Dictum:
?Nutrition books in the world. There is no book in life, there is no sunlight; wisdom without books, as if the birds do not have wings. -- Shakespeare
??蒙特卡洛(Monte Carlo, MC)方法是一種不基于模型的方法,它不需要具有完備的環境知識,只要求具備經驗,即來自于真實的或模擬的環境互動程序中的樣本序列\(\{\mathcal{S},\mathcal{A},\mathcal{R}\}\),
??同時,MC方法是基于平均采樣回報來解決強化學習問題,只針對幕式任務,
預備知識
MC預測
??MC方法是根據經驗進行估計,即對訪問該狀態后觀測到的回報求均值,隨著觀測到的回報越來越多,均值會逐漸收斂于期望值,
??MC方法又可以分為首次訪問型MC方法(first-visit MC method)和每次訪問型MC方法(every-visit MC method):
??首次訪問型MC方法用首次訪問狀態\(s\)得到的回報均值估計\(v_\pi(s)\);
??每次訪問型MC方法用所有訪問狀態\(s\)得到的回報均值估計\(v_\pi(s)\),
??根據大數定律(law of large numbers),當對\(s\)的訪問次數趨向無窮時,兩種方法的估計值都會收斂于\(v_\pi(s)\),
??MC方法沒有完備的環境模型,因此,將對狀態的訪問改為對“狀態-動作”二元組的訪,也就是說它估計的是\(q_\pi(s,a)\)而不是\(v_\pi(s)\),
MC控制
??MC方法也是用策略迭代演算法進行控制,但更新的是\(q_\pi(a|s)\),
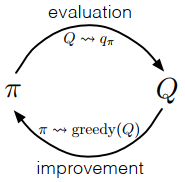
\[\pi_{0} \stackrel{E}{\longrightarrow} q_{\pi_{0}} \stackrel{I}{\longrightarrow} \pi_{1} \stackrel{E}{\longrightarrow} q_{\pi_{1}} \stackrel{I}{\longrightarrow} \pi_{2} \stackrel{E}{\longrightarrow} \cdots \stackrel{I}{\longrightarrow} \pi_{*} \stackrel{E}{\longrightarrow} q_{*} \]
??和DP相同,選擇貪心策略需要滿足
\[\pi(s) \doteq \underset{a}{\operatorname{argmax}} q(s,a) \tag{4.1} \]
??策略改進通過將\(q_{\pi_k}\)對應的貪心策略作為\(\pi_{k+1}\)進行,滿足策略改進定理,即
\[\begin{aligned} q_{\pi_{k}}\left(s, \pi_{k+1}(s)\right) &=q_{\pi_{k}}\left(s, \underset{a}{\arg \max } q_{\pi_{k}}(s, a)\right) \\ &=\max _{a} q_{\pi_{k}}(s, a) \\ & \geq q_{\pi_{k}}\left(s, \pi_{k}(s)\right) \\ & \geq v_{\pi_{k}}(s) \end{aligned} \tag{4.2}\]
MC方法
??MC方法可以分成同步策略(on-policy)方法和異步策略(off-policy)方法,它們的區別:
??同步策略方法用于生成決策軌跡的策略和進行評估或改進的策略是相同的;
??異步策略方法用于生成決策軌跡的策略和進行評估或改進的策略是不同的,
同步策略方法
??在同步策略方法中,策略是“軟性(soft)”的,即對任意\(s \in \mathcal{S},a \in \mathcal{A}(s)\),都有\(\pi(a|s)>0\),最典型的同步策略方法是\(\varepsilon\)-貪心策略(\(\varepsilon\)-greedy policy),即多數時候會選擇具有最大估計動作價值的動作,但有\(\varepsilon\)的概率隨機選擇一個動作,該策略可以被表示為
\[\pi(a|s) \leftarrow\left\{\begin{array}{ll} 1-\varepsilon+\varepsilon /|\mathcal{A}(s)| & \text { if } a=A^{*} \\ \varepsilon /|\mathcal{A}(s)| & \text { if } a \neq A^{*} \end{array}\right. \tag{4.3}\]
??根據策略改進定理,對于一個\(\varepsilon\)-軟性策略\(\pi\),任何一個根據\(q_\pi\)生成的\(\varepsilon\)-貪心策略都是對它的一個改進,假設\(\pi^\prime\)是一個\(\varepsilon\)-貪心策略,即
\[\begin{aligned} q_{\pi}\left(s, \pi^{\prime}(s)\right) &=\sum_{a} \pi^{\prime}(a | s) q_{\pi}(s, a) \\ &=\frac{\epsilon}{|\mathcal{A}(s)|} \sum_{a} q_{\pi}(s, a)+(1-\varepsilon) \max _{a} q_{\pi}(s, a) \\ & \geq \frac{\epsilon}{|\mathcal{A}(s)|} \sum_{a} q_{\pi}(s, a)+(1-\varepsilon) \sum_{a} \frac{\pi(a | s)-\frac{\epsilon}{|\mathcal{A}(s)|}}{1-\varepsilon} q_{\pi}(s, a) \\ &=\frac{\epsilon}{|\mathcal{A}(s)|} \sum_{a} q_{\pi}(s, a)-\frac{\epsilon}{|\mathcal{A}(s)|} \sum_{a} q_{\pi}(s, a)+\sum_{a} \pi(a | s) q_{\pi}(s, a)\\ &=v_{\pi}(s) \end{aligned} \tag{4.4}\]
異步策略方法
??所有的學習控制方法都面臨一個困境:它們試圖學習最優動作價值,但為了探索所有的動作,以此保證找到最優動作,它們需要嘗試那些非最優的動作,
??同步策略方法只是提出了一個妥協的辦法——它并不是學習最優策略的動作價值,而是學習一個近似最優且仍能進行探索的策略的動作價值,
??而異步策略方法則是使用兩個不同的策略,一個用于學習并最終達到最優的目標策略(target policy),另一個更具探索性,并能生成決策序列的行為策略(behavior policy),
??異步策略方法使用了重要性采樣(詳見附錄A),根據在目標策略和行為策略生成的軌跡的相對概率(即重要性采樣比)對回報值加權,
??假設目標策略為\(\pi\),行為策略為\(b(\pi \neq b)\),然后,給定一個起始狀態\(S_t\),后續的“狀態-動作”軌跡\(A_t,S_{t+1},A_{t+1},...,S_T\)在任意策略\(\pi\)下的概率為
\[\begin{array}{l} \operatorname{Pr}\left\{A_{t}, S_{t+1}, A_{t+1}, \ldots, S_{T} | S_{t}, A_{t: T-1} \sim \pi\right\} \\ \quad=\pi\left(A_{t} | S_{t}\right) p\left(S_{t+1} | S_{t}, A_{t}\right) \pi\left(A_{t+1} | S_{t+1}\right) \cdots p\left(S_{T} | S_{T-1}, A_{T-1}\right) \\ \quad=\displaystyle \prod_{k=t}^{T-1} \pi\left(A_{k} | S_{k}\right) p\left(S_{k+1} | S_{k}, A_{k}\right) \end{array} \tag{4.5}\]
??\(p\)為狀態轉移概率函式,可以得到重要性采樣比為
\[\rho_{t: T-1} \doteq \frac{\prod_{k=t}^{T-1} \pi\left(A_{k} | S_{k}\right) p\left(S_{k+1} | S_{k}, A_{k}\right)}{\prod_{k=t}^{T-1} b\left(A_{k} | S_{k}\right) p\left(S_{k+1} | S_{k}, A_{k}\right)}=\prod_{k=t}^{T-1} \frac{\pi\left(A_{k} | S_{k}\right)}{b\left(A_{k} | S_{k}\right)} \tag{4.6} \]
??由此可以看出,\(\rho\)只與策略\(\pi\),\(b\)和樣本序列有關,與MDP的動態特性無關,
??下面通過一批觀察得到的遵循策略\(b\)的episodes來估計\(v_\pi(s)\),定義時間步長集合\(\mathcal{T}(s)\)在首次訪問型方法下,包含所有訪問過狀態\(s\)的時間步長;在首次訪問型方法,只包含在episode內首次訪問狀態\(s\)的時間步長,用\(T(t)\)表示時刻t后的首次終止時刻,\(G_t\)表示\(t\)到\(T(t)\)之間的回報值,\(\left\{\rho_{t: T(t)-1}\right\}_{t \in \mathcal{T}(s)}\)表示相應的重要性采樣比,
??那么可以得出,普通重要性采樣為\(V(s) \doteq \frac{\sum_{t \in \mathcal{T}(s)} \rho_{t: T(t)-1} G_{t}}{|\mathcal{T}(s)|}\)
??加權重要性采樣為\(V(s) \doteq \frac{\sum_{t \in \mathcal{T}(s)} \rho_{t: T(t)-1} G_{t}}{\sum_{t \in \mathcal{T}(s)} \rho_{t: T(t)-1}}\)(若分母為\(0\),\(V(s)=0\))
??關于價值函式的更新,可以通過增量式實作(詳見附錄B),假設有一個回報序列\(G_1,G_2,...,G_{n-1}\),它們都是從相同的狀態開始,且每一個回報都對應一個權重\(W_i\),則可以定義
\[V_{n} \doteq \frac{\sum_{k=1}^{n-1} W_{k} G_{k}}{\sum_{k=1}^{n-1} W_{k}}, \quad n \geq 2 \tag{4.7} \]
??假設前\(n\)個回報對應的權重累加和為\(C_n\),則\(V_n\)的更新方式為
\[V_{n+1} \doteq V_{n}+\frac{W_{n}}{C_{n}}\left[G_{n}-V_{n}\right], \quad n \geq 1(V_1為任意值)\tag{4.8} \]
\[C_{n+1} \doteq C_{n}+W_{n+1}\quad (C_0 \doteq 0) \]
附錄
重要性采樣
??重要性采樣(importance sampling)主要作用是通過一個簡單的可預測分布區估計一個服從另一個分布的隨機變數的均值,
??在重要性采樣中,隨機變數服從的分布不同但其元素的集合相同,因此,假設變數\(A_1 \sim P\),\(A_2 \sim Q\),其中\(P=\{p_1,p_2,...,p_n\}\),\(Q=\{q_1,q_2,...,q_n\}\),離散隨機變數\(A_1\)可以寫成\(A=\{x_1,x_2,...,x_n\}\),其每個元素出現的概率都對應分布\(P\);同樣,\(A_2\)可以寫出\(A=\{x_1,x_2,...,x_n\}\),其每個元素出現的概率都對應分布\(Q\),則\(\mathbb{E}[A_1]= \displaystyle \sum^n_{i=1}x_ip_i\),\(\mathbb{E}[A_2]= \displaystyle \sum^n_{i=1}x_iq_i\),
??經過N次試驗后,用MC估計得到它們的均值\(\overline{A}_1=\frac{1}{N} \displaystyle \sum_{i=1}^{N} x_{i} K_{i}\),\(\overline{A}_2=\frac{1}{N} \displaystyle \sum_{i=1}^{N} x_{i} M_{i}\)(\(K_i\)和\(M_i\)分別表示\(x_i\)在兩次試驗中出現的次數,所以\(\displaystyle \sum_i K_i=\sum_i M_i=N\)),根據大數定律,當試驗次數\(N \rightarrow \infty\)時,統計均值是期望的無偏估計,
??了解基本原理后,現在考慮如何運用,假設現在只能做關于\(A_2\)的試驗,但又想估計\(A_1\)的均值,那么只需要將\(K_i\)替換為\(M_i\),當試驗次數\(N \rightarrow \infty\)時,\(K_i \approx Np_i\),\(K_i \approx Np_i\),可以推出\(K_i \approx M_i \frac{p_i}{q_i}\),因此,\(A_1\)的均值估計可以寫為\(\overline{A}_1=\frac{1}{N} \displaystyle \sum_{i=1}^{N} (x_{i}\frac{p_i}{q_i}) M_{i}\),
??上述內容為普通重要性采樣(ordinary importance sampling),但這只對\(K_i\)做了近似處理,\(\displaystyle \sum_i \frac{p_i}{q_i} M_{i}\)并非嚴格等于\(N\),會導致無界的方差,即無論\(N\)多大,普通重要性采樣的估計值方差始終不會趨向于\(0\),為了解決這個問題,進行了加權處理,就有了加權重要性采樣(weighted importance sampling),只需將試驗次數\(N\)替換成估計的試驗次數\(\displaystyle \sum_i \frac{p_i}{q_i} M_{i}\),則可得
\[\overline{A}_1=\frac{\sum_i (x_{i}\frac{p_i}{q_i}) M_{i}}{\sum_i\frac{p_i}{q_i} M_{i}} \]
??\(\frac{p_i}{q_i}\)為重要性采樣比(importance-sampling ratio),普通重要性采樣的估計是無偏的,而加權重要性采樣的估計是有偏的且偏差逐漸收斂為\(0\);普通重要性采樣方差無界,而加權重要性采樣估計的方差仍能收斂于\(0\),
增量式實作
\[\begin{aligned} Q_{n+1} &=\frac{1}{n} \sum_{i=1}^{n} R_{i} \\ &=\frac{1}{n}\left(R_{n}+\sum_{i=1}^{n-1} R_{i}\right) \\ &=\frac{1}{n}\left(R_{n}+(n-1) \frac{1}{n-1} \sum_{i=1}^{n-1} R_{i}\right) \\ &=\frac{1}{n}\left(R_{n}+(n-1) Q_{n}\right) \\ &=\frac{1}{n}\left(R_{n}+n Q_{n}-Q_{n}\right) \\ &=Q_{n}+\frac{1}{n}\left[R_{n}-Q_{n}\right] \end{aligned}\]
References
Richard S. Sutton and Andrew G. Barto. Reinforcement Learning: An Introduction (Second Edition). Cambridge, Massachusetts London, England : The MIT Press, 2018.
Csaba Szepesvári, ‘Algorithms for Reinforcement Learning’, Synthesis Lectures on Artificial Intelligence and Machine Learning, vol. 4, no. 1, pp. 1–103, Jan. 2010, doi: 10.2200/S00268ED1V01Y201005AIM009.
UCL Reinforcement Learning Course by David Silver:https://www.bilibili.com/video/BV1b7411y7ax
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/34023.html
標籤:其他