機器學習演算法學習02:決策樹的學習以及應用決策樹解決Cora資料集論文分類問題
文章目錄
- 機器學習演算法學習02:決策樹的學習以及應用決策樹解決Cora資料集論文分類問題
- 1.前言
- 2.演算法分析
- 2.1演算法概述
- 2.2 演算法優化
- 3.演算法代碼
- 3.1 決策屬性優先級選擇
- 3.1.1 資訊熵
- 3.2.2 資訊增益率
- 3.3.3 基尼系數
- 3.2 資料集的預處理
- 3.3 決策樹的生成
- 3.4 決策樹的分類
- 4.演算法運行與評估
- 4.1 使用資訊增益來劃分資料集
- 4.2 使用資訊增益率劃分資料
- 4.3 使用基尼指數劃分資料
- 5.結語
1.前言
決策樹方法作為非常經典的機器學習方法,曾經一度是作為專家推薦系統的研究方向,在數十年前,那時的部分人工智能學家相信,通過將生活中的事情逐一用邏輯表示,再通過決策樹對這些邏輯的回答進行逐一選擇,最終可以使得機器分辨所有物體,即使到了現在,決策樹系統逐漸退出人工智能應用領域的今天,他的思想還仍然在生活中被應用著,學習并掌握決策樹演算法對我們來說依舊十分重要,本次實驗代碼已發布在GITHUB上,需要的可以上GIT自取:liujiawen-jpg/Decision-Tree: Machine Learn 02 (github.com)
2.演算法分析
2.1演算法概述
決策樹演算法其實用邏輯可以非常簡單的解釋,就是我們將生活中的問題轉化為一個個邏輯問題,我們用下面這張圖來進行解釋:
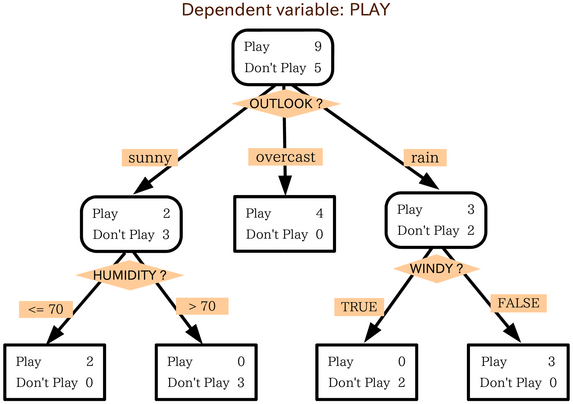
如上圖,我們想要決定今天到底要不要出去外面玩,那么有時候外面天氣可能下雨刮風 或者說非常炎熱,我們可能只想窩在家里打游戲,決策樹模擬了我們這種決策樹程序,我們以最左邊的葉子節點來敘述,首先我們要查看外面的天氣景色(outlook)屬性,發現是晴天,接下來我們判斷濕度是否大于七十,如果大于,很可惜又熱又濕的天氣并不適合我出去玩,只能在家里玩游戲了,但是如果小于七十,那么今天是一個不可多得的好天氣,我們應該出去玩,
通過上面這個案例,我們得知了決策樹演算法的大致流程,是不是覺得他看起來并不是很難,好像過于抽象到連數學公式都很難描述他😂😂😂,但這里其實有一個很重要的因素,那么就是為什么outLook(這里我們稱之為決策屬性)的決策優先級要排在humidity(濕度),windy(刮風的)之前,在這個簡單的例子之前我們還能判斷他的優先級,但是進入一些足夠復雜,決策屬性足夠多的問題時,我們是否還能主觀判斷誰應該作為優先級,所以選擇決策屬性的優先級也變得極為重要(如何判斷優先級,我們留到后面再說),那么到這里決策樹的演算法步驟相信大家就看得出來了:
-
選擇資料集中各個決策屬性的優先級
-
通過各個決策屬性各個優先級,訓練集的資料和標簽用于生成決策樹(這里可以認為是在訓練步驟)
-
將測驗集輸入決策樹,通過各個決策樹的屬性比較,最終由遍歷到的葉子節點的標簽作為測驗結果的標簽
2.2 演算法優化
看似上面的步驟,已經十分完美了,但這里還需要注意一個問題,如果最終測驗資料遍歷下去找到的葉子節點為空怎么辦(即沒有對應的葉子節點),為什么會出現這樣的結果呢?這是很正常的,首先我們需要知道,我們決策樹全部都是基于我們的訓練資料來生成的,我們仍然用上面的決策樹進行舉例:
如果我們的訓練集中沒有出現Humidity(濕度)<=70的時候,即生成的決策樹中不存在最左邊的葉子節點的時候,但我們測驗的時候遇到了這種結果我們應該如何解決?我們的演算法應該回傳什么結果 ,總不能回傳對不起無查詢結果而回傳吧,這個時候前人提出了一個改進方法,當查詢到的葉子節點為空時,演算法統計該空節點的兄弟節點中出現最多的類別作為我們回傳的類別,
比如上圖這種出現情況最左邊的葉子節點為空的時候,我們統計他的兄弟節點發現只有一個節點他的類別是不出去玩,那么我們就放心地選擇不出去玩算了(雖然你發現這樣的結果和真實相悖,但沒辦法訓練集如果沒有辦法包括所有情況的話,我們只能使用類似投票表決的方法來決定了),那么改良后的步驟就調整為這樣:
- 選擇資料集中各個決策屬性的優先級
- 通過各個決策屬性各個優先級,訓練集的資料和標簽用于生成決策樹(這里可以認為是在訓練步驟)
- 將測驗集輸入決策樹,通過各個決策樹的屬性比較,最終由遍歷到的葉子節點的標簽作為測驗資料的結果,如果遍歷到的葉子節點為空,則統計該空節點的兄弟節點中出現次數最多的標簽,作為測驗資料的輸出結果,
那么到這里演算法陳述完了,接下來我們需要使用代碼對于上述演算法的實作,
3.演算法代碼
3.1 決策屬性優先級選擇
在之前,我們說過一個資料擁有非常多的屬性,選擇各個屬性在決策樹節點中的優先級變得尤為重要,但是到呼叫什么標準去劃分,用什么公式去劃分顯得尤為重要,這里我使用了三種方法用于進行資料集的劃分:
3.1.1 資訊熵
資訊熵是由資訊論之父香農提出的,他認為資料的混亂程度是可以進行量化的,于是提出了資訊熵的概念,對于資料U我們對的資訊熵定義如下:
H
(
U
)
=
E
[
?
log
?
p
i
]
=
?
∑
i
=
1
n
p
i
log
?
p
i
H(U)=E\left[-\log p_{i}\right]=-\sum_{i=1}^{n} p_{i} \log p_{i}
H(U)=E[?logpi?]=?∑i=1n?pi?logpi?
這里做出解釋,n為資料中的類別, p i p_i pi?為i類別出現的概率, l o g p i logp_i logpi?為以2為底數 p i p_i pi?為真值的結果,對每個類我們計算這兩種結果,并將求他們的乘積之和作為該資料集的資訊熵,資訊熵代表資料集的混亂程度,下面我們撰寫代碼來將該公式來實作:
#計算資訊熵
def calcShannonEnt(dataSet, method = 'none'):
numEntries = len(dataSet)
labelCount = {}
for feature in dataSet:
if method =='prob': #統計資訊增益率時使用
label = feature
else:
label = feature[-1] #輸入資訊默認最后一維為標簽
if label not in labelCount.keys():
labelCount[label]=1
else:
labelCount[label]+=1
shannonEnt = 0.0
for key in labelCount:
numLabels = labelCount[key]
prob = numLabels/numEntries
shannonEnt -= prob*(log(prob,2))
return shannonEnt
通過上述代碼,我們便可以將一個資料集的資訊熵計算出來,那么回到我們原來的問題上,我們如何通過計算資訊熵來確定決策屬性的優先級呢?這里我們還需要一個資訊增益增益:
Gain
?
(
D
,
a
)
=
Ent
?
(
D
)
?
∑
v
=
1
V
∣
D
v
∣
∣
D
∣
Ent
?
(
D
v
)
\operatorname{Gain}(D, a)=\operatorname{Ent}(D)-\sum_{v=1}^{V} \frac{\left|D^{v}\right|}{|D|} \operatorname{Ent}\left(D^{v}\right)
Gain(D,a)=Ent(D)?v=1∑V?∣D∣∣Dv∣?Ent(Dv)
也就是對每個可以用來決策的屬性,我們都用它劃分資料集后并計算劃分后的資訊熵,然后用總的資料集的資訊熵減去該資訊熵,這我們稱之為該屬性的資訊增益,可以發現當該屬性劃分后的資料集的混亂程度越低(也就是說使用他劃分后效果好),資訊熵越低,則它所帶來的的資訊增益也會越大,所以我們遍歷所有決策屬性計算他們的資訊增益,選取資訊增益的大小作為我們劃分資料屬性的優先級:
#使用決策屬性劃分資料集,會將資料集axis維度的值等于value的值的資料集切出來
def splitDataSet(dataSet, axis, value): #劃分資料集
retDataSet = []
for featVec in dataSet:
if featVec[axis] == value:
reducedFeatVec = featVec[:axis]
reducedFeatVec.extend(featVec[axis+1:])
# 去掉對應位置的特征
retDataSet.append(reducedFeatVec)
return retDataSet
#選擇最佳劃分資料集的屬性
def chooseBestFeatureToSplit(dataSet):
numFeatures = len(dataSet[0]) -1 #最后一個位置的特征不算
baseEntropy = calcShannonEnt(dataSet) #計算資料集的總資訊熵
bestInfoGain = 0.0
bestFeature = -1
for i in range(numFeatures):
featList = [example[i] for example in dataSet]
uniqueVals = set(featList)
newEntropy = 0.0
for value in uniqueVals:
# 通過不同的特征值劃分資料子集
subDataSet = splitDataSet(dataSet, i, value)
prob = len(subDataSet)/float(len(dataSet))
newEntropy += prob *calcShannonEnt(subDataSet)
infoGain = baseEntropy - newEntropy #計算每個資訊值的資訊增益
if(infoGain > bestInfoGain): #資訊增益最大的作為
bestInfoGain = infoGain
bestFeature = i
return bestFeature #回傳資訊增益的最佳索引
3.2.2 資訊增益率
但是資訊增益其實是有偏向性的,他十分偏向于擁有更多選擇的決策屬性(如果我們將資料編號拿來也作為決策屬性毫無疑問他將作為第一優先級的決策屬性)這也導致了部分情況下決策樹正確率受到了影響,那么學者又提出了一個新的資料劃分方法–資訊增益率(Gain ratio),也就是是在原有資訊增益的情況下我們多考慮一個對于屬性內部也計算一次資訊熵:
Gain
?
ratio
?
(
D
,
a
)
=
Gain
?
(
D
,
a
)
IV
?
(
a
)
\operatorname{Gain} \operatorname{ratio}(D, a)=\frac{\operatorname{Gain}(D, a)}{\operatorname{IV}(a)}
Gainratio(D,a)=IV(a)Gain(D,a)?
I V ( a ) = ? ∑ v = 1 V ∣ D v ∣ ∣ D ∣ log ? 2 ∣ D v ∣ ∣ D ∣ \mathrm{IV}(a)=-\sum_{v=1}^{V} \frac{\left|D^{v}\right|}{|D|} \log _{2} \frac{\left|D^{v}\right|}{|D|} IV(a)=?v=1∑V?∣D∣∣Dv∣?log2?∣D∣∣Dv∣?
也就是說,我們也需要對內部再次進行一次劃分并用類似資訊熵的方式來求IV(a):
def calcShannonEnt(dataSet, method = 'none'):
numEntries = len(dataSet)
labelCount = {}
for feature in dataSet:
if method =='prob': #當引數為prob時轉而計算資訊增益率
label = feature
else:
label = feature[-1]
if label not in labelCount.keys():
labelCount[label]=1
else:
labelCount[label]+=1
shannonEnt = 0.0
for key in labelCount:
numLabels = labelCount[key]
prob = numLabels/numEntries
shannonEnt -= prob*(log(prob,2))
return shannonEnt
def chooseBestFeatureToSplit3(dataSet): #使用資訊增益率進行劃分資料集
numFeatures = len(dataSet[0]) -1 #最后一個位置的特征不算
baseEntropy = calcShannonEnt(dataSet) #計算資料集的總資訊熵
bestInfoGain = 0.0
bestFeature = -1
for i in range(numFeatures):
featList = [example[i] for example in dataSet]
newEntropyProb = calcShannonEnt(featList, method='prob') #計算內部資訊增益率
uniqueVals = set(featList)
newEntropy = 0.0
for value in uniqueVals:
# 通過不同的特征值劃分資料子集
subDataSet = splitDataSet(dataSet, i, value)
prob = len(subDataSet)/float(len(dataSet))
newEntropy += prob *calcGini(subDataSet)
newEntropy = newEntropy/newEntropyProb
infoGain = baseEntropy - newEntropy #計算每個資訊值的資訊增益
if(infoGain > bestInfoGain):
bestInfoGain = infoGain
bestFeature = i
return bestFeature #回傳資訊增益的最佳索引
3.3.3 基尼系數
基尼系數,相信大家并不陌生,各個新聞中也經常出現,它經常被用于衡量國家的貧富差距,在CART決策樹中,作者采用他來作為決策屬性劃分的依據,在這里就讓我們揭開他的神秘面紗,一起來看看他具體是如何計算的,對于資料集D我們定義基尼系數如下:
Gini
?
(
D
)
=
∑
k
=
1
∣
Y
∣
∑
k
′
≠
k
p
k
p
k
′
=
1
?
∑
k
=
1
∣
Y
∣
p
k
2
\begin{aligned} \operatorname{Gini}(D) &=\sum_{k=1}^{|\mathcal{Y}|} \sum_{k^{\prime} \neq k} p_{k} p_{k^{\prime}} \\ &=1-\sum_{k=1}^{|\mathcal{Y}|} p_{k}^{2} \end{aligned}
Gini(D)?=k=1∑∣Y∣?k′?=k∑?pk?pk′?=1?k=1∑∣Y∣?pk2??
p
k
p_k
pk?代表第資料集為K個類別的概率,也就是求資料集中某個決策屬性出現的所有類別概率的平方和,最后與1作差獲得結果,那么如何對于們每個決策屬性我們還需要再計算一個關于他們的基尼指數,如對于屬性a,我們計算他的基尼指數:
G
i
n
i
n
d
e
x
(
D
,
a
)
=
∑
v
=
1
V
∣
D
v
∣
∣
D
∣
Gini
?
(
D
v
)
Ginindex (D, a)=\sum_{v=1}^{V} \frac{\left|D^{v}\right|}{|D|} \operatorname{Gini}\left(D^{v}\right)
Ginindex(D,a)=v=1∑V?∣D∣∣Dv∣?Gini(Dv)
也就會我們還需要計算每個條件占所有資料集的概率并與之相乘,同時在書寫代碼有一個注意事項就是,基尼指數越小代表資料集差異越大,所以區別于之前的選擇標準,這里我們認為資料集越小越符合選擇標準:
def calcGini(dataset):
feature = [example[-1] for example in dataset]
uniqueFeat = set(feature)
sumProb =0.0
for feat in uniqueFeat:
prob = feature.count(feat)/len(uniqueFeat)
sumProb += prob*prob
sumProb = 1-sumProb
return sumProb
def chooseBestFeatureToSplit2(dataSet): #使用基尼系數進行劃分資料集
numFeatures = len(dataSet[0]) -1 #最后一個位置的特征不算
bestInfoGain = 0.0
bestFeature = np.Inf
for i in range(numFeatures):
featList = [example[i] for example in dataSet]
uniqueVals = set(featList)
newEntropy = 0.0
for value in uniqueVals:
# 通過不同的特征值劃分資料子集
subDataSet = splitDataSet(dataSet, i, value)
prob = len(subDataSet)/float(len(dataSet))
newEntropy += prob *calcGini(subDataSet)
infoGain = newEntropy
if(infoGain < bestInfoGain): # 選擇最小的基尼系數作為劃分依據
bestInfoGain = infoGain
bestFeature = i
return bestFeature #回傳決策屬性的最佳索引
3.2 資料集的預處理
在此次我們資料集選擇的是著名的圖神經網路分類資料集Cora論文分類資料集(關于他的詳細介紹可以查看我的博客(5條訊息) 圖神經網路學習01:圖卷積神經網路GCN實戰解決論文分類問題(tensorflow實作)_theworld666的博客-CSDN博客),該資料集收集了六個學術方向的2708篇論文,利用1433個關鍵詞對他進行編碼,大概意思就是假設是神經網路方向相關論文,那么學習率,神經網路,模型,這些詞應該會出現得比較頻繁,反過來我們也可以認為當出現這些詞時這篇論文大概率是神經網路方向的學術論文🖖,我們可以先決議一下他的資料:
import pandas as pd
import numpy as np
data=pd.read_csv('cora/cora.content',sep = '\t',header=None) #讀取資料查看
data.head() #查看資料前五項
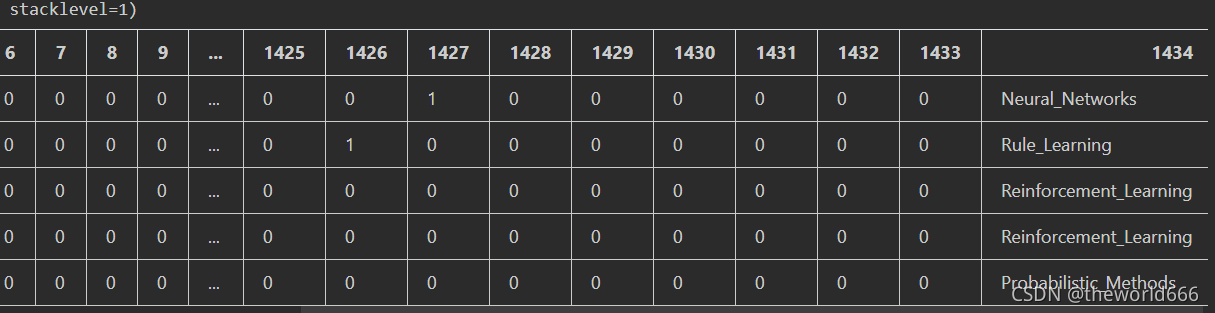
該資料集利用1433個關鍵詞對論文進行編碼,該關鍵詞出現就是1,沒出現就是0,同時給每個論文貼上他們屬于什么學術方向的標簽,這里我們可以利用pandas的方法查看一下到底每個標簽的數量如何:
feature=data.iloc[:,-1]
feature.value_counts()
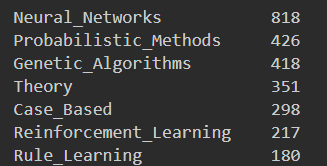
可以看到有七類其中關于神經網路的學術論文最多,達到了818個(可見火熱),這就是我們希望決策樹最終輸出的真值,那么接下來我們需要先處理一下資料集,這里由于我使用的決策樹演算法代碼的資料輸入形式,我將整個資料轉換為串列的形式:
def load_Cora():
dataSet=pd.read_csv('cora/cora.content',sep = '\t',header=None)
feature = dataSet.iloc[:,1:] #第一列是論文編號,我們不需要所以截取第一列之后的資料
feature = np.array(feature)
dataList = feature.tolist() #先轉換成向量再轉換為串列
label = [i for i in range(len(dataList[0])-1)] # 這里的標簽是用于索引屬性使用的
return dataList,label
通過以上的步驟我們完成了構建決策樹的準備步驟:
- 撰寫資料劃分代碼,選擇決策屬性方法代碼
- 完成了資料預處理
接下來,我們開始進入決策樹代碼的核心重點–如何通過訓練資料生成我們的決策樹
3.3 決策樹的生成
雖然名字是決策樹,看起來像是依靠需要樹形結構來構造的,但實際上我們為了更方便的取出資料同時也是因為可能出現兩個以上子節點的情況,這里我們不使用樹形結構表達決策樹,我們使用字典結構來存盤決策樹,那么如何使用字典結構來表達一個樹形結構呢?這里我們用一個例子來闡述如下圖:
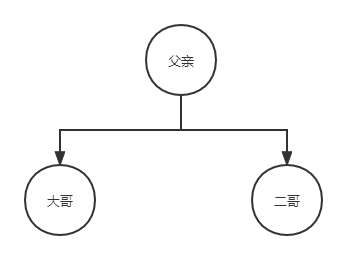
那么我們可以將根節點付清作為key 創建一個這樣的字典{父親:{左:大哥,右:二哥}},如果二哥也有自己的子節點,我們也可以按照這個樣子繼續嵌套字典,從而來表達一個樹形結構,于是我們撰寫創建決策樹代碼如下
def createTree(dataSet, labels):
classList = [example[-1] for example in dataSet]
# 獲取資料集的對應標簽序列
if classList.count(classList[0]) == len(classList):
return classList[0] # 當所有特征的類別都相同時停止劃分
if len(dataSet[0]) == 1: #當遍歷完是所有特征的時候回傳出現次數最多的類別
return majorityCnt(classList)
bestFeat = chooseBestFeatureToSplit(dataSet)#選擇最容易劃分的資料集
bestFeatLabel = labels[bestFeat]
myTree = {bestFeatLabel:{}}
del(labels[bestFeat]) # 洗掉對應位置的標簽
featValues = [example[bestFeat] for example in dataSet]
uniqueVals = set(featValues) #獲取該列特征值的所有不同的特征值
for value in uniqueVals: #利用該列的特征值來創造樹
subLabels = labels[:] #拷貝整個標簽
#遞回構造字典
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value), subLabels)
return myTree
這里需要注意一件事,就是按照上面的代碼我們生成的決策樹字典資料他的生命周期是維持到程式結束為止的,也就是下次我們還需要重新構造,但當決策屬性過多,比如本次使用資料集1433個決策屬性,我們每個屬性取值為0,1,那么我們的資料的大小就有將近2的1400次方左右這實在是太大了,所以為了資料集重復利用,我們還需要對資料進行存盤以及匯入:
import pickle
def storeTree(inputTree,filename):
with open(filename,'wb') as f: #將資料集使用二進制存盤
pickle.dump(inputTree,f)
def reloadTree(filename):
fr = open(filename, 'rb')#讀取時也需要使用二進制方式
return pickle.load(fr)
3.4 決策樹的分類
至此我們已經創造了決策樹結構,那么如何使用這個節點進行分類,以及如何使用我們之前提到的當查找到的節點為空該如何處理的步驟呢,讓我們繼續往下看:
#運用決策樹進行分類
def classify(inputTrees, featLabels, testVec):
firstStr = list(inputTrees.keys())[0]
secondDict = inputTrees[firstStr]
featIndex = featLabels.index(firstStr) #尋找決策屬性在輸入向量中的位置
classLabel = -1 #-1是作為flag值
for key in secondDict.keys():
if testVec[featIndex] == key: #如果對應位置的值與鍵值相等
if type(secondDict[key]).__name__ == 'dict':
#繼續遞回查找
classLabel = classify(secondDict[key],featLabels, testVec)
else:
classLabel = secondDict[key] #查找到子節點則回傳子節點的標簽
#標記classLabel為-1當回圈過后若仍然為-1,表示未找到該資料對應的節點則我們回傳他兄弟節點出現次數最多的類別
return getLeafBestCls(inputTrees) if classLabel == -1 else classLabel
#求該節點下所有葉子節點的串列
def getLeafscls(myTree, clsList):
numLeafs = 0
firstStr = list(myTree.keys())[0]
secondDict = myTree[firstStr]
for key in secondDict.keys():
if type(secondDict[key]).__name__ == 'dict':
clsList =getLeafscls(secondDict[key],clsList)
else:
clsList.append(secondDict[key])
return clsList
#回傳出現次數最多的類別
def getLeafBestCls(myTree):
clsList = []
resultList = getLeafscls(myTree,clsList)
return max(resultList,key = resultList.count)
4.演算法運行與評估
完成了以上代碼的書寫我們就撰寫運行程式將這上面的代碼整合起來:
from tree import *
from treePlotter import * #這個是用于可視化的代碼庫
import pandas as pd
import numpy as np
import sys
if __name__ == '__main__':
np.random.seed(1) #固定種子使得每次打亂的結果都一致,方便控制變數用于測驗
dataSet,label = load_Cora() #匯入資料集
train_num = int(len(dataSet)*0.8) #使用百分之八十得到資料進行訓練,百分之二十資料驗證
train_data = dataSet[:train_num]
test_data = dataSet[train_num+1:]
trainTree = createTree(train_data,label) #利用資料集標簽創建二叉樹
storeTree(trainTree,'CORATree.txt') #將決策樹存盤進入TXT檔案
# trainTree = reloadTree('CORATree.txt') #匯入存盤好的樹
createPlot(trainTree)#繪畫二叉樹
test_labels = [i for i in range(1433)]
errCount = 0.0
for data in test_data:
testVec = data[:-1]
result = classify(trainTree,test_labels, testVec) #獲得分類結果
if result!=data[-1]: #統計錯誤個數
errCount+=1.0
prob = (1-(errCount/len(test_data)))*100 #計算準確率
print(prob)
這里我們還可以查看一下可視化代碼,可以發現決策屬性(足足有1433個決策屬性)過多也導致了最終枝條過多,圖的可視化效果不是很好,
在評估演算法正確率的時候,需要闡明我是怎么判斷演算法到底對模型有沒有用,比如一個二分類問題,你說演算法正確率達到百分之52左右,那么就說明你這個演算法基本沒用,因為我瞎猜二分類正確率也在百分之五十左右,反之如果是六分類,七分類問題你達到百分之五十,就說明你的演算法的確發揮了一定作用,因為這正確率遠比瞎猜高(😂😮),這次資料集共有七個分類,所以我們正確率達到百分之五十其實已經證明演算法的準確了,
4.1 使用資訊增益來劃分資料集
當使用資訊增益時,決策樹如下:

正確率更穩定在64.95
4.2 使用資訊增益率劃分資料
決策樹如下:
正確率穩定在 49.95左右
4.3 使用基尼指數劃分資料
可視化決策樹如下:

準確率穩定在67左右,
通過以上三種演算法比較,我們發現,基尼指數劃分資料集的準確率最高百分之六十七左右,反而是資訊增益率改良后的決策樹準確率最低只有49左右(可能是因為此次所有決策屬性的值只有0和1,所有資訊增益率其實并不適用),但整體準確率其實較低,這說明決策樹其實不太適合決策屬性過多的條件下,
5.結語
通過此次決策樹的學習和代碼的運行,我掌握了決策樹基礎演算法的邏輯,和如何決議資料使得資料符合決策樹演算法輸入,決策樹的演算法不需要調整過多的引數,同時演算法的可解釋性也非常的強,但決策樹的缺點也同樣在此次實驗中暴露出來了,當決策屬性過多,整個決策樹的演算法的開銷將會膨脹到非常大,同時這樣擴展出來的資料集也容易達到過擬合的狀態,于是學者之后還研發出來了預剪枝,和后剪枝等技術,以及使用隨機森林演算法來解決這些相關問題,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/339009.html
標籤:AI