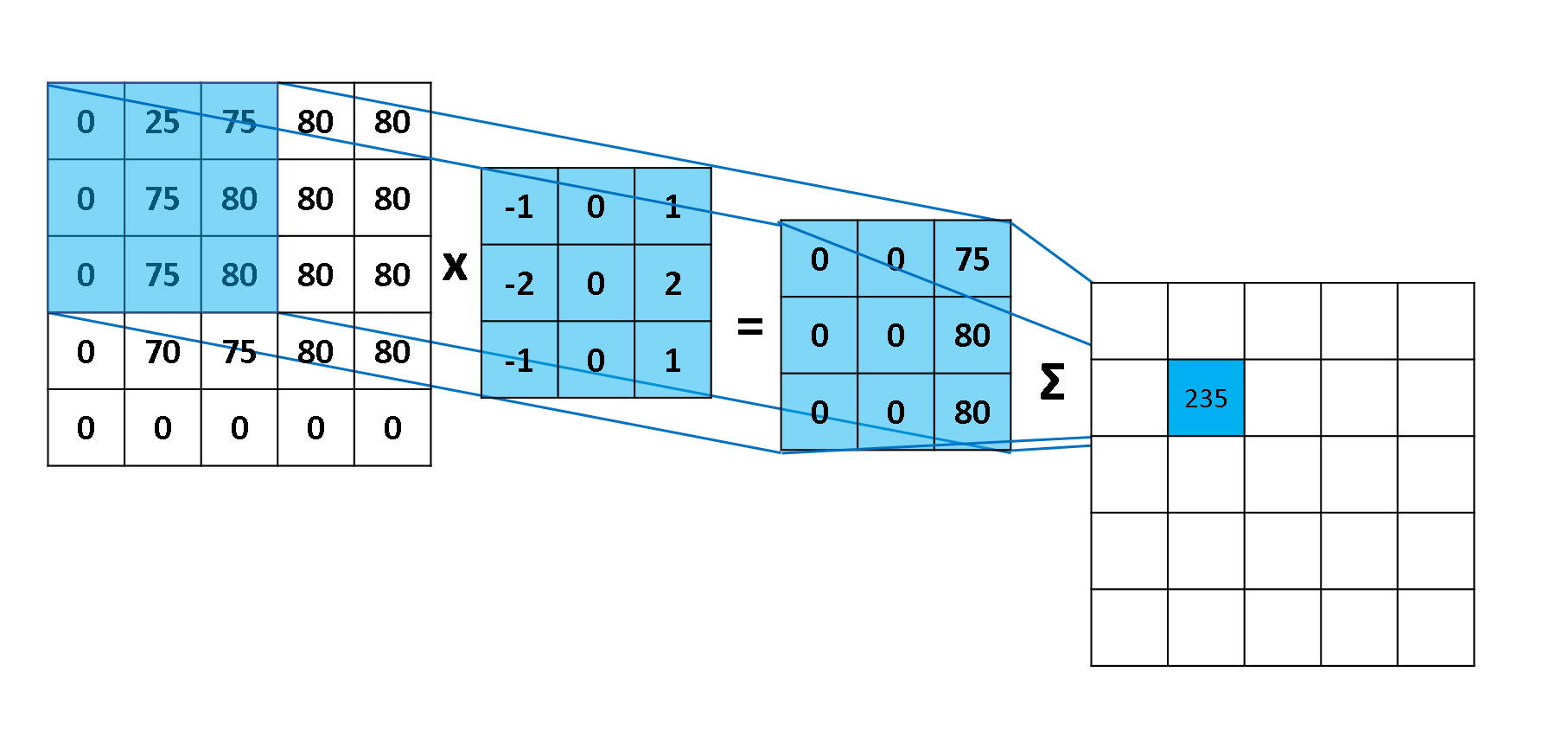
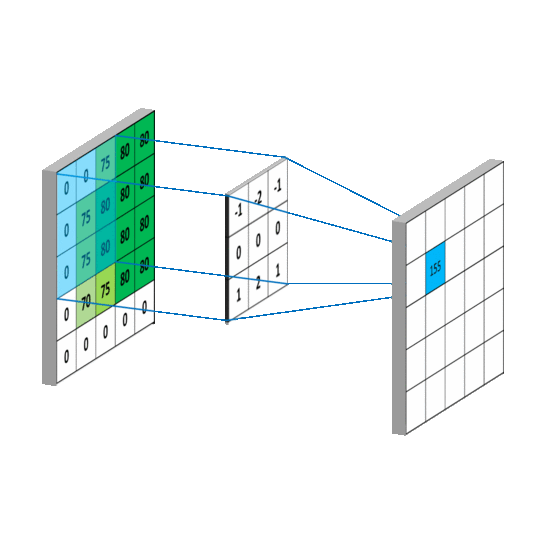
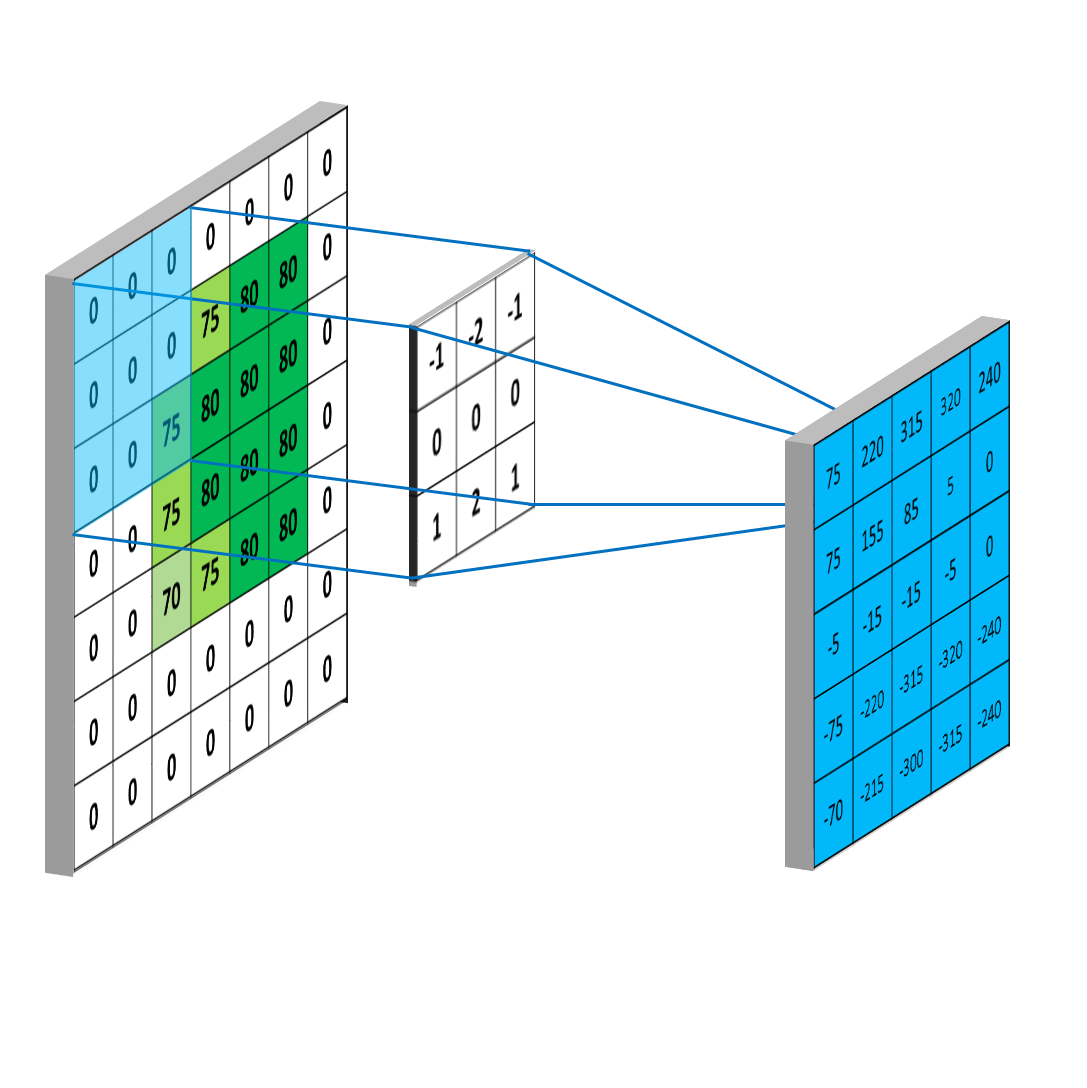

2.什么是核
??感謝前人的大量研究,我們有了很多功能明確的核,例如上文的Vertical Sobel,可以提取影像的垂直資訊,但是我們應該思考兩個問題:
??①我們并不知道需要用到怎樣的核;
??②假設你知道需要怎樣功能的核,但并不是所有我們需要的核都被明確的開發出來了
??因此,核中的值應該是被當做引數,通過誤差反向傳播、優化“學”出來的,就和簡單的神經網路一樣,
??具體怎么理解呢?
??首先,我們應該有這么一個認識:一個8×8的影像,一共有64個像素點,每個像素點的值都是它的一個特征,也就是輸入的一個節點,通過卷積,結果會被放入到另一些節點,即隱藏節點,而核中的每個值對應著輸入節點與隱藏節點的聯系,即權重,這些權重以與普通神經網路完全相同的方式學習:首先隨機初始化核值,將卷積后的結果與實際輸出進行比較(然后對其進行誤差反向傳播和優化),最終迭代出新的核值,如果輸入影像是二維的(即單通道),那么針對某一個功能的核(例如下圖的綠色核)也是二維的,當你想提取四類特征時候,就應該采用4個二維核: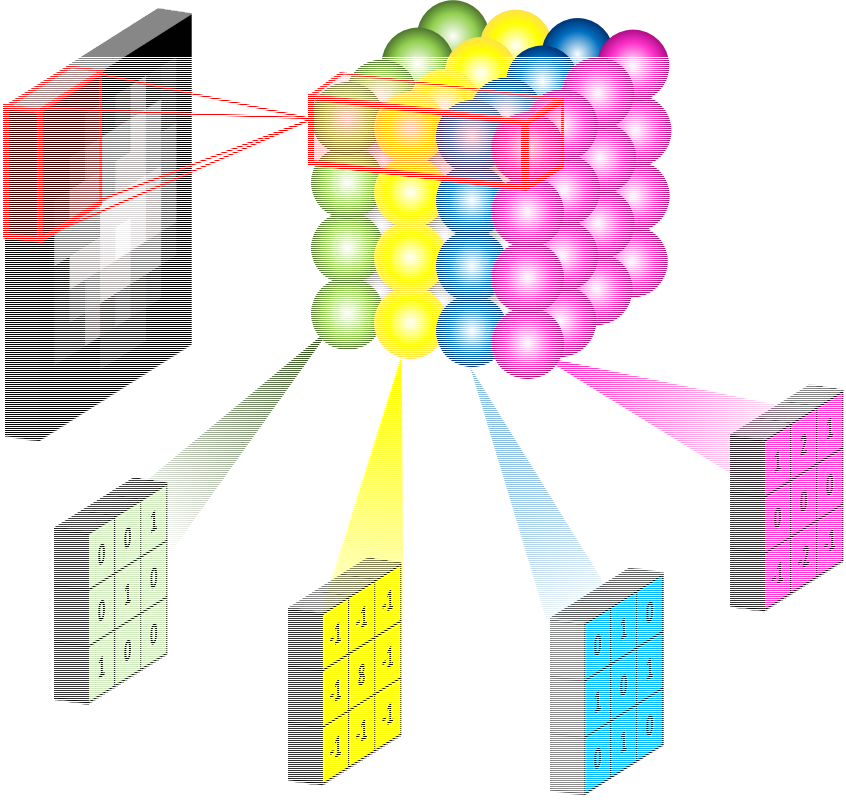
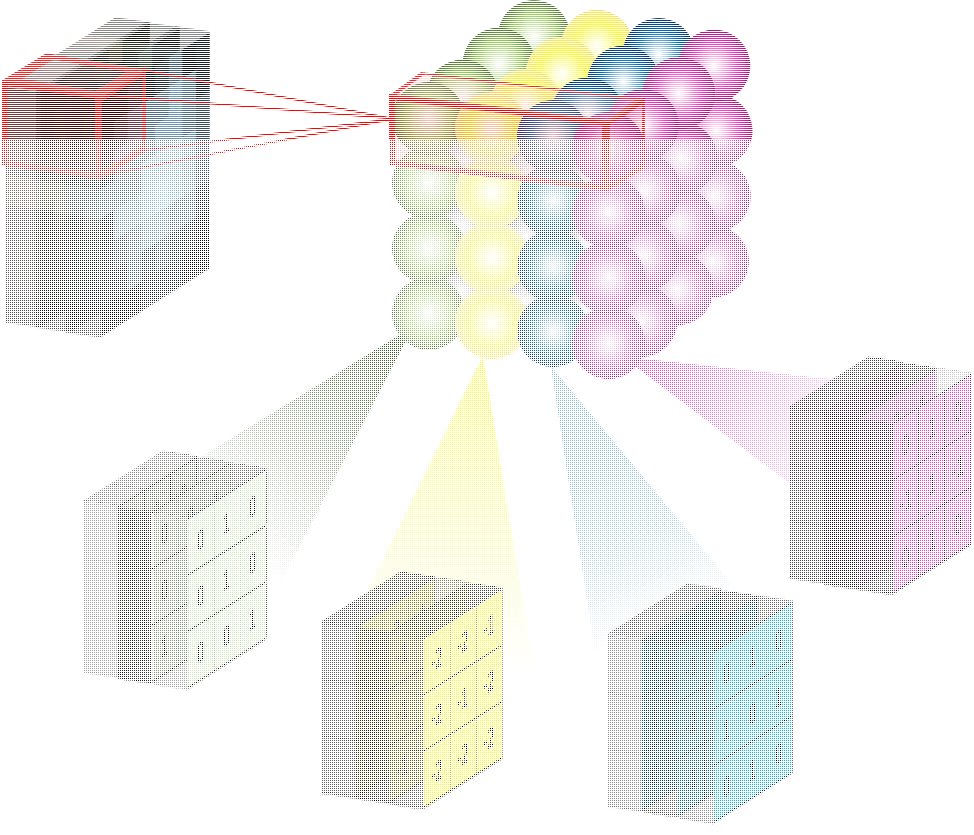
二、卷積層與全連接層的共同點
??在一個識別X與O的任務中,我們輸入一張影像,經過一系列卷積層、池化層后,得到了3×2×2的特征圖:
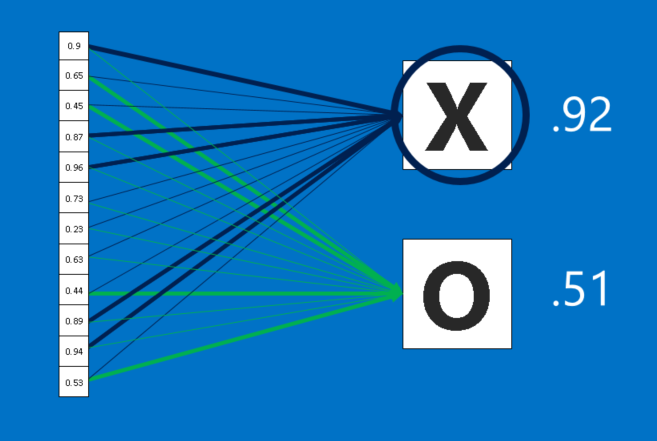
1.全連接層(Fully-connection)
??全連接層所扮演的角色是主要建構單元,當我們向這個單元輸入圖片時,它會將所有像素的值當成一個一維清單,而不是前面的二維矩陣,清單里的每個值都可以決定圖片中的符號是O還是X,不過這場選舉并不全然民主,由于某些值可以更好地判別叉,有些則更適合用來判斷圈,這些值可以投的票數會比其他值還多,所有值對不同選項所投下的票數,將會以權重(weight)的方式來表示,下圖連接線的不同粗細代表權重的高低,
2.卷積層1×1
?? 全連接層的結果是輸入影像歸屬某類的強度,但很多時候我們需要得到的是輸入影像中各個像素歸屬某類的強度,此時可以用1×1的卷積層來等價代替全連接層,
??下圖展示了1×1卷積核的計算,輸出中的每個元素來自輸入中在高和寬上相同位置的元素在不同通道間的按權重累加,這與上文的卷積運算相同,假設我們將通道維當作特征維,每個像素位置當成一個資料樣本,那么一個樣本是1×3,共有9個樣本,輸入為9×3,于是下圖實際上是9個全連接層的組合,每組樣本與核的卷積輸出就相當于一個全連接層輸出,下圖的兩個通道維對應著兩個輸出類別,
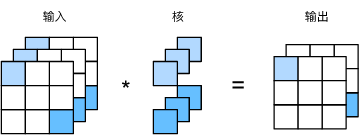
三、U-Net
1.反卷積
?? 經過上面的學習我們知道,卷積會導致尺寸變小,為了使得輸入輸出影像有相同的尺寸,我們會填充原影像(padding),
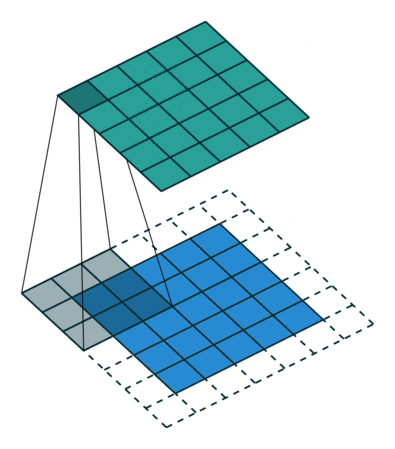
2.U-Net結構
U-Net: Convolutional Networks for Biomedical Image Segmentation
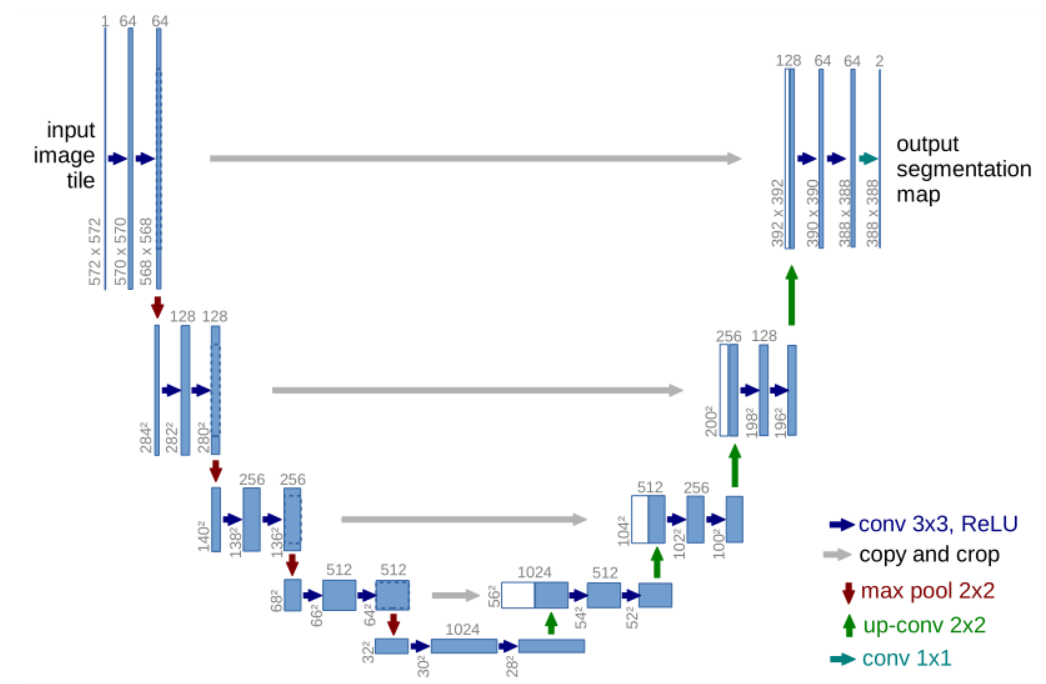
??U形的結構非常簡潔優雅,灰色的箭頭是Skip Connection,是將不同深度的下采樣層的輸出裁剪后與同深度的上采樣層的輸入疊加,疊加結果為通道數加倍,目的在于保留下采樣中部分損失的特征資訊,綠色的箭頭是反卷積,產生的結果是通道數減半但尺寸加倍,最后一層采用了1×1卷積層,目的是二分類,
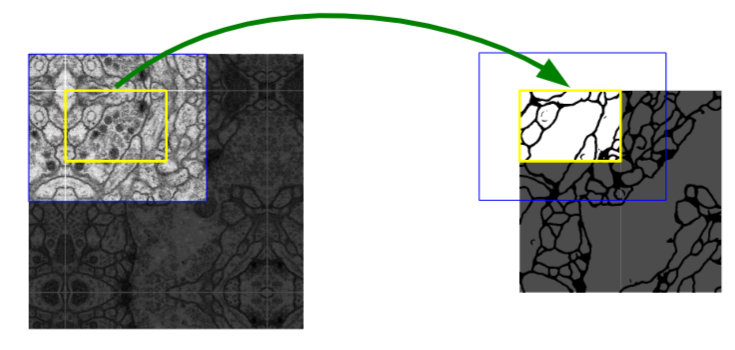
??為什么最終輸出圖片尺寸與輸入圖片尺寸不同呢?原論文中首先對資料進行了鏡像填充,可以減少有效資料的損失,此外,有些影像尺寸較大(如遙感影像),需要分塊輸入,之后再拼接結果,這樣做還可以避免拼接程序中邊緣部分不連接問題,
??為什么是四層深網路,而不是五層、六層,網路越深精度會越高嗎?針對不同的訓練資料,會有不同的最佳網路深度,網路過深會出現“退化”現象,即隨著網路層數變多,訓練誤差反而降低了,
強烈推薦閱讀:研習U-Net
四、U-Net實戰(Pytorch)
1.專案描述
??復現原論文中的醫學影像分割實驗,共有30張原始影像,解析度為512×512,
2.搭建U-Net
??根據U-Net的結構,首先重現卷積池化層與上采樣層,最后再在Unet中按順序連接起來,
2.1卷積層
??匯入模塊,實作卷積層
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchsummary import summary
#1.模型搭建
#***資料tensor是四維的(N,C,H,W)
#①卷積層
class Unetconv(nn.Module):
def __init__(self,in_channels,out_channels):
super(Unetconv,self).__init__()
self.conv1=nn.Sequential(
nn.Conv2d(in_channels,out_channels,kernel_size=3,stride=1,padding=0),
nn.ReLU(inplace=True),#inplace=True,節省記憶體開銷
)
self.conv2=nn.Sequential(
nn.Conv2d(out_channels,out_channels,kernel_size=3,stride=1,padding=0),
nn.ReLU(inplace=True),
)
def forward(self,X):
X=self.conv1(X)
outputs=self.conv2(X)
return outputs
2.2上采樣層
??Attention 1:在最后一行的torch.cat()中,我們需要資料在通道維進行疊加,而網路中的資料是四維的,(批大小,通道數,高,寬),dim=0時按批疊加,dim=1時按通道數疊加,大家可以動手實作下面這個例子來加深理解,
x=torch.randn(1,2,3)
print("x.shape:",x.shape)
print("dim1.shape:",torch.cat((x,x),dim=1).shape)
print("dim2.shape:",torch.cat((x,x),dim=2).shape)
輸出:
x.shape: torch.Size([1, 2, 3])
dim1.shape: torch.Size([1, 4, 3])
dim2.shape: torch.Size([1, 2, 6])
??Attention 2:反卷積層的輸出通道數為in_channels//2(//為向下取整除法),但進入卷積層的張量是torch.cat()后的,因此Unetconv的輸入通道數是in_channels.
??Attention 3:torch.cat()要求待疊加張量在除疊加維度外的其他維相同,例如按通道維疊加,那么另外三個維度應該完全相同(批大小、高、寬),批大小是人為給定一定相同,高和寬是不同的,因此需要對高、寬進行裁剪(crop),也就是U-Net結構中的copy and crop,pad=[左,右,上,下],陣列中的數大于0為填充,小于0為裁剪,例如“左=-2”則原影像裁剪兩列,詳細見:functional.pad()說明檔案
#②上采樣層
class upconv(nn.Module):
def __init__(self,in_channels, out_channels):
super(upconv,self).__init__()
self.conv=Unetconv(in_channels, out_channels)
#①反卷積
self.upconv1=nn.ConvTranspose2d(in_channels, in_channels//2, kernel_size=2, stride=2)
#②skip connection,資料合并
def forward(self,inputs_R,inputs_U):
#self,x2,x1
outputs_U=self.upconv1(inputs_U)
offset=outputs_U.size()[-1]-inputs_R.size()[-1]
pad=[offset//2,offset-offset//2,offset//2,offset-offset//2] # 2*[1,1]=[1,1,1,1]
outputs_R=F.pad(inputs_R,pad)
#這里教程寫的dim=1,但torch(c,h,w),我覺得dim=0的時候才是通道相加
#tensor是四維的,所以dim=1,即按三維拼接
return self.conv(torch.cat((outputs_U,outputs_R),dim=1))
2.3完成U-Net結構搭建
??在最后的1×1卷積層中,為了使得輸出結果與原始影像有相同尺寸,使用了Upsample層,這并不是最好的辦法,
#③完成U-net構建
#in_channels:圖片維度
#n_classes:最終分類數
class Unet(nn.Module):
def __init__(self,in_channels=3,n_classes=1):
super(Unet,self).__init__()
self.in_channels=in_channels
filters=[64,128,256,512,1024]
#下采樣
self.conv1=Unetconv(self.in_channels,filters[0])
self.maxpool1=nn.MaxPool2d(kernel_size=2)
self.conv2=Unetconv(filters[0],filters[1])
self.maxpool2=nn.MaxPool2d(kernel_size=2)
self.conv3=Unetconv(filters[1],filters[2])
self.maxpool3=nn.MaxPool2d(kernel_size=2)
self.conv4=Unetconv(filters[2],filters[3])
self.maxpool4=nn.MaxPool2d(kernel_size=2)
self.center=Unetconv(filters[3],filters[4])
#上采樣
self.upnet4=upconv(filters[4],filters[3])
self.upnet3=upconv(filters[3],filters[2])
self.upnet2=upconv(filters[2],filters[1])
self.upnet1=upconv(filters[1],filters[0])
#
self.final=nn.Sequential(
nn.Conv2d(filters[0],n_classes,kernel_size=1),
######為了使得輸出與label同尺寸,這里加入了一個Upsample層,但為什么是2D而不是4D呢?
nn.Upsample(size=(512, 512)),
)
def forward(self,inputs):
#下
conv1=self.conv1(inputs)
maxpool1=self.maxpool1(conv1)
conv2=self.conv2(maxpool1)
maxpool2=self.maxpool2(conv2)
conv3=self.conv3(maxpool2)
maxpool3=self.maxpool3(conv3)
conv4=self.conv4(maxpool3)
downputs=self.maxpool4(conv4)
centerputs=self.center(downputs)
#上
up4=self.upnet4(conv4,centerputs)
up3=self.upnet3(conv3,up4)
up2=self.upnet2(conv2,up3)
up1=self.upnet1(conv1,up2)
#1×1
final=self.final(up1)
return final
3.資料集定義
??Pytorch提供了自定義資料集的框架,我們需要重構dataset,然后用dataloader讀取,框架如下:
??對Dataloader感興趣的話推薦看一下這個:Dataloader講解-Miracle8070
# ================================================================== #
# Input pipeline for custom dataset #
# ================================================================== #
# You should build your custom dataset as below.
class CustomDataset(torch.utils.data.Dataset):
def __init__(self):
# TODO
# 1. Initialize file paths or a list of file names.
pass
def __getitem__(self, index):
# TODO
# 1. Read one data from file (e.g. using numpy.fromfile, PIL.Image.open).
# 2. Preprocess the data (e.g. torchvision.Transform).
# 3. Return a data pair (e.g. image and label).
pass
def __len__(self):
# You should change 0 to the total size of your dataset.
return 0
# You can then use the prebuilt data loader.
custom_dataset = CustomDataset()
train_loader = torch.utils.data.DataLoader(dataset=custom_dataset,
batch_size=64,
shuffle=True)
??于是我們自定義資料集如下,我的理解是:在__init__()中得到一個串列,這個串列中的每個元素是一個圖片的路徑,即[圖片路徑1,圖片路徑2,…],在__getitem__(index)中,用index來挨個讀取某一個圖片路徑,從而能得到一張圖片資料,及其對應標簽資料,再return即可,
from torch.utils.data import Dataset
from matplotlib import pyplot as plt
import os
import glob
import cv2
import random
class MyDataset(Dataset):
def __init__(self,data_dir,transform=None):
# TODO
# 1. Initialize file paths or a list of file names.
self.data_dir=data_dir
#img_dir為圖片路徑串列
self.img_dir=glob.glob(os.path.join(data_dir,'image/*.png'))
def __getitem__(self, index):
# TODO
# 1. Read one data from file (e.g. using numpy.fromfile, PIL.Image.open).
# 2. Preprocess the data (e.g. torchvision.Transform).
# 3. Return a data pair (e.g. image and label).
#先傳入圖片的路徑串列
img_path=self.img_dir[index]
#修改后得到了對應標簽的路徑串列
label_path=img_path.replace('image','label')
#得到圖片和標簽資料
image = cv2.imread(img_path)
label = cv2.imread(label_path)
#資料轉換為單通道
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
label = cv2.cvtColor(label, cv2.COLOR_BGR2GRAY)
image = image.reshape(1, image.shape[0], image.shape[1])
label = label.reshape(1, label.shape[0], label.shape[1])
#把標簽從[0,255]變到[0,1]
if label.max()>1:
label=label/255
flipCode = random.choice([-1, 0, 1, 2])
if flipCode != 2:
## 使用cv2.flip進行資料增強,filpCode為1水平翻轉,0垂直翻轉,-1水平+垂直翻轉
image = cv2.flip(image, flipCode)
label=cv2.flip(label,flipCode)
return image,label
def __len__(self):
# You should change 0 to the total size of your dataset.
return len(self.img_dir)
4.訓練
??損失函式采用了論文中的交叉熵損失函式,優化演算法采用了RMSprop,訓練中保存了best_model.pth,它是loss最小時保存的模型引數,并不是最后一次迭代的模型引數,
from torch import optim
def train_net(net, device, data_path, epochs=10, batch_size=15, lr=0.001):
# 加載訓練集
isbi_dataset = MyDataset(data_path)
train_loader = torch.utils.data.DataLoader(dataset=isbi_dataset,
batch_size=batch_size,
shuffle=True)
# 定義RMSprop演算法
optimizer = optim.RMSprop(net.parameters(), lr=lr, weight_decay=1e-8, momentum=0.9)
# 定義Loss演算法
criterion = nn.BCEWithLogitsLoss()
# best_loss統計,初始化為正無窮
best_loss = float('inf')
# 訓練epochs次
for epoch in range(epochs):
# 訓練模式
net.train()
# 按照batch_size開始訓練
for image, label in train_loader:
optimizer.zero_grad()
# 將資料拷貝到device中
image = image.to(device=device, dtype=torch.float32)
label = label.to(device=device, dtype=torch.float32)
# 使用網路引數,輸出預測結果
pred = net(image)
# 計算loss
loss = criterion(pred, label)
print('Loss/train', loss.item())
# 保存loss值最小的網路引數
if loss < best_loss:
best_loss = loss
torch.save(net.state_dict(), 'best_model.pth')
# 更新引數
loss.backward()
optimizer.step()
print("訓練結束")
5.預測
# 選擇設備,有cuda用cuda,沒有就用cpu
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 加載網路,圖片單通道1,分類為1,
net = Unet(in_channels=1, n_classes=1)
# 將網路拷貝到deivce中
net.to(device=device)
# 指定訓練集地址,開始訓練
data_path = "C:/Users/tc/Desktop/lesson-2/data/train/"
train_net(net, device, data_path)
參考鏈接
How do Convolutional Neural Networks work?
Dive into Pytorch
Convolutional Neural Networks - Basics
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/337582.html
標籤:AI
上一篇:如何同時執行djangorunserver和python腳本(在cmd中的一行)
下一篇:LSTM詳解