這一節我們總結FM另外兩個遠親NFM,AFM,NFM和AFM都是針對Wide&Deep 中Deep部分的改造,上一章PNN用到了向量內積外積來提取特征互動資訊,總共向量乘積就這幾種,這不NFM就帶著element-wise(hadamard) product來了,AFM則是引入了注意力機制把NFM的等權求和變成了加權求和,
以下代碼針對Dense輸入感覺更容易理解模型結構,針對spare輸入的代碼和完整代碼 ??
https://github.com/DSXiangLi/CTR
NFM
NFM的創新點是在wide&Deep的Deep部分,在Embedding層和全聯接層之間加入了BI-Pooling層,也就是Embedding兩兩做element-wise乘積得到 \(N*(N-1)/2\)個 \(1*K\)的矩陣然后做sum_pooling得到最終\(1*k\)的矩陣,
\[f_{BI}(V_x) = \sum_{i=1}^n\sum_{j=i+1}^n (x_iv_i) \odot (x_jv_j) \]
Deep部分的模型結構如下
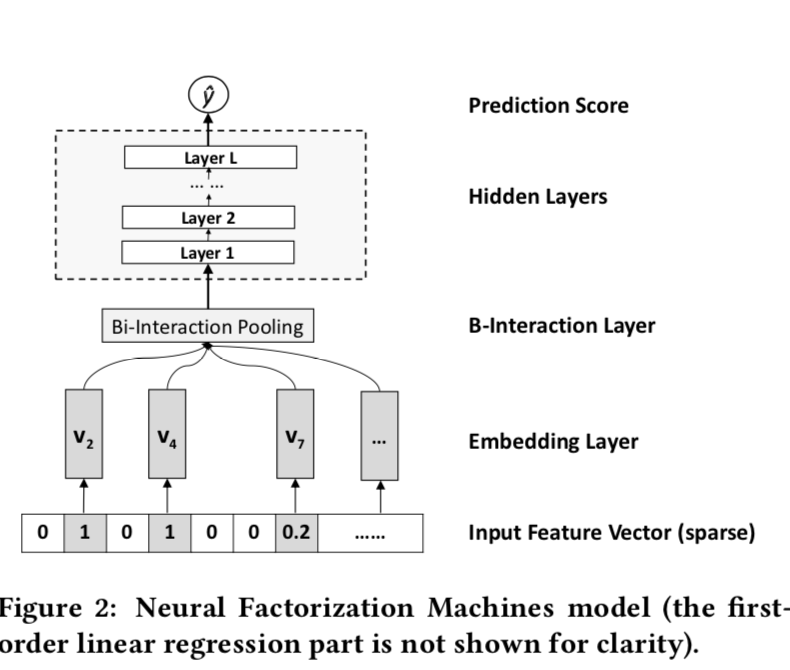
和其他模型的聯系
NFM不接全連接層,直接weight=1輸出就是FM,所以NFM可以在FM上學到更高階的特征互動,
有看到一種說法是DeepFM是FM和Deep并聯,NFM是把FM和Deep串聯,也是可以這么理解,但感覺本質是在學習不同的資訊,把FM放在wide側是幫助學習二階‘記憶特征’,把FM放在Deep側是幫助學習高階‘泛化特征’,
NFM和PNN都是用向量相乘的方式來幫助全聯接層提煉特征互動資訊,雖然一個是element-wise product一個是inner product,但區別其實只是做sum_pooling時axis的差異, IPNN是在k的axis上求和得到\(N^2\)個scaler拼接成輸入, 而NFM是在\(N^2\)的axis上求和得到\(1*K\)的輸入,
下面這個例子可以比較直觀的比較一下FM,NFM,IPNN對Embedding的處理(為了簡單理解給了Embedding簡單數值)
\[\begin{align} & embedding_1 = [0.5,0.5,0.5]\\ & embedding_2 = [2,2,2]\\ & embedding_3 = [4,4,4]\\ & embedding_1 \odot embedding_2 = [1,1,1]\\ & embedding_1 \odot embedding_3 = [2,2,2]\\ & embedding_2 \odot embedding_3 = [8,8,8]\\ & IPNN = [3,6,24] \\ & NFM = [11,11,11]\\ & FM = [33]\\ \end{align} \]
NFM幾個想吐槽的點
- 和FNN,PNN一樣對低階特征的提煉比較有限
- 這個sum_pooling同樣會存在資訊損失,不同的特征互動對Target的影響不同,等權加和一定不是最好的方法,但也算是為特征互動提供了一種新方法
代碼實作
@tf_estimator_model
def model_fn_dense(features, labels, mode, params):
dense_feature, sparse_feature = build_features()
dense = tf.feature_column.input_layer(features, dense_feature)
sparse = tf.feature_column.input_layer(features, sparse_feature)
field_size = len( dense_feature )
embedding_size = dense_feature[0].variable_shape.as_list()[-1]
embedding_matrix = tf.reshape( dense, [-1, field_size, embedding_size] ) # batch * field_size *emb_size
with tf.variable_scope('Linear_output'):
linear_output = tf.layers.dense( sparse, units=1 )
add_layer_summary( 'linear_output', linear_output )
with tf.variable_scope('BI_Pooling'):
sum_square = tf.pow(tf.reduce_sum(embedding_matrix, axis=1), 2)
square_sum = tf.reduce_sum(tf.pow(embedding_matrix, 2), axis=1)
dense = tf.subtract(sum_square, square_sum)
add_layer_summary( dense.name, dense )
dense = stack_dense_layer(dense, params['hidden_units'],
dropout_rate = params['dropout_rate'], batch_norm = params['batch_norm'],
mode = mode, add_summary = True)
with tf.variable_scope('output'):
y = linear_output + dense
add_layer_summary( 'output', y )
return y
AFM
AFM和NFM同樣使用element-wise product來提取特征互動資訊,和NFM直接等權重做pooling不同的是,AFM增加了一層Attention Layer來學習pooling的權重,
Deep部分的模型結構如下
\[\begin{align} f_{Att} = \sum_{i=1}^n\sum_{j=i+1}^n a_{ij}(v_ix_i) \odot (v_jx_j) \end{align} \]
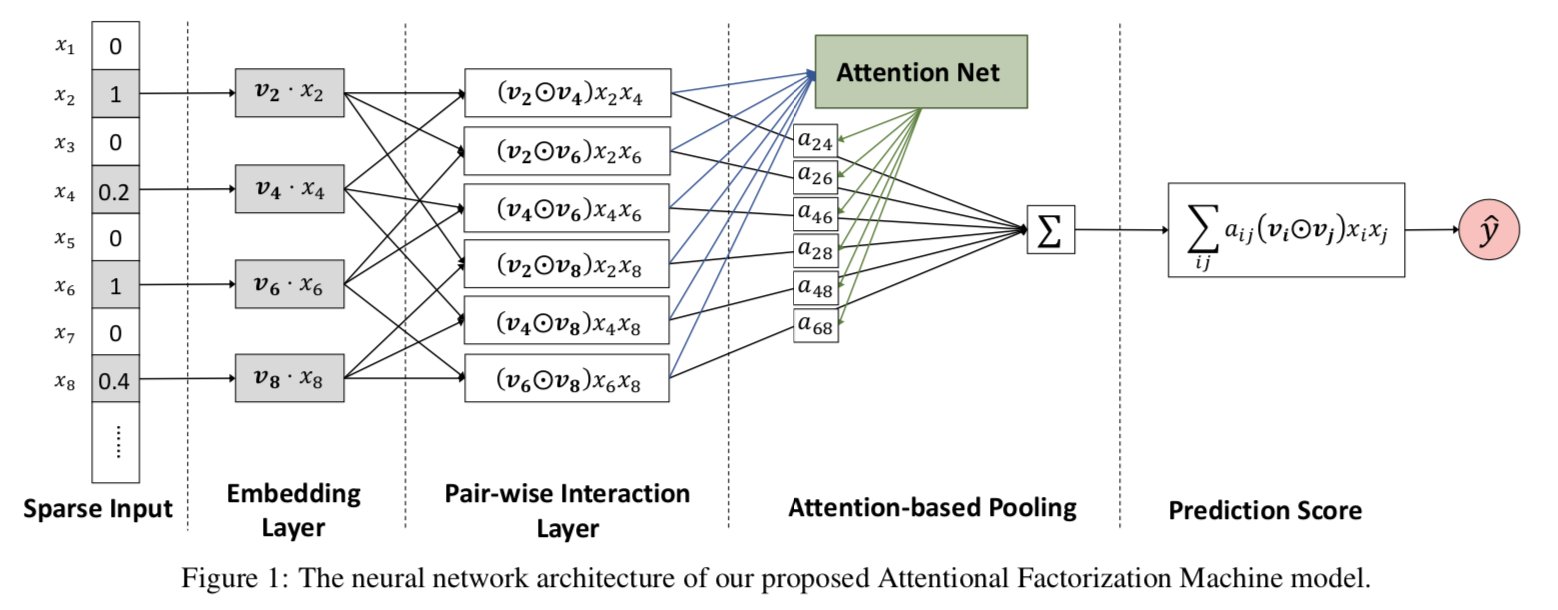
注意力部分是一個簡單的全聯接層,輸出的是\(N(N-1)/2\)的矩陣,作為sum_pooling的權重向量,對element-wise特征互動向量進行加權求和,加權求和的向量直接連接output,不再經過全聯接層,如果權重為1,那AFM和不帶全聯接層的NFM是一樣滴,
\[\begin{align} a_{ij} &= h^T ReLU(W (v_ix_i) \odot (v_jx_j) +b) \\ a_{ij} &= \frac{exp(a_{ij})}{\sum_{ij}exp(a_{ij})}\\ \end{align} \]
AFM幾個想吐槽的點
- 不帶全聯接層會導致高級特征表達有限,不過這個不重要啦,AFM更多還是為特征互動提供了Attention的新思路
代碼實作
@tf_estimator_model
def model_fn_dense(features, labels, mode, params):
dense_feature, sparse_feature = build_features()
dense = tf.feature_column.input_layer(features, dense_feature) # lz linear concat of embedding
sparse = tf.feature_column.input_layer(features, sparse_feature)
field_size = len( dense_feature )
embedding_size = dense_feature[0].variable_shape.as_list()[-1]
embedding_matrix = tf.reshape( dense, [-1, field_size, embedding_size] ) # batch * field_size *emb_size
with tf.variable_scope('Linear_part'):
linear_output = tf.layers.dense(sparse, units=1)
add_layer_summary( 'linear_output', linear_output )
with tf.variable_scope('Elementwise_Interaction'):
elementwise_list = []
for i in range(field_size):
for j in range(i+1, field_size):
vi = tf.gather(embedding_matrix, indices=i, axis=1, batch_dims=0,name = 'vi') # batch * emb_size
vj = tf.gather(embedding_matrix, indices=j, axis=1, batch_dims=0,name = 'vj')
elementwise_list.append(tf.multiply(vi,vj)) # batch * emb_size
elementwise_matrix = tf.stack(elementwise_list) # (N*(N-1)/2) * batch * emb_size
elementwise_matrix = tf.transpose(elementwise_matrix, [1,0,2]) # batch * (N*(N-1)/2) * emb_size
with tf.variable_scope('Attention_Net'):
# 2 fully connected layer
dense = tf.layers.dense(elementwise_matrix, units = params['attention_factor'], activation = 'relu') # batch * (N*(N-1)/2) * t
add_layer_summary( dense.name, dense )
attention_weight = tf.layers.dense(dense, units=1, activation = 'softmax') # batch *(N*(N-1)/2) * 1
add_layer_summary( attention_weight.name, attention_weight)
with tf.variable_scope('Attention_pooling'):
interaction_output = tf.reduce_sum(tf.multiply(elementwise_matrix, attention_weight), axis=1) # batch * emb_size
interaction_output = tf.layers.dense(interaction_output, units=1) # batch * 1
with tf.variable_scope('output'):
y = interaction_output + linear_output
add_layer_summary( 'output', y )
return y
CTR學習筆記&代碼實作系列??
https://github.com/DSXiangLi/CTR
CTR學習筆記&代碼實作1-深度學習的前奏LR->FFM
CTR學習筆記&代碼實作2-深度ctr模型 MLP->Wide&Deep
CTR學習筆記&代碼實作3-深度ctr模型 FNN->PNN->DeepFM
資料
- Jun Xiao, Hao Ye ,2017, Attentional Factorization Machines - Learning the Weight of Feature Interactions via Attention Networks
- Xiangnan He, Tat-Seng Chua,2017, Neural Factorization Machines for Sparse Predictive Analytics
- https://zhuanlan.zhihu.com/p/86181485
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/34024.html
標籤:其他
下一篇:五分鐘教你學會云審計