多元線性回歸演算法預測房價
- 一、理論學習
- (一)背景
- (二)線性回歸檢驗
- 二、資料清洗
- (一)數值資料處理
- (二)非數值型資料轉換
- 三、Excel多元線性回歸
- 四、多元線性回歸模型預測房價
- (一)基礎包與資料匯入
- (二)變數探索
- (三)分析資料
- (四)擬合
- 四、sklearn多元線性回歸預測房價
- (一)不進行資料處理
- (二)對資料進行清洗后再求解
- 五、總結
- 六、參考資料
一、理論學習
學習參考資料“多元線性回歸模型預測房價.ipynb”,自己實踐重新做一下針對房屋資料集“house_prices.csv”的多元線性回歸(基于統計分析庫statsmodels);并重點理解偏差資料、缺少資料的預處理(資料清洗)、“特征共線性”的檢測方法以及統計學的傳統估計引數,
(一)背景
波士頓房價資料集包括多個樣本,每個樣本包括多個特征變數和該地區的平均房價,房價(單價)顯然和多個特征變數相關,不是單變數線性回歸(一元線性回歸)問題;選擇多個特征變數來建立線性方程,這就是多變數線性回歸(多元線性回歸)問題,
房價和多個特征變數相關,本案例嘗試使用多元線性回歸建模

(二)線性回歸檢驗
在正態假定下,如果X是列滿秩的,則普通線性回歸模型的引數最小二乘估計為:
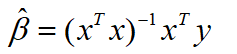
于是y的估計值為:

(1)回歸方程的顯著性檢驗

(2)回歸系數的顯著性檢驗

二、資料清洗
(一)數值資料處理
1.資料集主要問題
(1)資料缺失
(2)資料不一致
(3)存在“臟”資料
(4)資料不規范
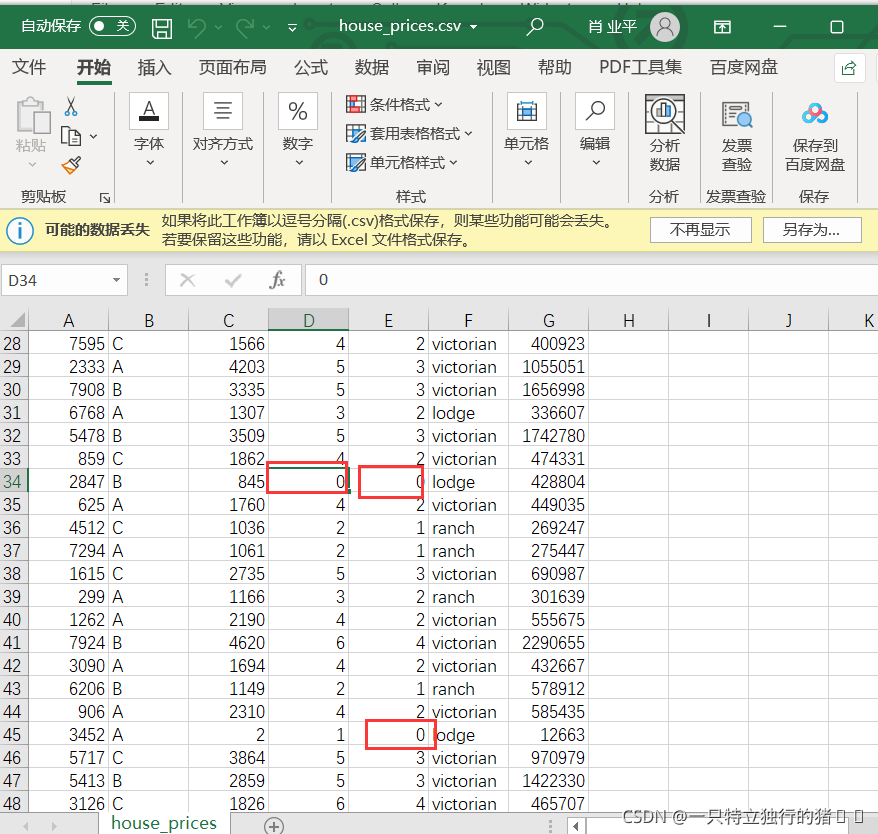
資料整體較為規整,但通過初步觀察,該資料集主要存在如下問題:資料缺失,存在某些資料等于0
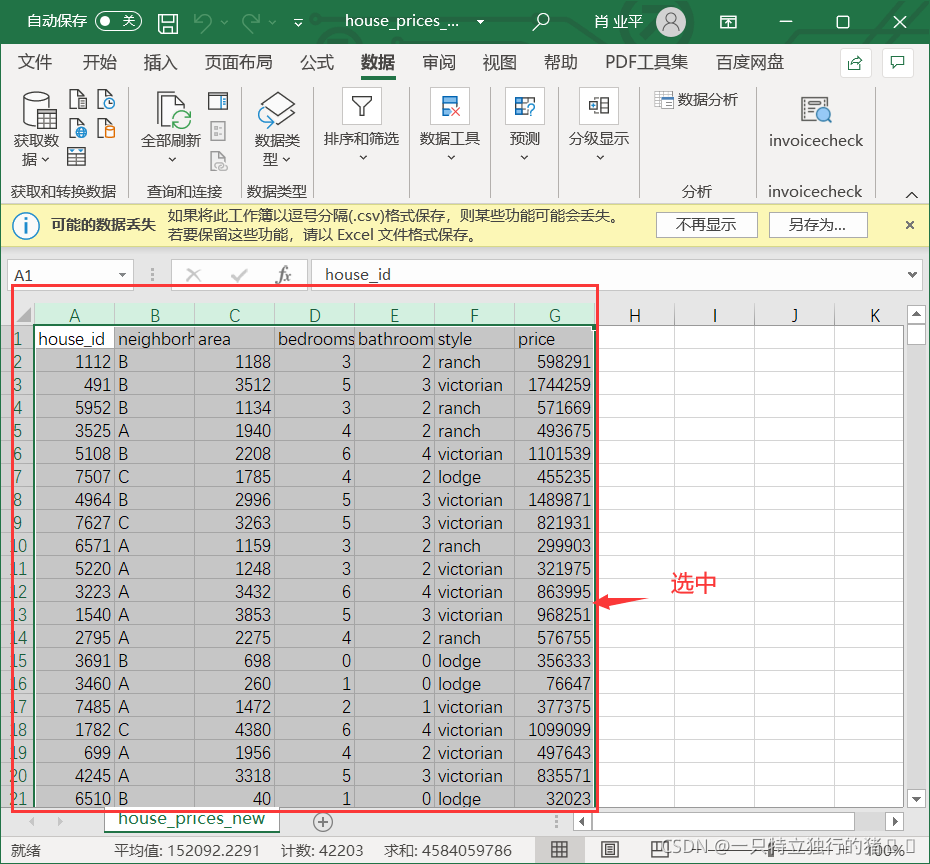
2、洗掉重復資料
(1)在 Excel 中新建一個作業表house_prices_new.csv執行資料清洗,方便和原始資料區分開來,選中需要處理的資料
(2)選擇資料——資料工具——洗掉重復值
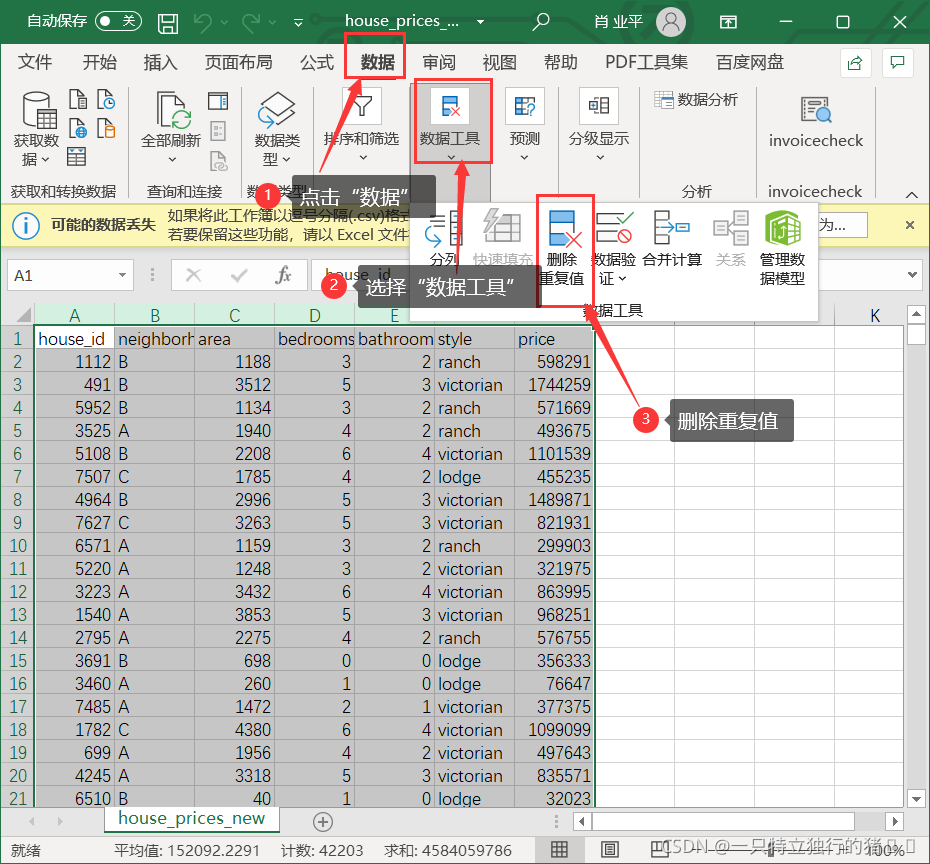
(3)利用唯一標識house_id,洗掉重復值
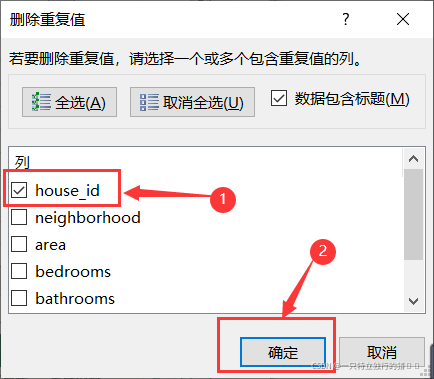
會發現沒有重復資料

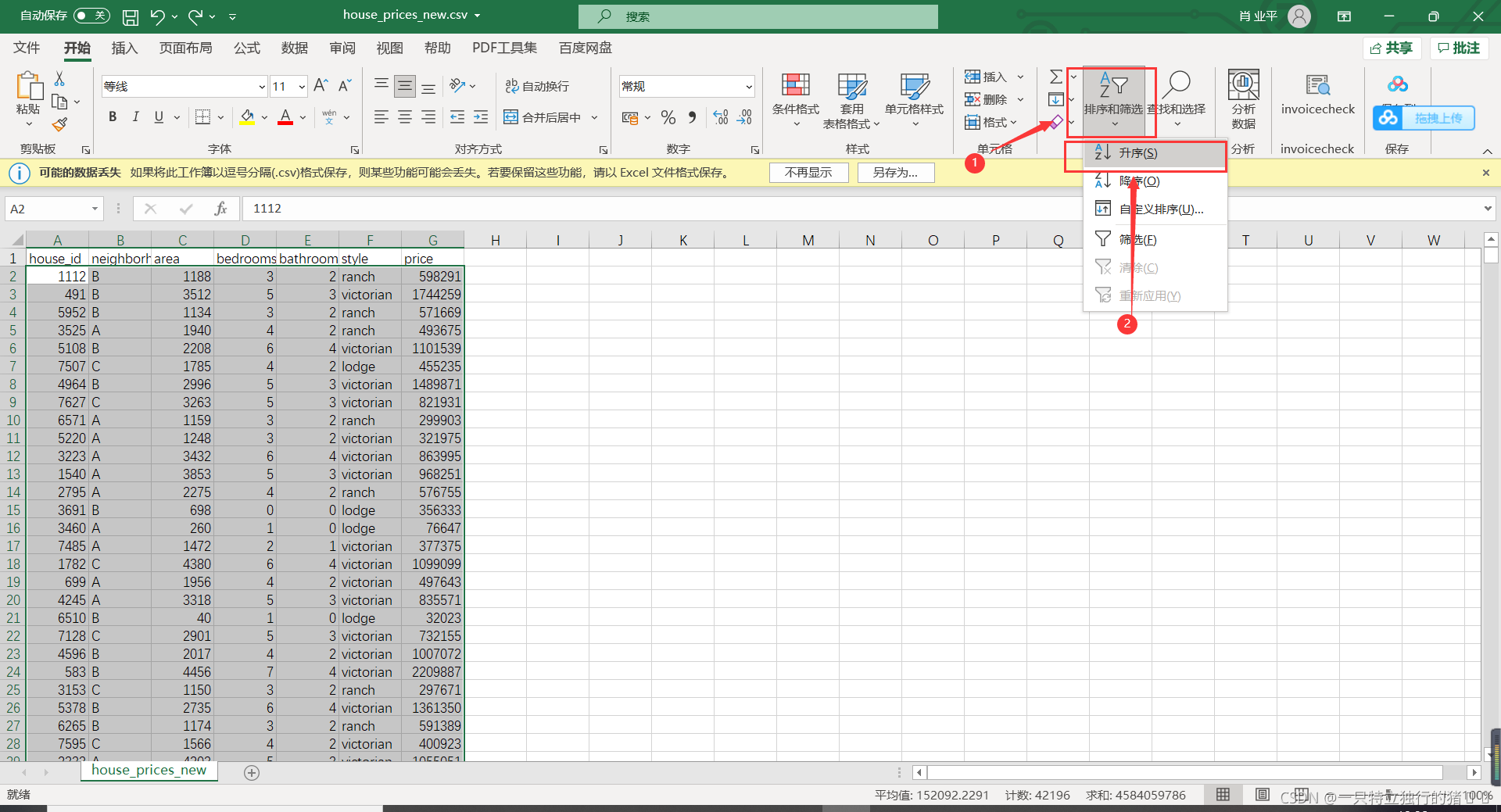
3.升序排列,選擇篩選和排序——升序
4,缺失值處理
- 通過人工手動補全,適合與缺失值比較少
- 洗掉缺失資料
- 用串列平均值代替缺失值
- 用統計模型計算出來的值代替缺失值
本題洗掉所有值為0的,缺失值所在行
(1)選中地址列的資料區域即bedrooms所在的列
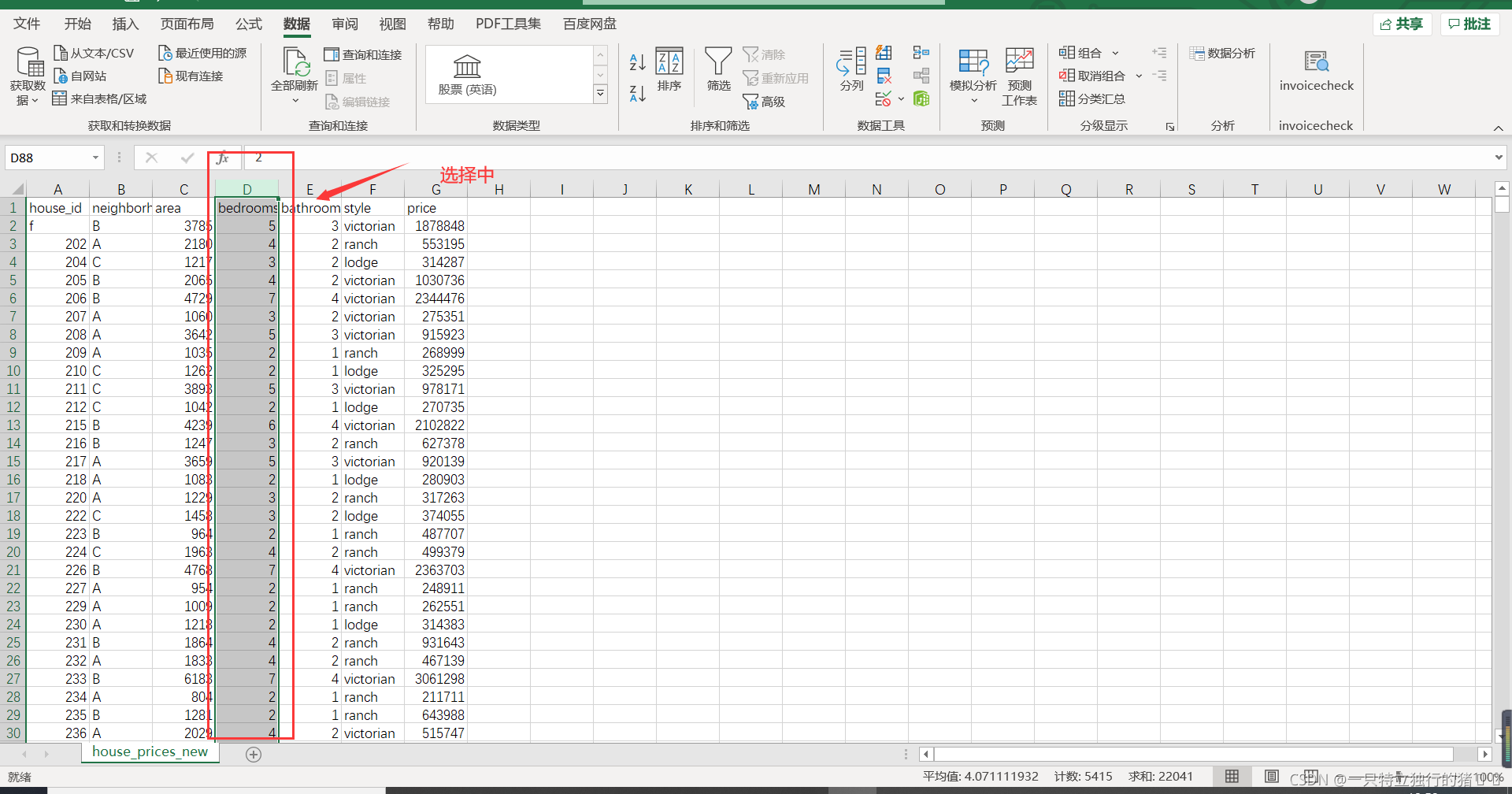
(2)采用選擇選單:點擊資料——篩選——圖中下拉三角形
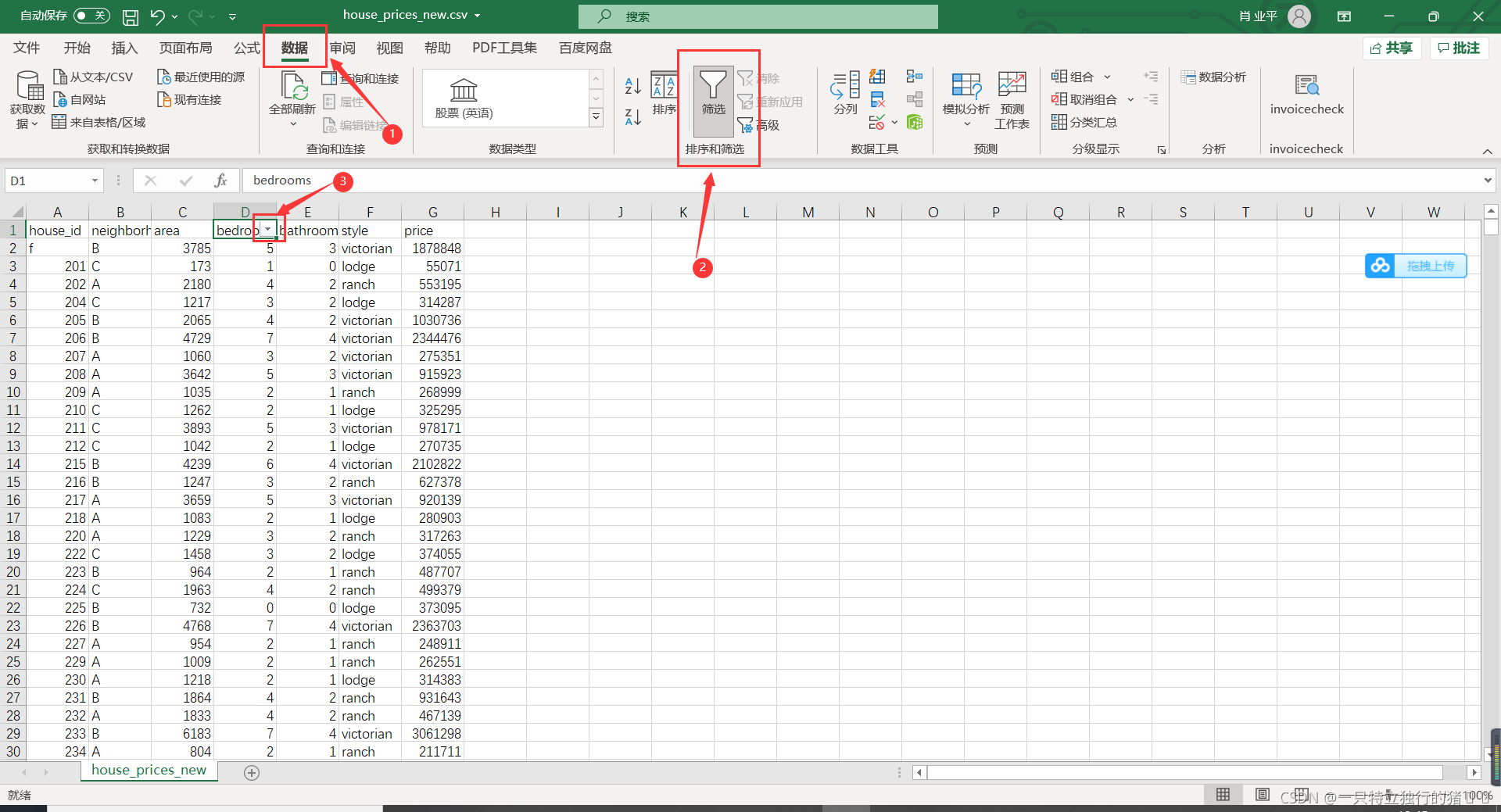
(3)篩選值為0
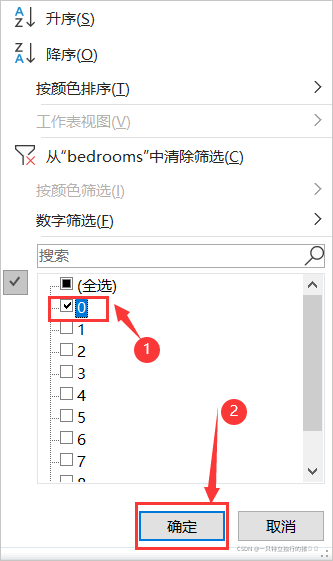
(4)選中洗掉bedrooms值為0的所有行
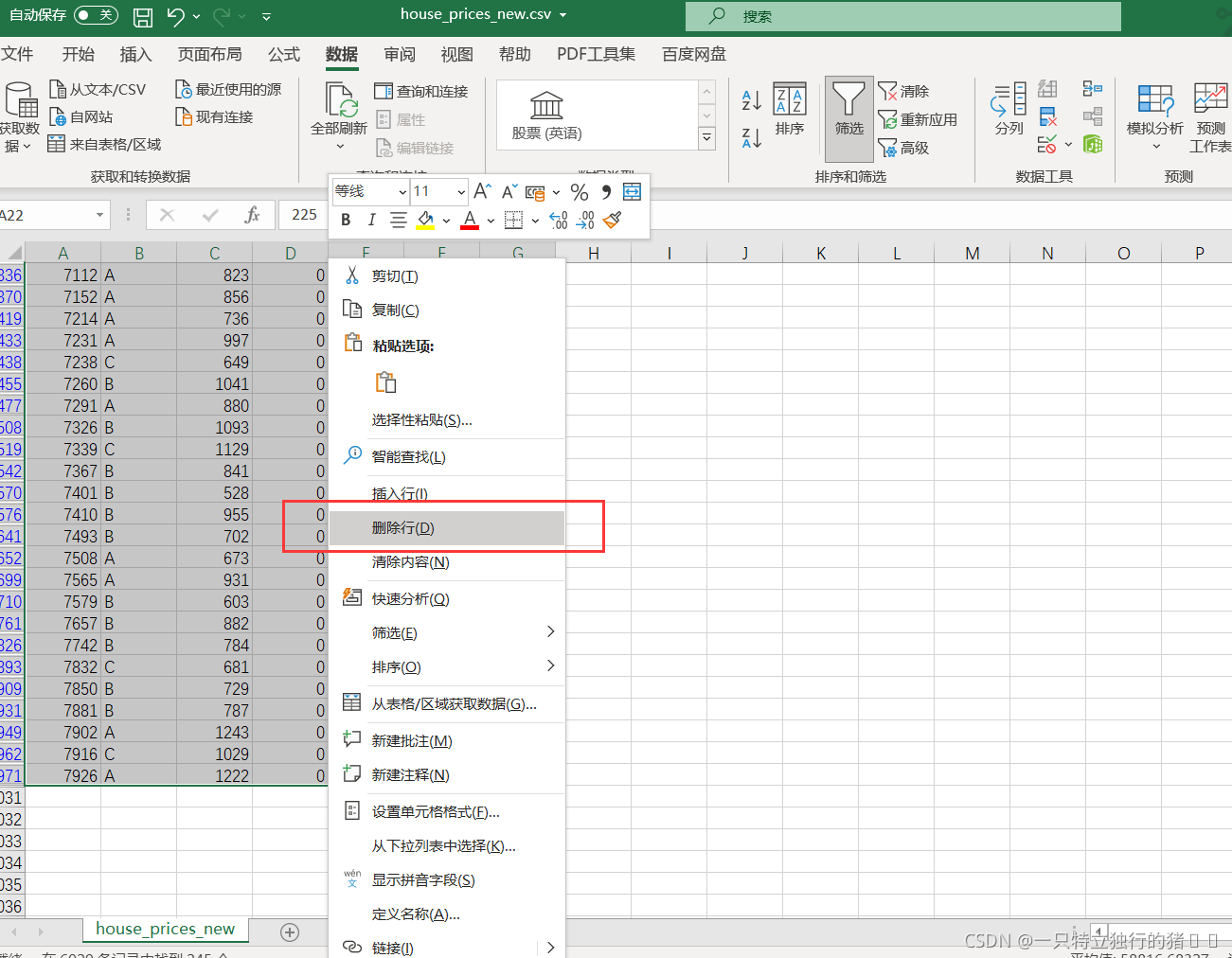
(5)以同樣的方法洗掉bathrooms值為0的行
結果如下
(二)非數值型資料轉換
在原始資料中,
neighborhood和style為非數值型資料,需要轉換成數值型資料才能夠進行回歸分析,
(1)開始——查找和替換——替換
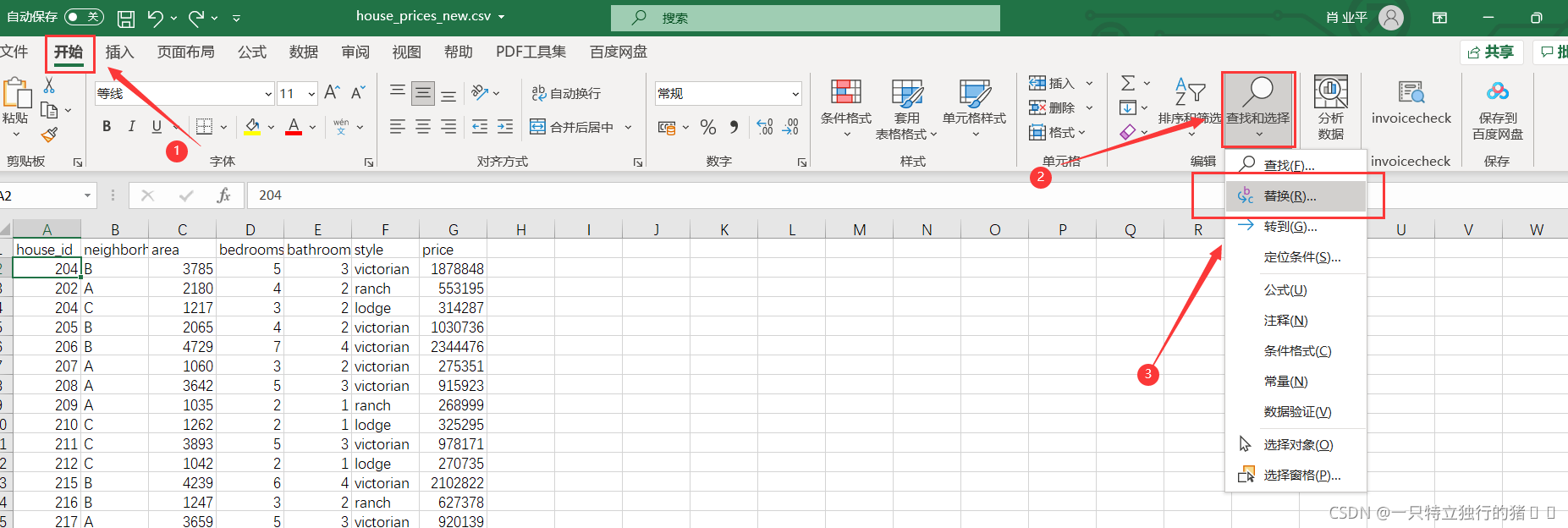
(2)選中neighborhood所在的列進行替換,把原資料的A、B、C替換為10、20、30
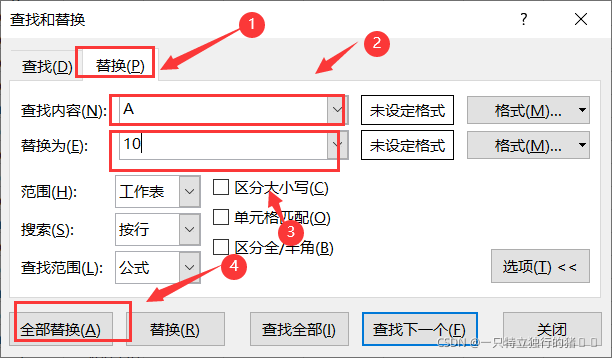
(3)替換成功
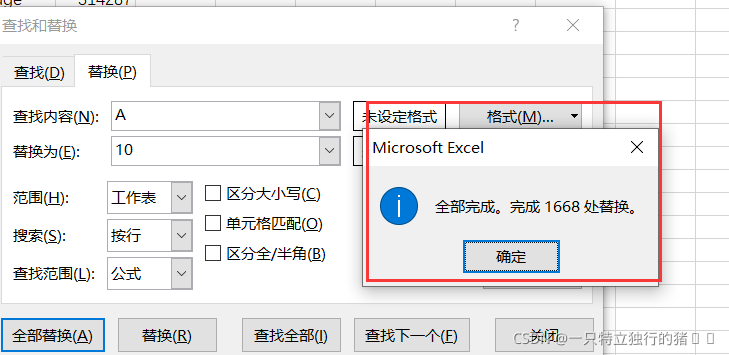
(4)以同樣的方式替換style,將原資料的victorian、ranch、lodge替換為100、200、300
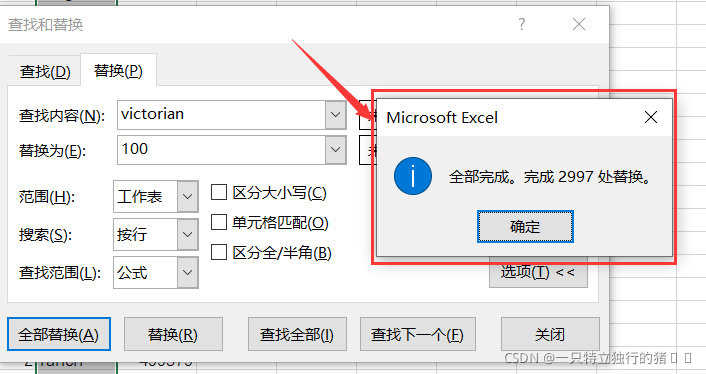
(5)替換結果
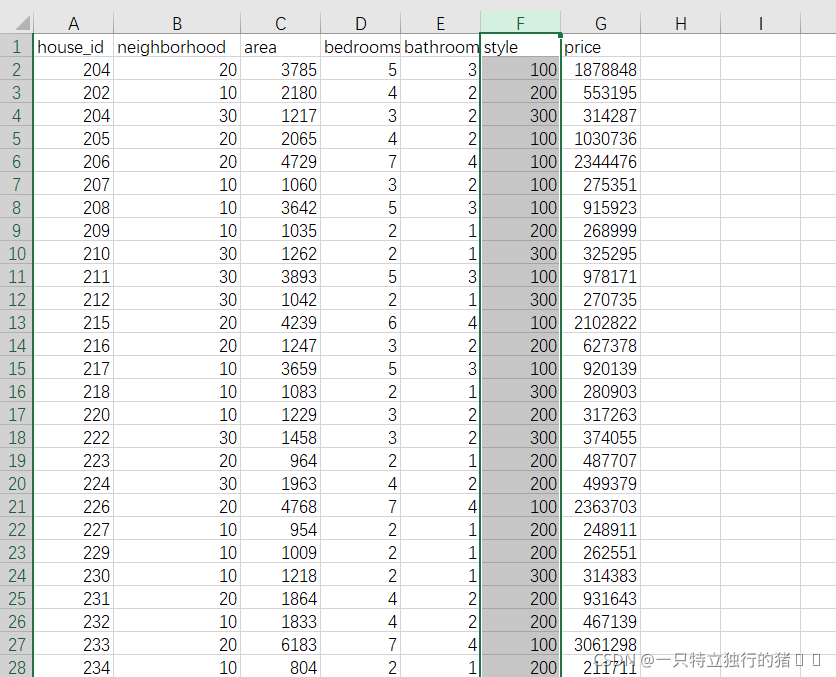
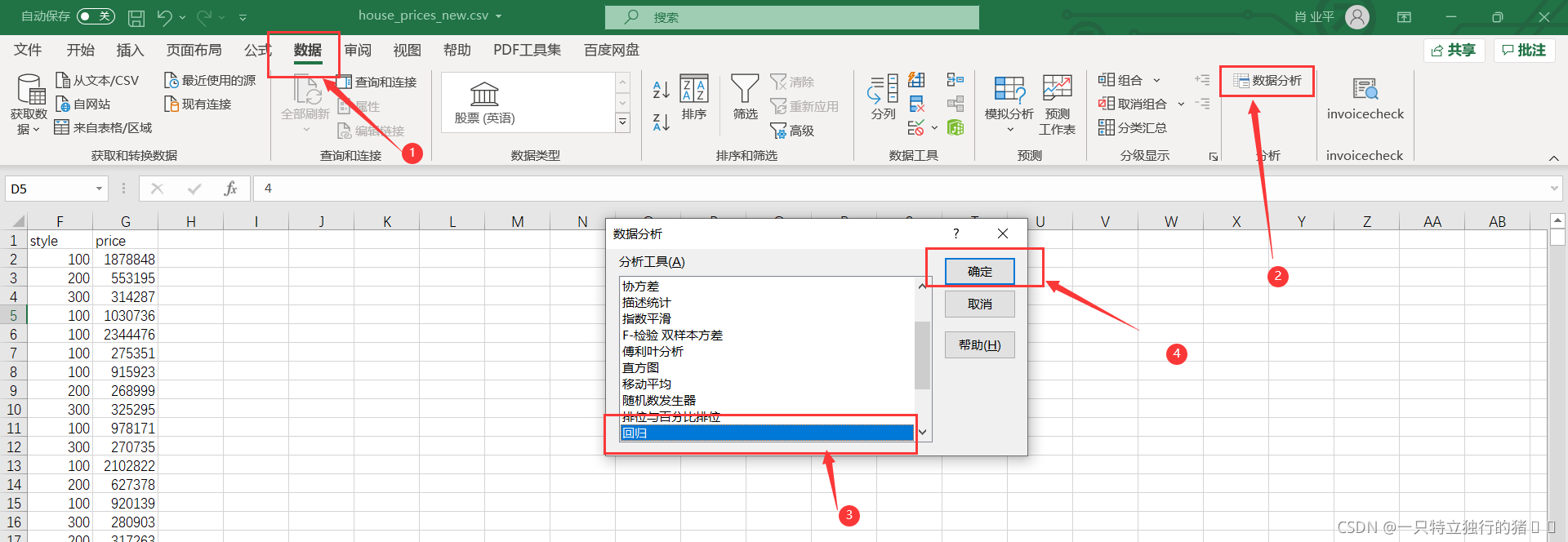
三、Excel多元線性回歸
1.選擇資料——資料分析——回歸——確定
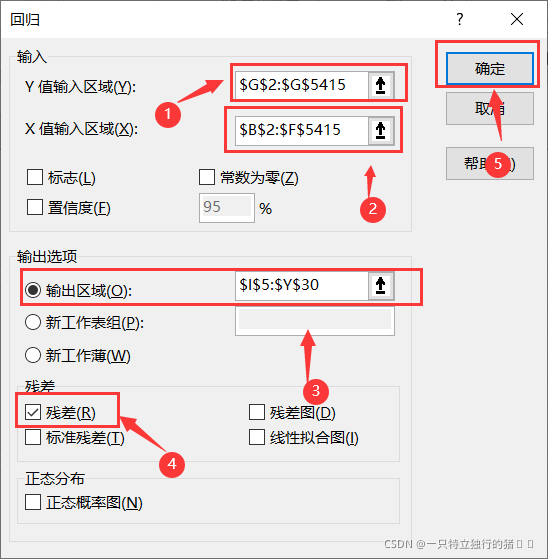
2.以X和Y值區間
①以
price作為Y值輸入區間
②以neighborhood、area、bedrooms、bathrooms、style作為X值輸入區間
③輸出顯示區域選擇
④勾選殘差
⑤點擊確定
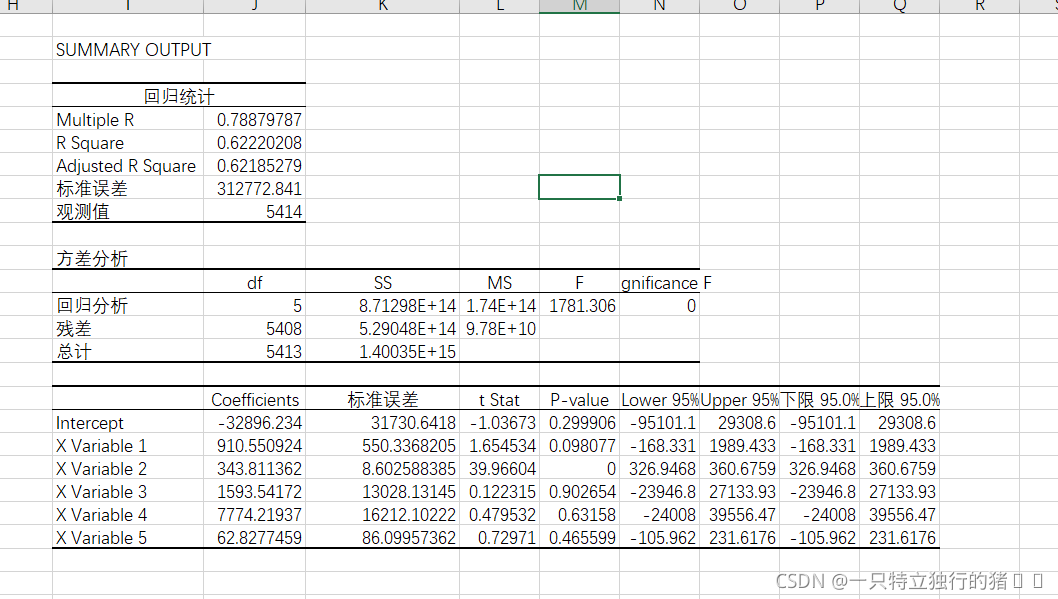
3.輸出結果
四、多元線性回歸模型預測房價
(一)基礎包與資料匯入
1.匯入包
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
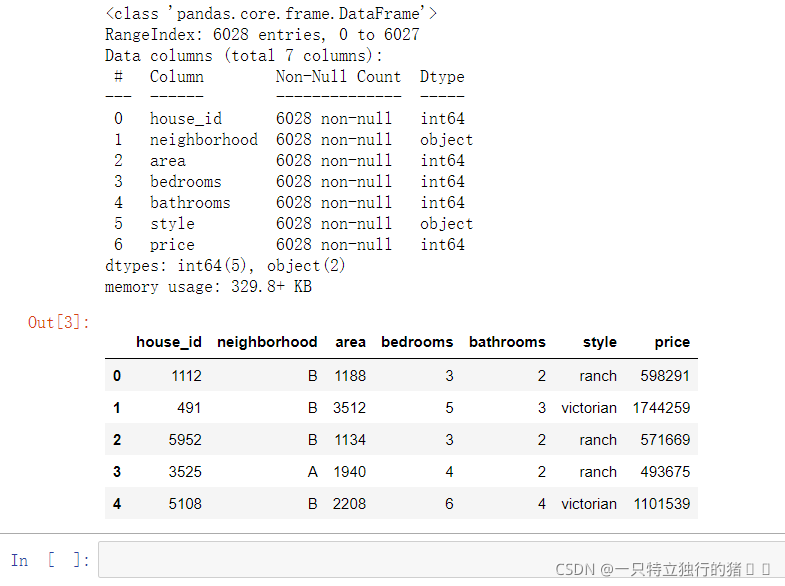
2.讀取檔案house_prices.csv’資料
(1)代碼
df = pd.read_csv('C:/Users/86199/Jupyter/house_prices.csv')
df.info(); df.head()
(2)輸出結果
(二)變數探索
1.資料處理
# 例外值處理
# ================ 例外值檢驗函式:iqr & z分數 兩種方法 =========================
def outlier_test(data, column, method=None, z=2):
""" 以某列為依據,使用 上下截斷點法 檢測例外值(索引) """
"""
full_data: 完整資料
column: full_data 中的指定行,格式 'x' 帶引號
return 可選; outlier: 例外值資料框
upper: 上截斷點; lower: 下截斷點
method:檢驗例外值的方法(可選, 默認的 None 為上下截斷點法),
選 Z 方法時,Z 默認為 2
"""
# ================== 上下截斷點法檢驗例外值 ==============================
if method == None:
print(f'以 {column} 列為依據,使用 上下截斷點法(iqr) 檢測例外值...')
print('=' * 70)
# 四分位點;這里呼叫函式會存在例外
column_iqr = np.quantile(data[column], 0.75) - np.quantile(data[column], 0.25)
# 1,3 分位數
(q1, q3) = np.quantile(data[column], 0.25), np.quantile(data[column], 0.75)
# 計算上下截斷點
upper, lower = (q3 + 1.5 * column_iqr), (q1 - 1.5 * column_iqr)
# 檢測例外值
outlier = data[(data[column] <= lower) | (data[column] >= upper)]
print(f'第一分位數: {q1}, 第三分位數:{q3}, 四分位極差:{column_iqr}')
print(f"上截斷點:{upper}, 下截斷點:{lower}")
return outlier, upper, lower
# ===================== Z 分數檢驗例外值 ==========================
if method == 'z':
""" 以某列為依據,傳入資料與希望分段的 z 分數點,回傳例外值索引與所在資料框 """
"""
params
data: 完整資料
column: 指定的檢測列
z: Z分位數, 默認為2,根據 z分數-正態曲線表,可知取左右兩端的 2%,
根據您 z 分數的正負設定,也可以任意更改,知道任意頂端百分比的資料集合
"""
print(f'以 {column} 列為依據,使用 Z 分數法,z 分位數取 {z} 來檢測例外值...')
print('=' * 70)
# 計算兩個 Z 分數的數值點
mean, std = np.mean(data[column]), np.std(data[column])
upper, lower = (mean + z * std), (mean - z * std)
print(f"取 {z} 個 Z分數:大于 {upper} 或小于 {lower} 的即可被視為例外值,")
print('=' * 70)
# 檢測例外值
outlier = data[(data[column] <= lower) | (data[column] >= upper)]
return outlier, upper, lower
2.呼叫函式
outlier, upper, lower = outlier_test(data=df, column='price', method='z')
outlier.info(); outlier.sample(5)
3.洗掉錯誤資料
# 這里簡單的丟棄即可
df.drop(index=outlier.index, inplace=True)
(三)分析資料
1.定義變數
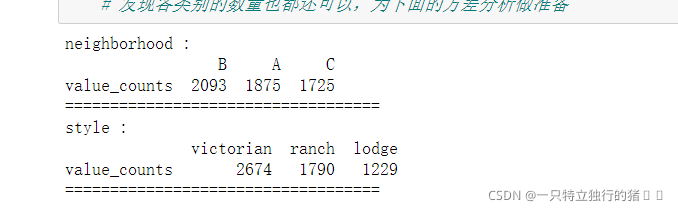
# 類別變數,又稱為名義變數,nominal variables
nominal_vars = ['neighborhood', 'style']
for each in nominal_vars:
print(each, ':')
print(df[each].agg(['value_counts']).T)
# 直接 .value_counts().T 無法實作下面的效果
## 必須得 agg,而且里面的中括號 [] 也不能少
print('='*35)
# 發現各類別的數量也都還可以,為下面的方差分析做準備
2.熱力圖查看變數關聯性
# 熱力圖
def heatmap(data, method='pearson', camp='RdYlGn', figsize=(10 ,8)):
"""
data: 整份數據
method:默認為 pearson 系數
camp:默認為:RdYlGn-紅黃藍;YlGnBu-黃綠藍;Blues/Greens 也是不錯的選擇
figsize: 默認為 10,8
"""
## 消除斜對角顏色重復的色塊
# mask = np.zeros_like(df2.corr())
# mask[np.tril_indices_from(mask)] = True
plt.figure(figsize=figsize, dpi= 80)
sns.heatmap(data.corr(method=method), \
xticklabels=data.corr(method=method).columns, \
yticklabels=data.corr(method=method).columns, cmap=camp, \
center=0, annot=True)
# 要想實作只是留下對角線一半的效果,括號內的引數可以加上 mask=mask
3.呼叫函式輸出結果
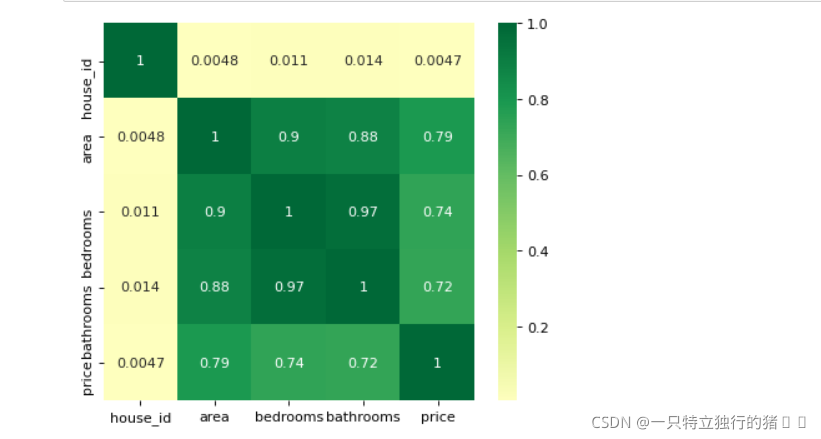
# 通過熱力圖可以看出 area,bedrooms,bathrooms 等變數與房屋價格 price 的關系都還比較強
## 所以值得放入模型,但分類變數 style 與 neighborhood 兩者與 price 的關系未知
heatmap(data=df, figsize=(6,5))
(四)擬合
1.引入模型
(1) 剛才的探索我們發現,style 與 neighborhood 的類別都是三類, 如果只是兩類的話我們可以進行卡方檢驗,所以這里我們使用方差分析
利用回歸模型中的方差分析,只有 statsmodels 有方差分析庫, 從線性回歸結果中提取方差分析結果
1)代碼
import statsmodels.api as sm
from statsmodels.formula.api import ols # ols 為建立線性回歸模型的統計學庫
from statsmodels.stats.anova import anova_lm
2)結果

(2)資料集樣本隨機選擇 600 條
1)代碼
df = df.copy().sample(600)
# C 表示告訴 Python 這是分類變數,否則 Python 會當成連續變數使用
## 這里直接使用方差分析對所有分類變數進行檢驗
## 下面幾行代碼便是使用統計學庫進行方差分析的標準姿勢
lm = ols('price ~ C(neighborhood) + C(style)', data=df).fit()
anova_lm(lm)
# Residual 行表示模型不能解釋的組內的,其他的是能解釋的組間的
# df: 自由度(n-1)- 分類變數中的類別個數減1
# sum_sq: 總平方和(SSM),residual行的 sum_eq: SSE
# mean_sq: msm, residual行的 mean_sq: mse
# F:F 統計量,查看卡方分布表即可
# PR(>F): P 值
# 反復重繪幾次,發現都很顯著,所以這兩個變數也挺值得放入模型中
2)結果

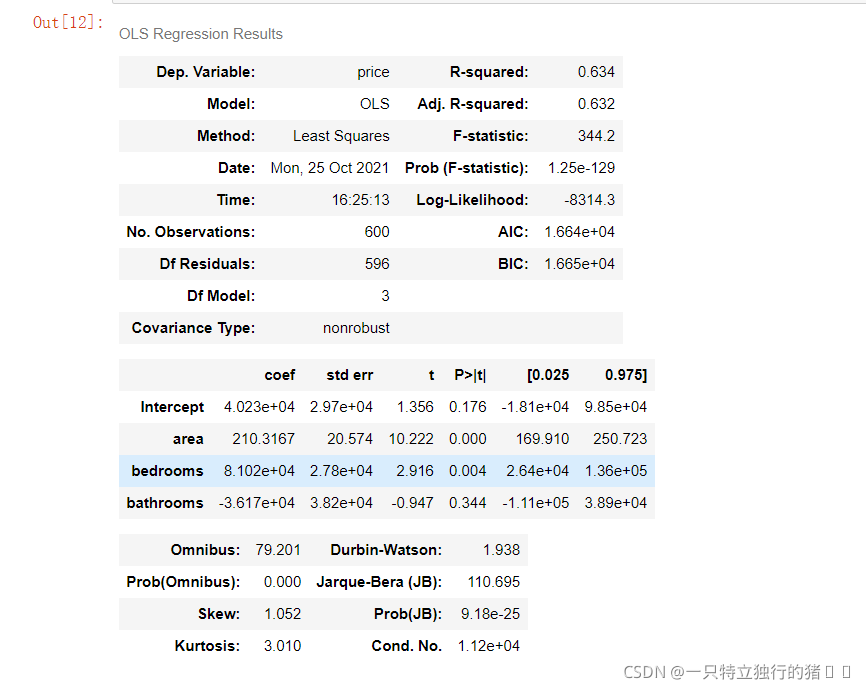
2.多元線性回歸建模
(1)代碼
from statsmodels.formula.api import ols
lm = ols('price ~ area + bedrooms + bathrooms', data=df).fit()
lm.summary()
(2)輸出結果
3.模型優化
(1)發現精度還不夠高,這里通過添加虛擬變數與使用方差膨脹因子檢測多元共線性的方式來提升模型精度
# 設定虛擬變數
# 以名義變數 neighborhood 街區為例
nominal_data = df['neighborhood']
# 設定虛擬變數
dummies = pd.get_dummies(nominal_data)
dummies.sample() # pandas 會自動幫你命名
# 每個名義變數生成的虛擬變數中,需要各丟棄一個,這里以丟棄C為例
dummies.drop(columns=['C'], inplace=True)
dummies.sample()
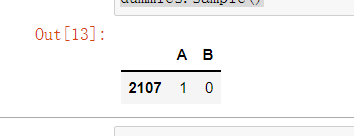
(2)結果與原資料集拼接
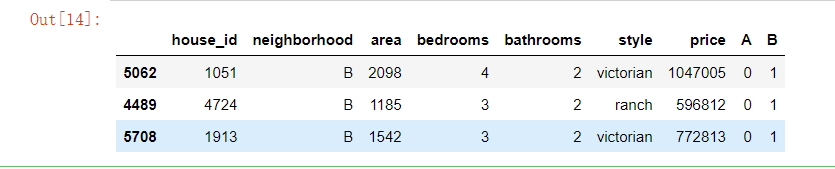
# 將結果與原資料集拼接
results = pd.concat(objs=[df, dummies], axis='columns') # 按照列來合并
results.sample(3)
# 對名義變數 style 的處理可自行嘗試
(3)輸出結果
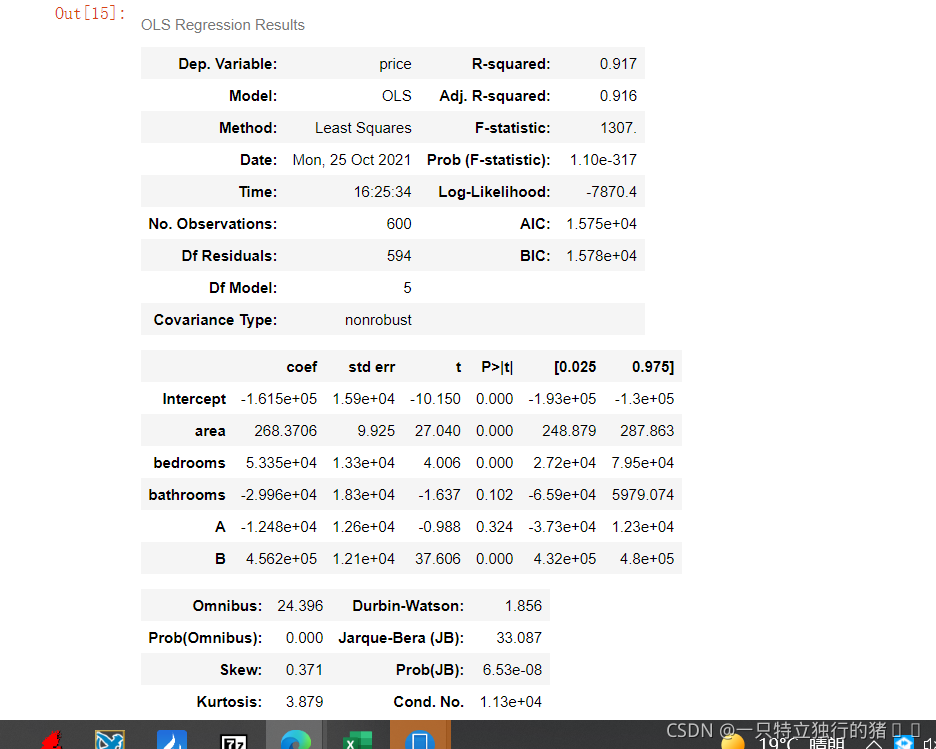
4.再次建模
(1)代碼
# 再次建模
lm = ols('price ~ area + bedrooms + bathrooms + A + B', data=results).fit()
lm.summary()
(2)結果
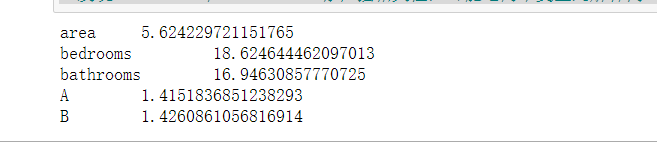
5.處理多元共線性
(1)#自定義方差膨脹因子的檢測公式
def vif(df, col_i):
"""
df: 整份資料
col_i:被檢測的列名
"""
cols = list(df.columns)
cols.remove(col_i)
cols_noti = cols
formula = col_i + '~' + '+'.join(cols_noti)
r2 = ols(formula, df).fit().rsquared
return 1. / (1. - r2)
(2)函式呼叫
test_data = results[['area', 'bedrooms', 'bathrooms', 'A', 'B']]
for i in test_data.columns:
print(i, '\t', vif(df=test_data, col_i=i))
# 發現 bedrooms 和 bathrooms 存在強相關性,可能這兩個變數是解釋同一個問題
(3)結果
6.再次擬合
bedrooms 和 bathrooms 這兩個變數的方差膨脹因子較高,印證了方差膨脹因子大多成對出現的原則,這里我們丟棄膨脹因子較大的
bedrooms 即可
(1)代碼
lm = ols(formula='price ~ area + bathrooms + A + B', data=results).fit()
lm.summary()
(2)輸出結果
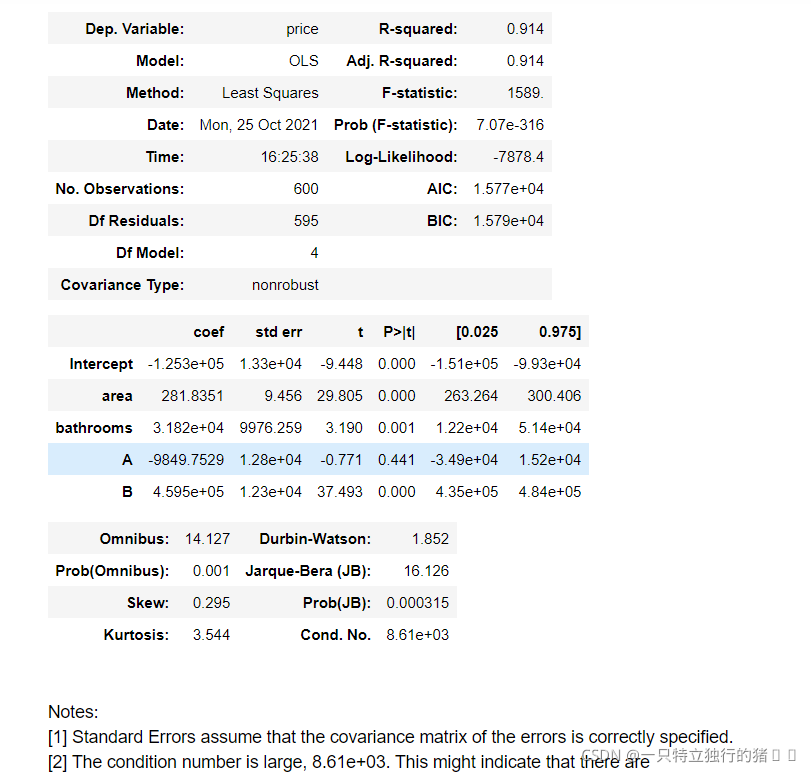
(3)還是存在多元共線性,再次檢測
test_data = df[['area', 'bathrooms']]
for i in test_data.columns:
print(i, '\t', vif(df=test_data, col_i=i))
(4)結果輸出

(5)發現精度沒變,但具體問題還是需要結合具體業務來分析
四、sklearn多元線性回歸預測房價
(一)不進行資料處理
1.匯入包和資料
(1)代碼
import pandas as pd
import numpy as np
import math
import matplotlib.pyplot as plt # 畫圖
from sklearn import linear_model # 線性模型
data = pd.read_csv('C:/Users/86199/Jupyter/house_prices_second.csv') #讀取資料
data.head() #資料展示
(2)顯示結果
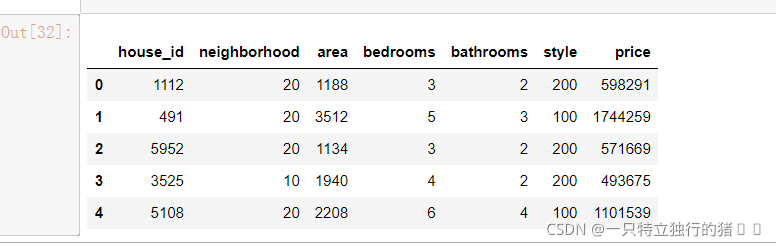
2.去除第一列house_id
(1)代碼
new_data=data.iloc[:,1:] #除掉id這一列
new_data.head()
(2)結果
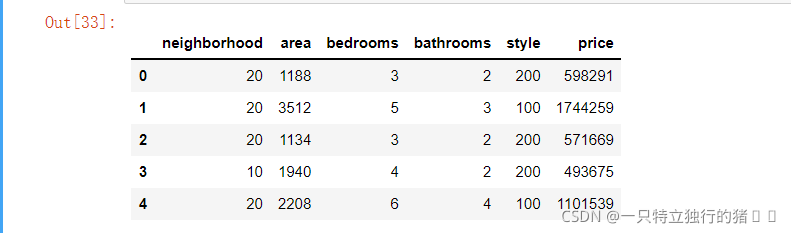
3.關系系數矩陣顯示
new_data.corr() # 相關系數矩陣,只統計數值列
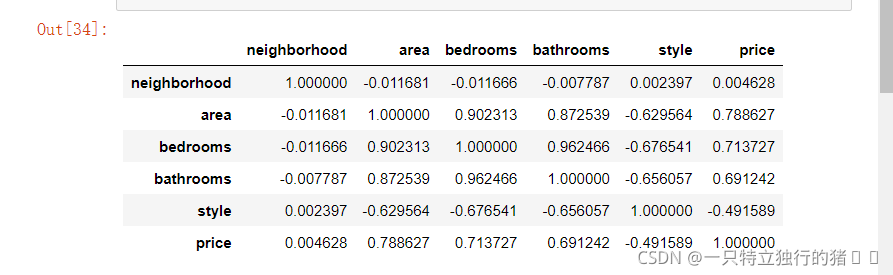
4.賦值變數
(1)代碼
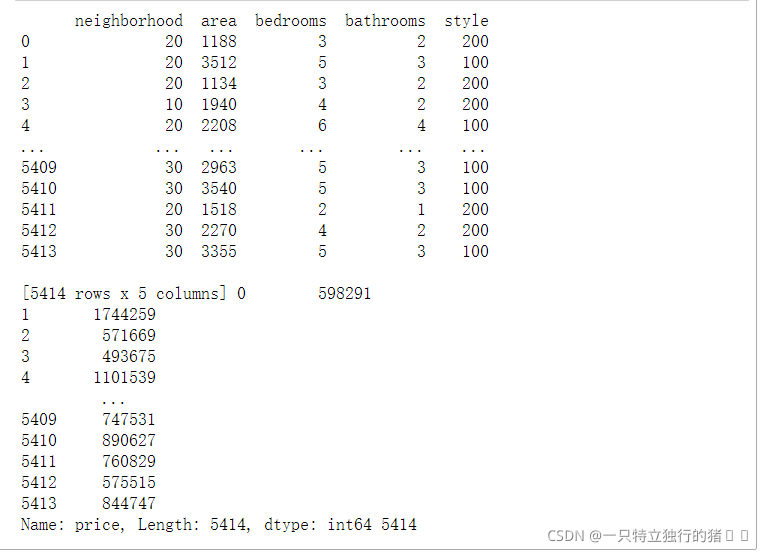
x_data = new_data.iloc[:, 0:5] #area、bedrooms、bathroom對應列
y_data = new_data.iloc[:, -1] #price對應列
print(x_data, y_data, len(x_data))
(2)結果
5.建立模型并輸出結果
# 應用模型
model = linear_model.LinearRegression()
model.fit(x_data, y_data)
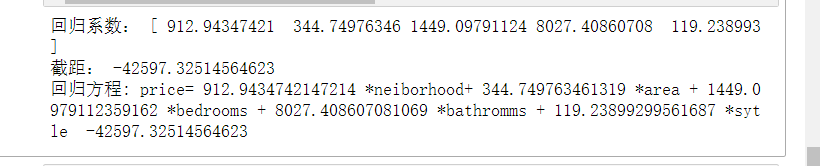
print("回歸系數:", model.coef_)
print("截距:", model.intercept_)
print('回歸方程: price=',model.coef_[0],'*neiborhood+',model.coef_[1],'*area +',model.coef_[2],'*bedrooms +',model.coef_[3],'*bathromms +',model.coef_[4],'*sytle ',model.intercept_)
(二)對資料進行清洗后再求解
1.賦值新變數
new_data_Z=new_data.iloc[:,0:]
new_data_IQR=new_data.iloc[:,0:]
2.例外值處理
# ================ 例外值檢驗函式:iqr & z分數 兩種方法 =========================
def outlier_test(data, column, method=None, z=2):
""" 以某列為依據,使用 上下截斷點法 檢測例外值(索引) """
"""
full_data: 完整資料
column: full_data 中的指定行,格式 'x' 帶引號
return 可選; outlier: 例外值資料框
upper: 上截斷點; lower: 下截斷點
method:檢驗例外值的方法(可選, 默認的 None 為上下截斷點法),
選 Z 方法時,Z 默認為 2
"""
# ================== 上下截斷點法檢驗例外值 ==============================
if method == None:
print(f'以 {column} 列為依據,使用 上下截斷點法(iqr) 檢測例外值...')
print('=' * 70)
# 四分位點;這里呼叫函式會存在例外
column_iqr = np.quantile(data[column], 0.75) - np.quantile(data[column], 0.25)
# 1,3 分位數
(q1, q3) = np.quantile(data[column], 0.25), np.quantile(data[column], 0.75)
# 計算上下截斷點
upper, lower = (q3 + 1.5 * column_iqr), (q1 - 1.5 * column_iqr)
# 檢測例外值
outlier = data[(data[column] <= lower) | (data[column] >= upper)]
print(f'第一分位數: {q1}, 第三分位數:{q3}, 四分位極差:{column_iqr}')
print(f"上截斷點:{upper}, 下截斷點:{lower}")
return outlier, upper, lower
# ===================== Z 分數檢驗例外值 ==========================
if method == 'z':
""" 以某列為依據,傳入資料與希望分段的 z 分數點,回傳例外值索引與所在資料框 """
"""
params
data: 完整資料
column: 指定的檢測列
z: Z分位數, 默認為2,根據 z分數-正態曲線表,可知取左右兩端的 2%,
根據您 z 分數的正負設定,也可以任意更改,知道任意頂端百分比的資料集合
"""
print(f'以 {column} 列為依據,使用 Z 分數法,z 分位數取 {z} 來檢測例外值...')
print('=' * 70)
# 計算兩個 Z 分數的數值點
mean, std = np.mean(data[column]), np.std(data[column])
upper, lower = (mean + z * std), (mean - z * std)
print(f"取 {z} 個 Z分數:大于 {upper} 或小于 {lower} 的即可被視為例外值,")
print('=' * 70)
# 檢測例外值
outlier = data[(data[column] <= lower) | (data[column] >= upper)]
return outlier, upper, lower
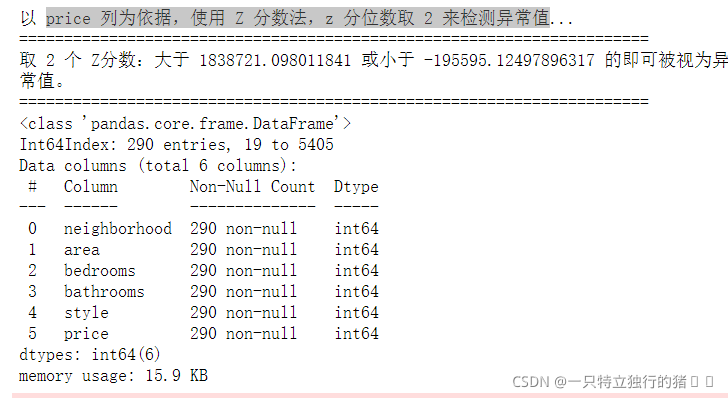
3.price 列為依據,使用 Z 分數法,z 分位數取 2 來檢測例外值
outlier, upper, lower = outlier_test(data=new_data_Z, column='price', method='z')
outlier.info(); outlier.sample(5)
# 這里簡單的丟棄即可
new_data_Z.drop(index=outlier.index, inplace=True)
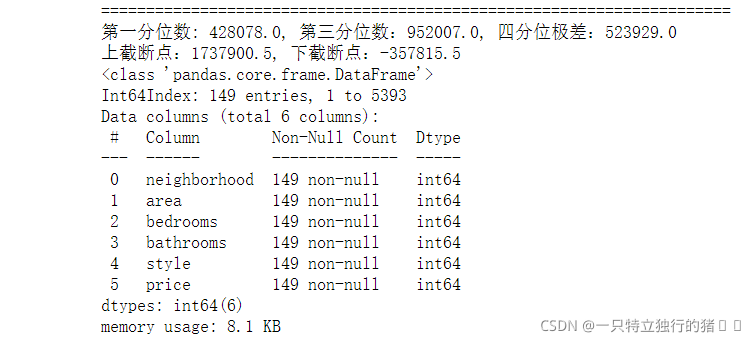
4. price 列為依據,使用 上下截斷點法(iqr) 檢測例外值
outlier, upper, lower = outlier_test(data=new_data_IQR, column='price')
outlier.info(); outlier.sample(6)
# 這里簡單的丟棄即可
new_data_IQR.drop(index=outlier.index, inplace=True)
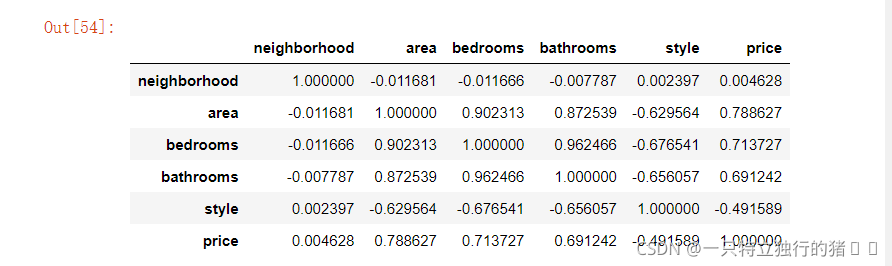
5.輸出原資料相關矩陣
print("原資料相關性矩陣")
new_data.corr()
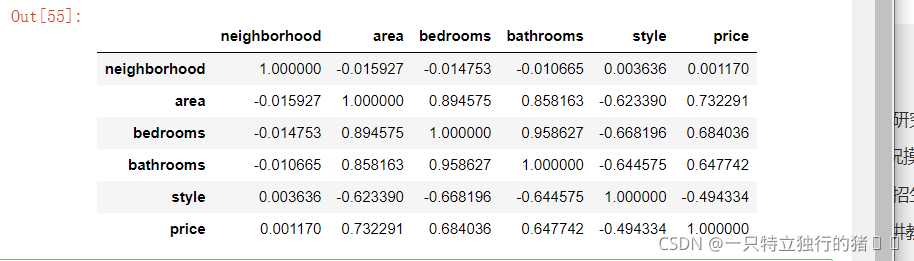
6.Z方法處理的資料相關性矩陣
在這里插入代碼片print("Z方法處理的資料相關性矩陣")
new_data_Z.corr()
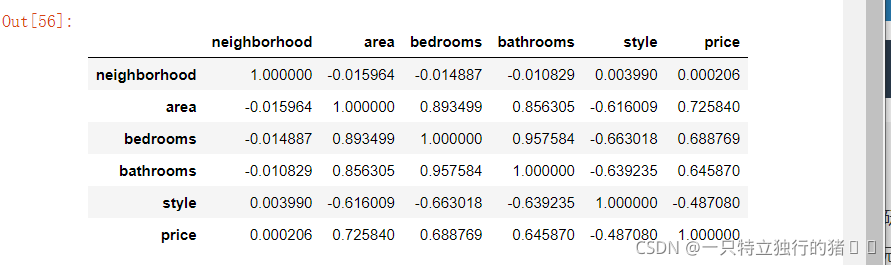
7.IQR方法處理的資料相關性矩陣
print("IQR方法處理的資料相關性矩陣")
new_data_IQR.corr()
8.建模輸出
x_data = new_data_Z.iloc[:, 0:5]
y_data = new_data_Z.iloc[:, -1]
# 應用模型
model = linear_model.LinearRegression()
model.fit(x_data, y_data)
print("回歸系數:", model.coef_)
print("截距:", model.intercept_)
print('回歸方程: price=',model.coef_[0],'*neiborhood+',model.coef_[1],'*area +',model.coef_[2],'*bedrooms +',model.coef_[3],'*bathromms +',model.coef_[4],'*sytle ',model.intercept_)

五、總結
本次實驗了解了多元回歸模型的相關概念,構建模型的基本步驟,學會了如何用Excel表構建多元回歸模型,其實更一元線性回歸所用方法很相似,唯一不同的點就是X值區間的選擇,由一元線性回歸的單個變數變為多個,更加熟悉使用sklearn庫呼叫函式的方法,了解了一些處理資料的基本方法,包括處理預設值和非數值資料的處理方法等,
六、參考資料
多元線性回歸—波士頓房價預測(版本一)
多元線性回歸模型
資料清洗技術——Excel資料清洗
excel資料清洗_資料清洗步驟
【機器學習】機器學習之多元線性回歸
sklearn多元線性回歸預測房價
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/337592.html
標籤:AI
上一篇:深度學習 -- TensorFlow(9)回圈神經網路RNN
下一篇:推薦演算法-協同過濾代碼問題匯總