介紹與推導
LDA是線性判別分析的英文縮寫,該方法旨在通過將多維的特征映射到一維來進行類別判斷,映射的方式是將數值化的樣本特征與一個同維度的向量做內積,即:
$y=w^Tx$
因此,建立模型的目標就是找到一個最優的向量,使映射到一維后的不同類別的樣本之間“距離”盡可能大,而同類別的樣本之間“距離”盡可能小,使分類盡可能準確,
具體來說,就是使映射后類內樣本方差盡可能小,類間樣本方差盡可能大,也就是(這里為二分類,多分類類似):
$ \begin{align*} &\quad \min\limits_w \left[\sum\limits_{x\in X_0}(w^Tx-w^T\mu_0)^2+\sum\limits_{x\in X_1}(w^Tx-w^T\mu_1)^2\right]\\ &=\min\limits_w w^T \left[\sum\limits_{x\in X_0}(x-\mu_0)(x-\mu_0)^T+\sum\limits_{x\in X_1}(x-\mu_1)(x-\mu_1)^T\right]w \\ &=\min\limits_w w^TS_ww \\ \end{align*} $
和
$ \begin{align*} &\quad \max\limits_w \left[(w^T\mu_0-\frac{w^T\mu_0+w^T\mu_1}{2})^2+(w^T\mu_1-\frac{w^T\mu_0+w^T\mu_1}{2})^2\right]\\ &=\max\limits_w \frac{1}{2}w^T(\mu_0-\mu_1)(\mu_0-\mu_1)^Tw\\ &=\max\limits_w \frac{1}{2}w^TS_bw \\ \end{align*} $
因為自變數只有$w$,不一定二者都能同時達到最優,所以整合到一起取下式的最大值:
$J = \displaystyle \frac{w^TS_bw}{w^TS_ww}$
也就是:
$ \begin{align*} &\min\limits_w -w^TS_bw\\ &\text{s.t.}\,\, w^TS_ww = 1 \end{align*} $
因為$S_w$正定,$S_b$半正定,所以使用拉格朗日乘子法(點擊鏈接),最終得到:
$w = S_w^{-1}(\mu_0-\mu_1)$
其中$S_w^{-1}$是$S_w$的偽逆,
實驗
西瓜資料集
實驗用資料集為西瓜資料集:
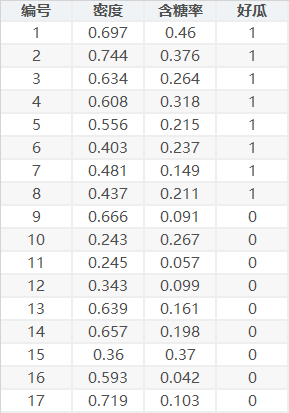
將資料填入Excel中后,在python中讀取,然后使用處理好的資料計算出$w$,最后進行測驗,
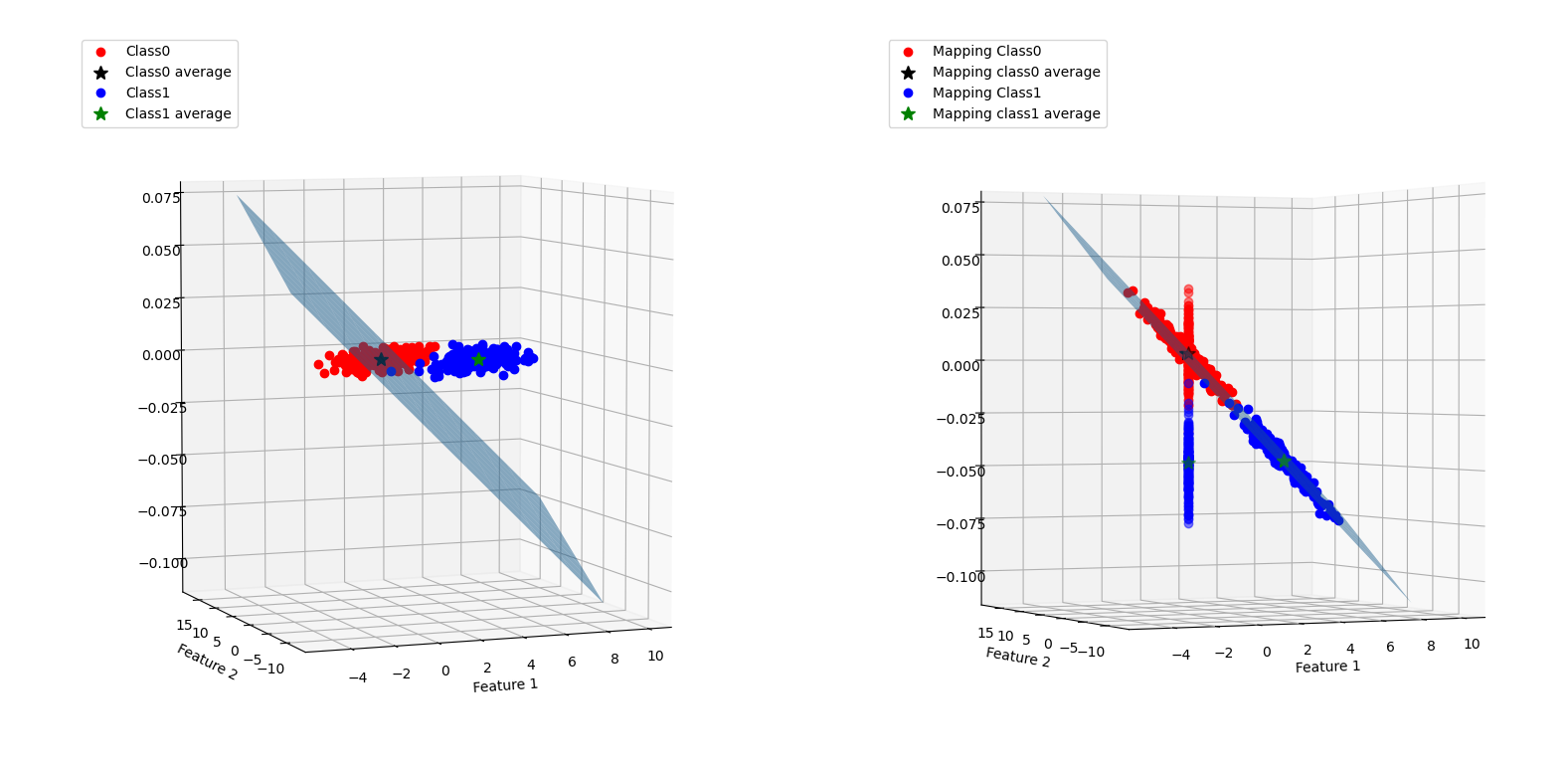
各個樣本點、映射平面以及映射后的樣本點如下圖所示:
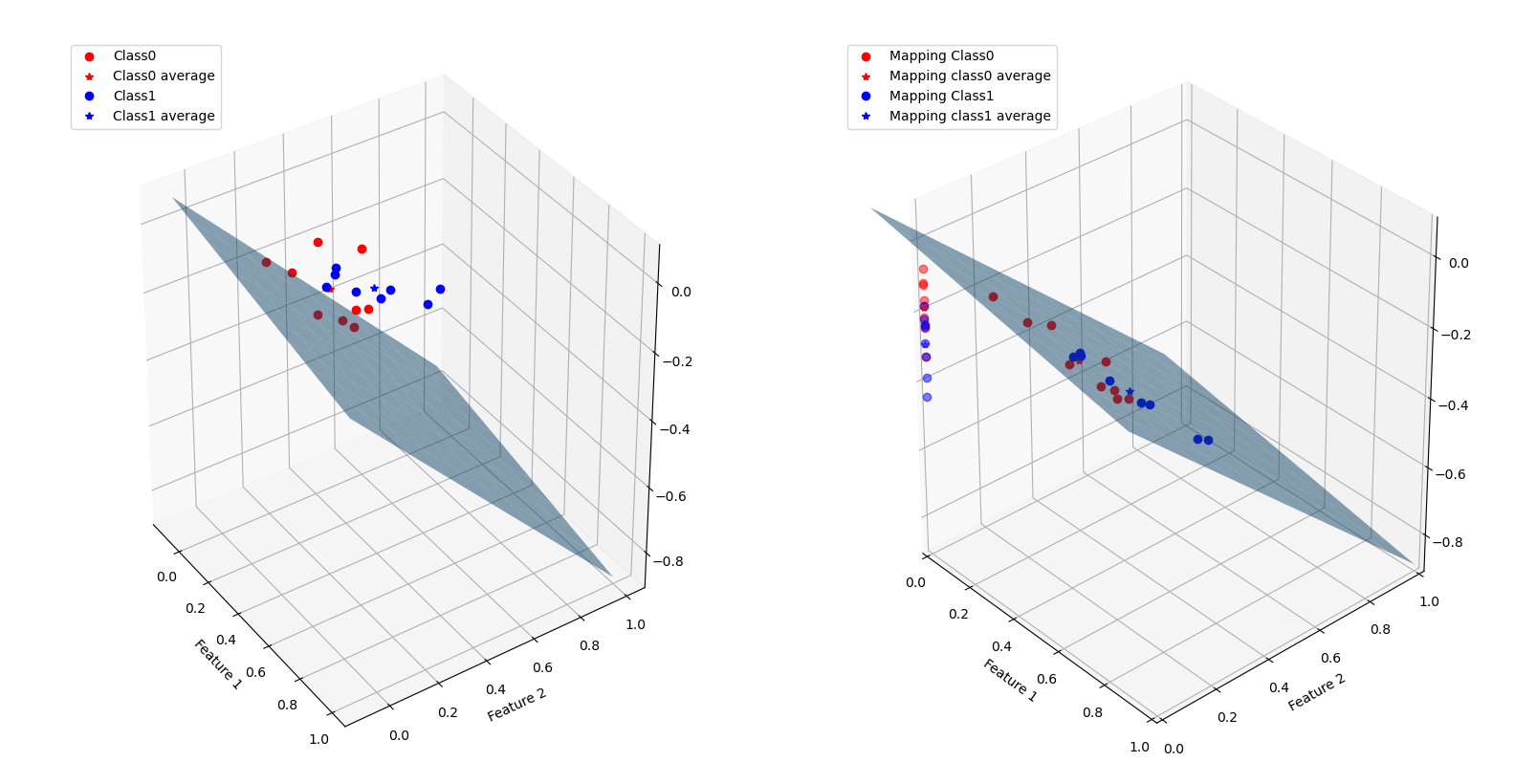
可以看到兩類的樣本點明顯不是線性可分的,因此,不論如何選取一次的線性映射,都不可能將兩類樣本完全分開,而找到的映射平面將樣本映射到一維后(即在右圖的Z軸上),依然是很多不同類別的點穿插在一起,
因此,判別訓練集的正確率較低:
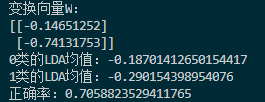
僅0.7,
線性資料集
為了測驗LDA在線性可分特征資料集上的性能,以二維正態分布生成如下樣本點:
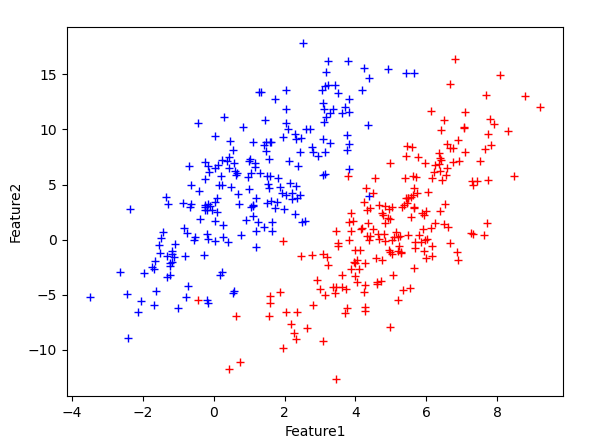
其中藍色點均值為$[1,5]$,紅色為$[5,1]$;兩類樣本的協方差矩陣都為:
$\left[\begin{matrix}1.4&1\\1&5\\\end{matrix}\right]$
映射圖如下:
判斷結果如下:
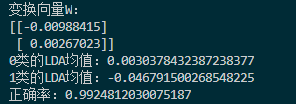
正確率提高到了0.99,可見LDA在線性可分資料上的性能還是不錯的,
實驗代碼
LDA代碼(資料輸入data.xlsx中第一個表即可):
1 #%% 2 import matplotlib.pyplot as plt 3 import numpy as np 4 import xlrd 5 6 table = xlrd.open_workbook('test.xlsx').sheets()[0]#讀取Excel資料 7 data =https://www.cnblogs.com/qizhou/p/ [] 8 for i in range(1,table.nrows):#假設第一行是表頭不讀入 9 data.append(table.row_values(i)) 10 class0 = [] 11 class1 = [] 12 #劃分正反特征集,編號第一列,類別最后一列,特征在中間 13 for i in data: 14 if i[-1] == 0: 15 class0.append(i[1:-1]) 16 else: 17 class1.append(i[1:-1]) 18 data = https://www.cnblogs.com/qizhou/p/np.array(data) #轉為數字矩陣 19 class0 = np.array(class0) #特征都是行向量,組成矩陣 20 class1 = np.array(class1) 21 22 # %% 23 #計算相應類別特征的平均 24 n0 = len(class0) 25 n1 = len(class1) 26 miu0 = np.dot(np.ones([1,n0]),class0)/n0 27 miu1 = np.dot(np.ones([1,n1]),class1)/n1 28 29 #%% 30 #計算類內散度矩陣 31 s0 = class0 - miu0 32 s1 = class1 - miu1 33 Sw = np.dot(s0.transpose(),s0)+np.dot(s1.transpose(),s1) 34 W = np.dot(np.linalg.pinv(Sw),(miu0-miu1).transpose()) #計算W 35 #輸出W、miu0和miu1在映射后的值 36 miu0_LDA = np.dot(miu0,W) 37 miu1_LDA = np.dot(miu1,W) 38 print("變換向量W:") 39 print(W) 40 print("0類的LDA均值:"+str(miu0_LDA[0,0])) 41 print("1類的LDA均值:"+str(miu1_LDA[0,0])) 42 43 #%% 44 #判斷類別 45 c_discrim = np.dot(data[:,1:-1],W) 46 #統計正確率 47 right = 0 48 for i in range(len(data)): 49 if np.abs(miu0_LDA[0,0] - c_discrim[i]) < np.abs(miu1_LDA[0,0] - c_discrim[i]): 50 if data[i][-1] == 0: 51 right +=1 52 else: 53 if data[i][-1] == 1: 54 right +=1 55 print("正確率:"+str(right / len(data))) 56 57 #%% 58 #畫圖(僅適用于二維特征) 59 ##################圖一 60 fig = plt.figure() 61 ax = fig.add_subplot(121,projection = '3d') 62 plt.xlabel("Feature 1") 63 plt.ylabel("Feature 2") 64 ax.plot(class0[:,0],class0[:,1],'o',label = 'Class0',color = "red") #0類 65 ax.plot([miu0[0,0]],[miu0[0,1]],'*',label = 'Class0 average',color = "black",markersize = 10) #0類平均 66 ax.plot(class1[:,0],class1[:,1],'o',label = 'Class1',color = "blue") #1類 67 ax.plot([miu1[0,0]],[miu1[0,1]],'*',label = 'Class1 average',color = "green",markersize = 10) #1類平均 68 #映射平面 69 t = np.linspace(-5,10,10) 70 X,Y = np.meshgrid(t,t) 71 ax.plot_surface(X,Y,X*W[0]+Y*W[1],alpha = 0.5) 72 ax.legend(loc = 'upper left') 73 74 ##################圖二 75 ax = fig.add_subplot(122,projection = '3d') 76 plt.xlabel("Feature 1") 77 plt.ylabel("Feature 2") 78 ax.plot(class0[:,0],class0[:,1],np.dot(class0,W)[:,0],'o',label = 'Mapping Class0',color = "red") #0類映射 79 ax.plot([miu0[0,0]],[miu0[0,1]],np.dot(miu0[0],W),'*',label = 'Mapping class0 average',color = "black",markersize = 10) #0類平均映射 80 ax.plot(class1[:,0],class1[:,1],np.dot(class1,W)[:,0],'o',label = 'Mapping Class1',color = "blue") #1類映射 81 ax.plot([miu1[0,0]],[miu1[0,1]],np.dot(miu1[0],W),'*',label = 'Mapping class1 average',color = "green",markersize = 10) #1類平均映射 82 ax.plot(np.zeros([len(class0)]),np.zeros([len(class0)]),np.dot(class0,W)[:,0],'o',color = "red",alpha = 0.5) #0類映射值 83 ax.plot(np.zeros([len(class1)]),np.zeros([len(class1)]),np.dot(class1,W)[:,0],'o',color = "blue",alpha = 0.5) #1類映射值 84 ax.plot([np.zeros([1])],np.zeros([1]),np.dot(miu0[0],W),'*',color = "black",alpha = 0.5,markersize = 10) #0類平均映射值 85 ax.plot([np.zeros([1])],np.zeros([1]),np.dot(miu1[0],W),'*',color = "green",alpha = 0.5,markersize = 10) #1類平均映射值 86 #映射平面 87 X,Y = np.meshgrid(t,t) 88 ax.plot_surface(X,Y,X*W[0]+Y*W[1],alpha = 0.5) 89 ax.legend(loc = 'upper left') 90 91 plt.show()
生成線性資料集代碼:
1 import openpyxl 2 import numpy as np 3 import matplotlib.pyplot as plt 4 5 sampleNum = 200 6 7 # 二維正態分布 8 mu = np.array([[1, 5]]) 9 Sigma = np.array([[1.4, 1], [1, 5]]) 10 s1 = np.dot(np.random.randn(sampleNum, 2), Sigma) + mu 11 plt.plot(s1[:,0],s1[:,1],'+',color='blue') 12 13 mu = np.array([[5, 1]]) 14 Sigma = np.array([[1.4, 1], [1, 5]]) 15 s2 = np.dot(np.random.randn(sampleNum, 2), Sigma) + mu 16 plt.plot(s2[:,0],s2[:,1],'+',color='red') 17 plt.xlabel('Feature1') 18 plt.ylabel('Feature2') 19 20 plt.show() 21 data =https://www.cnblogs.com/qizhou/p/ openpyxl.Workbook() 22 table = data.create_sheet('test') 23 table.cell(1,1,'id') 24 table.cell(1,2,'feature1') 25 table.cell(1,3,'feature2') 26 table.cell(1,4,'class') 27 for i in range(sampleNum): 28 table.cell(i+2,1,i+1) 29 table.cell(i+2,2,s1[i][0]) 30 table.cell(i+2,3,s1[i][1]) 31 table.cell(i+2,4,0) 32 for i in range(sampleNum): 33 table.cell(i+1+sampleNum,1,i+1) 34 table.cell(i+1+sampleNum,2,s2[i][0]) 35 table.cell(i+1+sampleNum,3,s2[i][1]) 36 table.cell(i+1+sampleNum,4,1) 37 data.remove(data['Sheet']) 38 data.save('test.xlsx')
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/34022.html
標籤:其他