0、前言
降維是計算機視覺、模式識別、機器學習等領域常見的資料分析和處理方法,在人臉識別、資料可視化等領域,通常需要從高維資料中提取有效的低維特征,以方便資料分析和處理,
降維演算法主要包括線性降維演算法和非線性降維演算法,線性降維演算法最典型的包括:主成分分析(Principal Component Analysis,PCA)和線性判別分析(Linear Discriminant Analysis,LDA),PCA 是一種無監督的降維演算法,其核心思想是找到一組正交基,將高維資料映射到低維空間,使降維后的資料方差最大,從而達到盡可能多的保留原始高維資料的資訊,LDA 是一種監督的降維演算法,其目標是尋找一組最優投影向量來最大化類間散度矩陣和類內散度矩陣之間的比值,使得同一類資料盡可能聚集在一起,不同類資料盡可能分開,
但是這兩種演算法都旨在保留原始高維資料的全域歐氏結構,并不能挖掘到原始高維資料的區域流形特征,因此,眾多基于流形學習的非線性降維演算法被廣泛研究,
典型的演算法有:鄰域保持嵌入( Neighborhood PreservingEmbedding , NPE )和區域保留 投影(Locality Preserving Projection,LPP),此類演算法都通過線性嵌入來保留資料的區域流形特征,給出了高維資料到低維資料的映射關系,但僅通過保留原始高維資料的區域流形特征,并不能很好地表征原始高維資料的可分性,于是,基于圖嵌入的降維演算法——邊界 Fisher 分析(Marginal Fisher Analysis,MFA)、區域敏感判別分析(Locality Sensitive Discriminant Analysis ,LSDA)、 判 別最大化邊界投影(Discriminant Maximum Margin Projections,DMMP),相繼被提出 ,
1、MFA理論
MFA通過邊界Fisher準則尋找最佳投影方向 :目標函式如下
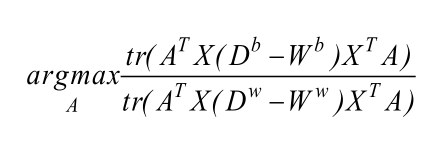
其中:
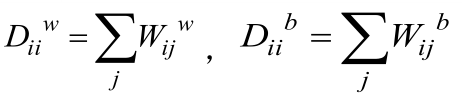
同類近鄰連接權重矩陣:![]() ,根據該矩陣構造本征圖
,根據該矩陣構造本征圖
異類近鄰連接權重矩陣:![]() ,根據該矩陣構造懲罰圖
,根據該矩陣構造懲罰圖
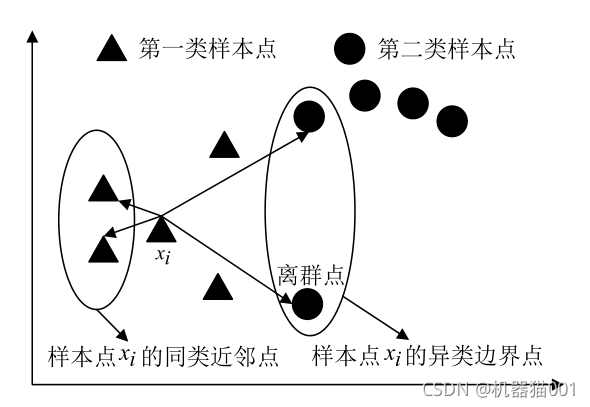
圖1 MFA邊界點分析圖
結合MFA目標函式和邊界點示意圖,可以看出MFA旨在找到一個投影,使得同類近鄰樣本更加緊湊(即目標函式分母更小)和異類近鄰樣本間距離即異類邊界點更遠(目標函式分子更大),以最大化目標函式為目標得到投影矩陣A,
2、理論優缺點分析
2.1 優點
如上述所說,在流形學習基礎上,考慮邊界的問題
2.2 可能存在的不足
①首先這是一種線性映射,不能增加原有資料集的資訊(只可能減少原有資料集的資訊)即不可能提升原有資料集的區分能力,線性降維只是實作用盡可能少的特征去逼近原始資料包含的所有資訊(有用或者干擾資訊),
②MFA對于邊界較為清晰或者是異類樣本重合度不夠高的資料空間應該是有效的,可以想象圖1中兩類樣本點完全雜亂無章融合在一起,這時候樣本的異類邊界和同類邊界也完全融合在一起(目標點與其同類樣本和異類樣本的連接權重接近),根據目標函式,很難找到一組映射使得分子大而分母小,這個時候取得的映射矩陣并不能達到我們想要的效果(當然這種情況下任何線性方法都不一定能做到),
③MFA選擇的異類邊界點與同類邊界點之間沒有直接的關聯(都是獨立尋找,并建立權重矩陣),我們為了兩類樣本盡可能分開,理想情況肯定是異類邊界點與同類邊界點盡可能分離,即應該將這兩種邊界點建立一種聯系,
2.3 改進方向:
根據上述分析改進點如下:
①非線性化
②非線性基礎上如何進一步改進樣本間權重計算方法,避免權重接近情況
③異類邊界和同類邊界關聯化,即本征圖和懲罰圖的構建不應該獨立無關
④其他
3、MFA實作效果
待下文分解
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/337847.html
標籤:其他