LSTM詳解
文章目錄
- LSTM詳解
- 改進
- 記憶單元
- 門控機制
- LSTM結構
- LSTM的計算程序
- 遺忘門
- 輸入門
- 更新記憶單元
- 輸出門
- LSTM單元的pytorch實作
- Pytorch中的LSTM
- 引數
- 輸入
- 輸出
- 參考與摘錄
LSTM是RNN的一種變種,可以有效地解決RNN的梯度爆炸或者消失問題,關于RNN可以參考作者的另一篇文章https://blog.csdn.net/qq_40922271/article/details/120965322
LSTM的改進在于增加了新的記憶單元與門控機制
改進
記憶單元
LSTM進入了一個新的記憶單元 c t c_t ct?,用于進行線性的回圈資訊傳遞,同時輸出資訊給隱藏層的外部狀態 h t h_t ht?,在每個時刻 t t t, c t c_t ct?記錄了到當前時刻為止的歷史資訊,
門控機制
LSTM引入門控機制來控制資訊傳遞的路徑,類似于數字電路中的門,0即關閉,1即開啟,
LSTM中的三個門為遺忘門 f t f_t ft?,輸入門 i t i_t it?和輸出門 o t o_t ot?
- f t f_t ft?控制上一個時刻的記憶單元 c t ? 1 c_{t-1} ct?1?需要遺忘多少資訊
- i t i_t it?控制當前時刻的候選狀態 c ~ t \tilde{c}_t c~t?有多少資訊需要存盤
- o t o_t ot?控制當前時刻的記憶單元 c t c_t ct?有多少資訊需要輸出給外部狀態 h t h_t ht?
下面我們就看看改進的新內容在LSTM的結構中是如何體現的,
LSTM結構
如圖一所示為LSTM的結構,LSTM網路由一個個的LSTM單元連接而成,
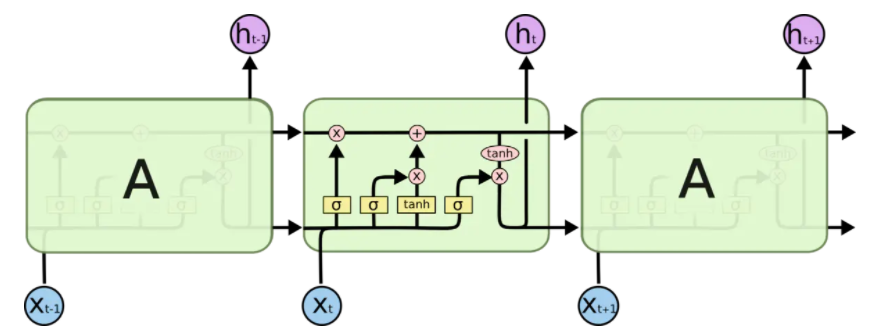
圖二描述了圖一中各種元素的圖示,從左到右分別為,神經網路( σ 表 示 s i g m o i d \sigma表示sigmoid σ表示sigmoid)、向量元素操作( × \times ×表示向量元素乘, + + +表示向量加),向量傳輸的方向、向量連接、向量復制

LSTM 的關鍵就是記憶單元,水平線在圖上方貫穿運行,
記憶單元類似于傳送帶,直接在整個鏈上運行,只有一些少量的線性互動,資訊在上面流傳保持不變會很容易,
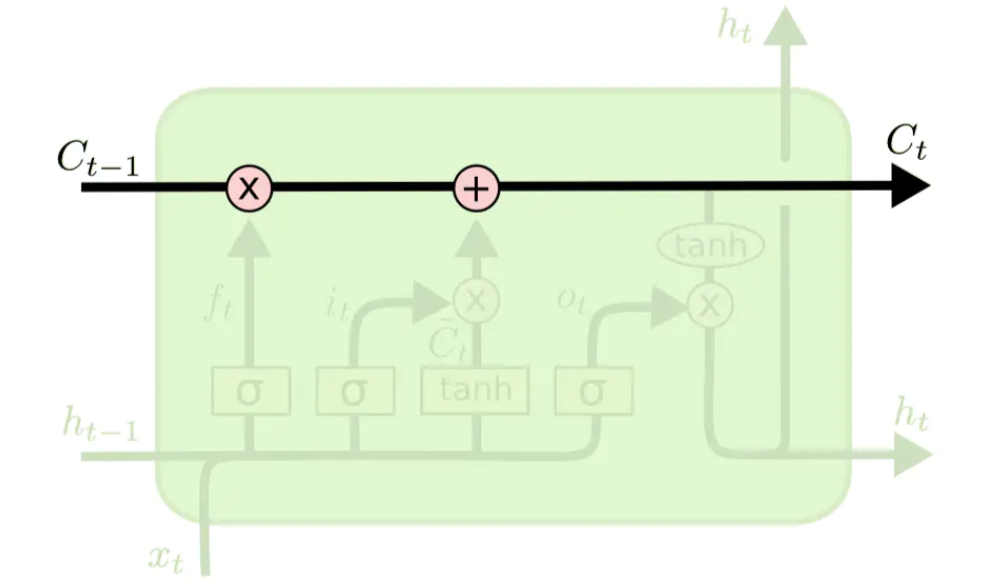
LSTM的計算程序
遺忘門
在這一步中,遺忘門讀取 h t ? 1 h_{t-1} ht?1?和 x t x_t xt?,經由sigmoid,輸入一個在0到1之間數值給每個在記憶單元 c t ? 1 c_{t-1} ct?1?中的數字,1表示完全保留,0表示完全舍棄,
輸入門
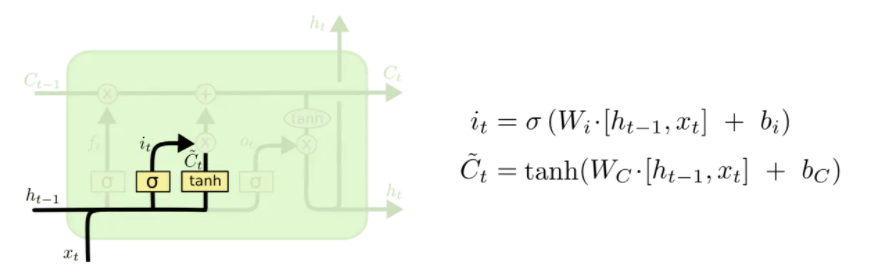
輸入門將確定什么樣的資訊記憶體放在記憶單元中,這里包含兩個部分,
- sigmoid層同樣輸出[0,1]的數值,決定候選狀態 c ~ t \tilde{c}_t c~t?有多少資訊需要存盤
- tanh層會創建候選狀態 c ~ t \tilde{c}_t c~t?
更新記憶單元
隨后更新舊的細胞狀態,將 c t ? 1 c_{t-1} ct?1?更新為 c t c_t ct?
首先將舊狀態 c t ? 1 c_{t-1} ct?1?與 f t f_t ft?相乘,遺忘掉由 f t f_t ft?所確定的需要遺忘的資訊,然后加上 i t ? c ~ t i_t*\tilde{c}_t it??c~t?,由此得到了新的記憶單元 c t c_t ct?
輸出門
結合輸出門 o t o_t ot?將內部狀態的資訊傳遞給外部狀態 h t h_t ht?,同樣傳遞給外部狀態的資訊也是個過濾后的資訊,首先sigmoid層確定記憶單元的那些資訊被傳遞出去,然后,把細胞狀態通過 tanh層 進行處理(得到[-1,1]的值)并將它和輸出門的輸出相乘,最終外部狀態僅僅會得到輸出門確定輸出的那部分,
通過LSTM回圈單元,整個網路可以建立較長距離的時序依賴關系,以上公式可以簡潔地描述為
[ c ~ t o t i t f t ] = [ t a n h σ σ σ ] ( W [ x t h t ? 1 ] + b ) \begin{bmatrix} \tilde{c}_t \\ o_t \\ i_t \\ f_t \end{bmatrix} = \begin{bmatrix} tanh \\ \sigma \\ \sigma \\ \sigma \end{bmatrix} \begin{pmatrix} W \begin{bmatrix} x_t \\ h_{t-1} \end{bmatrix} +b \end{pmatrix} ?????c~t?ot?it?ft???????=?????tanhσσσ??????(W[xt?ht?1??]+b?)
c t = f t ⊙ c t ? 1 + i t ⊙ c ~ t c_t=f_t \odot c_{t-1}+i_t \odot \tilde{c}_t ct?=ft?⊙ct?1?+it?⊙c~t?
h t = o t ⊙ t a n h ( c t ) h_t=o_t \odot tanh(c_t) ht?=ot?⊙tanh(ct?)
LSTM單元的pytorch實作
下面通過手寫LSTM單元加深對LSTM網路的理解
class LSTMCell(nn.Module):
def __init__(self, input_size, hidden_size, cell_size, output_size):
super().__init__()
self.hidden_size = hidden_size # 隱含狀態h的大小,也即LSTM單元隱含層神經元數量
self.cell_size = cell_size # 記憶單元c的大小
# 門
self.gate = nn.Linear(input_size+hidden_size, cell_size)
self.output = nn.Linear(hidden_size, output_size)
self.sigmoid = nn.Sigmoid()
self.tanh = nn.Tanh()
self.softmax = nn.LogSoftmax(dim=1)
def forward(self, input, hidden, cell):
# 連接輸入x與h
combined = torch.cat((input, hidden), 1)
# 遺忘門
f_gate = self.sigmoid(self.gate(combined))
# 輸入門
i_gate = self.sigmoid(self.gate(combined))
z_state = self.tanh(self.gate(combined))
# 輸出門
o_gate = self.sigmoid(self.gate(combined))
# 更新記憶單元
cell = torch.add(torch.mul(cell, f_gate), torch.mul(z_state, i_gate))
# 更新隱藏狀態h
hidden = torch.mul(self.tanh(cell), o_gate)
output = self.output(hidden)
output = self.softmax(output)
return output, hidden, cell
def initHidden(self):
return torch.zeros(1, self.hidden_size)
def initCell(self):
return torch.zeros(1, self.cell_size)
Pytorch中的LSTM
CLASS torch.nn.LSTM(*args, **kwargs)
引數
- input_size – 輸入特征維數
- hidden_size – 隱含狀態 h h h的維數
- num_layers – RNN層的個數:(在豎直方向堆疊的多個相同個數單元的層數),默認為1
- bias – 隱層狀態是否帶bias,默認為true
- batch_first – 是否輸入輸出的第一維為batchsize
- dropout – 是否在除最后一個RNN層外的RNN層后面加dropout層
- bidirectional –是否是雙向RNN,默認為false
- proj_size – If
> 0, will use LSTM with projections of corresponding size. Default: 0
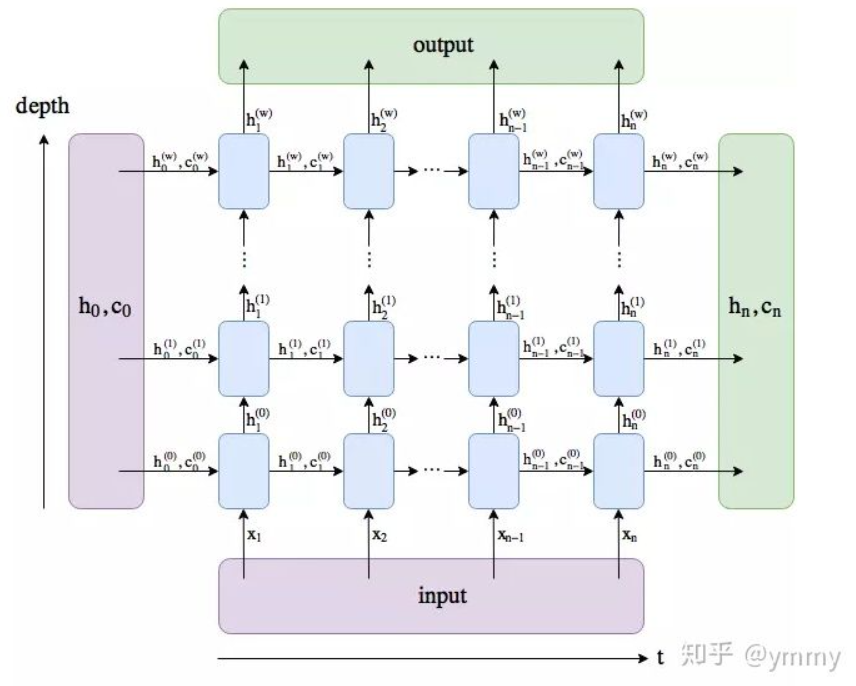
其中比較重要的引數就是hidden_size與num_layers,hidden_size所代表的就是LSTM單元中神經元的個數,從知乎截來的一張圖,通過下面這張圖我們可以看出num_layers所代表的含義,就是depth的堆疊,也就是有幾層的隱含層,可以看到output是最后一層layer的hidden輸出的組合
輸入
input, (h_0, c_0)
- input: (seq_len, batch, input_size) 時間步數或序列長度,batch數,輸入特征維度,如果設定了batch_first,則batch為第一維
- h_0: shape(num_layers * num_directions, batch, hidden_size) containing the initial hidden state for each element in the batch. Defaults to zeros if (h_0, c_0) is not provided.
- c_0: **shape(num_layers * num_directions, batch, hidden_size)**containing the initial cell state for each element in the batch. Defaults to zeros if (h_0, c_0) is not provided.
輸出
output, (h_n, c_n)
- output: (seq_len, batch, hidden_size * num_directions) 包含每一個時刻的輸出特征,如果設定了batch_first,則batch為第一維
- h_n: shape(num_layers * num_directions, batch, hidden_size) containing the final hidden state for each element in the batch.
- c_n: shape (num_layers * num_directions, batch, hidden_size) containing the final cell state for each element in the batch.
h與c維度中的num_direction,如果是單向回圈網路,則num_directions=1,雙向則num_directions=2
參考與摘錄
https://blog.csdn.net/qq_40728805/article/details/103959254
https://zhuanlan.zhihu.com/p/79064602
https://www.jianshu.com/p/9dc9f41f0b29
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/337583.html
標籤:AI