K-means聚類及相關理論介紹
- 什么是K-Means聚類方法
- Kmeans聚類演算法流程
什么是K-Means聚類方法
將Kmeans聚類分為兩部分進行介紹:
- 聚類:所謂聚類就是將資料集中的資料,根據某部分特性進行類別的劃分,
- 聚類流程:
- 資料準備,將需要聚類的資料集進行一些預處理,如歸一化、正則化、降維等
- 特征選取,定義需要聚類的特征,比如狗的分類中,都有尖尖的耳朵,
- 特征提取,提取到關鍵的特征
- 聚類,根據類似特征,對資料進行分類
- 效驗,對最終聚類的結果進行效驗并調整 - Kmeans:kmeans就是經典且有效的聚類演算法,
主要思想:計算各個資料的之間的聚類,并將這幾個類別分為K個類別,
具體:準備一個資料集和人為設定的聚類數目K值(在YOLO系列中Anchor聚類的數目為9,這是精確度和速度的均衡);選取K個物件作為開始的聚類中心,然后計算每個物件與聚類中心之間的聚類,將物件分配到對應的聚類中心;分配完成之后,在重復計算以滿足設定的某個條件,
Kmeans聚類演算法流程
-
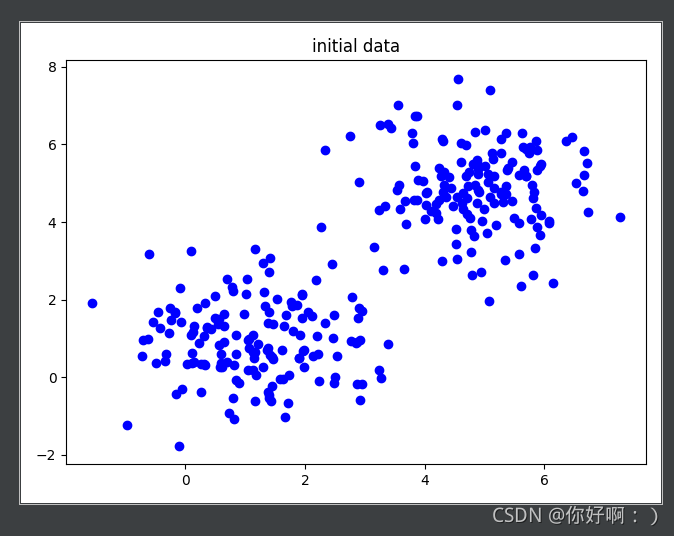
1 隨機初始化資料
-
-
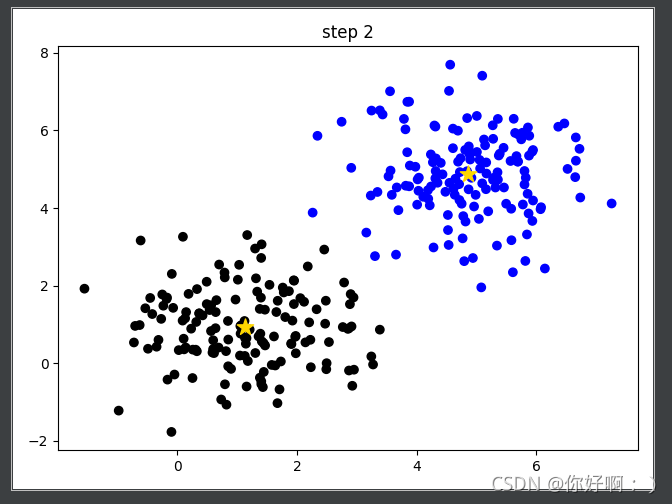
2 生成兩個聚類中心(第一次是隨機生成的),將每個類別計算距離距離中心的距離,進行分類,
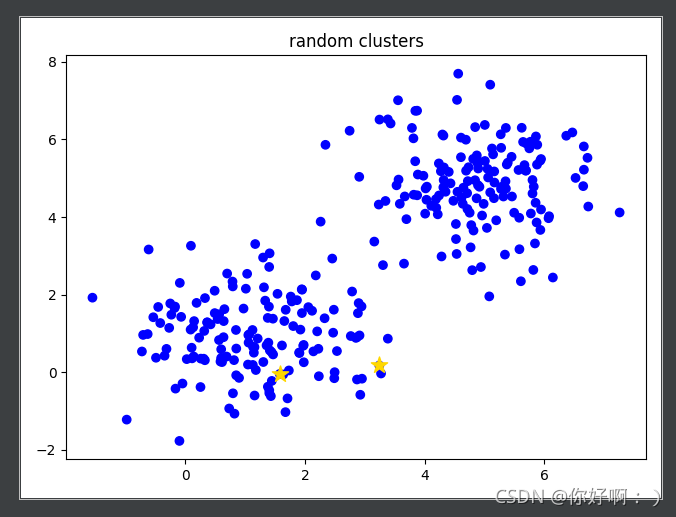
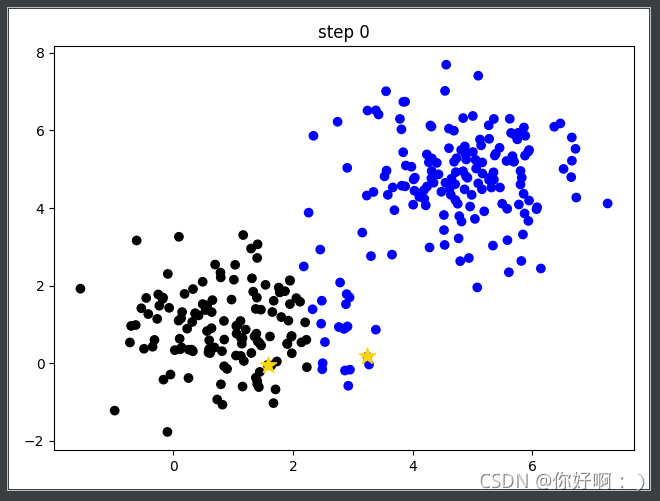
-
3 計算每個聚類中心的平均值(如:X坐標/Y坐標的均值作為新的聚類中心),生成新的聚類中心,再對按照聚類中心的距離重新分類,
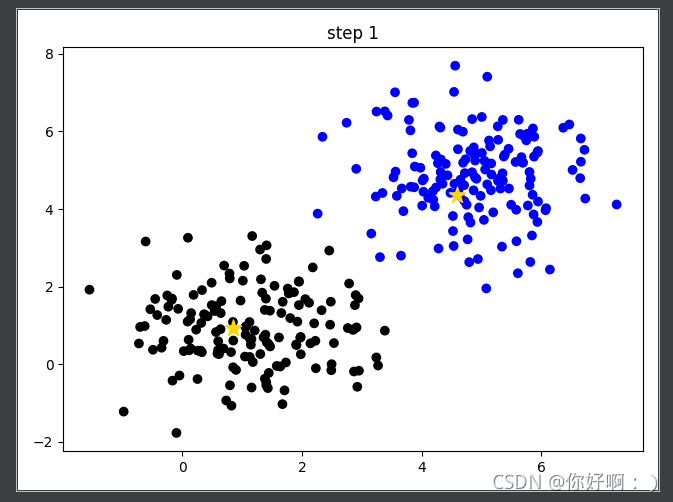
-
不斷重復,最終沒什么變化或者滿足閾值調節終止,即算到最優情況
-
!!!end!!!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/339011.html
標籤:AI