MapReduce概述:
MapReduce最早是在Google的論文中提出的,但是對應的代碼并沒有開源,從2004年Google公開發布MapReduce論文到2012為止,MapReduce已經成長為被廣泛采用的分布式資料處理的業界標準,
MapReduce是一種思想,總結也就是:“分而治之,迭代匯總”
MapReduce簡介:
Hadoop MapReduce將作業分成一系列運行在分布式集群中的map任務和reduce任務,每個任務都作業在指定的小的資料子集上,因此負載是遍布集群中各個節點上的,其中:
map:負責資料的載入,決議,轉換,過濾
reduce:負責處理map任務的輸出結果的一個子集(reducer任務從mapper任務處2復制map任務的中間資料,進行聚合和分組操作)
map:
任務可以細分為:record reader、 mapper 、combiner、partitioner 四個階段
map任務的輸處被稱為中間建和中間值,會發送到reducer做后續的處理,map任務運行的節點會優先選擇資料所在的節點,因此,一般可以通過在本地機器上進行計算來減少資料的網路傳輸,
reduce:
任務可以細分為:混排、排序、reducer、輸出格式 四個階段
MapReduce資料型別與格式:
1.內置資料型別:
hadoop內置資料型別 主要有:
(1)BooleanWritable:標準布爾型數值
(2)ByteWritable:單字數值
(3)DoubleWritable:雙位元組數
(4)FloatWritable 浮點數
(5)IntWritable:整型數;
(6) LongWritable: 長整型數;
(7) Text:適用UTF8格式存盤的文本
(8) NullWritable:null值;
(9)ArrayWritable:Writable型別的陣列
2.用戶自定義資料型別:
第一個基本要求:
實作writable介面,以便資料能被序列化后完成網路傳輸或檔案輸入\輸出
第二個基本要求:
若該資料需作為主鍵key使用or需比較值大小時,則需實作WritableComparable介面,
3.資料輸入格式:(InputFormat)
用于描述MapReduce作業的資料輸入規范,MapReduce框架依靠資料輸入規范檢查,對資料檔案進行輸入分塊(InputSplit),及提供輸入分塊中將資料逐一讀出并轉換為map程序的輸入鍵值對等功能,
最常用的資料輸入格式包括:TextInputFormat
KeyValueTextInput
4.MapReduce架構:“分而治之”分解與結果的匯總
資料分片:
兩個重要的函式:map和reduce函式
map:把任務分解成多個任務
reduce:負責把分解后的多任務處理的結果匯總起來
這兩個函式的具體功能由用戶根據自己的需求設計,只要按照用戶自定義的規則,將輸入的<key,value>對轉換成另一個或一批<key,value>對輸出即可,
理解:整體程序的目標就像是做果醬一樣,map程序就是負責把需要的水果,分別切碎,這就是各自作用在這些物體上的一個Map操作,所以你給Map一個橘子,Map就會把它切碎, 同樣的,你把芒果,番茄一一地拿給Map,你也會得到各種碎塊, 所以,當你在切像果蔬時,你執行就是一個Map操作,Reduce(化簡):在這一階段,你將各種果碎都放入研磨機里進行研磨,你就可以得到一瓶果醬了,這意味要制成一瓶果醬,你得研磨所有的原料,因此,研磨機通常將map操作的果蔬碎聚集在了一起,
MapReduce處理大資料集的程序:
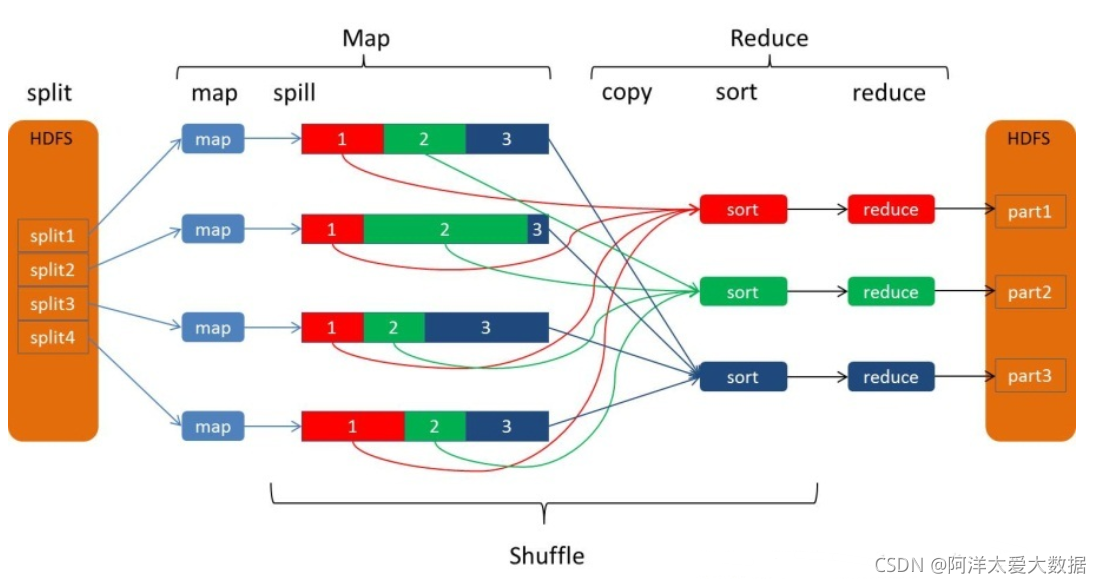
在map階段:
MapReduce框架將任務的輸入資料分割成固定大小的片段(splits),隨后將每個split進一步分解成批鍵值對<K1, V1>,Hadoop 為每一個 split 創建一個 map任務(以下簡稱Mapper)用于執行用戶自定義的map函式,并將對應split中的<K1, V1>對作為輸人,得到計算的中間結果<K2, V2>,接著將中間結果按照K2進行排序,并將key值相同的value放在一起形成一個新的表,形成<K2, list( V2)>元組,最后再根據key值的范圍將這些元組進行分組,對應不同的reduce任務(簡稱reducer)
總的來說:其中collect和spill是屬于shuffle階段,而shuffle是橫跨map和reduce階段的(會在后文中提到)
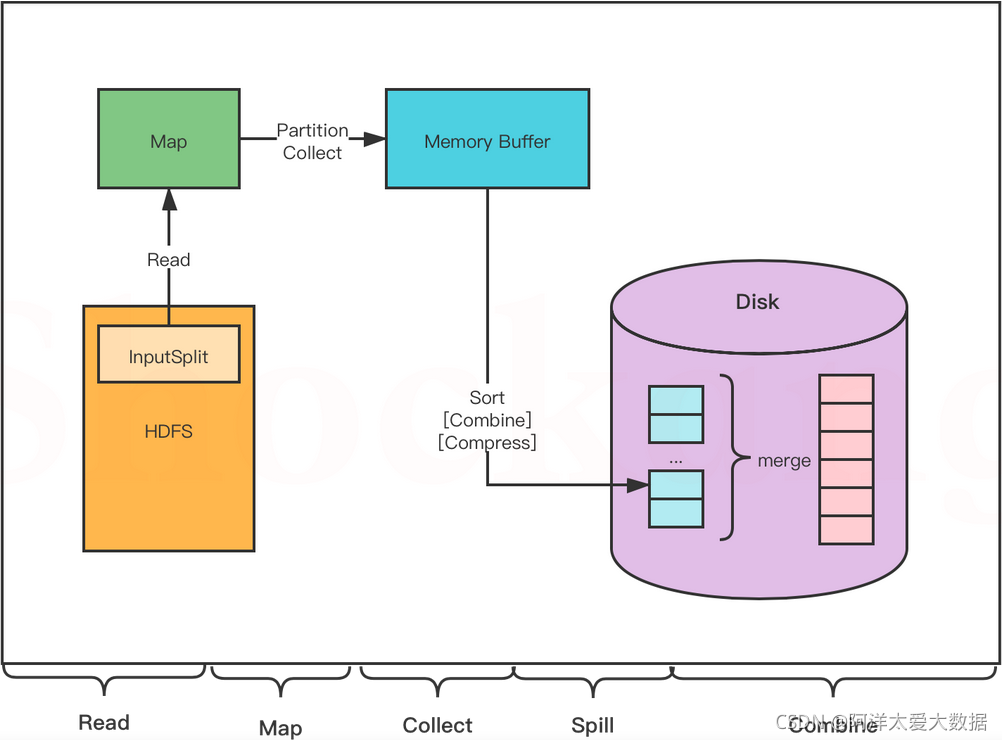
1. Read 階段: MapTask 通過用戶撰寫的 RecordReader ,從輸入的 InputSplit 中決議出一個個 key / value ,
2. Map 階段:將決議出的 key / value 交給用戶撰寫的 Map ()函式處理,并產生一系列新的 key / value ,
3. Collect 階段:在用戶撰寫的 map() 函式中,資料處理完成后,一般會呼叫 outputCollector.collect() 輸出結果,在該函式內部,它會將生成的 key / value 分片(通過呼叫 partitioner ),并寫入一個環形記憶體緩沖區中(該緩沖區默認大小是 100MB ),
4.Spill 階段(此處的spill對應后問的sort(排序),溢寫(spill)這兩個程序):即“溢寫”,當緩沖區快要溢位時(默認達到緩沖區大小的 80 %),會在本地檔案系統創建一個溢位檔案,將該緩沖區的資料寫入這個檔案,
將資料寫入本地磁盤前,先要對資料進行一次本地排序,并在必要時對資料進行合并、壓縮等操作,
寫入磁盤之前,執行緒會根據 ReduceTask 的數量,將資料磁區,一個 Reduce 任務對應一個磁區的資料,
這樣做的目的是為了避免有些 Reduce 任務分配到大量資料,而有些 Reduce 任務分到很少的資料,甚至沒有分到資料的尷尬局面,
如果此時設定了 Combiner ,將排序后的結果進行 Combine 操作,這樣做的目的是盡可能少地執行資料寫入磁盤的操作,
5. Combine 階段(對應后文的merge(合并)):當所有資料處理完成以后, MapTask 會對所有臨時檔案進行一次合并,以確保最終只會生成一個資料檔案
合并的程序中會不斷地進行排序和 Combine 操作,
其目的有兩個:一是盡量減少每次寫人磁盤的資料量;二是盡量減少下一復制階段網路傳輸的資料量,
最后合并成了一個已磁區且已排序的檔案,
在reduce階段:
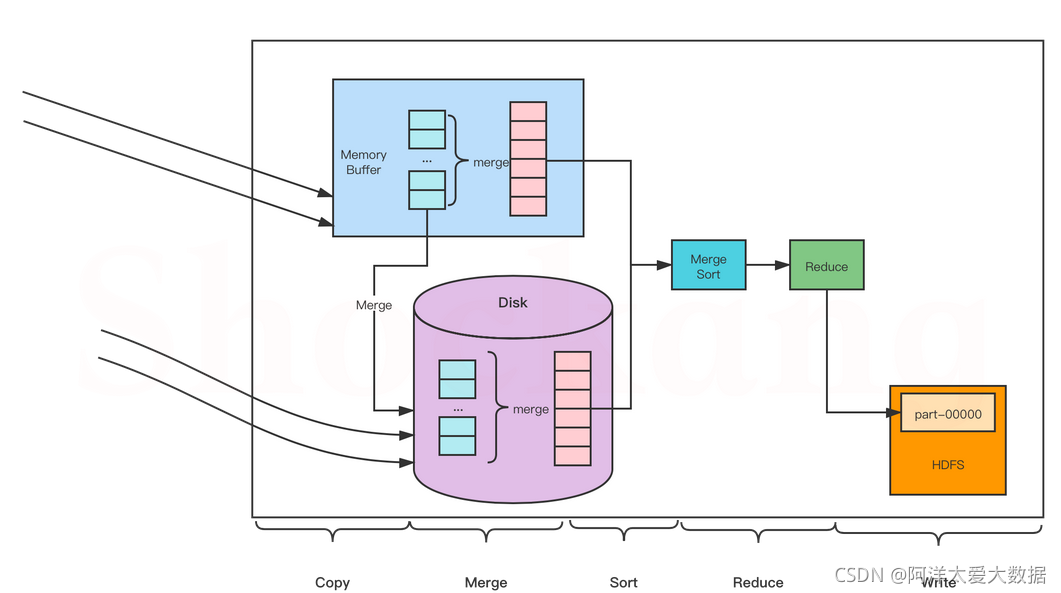
reducer把從不同mapper接受來的資料整合在一起,并進行排序,然后呼叫用戶自定義reduce函式,對輸入的<K2, list( V2)>對進行相應的處理,得到鍵值對<K3,V3>并輸入到HDFS上,
總的來說:
1. Copy 階段(屬于shuffle): Reduce 會從各個 MapTask 上遠程復制一片資料(每個 MapTask 傳來的資料都是有序的),并針對某一片資料,如果其大小超過一定國值,則寫到磁盤上,否則直接放到記憶體中
2. Merge 階段(屬于shuffle):在遠程復制資料的同時, ReduceTask 會啟動兩個后臺執行緒,分別對記憶體和磁盤上的檔案進行合并,以防止記憶體使用過多或者磁盤檔案過多,
3.Sort 階段(屬于shuffle):用戶撰寫 reduce() 方法輸入資料是按 key 進行聚集的一組資料,
為了將 key 相同的資料聚在一起, Hadoop 采用了基于排序的策略,
由于各個 MapTask 已經實作對自己的處理結果進行了區域排序,因此, ReduceTask 只需對所有資料進行一次歸并排序即可,
4.Reduce 階段:對排序后的鍵值對呼叫 reduce() 方法,鍵相等的鍵值對呼叫一次 reduce()方法,每次呼叫會產生零個或者多個鍵值對,最后把這些輸出的鍵值對寫入到 HDFS 中
5.Write 階段: reduce() 函式將計算結果寫到 HDFS 上,
合并的程序中會產生許多的中間檔案(寫入磁盤了),但 MapReduce 會讓寫入磁盤的資料盡可能地少,并且最后一次合并的結果并沒有寫入磁盤,而是直接輸入到 Reduce 函式,
Shuffle:
MapReduce 作業程序中, Map 階段處理的資料如何傳遞給 Reduce 階段,這是 MapReduce 框架中關鍵的一個程序,這個程序叫作 Shuffle ,
Shuffle 會將 MapTask 輸出的處理結果資料分發給 ReduceTask ,并在分發的程序中,對資料按 key 進行磁區和排序,
Shuffle橫跨map端和reduce端,在map端包括spill(溢寫),而在reduce端包括copy和sort程序
map端的spill: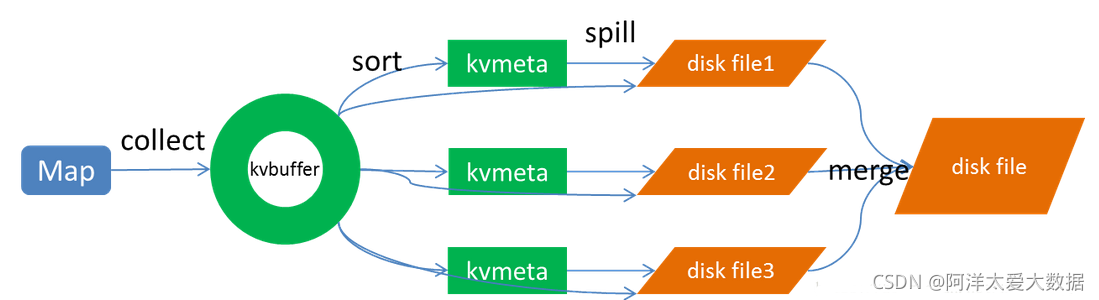
“其中spill程序包括四個程序:collect(輸出),sort(排序),溢寫(spill),merge(合并)
Collect:
每個Map任務不斷地以對的形式把資料輸出到在記憶體中構造的一個環形資料結構中,使用環形資料結構是為了更有效地使用記憶體空間,在記憶體中放置盡可能多的資料,這個資料結構其實就是個位元組陣列,叫Kvbuffer
Sort:
先把Kvbuffer中的資料按照partition值和key兩個關鍵字升序排序,移動的只是索引資料,排序結果是Kvmeta中資料按照partition為單位聚集在一起,同一partition內的按照key有序,
Spill:
Spill執行緒為這次Spill程序創建一個磁盤檔案:從所有的本地目錄中輪訓查找能存盤這么大空間的目錄,找到之后在其中創建一個類似于 “spill12.out”的檔案,Spill執行緒根據排過序的Kvmeta挨個partition的把資料吐到這個檔案中,一個partition對應的資料吐完之后順序地吐下個partition,直到把所有的partition遍歷 完,一個partition在檔案中對應的資料也叫段(segment),
記憶體緩沖區是有大小限制的,默認是100MB,當map task的輸出結果很多時,就可能會撐爆記憶體,所以需要在一定條件下將緩沖區中的資料臨時寫入磁盤,然后重新利用這塊緩沖區,這個從記憶體往磁盤寫資料的程序被稱為Spill,中文可譯為溢寫,比例默認是0.8,也就是當緩沖區的資料已經達到閾值(buffer size * spill percent = 100MB * 0.8 = 80MB),溢寫執行緒啟動,鎖定這80MB的記憶體,執行溢寫程序,Map task的輸出結果還可以往剩下的20MB記憶體中寫,互不影響,
Merge:
Map任務如果輸出資料量很大,可能會進行好幾次Spill,out檔案和Index檔案會產生很多,分布在不同的磁盤上,最后把這些檔案進行合并的merge程序閃亮登場,如前面的例子,“aaa”從某個map task讀取過來時值是5,從另外一個map 讀取時值是8,因為它們有相同的key,所以得merge成group,什么是group,對于“aaa”就是像這樣的:{“aaa”, [5, 8, 2, …]}
”
reduce的shuffle程序:
Copy:
Reduce 任務通過HTTP向各個Map任務拖取它所需要的資料,每個節點都會啟動一個常駐的HTTP server,其中一項服務就是回應Reduce拖取Map資料,當有MapOutput的HTTP請求過來的時候,HTTP server就讀取相應的Map輸出檔案中對應這個Reduce部分的資料通過網路流輸出給Reduce,
Merge SORT:
這里使用的Merge和Map端使用的Merge程序一樣,Map的輸出資料已經是有序的,Merge進行一次合并排序,所謂Reduce端的 sort程序就是這個合并的程序,一般Reduce是一邊copy一邊sort,即copy和sort兩個階段是重疊而不是完全分開的,
當Reducer的輸入檔案已定,整個Shuffle才最終結束
整體:
流程大體可以分為以下五步:
分片格式化==>執行maptask==>執行shuffle==>執行reducetask==>寫入檔案
MapReduce編程時,階段的順序:
Mapper --> Partitioner --> Shuffle/sort --> Combiner
MapReduce資料流的順序是?
InputFormat --> Mapper --> Combiner --> Partitioner --> Reducer --> Outputformat
MapReduce編程模型中,以下哪個組件是最后執行的?
A.Reducer B.Mapper C.Partitioner D.RecordReader
解答:以上四個執行的順序是:Rcordreader,Mapper,Partitioner,Reducer
在MapReduce中,map的數量取決于(輸入資料)的總量?
解答:在map階段讀取資料前,FilInputFormat會將輸入檔案分割成split,split的個數決定了map的個數,
而影響map(spilt的個數)的主要因素有:
1) 檔案的大小,當塊(dfs.block.size)為128m時,如果輸入檔案為128m,會被劃分為1個split;
當塊為256m,會被劃分為2個split,
2) 檔案的個數,FileInputFormat按照檔案分割split,并且只會分割大檔案,即那些大小超過HDFS塊的大小的檔案,如果HDFS中dfs.block.size設定為128m,而輸入的目錄中檔案有100個,則劃分后的split個數至少為100個,
3) splitsize的大小,分片是按照splitszie的大小進行分割的,一個split的大小在沒有設定的情況下,默認等于hdfs block的大小,但應用程式可以通過兩個引數來對splitsize進行調節
在Hadoop磁區階段,默認的Partitioner是?
HashpPrtitioner
總結:
參考到過的博客:Shuffle程序詳解及優化_菜如張學清的博客-CSDN博客_shuffle程序
圖文詳解 MapReduce 作業流程_Shockang的博客-CSDN博客
圖文詳解 MapReduce 作業流程_Shockang的博客-CSDN博客
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/339075.html
標籤:其他