關注并星標
從此不迷路
計算機視覺研究院


公眾號ID|ComputerVisionGzq
學習群|掃碼在主頁獲取加入方式

論文地址:https://arxiv.org/pdf/1901.01928v1.pdf
計算機視覺研究院專欄
作者:Edison_G
深度學習模型在目標檢測的性能上取得了重大突破,然而,在傳統模型中,例如Faster R-CNN和YOLO,由于計算資源有限和功率預算緊張,這些網路的規模使其難以部署在嵌入式移動設備上,
一、背景
卷積神經網路已被證明在計算機視覺中傳統的艱巨任務中是成功的,例如影像分類和目標檢測,隨著AlexNet的突破,ILSVRC中創建了許多新的拓撲來實作高精度,此類網路的成功不僅將注意力轉移到如何做到這一點上,而且還轉移到了它運行的速度和記憶效率上,這些模型以具有數百萬個引數而聞名,即使使用GPU,它也需要更多的計算時間和比許多應用程式所需的更多的存盤空間,

運行卷積神經網路時所需的大部分記憶體和計算作業都花在了卷積層中,例ResNet50超過90%的時間/記憶體,這意味著,為了讓網路運行得更快更高效,我們必須提高卷積層的計算負載,
二、前言
考慮到這一點,研究者提出了一種新型的卷積層,我們稱之為分布移位卷積(DSConv),這種型別的層在設計時考慮了兩個主要目標:(i)它應該大大提高標準卷積層的記憶體效率和速度;(ii)它應該是標準卷積的即插即用替代品,因此它可以直接用于任何卷積神經網路,包括推理和訓練,
研究者通過將傳統的卷積內核分解為兩個組件來實作這一點,其中之一是只有整數值的張量,不可訓練,并根據預訓練網路中浮點 (FP) 權重的分布進行計算,另一個組件由兩個分布移位器張量組成,它們將量化張量的權重定位在模擬原始預訓練網路分布的范圍內:其中一個移動每個內核的分布,另一個移動每個通道,這些權重可以重新訓練,使網路能夠適應新的任務和資料集,
三、新框架(DSConv layer)
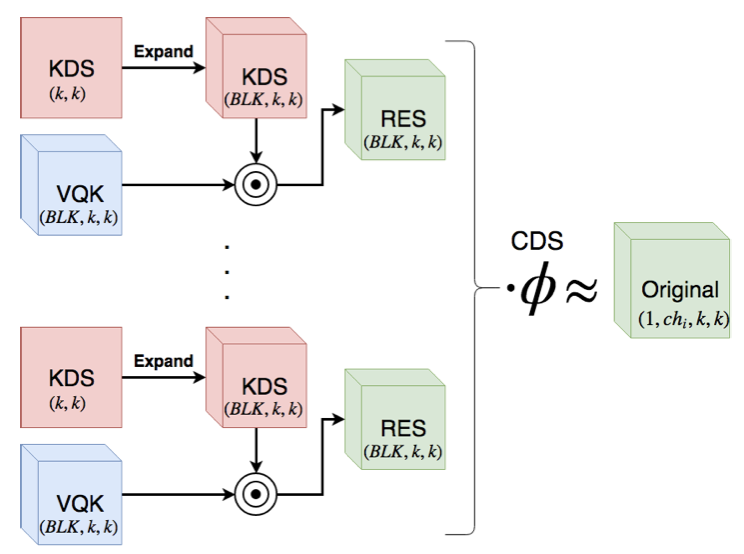
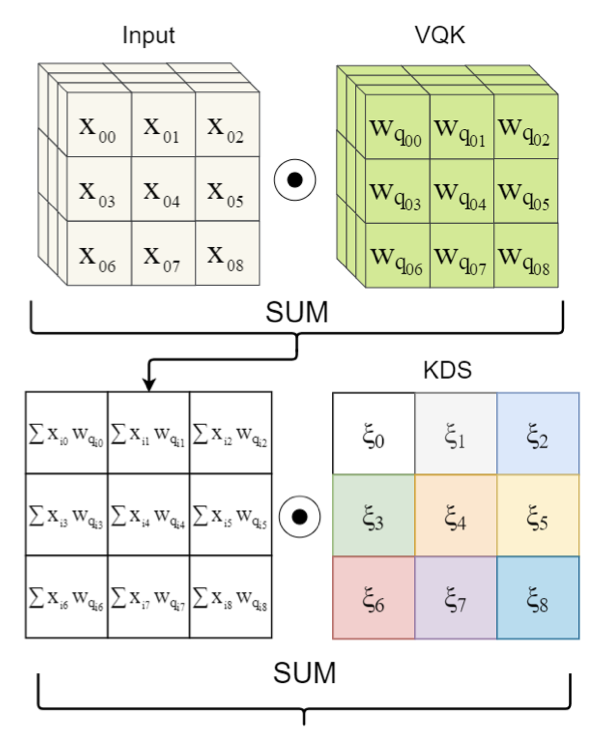
可變數化內核(VQK):此張量僅保留可變位長整數值,并且與原始卷積張量具有相同大小的(ch0,chi,k,k),引數值被設定為從原始浮點模型量化,并且一旦設定不能改變,這是DSConv的量化組件,
分布移位:此組件的目的是移動VQK的分布以嘗試模仿原始卷積內核的分布,通過使用兩個張量轉換兩個域來實作,第一個張量是內核分布移位器(KDS),他改變每個(1,BLK,1,1)的分布,
例如,給定(128,128,3,3)的原始單精度張量大小,將位大小的超引數設定為2位且塊大小設定為64,將保存2位整數的VQK的大小為(128,128,3,3)(量化后的,由單精度變整型),保持FP32編號的內核移位器(KDS)的大小為2*(128,2,3,3),保存Fp32編號的通道移位器的大小為2*(128),在此示例中,卷積內核減少到其原始大小的7%
使用此設定,VQK充當先驗,它捕獲特定切片應提取的特征型別的本質,
四、 Quantization Procedure
量化函式將要量化的網路的位元數作為輸入,并將帶符號的整數表示來存盤,
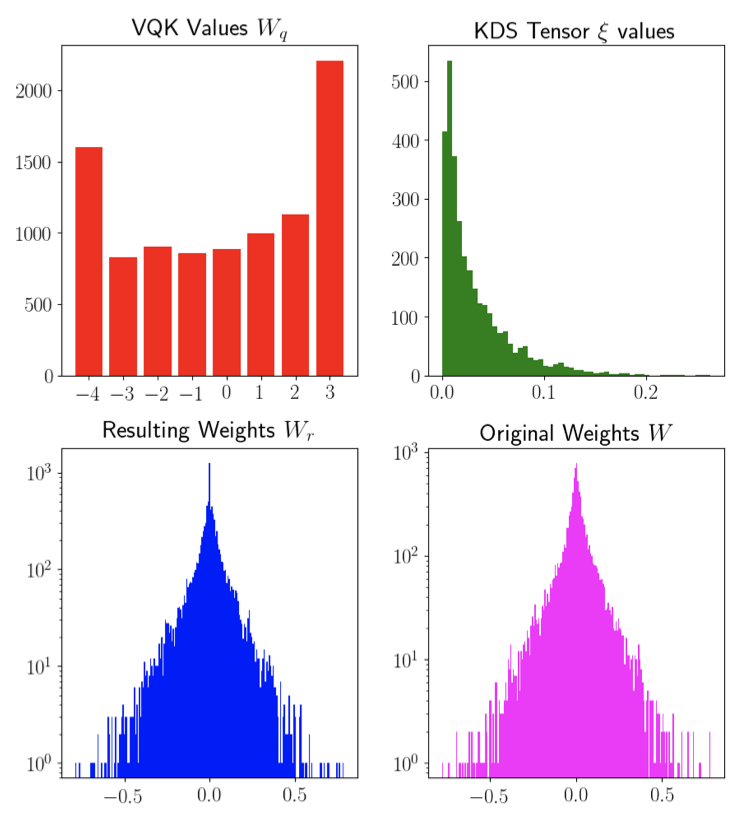
這是通過首先縮放每個卷積層的權重以使得原始權重w的最大絕對值與上面的量化約束的最大值匹配來實作的,再次步驟之后,將所有權重量化為最接近的整數,然后將新權重wq作為整數值存盤到存盤器中,以便稍后在訓練和推理中使用,
五、 Distribution Shifts
分布轉移的目的是移動VQK,使得輸出和原始權重張量的值是相匹配的,這是通過內核中的分布偏移(KDS)以及通道中的分布偏移(CDS)來完成的,對其進行良好的初始化是有必要的,因為他會使網路最接近最佳值,只有在達到最大精度之前才進行微調,
KL-Divergence: 內核分布器移位后產生的VQK應該具有與原始權重類似的分布,量化程序僅適用縮放因子來評估VQK的整數值
最小化L2范數:初始化內核移位器張量的值,使得逐元素乘法后的結果盡可能接近原始值,
兩種方法效果是一致的,
六、 Optimized Inference
首先將它乘以輸入張量,而不是移動VQK,這意味著大部分操作將以整數值而不是浮點數計算,根據所使用的硬體,這可以通過8位操作實作2-10倍的加速,使硬體可以利用整數運算而不必使用浮點運算,
給定BLK的塊大小,當chi是BLK的倍數時,該方法將執行比其原始對應物少的FP乘法的BLK倍,對于塊大小為128,通過簡單的將卷積層更改為DSConv,將顯著減少2個量級的fp乘法
在執行給定內核中所有卷積的總和之后,將在稍微應用信道分布移位,進一步改善存盤器和計算能力,如果模型在卷積運算子之后包括它,則可以將通道移位合并到BN中,
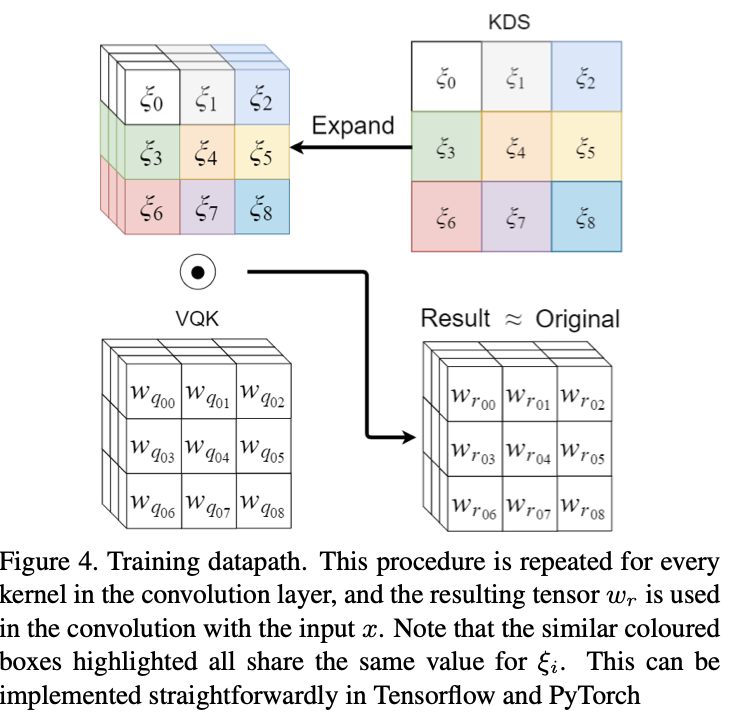
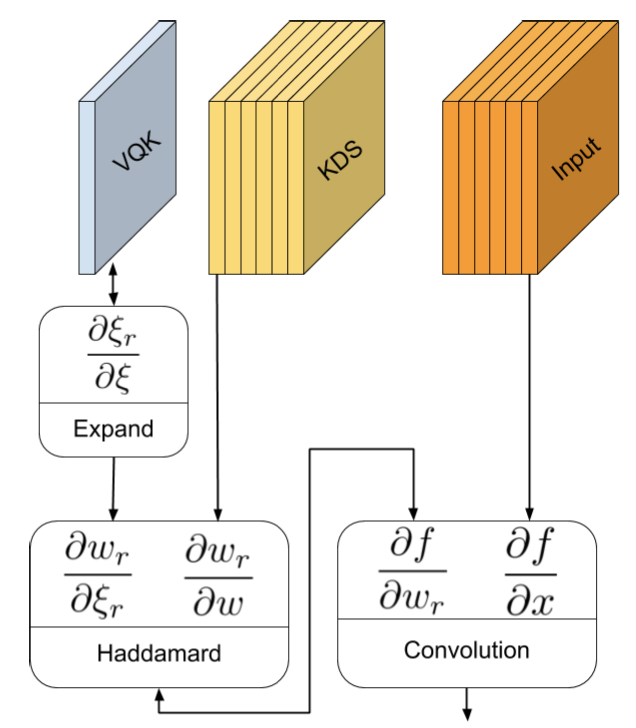
使用此程序,也可以很容易地計算方向傳播,借助上圖可以看出方向傳播被簡單地分解為三個簡單的操作,還應該注意的是,VQK核是不可訓練的,因此不需要計算?wr/?w的值,相反,只需要計算?ξr/?ξ,它的大小明顯小于?wr/?w,
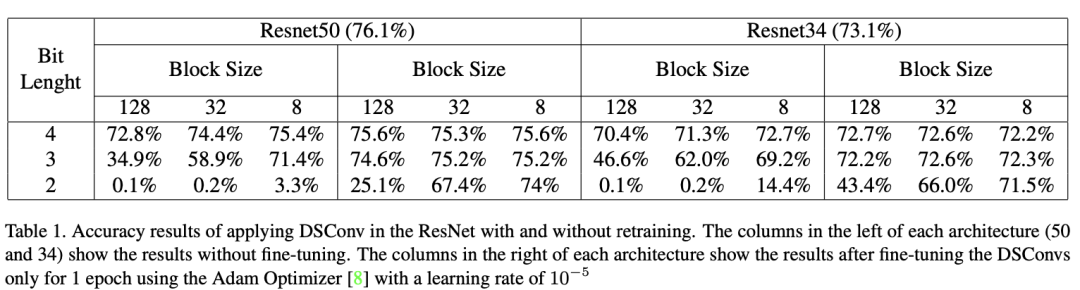
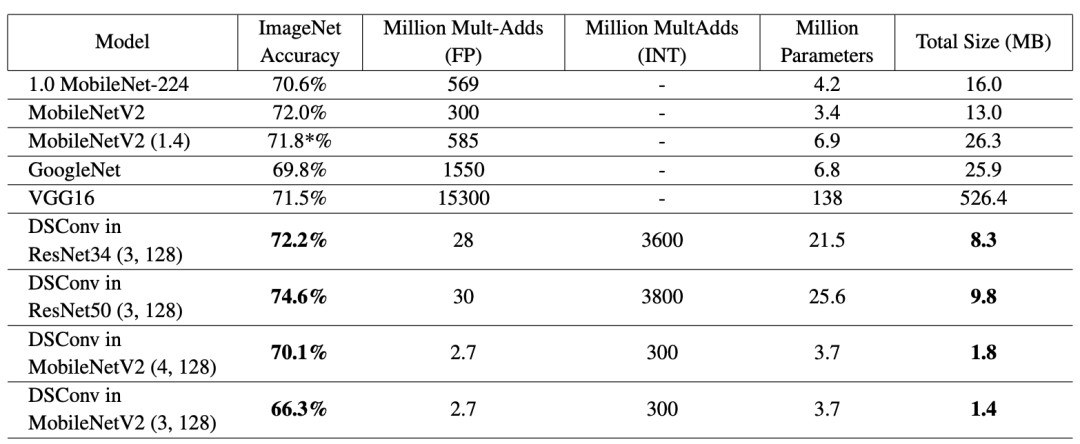
七、 實驗

? THE END
轉載請聯系本公眾號獲得授權

計算機視覺研究院學習群等你加入!
計算機視覺研究院主要涉及深度學習領域,主要致力于人臉檢測、人臉識別,多目標檢測、目標跟蹤、影像分割等研究方向,研究院接下來會不斷分享最新的論文演算法新框架,我們這次改革不同點就是,我們要著重”研究“,之后我們會針對相應領域分享實踐程序,讓大家真正體會擺脫理論的真實場景,培養愛動手編程愛動腦思考的習慣!

掃碼關注
計算機視覺研究院
公眾號ID|ComputerVisionGzq
學習群|掃碼在主頁獲取加入方式
往期推薦
🔗
Micro-YOLO:探索目標檢測壓縮模型的有效方法(附論文下載)
位元組跳動新框架:圖片中遮擋關系如何判斷?新方法重繪SOTA(附源代碼)
Apple團隊:輕量級、通用且移動友好的網路框架(附論文下載)
多目標檢測:基于YoloV4優化的多目標檢測(附論文下載)
Fast YOLO:用于實時嵌入式目標檢測(附論文下載)
目標檢測干貨 | 多級特征重復使用大幅度提升檢測精度(文末附論文下載)
多尺度深度特征(下):多尺度特征學習才是目標檢測精髓(論文免費下載)
多尺度深度特征(上):多尺度特征學習才是目標檢測精髓(干貨滿滿,建議收藏)
ICCV2021目標檢測:用圖特征金字塔提升精度(附論文下載)
CVPR21小樣本檢測:蒸餾&背景關系助力小樣本檢測(代碼已開源)
半監督輔助目標檢測:自訓練+資料增強提升精度(附原始碼下載)
目標檢測干貨 | 多級特征重復使用大幅度提升檢測精度(文末附論文下載)
目標檢測新框架CBNet | 多Backbone網路結構用于目標檢測(附原始碼下載)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/337845.html
標籤:其他
上一篇:undefined reference to `cv::VideoCapture::VideoCapture()