如有錯誤,懇請指出,
文章目錄
- 1. Introduction
- 2. Related Work
- 2.1 Efficient Self-attentions
- 2.2 Positional Encoding
- 3. Method
- 3.1 Overall Architecture
- 3.2 Cross-Shaped Window Self-Attention
- 3.3 Locally-Enhanced Positional Encoding
- 3.4 CSWin Transformer Block
- 4. Result
paper:CSWin Transformer: A General Vision Transformer Backbone with Cross-Shaped Windows
code:https://github.com/microsoft/CSWin-Transformer

摘要:
Transformer設計中一個具有挑戰性的問題是,全域自注意力的計算成本非常高,而區域自注意力通常會限制每個token的互動域,為了解決這個問題,作者提出了Cross-Shaped Window的自注意機制,可以并行計算十字形視窗的豎直與水平中的自注意力,其中通過將輸入特征分割成等寬的條帶來得到每個條帶,
其中條帶的寬度必然會對視野產生影響,為此作者對條帶寬度的影響進行了詳細的數學分析,并根據Transformer網路的不同層改變條帶寬度,從而在限制計算成本的同時實作了較強的建模能力,
此外,作者還引入了區域增強位置編碼(local -enhanced Positional Encoding, LePE),它比現有的編碼方案能更好地處理區域位置資訊,而且其能適應不同大小輸入特征,支持任意輸入解決方案,因此對下游任務特別有效和友好,
結合這些設計(Cross-Shaped Window 和 LePE)和層次結構,CSWin Transformer在常見視覺任務上展示了具有競爭力的性能,實作的效果:
- 85.4%Top-1 accuracy on ImageNet-1K without extra data
- 53.9box AP and 46.4 mask AP on the COCO detection task
- 51.7mIOU on the ADE20K semantic segmentation task
- 87.5%Top1 accuracy on ImageNet-1K with pretraining on ImageNet-21K
- segmentation performance on ADE20K with 55.7mIoU with pretrain(SOTA)
1. Introduction
盡管Transformer-based的架構在各方面取得了成功,但是全域注意力機制的Transformer體系結構在計算效率方面是低效的,為了提高效率,一種典型的方法是將每個token的注意區域從全域注意限制為區域/視窗(local/windowed)注意,而為了讓不同的視窗進行聯系,研究人員進一步提出了halo和shift操作,通過附近的視窗交換資訊,但是,這樣的互動資訊使得感受野的擴大比較緩慢,需要堆疊大量的塊來實作全域的自注意力,而足夠多的全域資訊對性能是比較重要的,因此,在保持較低的計算成本的同時,有效地實作大接收域是非常重要的,
為此,作者提出了Cross-Shaped Window(CSWin)自注意力,其結構如下所示,并與現有的自注意機制進行了比較:
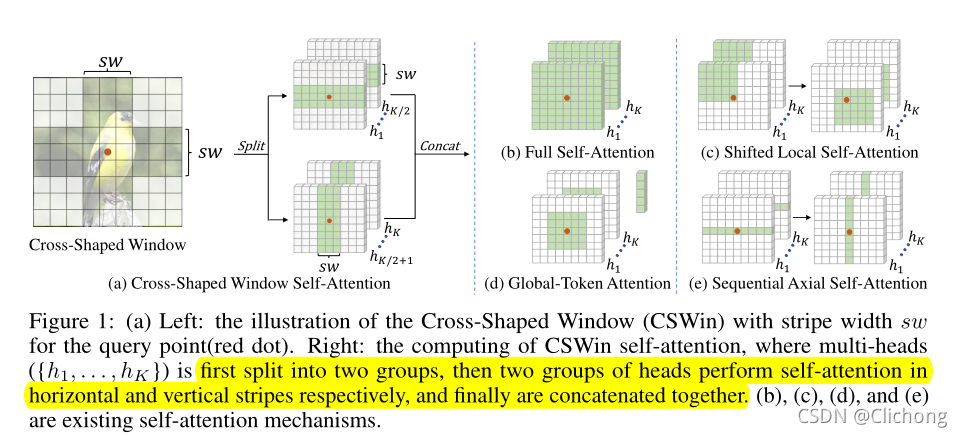
利用CSWin自注意力機制,實作并行地在水平和垂直條帶中進行自注意力計算,每個條帶都是通過將輸入特征分割成等寬的條帶得到的,條帶寬度是十字形視窗的一個重要引數,它可以在限制計算成本的同時實作較強的建模能力,具體上,作者根據網路的深度調整條帶寬度:淺層的寬度較小,深層的寬度較大,較大的條帶寬度可以增強長程元素之間的連接,以較小的計算成本增加獲得更好的網路容量,
值得注意的是,采用CSWin self-attention機制,水平條寬和垂直條寬的自注意是并行計算的,作者將多個頭部分成平行的組,并對不同組進行不同的自注意操作(水平與豎直),這種并行策略沒有引入額外的計算成本,同時擴大了每個Transformer block內計算自注意的區域,
在CSWin self-attention的基礎上,采用分層設計的方法,提出了一種新的通用視覺任務的Vit架構,稱為:CSWin Transformer,為了進一步增強性能,作者還引入了一種有效的位置編碼,區域增強位置編碼(Locally-enhanced Positional Encoding,LePE),其直接對注意力結果進行操作,而不是對注意力計算,LePE使CSWin Transformer對下游任務更加有效和友好,
2. Related Work
2.1 Efficient Self-attentions
如圖1所示,現有的視窗互動的方法有shifted/haloed version(圖c),添加了跨不同區域視窗的互動,還有Axial Self-Attention(圖e),它將區域視窗沿水平軸或垂直軸依次應用,以實作全域關注,但是,它的順序機制和有限的視窗大小限制了它的表示學習性能,
ps:Axial Self-Attention與Cross-Shaped Window比較相像的,但不同的是本文用了一半的head捕獲橫向注意力,另一半的head捕獲縱向注意力,但是Axial Self-Attention的結構是先捕獲橫向注意力、再捕獲縱向注意力,后面的操作是基于前面的操作,所以不能夠并行計算,這就導致模型的計算時間會變長,
2.2 Positional Encoding
由于self-attention是置換不變的,并且忽略了token位置資訊,因此位置編碼在transformer中被廣泛使用,以將這些位置資訊添加回來,典型的位置編碼機制包括絕對位置編碼(APE)、相對位置編碼(RPE)和條件位置編碼(CPE),
APE和RPE通常被定義為一系列頻率或可學習引數的正弦函式,它們是為特定的輸入尺寸而設計的,對變化的輸入解析度不友好,
CPE以該特征作為輸入,可以生成任意輸入解析度的位置編碼,然后將生成的位置編碼添加到輸入特征上(也就是與輸入特征進行一個簡單的相加操作),然后將其輸入到self-attention block中,
LePE與CPE類似,但建議將位置編碼作為一個并行模塊添加到自注意操作中,并對每個Transformer block中的投影值進行操作,該設計將位置編碼與自注意計算解耦,可以增強區域歸納偏差(local inductive bias),
3. Method
3.1 Overall Architecture
CSWin Transformer的總體架構如圖2所示:
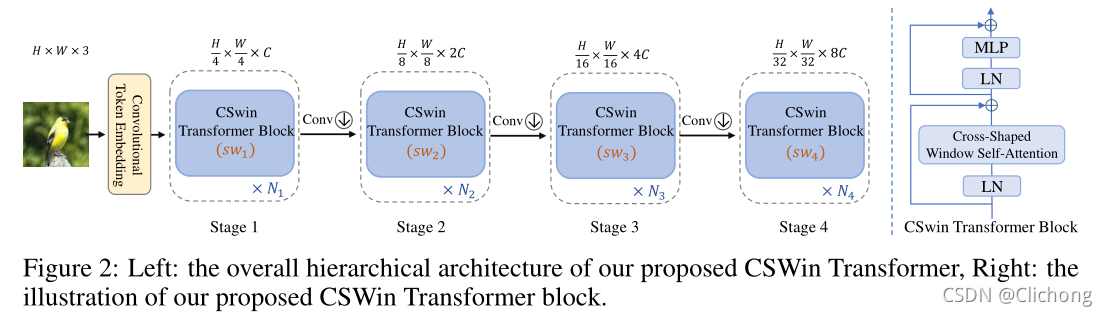
對于大小為HxWx3的RGB影像,首先利用重疊卷積獲取
H
4
×
W
4
\frac{H}{4} \times \frac{W}{4}
4H?×4W?個token(具體通過卷積核大小為7,步長為4的卷積操作獲得,其中的重疊卷積指的就是卷積核大小與步長不同而已),其中每個token的資訊維度為C,為了產生一個層次表示,整個網路由四個階段組成,
兩個相鄰的階段之間使用卷積層(3×3, stride 2)操作,以減少token數量并使通道維數加倍,因此構建的第 i i i層特征圖具有 H 2 i + 1 × W 2 i + 1 \frac{H}{2^{i+1}} \times \frac{W}{2^{i+1}} 2i+1H?×2i+1W?個token,這類似于傳統的CNN主干(所以這個輸出既可以看成是token的集合,也可以看成是特征圖),每個階段由 N i N_{i} Ni?個連續的CSWin Transformer Blocks組成,這不會改變token的數量,
CSWin Transformer Block總體上與multi-head self-attention Transformer block 具有相似的拓撲結構,但有兩個區別:
1)Cross-Shaped Window取代了自注意機制
2)為了引入區域感應偏置,將LePE作為一個并聯模塊加入到自注意分支中
3.2 Cross-Shaped Window Self-Attention
根據MSA機制,輸入特征的每個token會產生K個head,然后每個head在水平或垂直條帶內進行區域自注意,
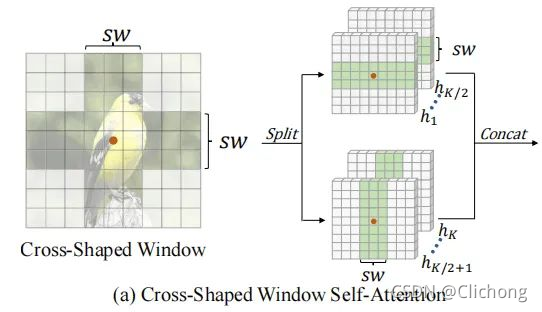
以橫條帶自注意力為例,將X均勻分割成不重疊的橫條紋 [ X 1 , . . . , X M ] [X^{1},...,X^{M}] [X1,...,XM],每個條帶包含著sw x W個token,其中sw是條帶的寬度,可以調整以平衡學習能力和計算復雜度,
其中數學表達為:
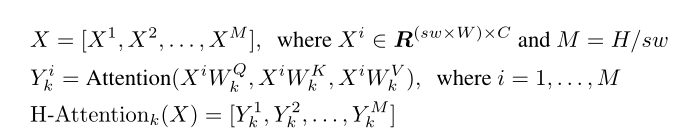
對于豎直條帶自注意力進行類似的操作,
假設自然影像沒有方向偏差,作者將k個head平均分成兩個平行組,第一組的head表現出橫條帶的自注意力,第二組的head表現出豎條帶的自注意力,最后,這兩個并行組的輸出將被連接在一起(也就是concat操作),

通過多頭分組,一個Transformer塊中每個token的注意區域被擴大,
其中, CSWin self-attention的計算復雜度為:
?
(
C
S
W
i
n
_
A
t
t
e
n
t
i
o
n
)
=
H
W
C
?
(
4
C
+
s
w
?
H
+
s
w
?
W
)
?(CSWin\_Attention)=HWC*(4C+sw*H+sw*W)
?(CSWin_Attention)=HWC?(4C+sw?H+sw?W)
3.3 Locally-Enhanced Positional Encoding
SA具有排列不變性(不同排列的輸出結果是一樣的),為了彌補SA的這個缺陷,通常會在Transformer上加入位置編碼,如圖3中展示了一些典型的位置編碼機制:
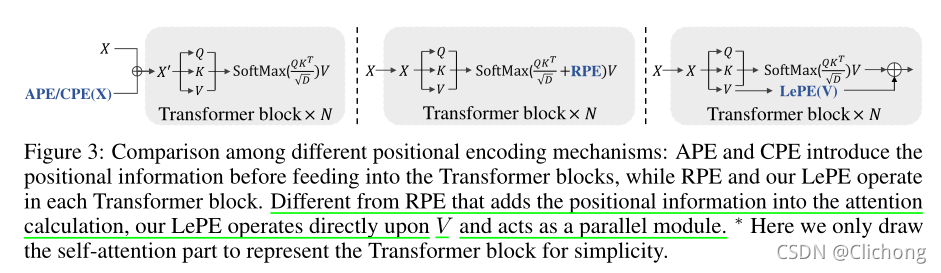
APE/CPE(上圖左)是在進行SA之前就加入了位置資訊,RPE(上圖中)是在計算權重矩陣的程序中加入相對位置資訊,作者采用了一種更加直接的方式進行了位置資訊編碼:直接將位置資訊加入到Value中,然后將結果加到SA的結果中,
作者為了減少計算量,只捕獲了區域的注意力,所以用了一個Depth-wise Conv對value進行卷積,然后將結果加入到了SA的結果中,
由公式:
A
t
t
e
n
t
i
o
n
(
Q
,
K
,
V
)
=
S
o
f
t
M
a
x
(
Q
K
T
/
d
)
V
+
E
V
Attention(Q, K, V) = SoftMax(QK^{T}/\sqrt{d})V + EV
Attention(Q,K,V)=SoftMax(QKT/d
?)V+EV
改變為:
A
t
t
e
n
t
i
o
n
(
Q
,
K
,
V
)
=
S
o
f
t
M
a
x
(
Q
K
T
/
d
)
V
+
D
W
C
o
n
v
(
V
)
Attention(Q, K, V) = SoftMax(QK^{T}/\sqrt{d})V + DWConv(V)
Attention(Q,K,V)=SoftMax(QKT/d
?)V+DWConv(V)
3.4 CSWin Transformer Block
采用上訴的Cross-Shaped Window自注意力與Locally-Enhanced位置編碼方式,CSWin Transformer block可以定義為:
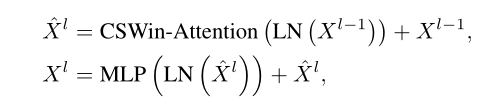
其中
X
l
X^{l}
Xl表示第l個Transformer塊的輸出,如果在每個階段的開始存在,則表示前一個卷積層,
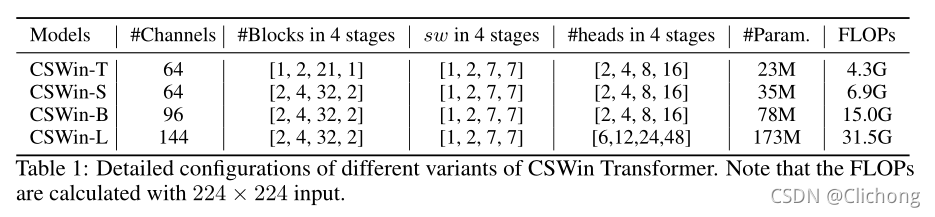
引數設定如下:
4. Result
-
消融實驗:
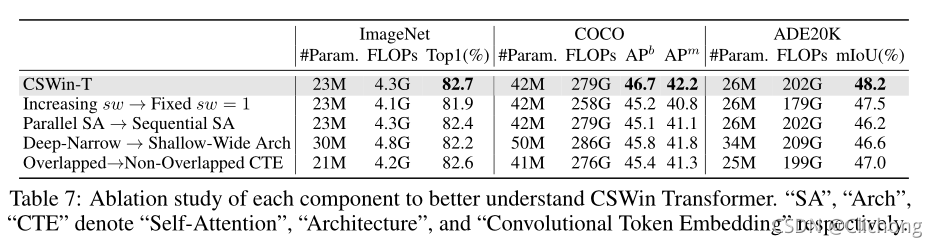
證實了橫豎并行自注意操作與深層結構的效果 -
LePE與CSWin的效果:
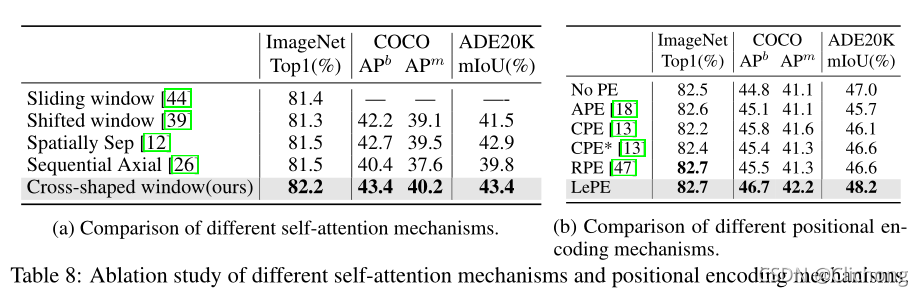
-
ImageNet-1K分類中不同模型的比較:
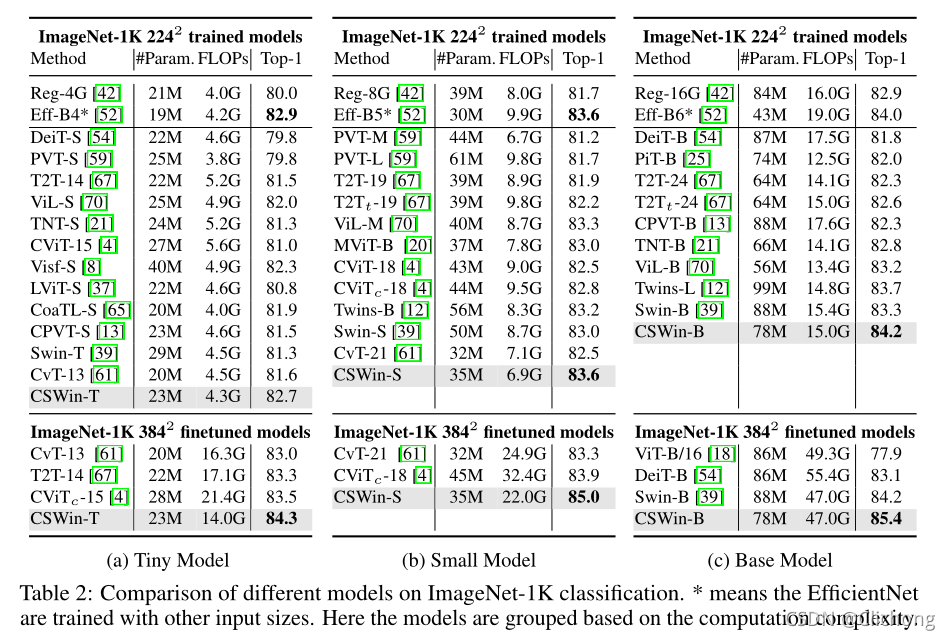
-
ImageNet-1K通過對ImageNet-21K資料集進行預訓練得到微調結果:
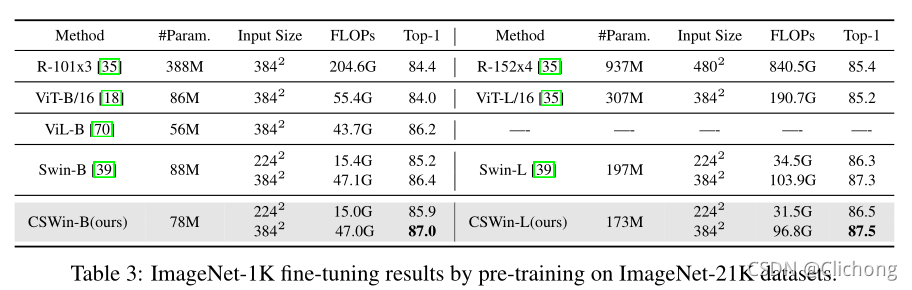
可以看見,在相同引數量下,CSWin Transformer的效果要比Vit與Swin Transformer的效果要好 -
基于Mask R-CNN框架的COCO val2017目標檢測和實體分割性能:
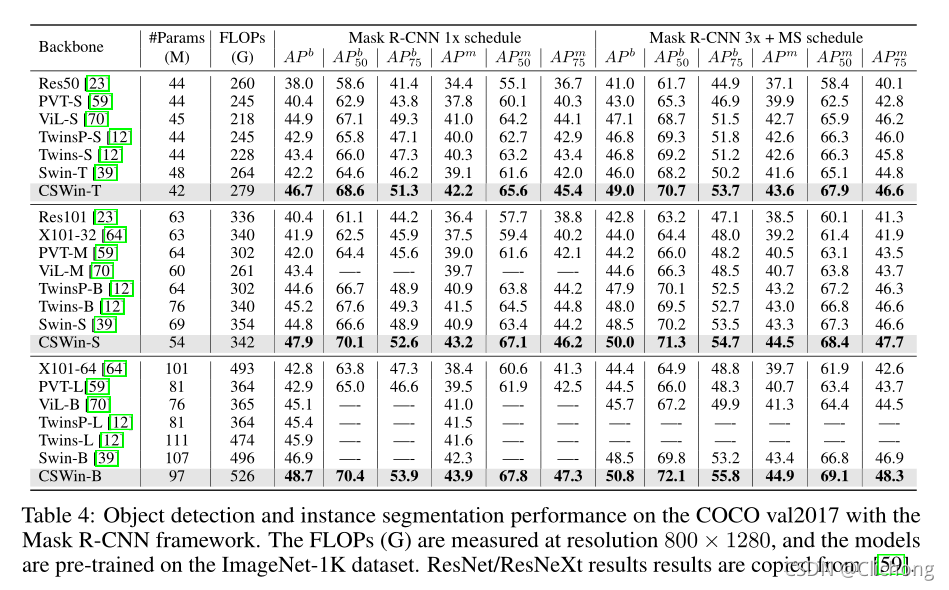
-
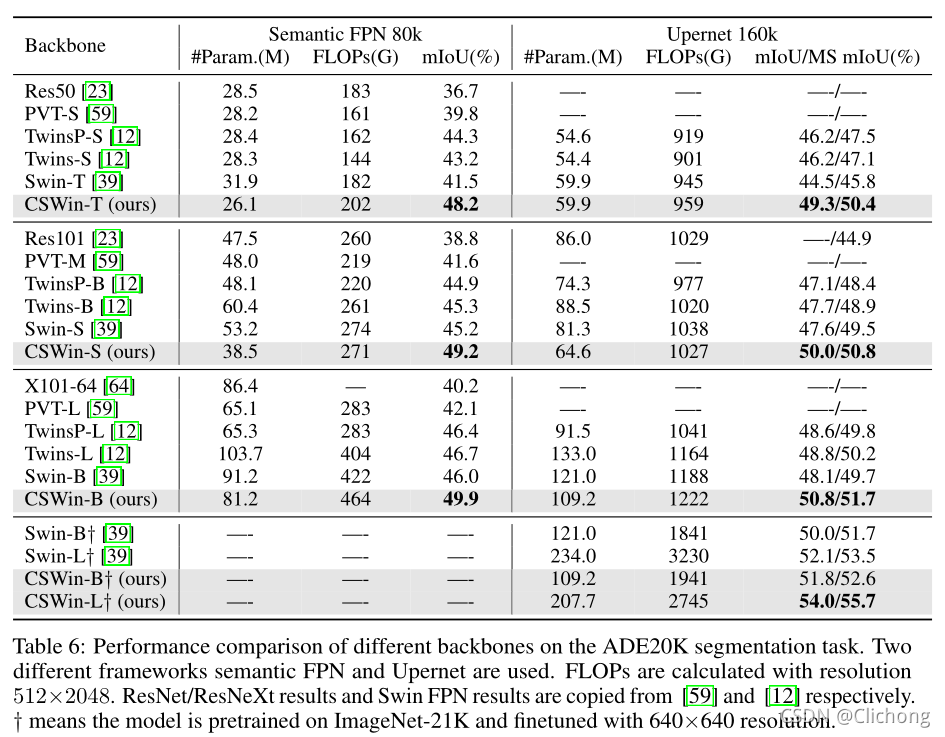
語意分割性能測驗:
總結:
作者提出了一種新的Vision Transformer架構CSWin Transformer,其核心是CSWin Self-Attention,它通過將多個head分成兩個橫豎兩方向上的并行組,在水平和垂直條帶上實作自注意,這樣的設計可以有效地擴大一個Transformer block內每個token的關注范圍,此外,還引入了LePE模塊,直接將位置資訊加入到Value中,
ps:本質上作者在進行下采樣和區域增強的位置編碼時,都用的是卷積,
此外,極市平臺提出了一個想法,這里將head分為了兩組,那分為更多組,每個組還是關注不同的區域,那樣感受野就會更大,對模型的性能是否還會有進一步的提升呢?
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/339006.html
標籤:AI