最近在學3D方向的語意分析,
師兄推薦了一個嗶哩大學的將門創投 | 斯坦福大學在讀博士生祁芮中臺:點云上的深度學習及其在三維場景理解中的應用!的寶藏視頻,我會多看幾遍,并寫下每次觀看筆記,
下文的截圖都源自講解的PPT,在我的資源:祁芮中臺點云講解.pdf
全篇手碼,內容較多會持續更新,
帶問號的句子都是乘上引下的重點作用,文章分為三篇,這是第一篇請耐心食用,

正文開始
Emerging 3D Applications
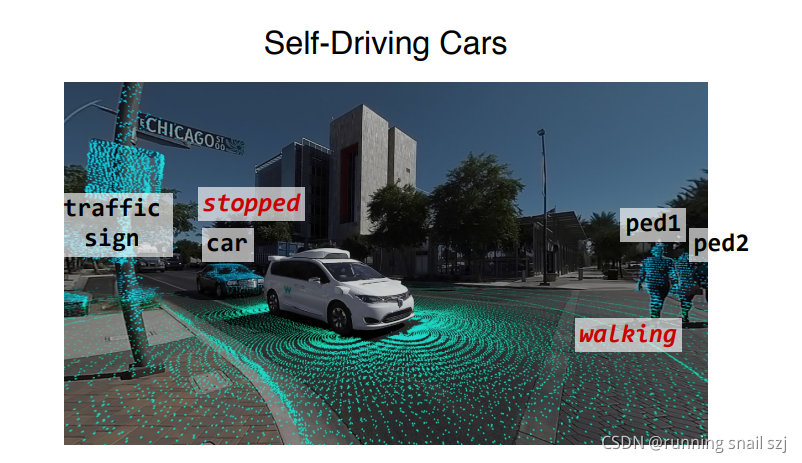
3D應用很多,比如自動駕駛
VR

3D Representations
三維資料的深度學習和二維有不一樣的地方,最大的不一樣就是由三維資料的本書復雜性帶來的,不像影像可以很精準的表示為二維矩陣:RGB,三維資料有很多種的表達形式,不同的表達形式有不同的應用驅動,如下下邊四種表達形式:

第一種是點云,opint cloud,是一組點的集合,可以由深度傳感器掃描得到的深度資料,
第二種為Mesh,可以由三角面片組成,在計算機圖形學中有很多應用,是一種適合做建模、渲染的資料格式,
第三種Volumetric,可以把空間劃分成三維的網格,每一個小的正方體代表此處有沒有物體,就形成了一個結構來代表空間中物體的分布,
第四種Multi-View Images RGB(D),可以用圖片的形式表達三維,用多個角度的圖片來表達三維常常用在可視化的程序中,因為人對圖片的理解遠遠好于對3D的理解,
在這多種表達中,點云資料是一種非常適合三維場景理解演算法的格式,原因有二,
一:點云是最接近于最原始的傳感器資料的,比如用激光雷達掃描到的資料直接就是點云,深度傳感器有一個深度影像,實際上也是點云,只不過是一個區域的點云,這種原始的資料可以做出端到端的深度學習,能盡可能挖掘原始資料中的模式,
二:點云在表達形式中是十分簡單的,僅僅是一組點,和其他格式相比,例如Mesh需要選擇是三角面片還是四角或五角面片,以及面片的大小和鏈接方式,選擇空間復雜,Volumetric需要選擇解析度,選擇多大的網格,若選的小,則會有很多空白的區域,大則損失精度,Multi-View Images RGB(D)需要選擇一些影像拍攝的角度,同時對3D表達形式不全面,僅僅能表達一個視角,不能表達完整的3D資料,
Previous Work(前人的作業概述)
點云是一種不規則的資料,不是定義在規則的網格上,在空間種任意分布,數量上也是任意,之前的研究作業是把他先轉換成一種柵格化編程的規則資料,比如變成一個三維的柵格,他就會分布在一個均勻的三維網格中,我們就可以用3D CNN(2D CNN的擴展)來處理這種資料,這是一個很經典的做法,如下圖:


但是有缺點:
一:三維的卷積他的代價很高,空間的復雜度和時間的復雜度隨著解析度的增長都是N的三次方(三次冪)的增長,計算代價很大,只能采用很低的解析度,會帶來量化的噪聲錯誤,會限制識別的精確度,
二:若不計不復雜度,解析度很高的話,會有很多空格是空白的狀態,掃描物體只能掃描到表面,而內部是空白的,所以其實柵格并不是對三維的最好表達形式,
除了柵格化的轉化,還有人嘗試把3D的點云投影到一個平面,這樣3D資料就變成了一個2D的資料,然后用2D的卷積神經網路去處理,這樣做會損失一些3D的資訊,因為投影的程序中3D會產生丟失,而且要決定投影的角度,并不簡單,

還有很多的方法,比如點云中手工提取特征,然后用一些用全連接的網路去處理,這樣會被手工提取的局限性限制住,
綜上:我們能不能做一種直接在點云上做特征學習的方法?有,PointNet,
PointNet:用于三維場景理解的點云深度學習
(此方法已經有別人總結過,可以看我上傳的資源:PointNet.pdf)

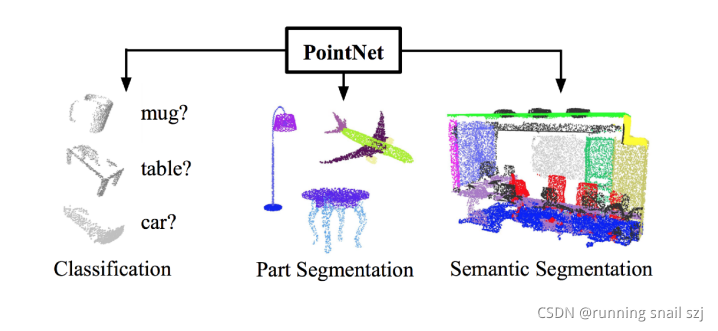
下圖有直接的感觀,比如最左邊是一個物體的點云(杯子、桌子)分開成不同的類,也可以把一個物體分成不同的區塊,比如第二列,可以把飛機分成飛機機翼和機身,桌子分成桌面和桌腳,給出一個常見的空間的點云也可以做語意的分割,可以把場景的點分成桌子椅子墻壁,完成一系列的任務,
我們構建模型必須考慮點云的兩點特性:
- 置換不變性:點云是一組無序點,點的順序不影響集合本身,
- 變換不變性:點云旋轉不應改變分類結果
首先看第1點:

點云往往會表達成二維的矩陣,他是一個N行D列的矩陣,N行代表有N個點,D列就代表每個點有D維的特征,最簡單的D=3就代表這個點的xyz坐標,也可以有更多的特征比如顏色、法向量,若把矩陣的行做了變換,比如下圖藍色從一行到四行,他表示的仍是同一個點集,這就要求設計的網路對所有的置換都一樣,

那如何做到置換的不變性?有一個系統化的解決方案,那就是設計一個對稱函式,
因為神經網路本身就是一個函式,對稱函式有置換不變性,下圖為舉例的取最大值的池化,就和點的順序無關,取所有點的和、平均都無關,

在這種對稱函式的框架下,如何利用神經網路來構建一組對稱函式?
Construct Symmetric Functions by Neural Networks:構建程序為以下四個圖片,
下圖從最簡單的例子開始,我們有一組點(第一個點坐標為(1,2,3)),我們取最大值,第一維最大值為2、第三維最大值為4,得出(2,3,4),但這樣的話我們只能得到最大值,其他資訊就丟失了,
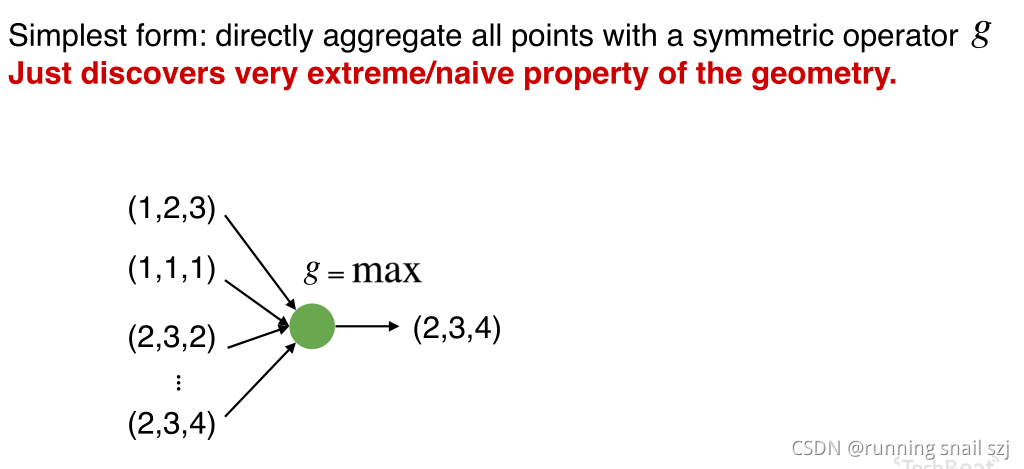
怎么才不丟失?
我們先把每個點映射到一個高維的空間,比如用一個一千維的空間來表示三維空間,再來做取最大值的對稱性操作,可以避免資訊丟失,
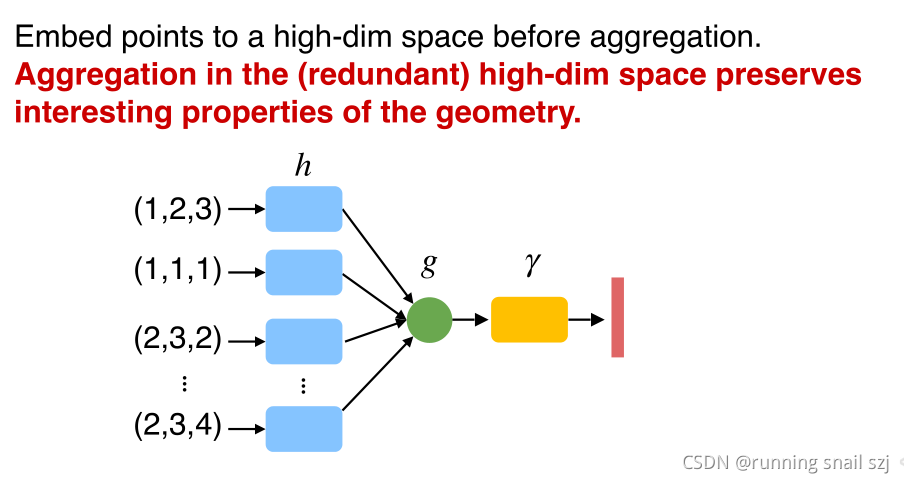
這個程序實際是一個函式的組合,函式g、h、r的一個組合,h把每個點做低維到高維的映射,然后只要函式g是對稱的那么整個函式就是對稱的,這個結構叫做原始的PointNet結構,
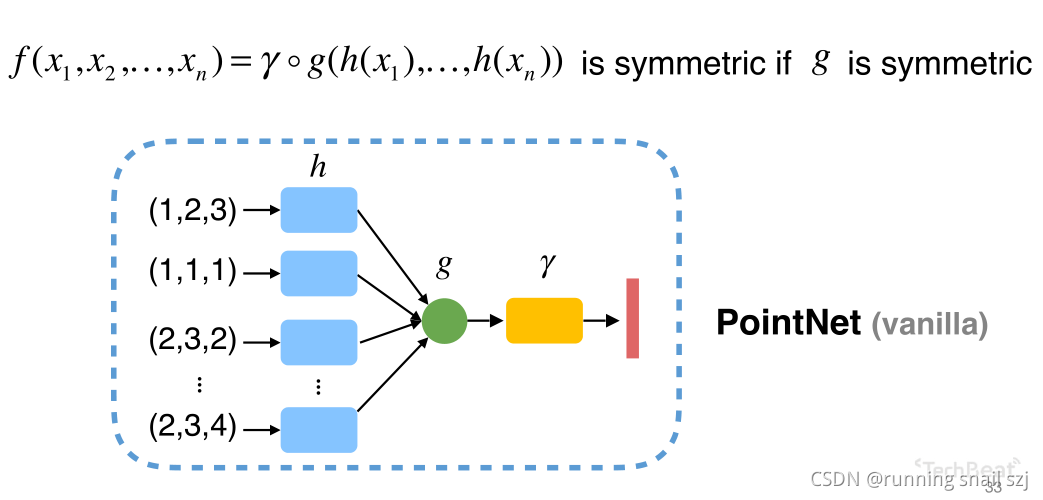
執行程序可以用多層感知器來描述函式h、r,對于函式g可以有很多種選擇,比如max就是一個對稱性好的池化操作,
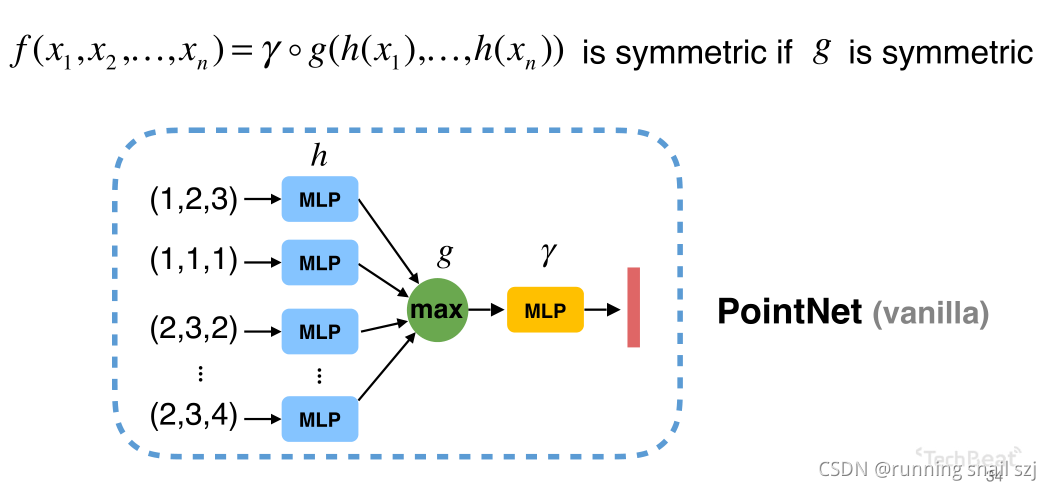
我們用神經網路構建了PointNet(vanlilla),那么在所有的對稱函式空間中,他占據了一個什么位置呢?什么函式能代表什么函式并不能代表呢?

實際上PointNet可以成為一種Universal Approximation(通用近似),可以任意的逼近集合上的對稱函式,只要這個對稱函式是在Hausdorff空間中是連續的,我們就可以通過增加神經網路的個數和網路的寬度來任意逼近這個函式,理論上是可行的,

再看第2點:
如何來應對輸入點云的幾何變換?一輛車從不同角度看都應該是車,網路也要應對這種視角的變化,

通過以下幾個圖片就可以理解:
Input Alignment by Transformer Network
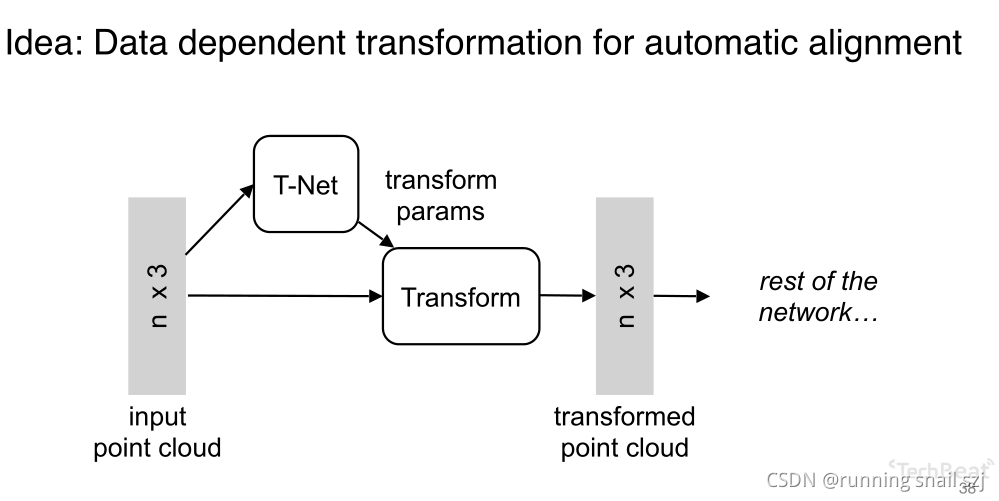
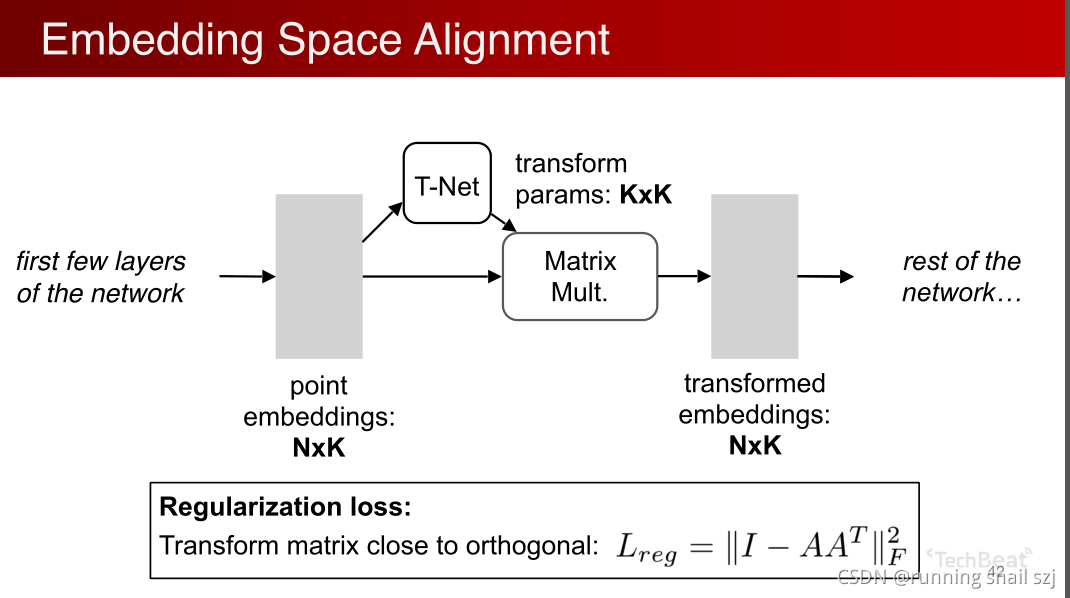
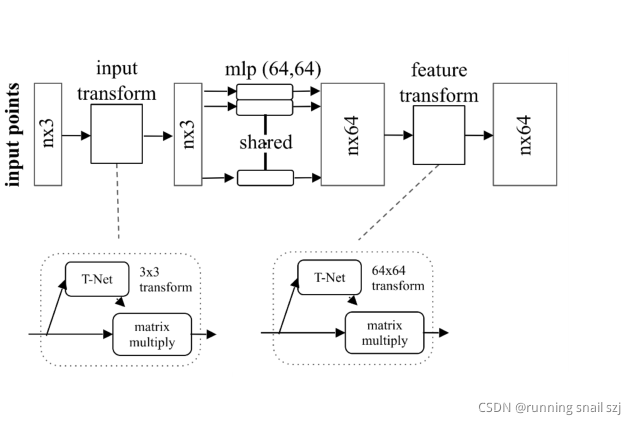
增加一個基于資料本身的變換函式模塊,下圖最左邊輸入的點云是n×3,有n個點,三個位置xyz,我們希望對這個點做一個變換,有一個神經網路T-Net,來生成一個變化引數,然后對n×3的點云做變換生成另一組變換后的點,之后再用后面的網路機制處理這組點,我們希望通過整體優化這個變換函式以及之后的網路,使得這個變換函式能夠自動的去對準對齊我的輸入,若對齊后會使得后面網路的任務很簡單,把不同視角的問題簡化,
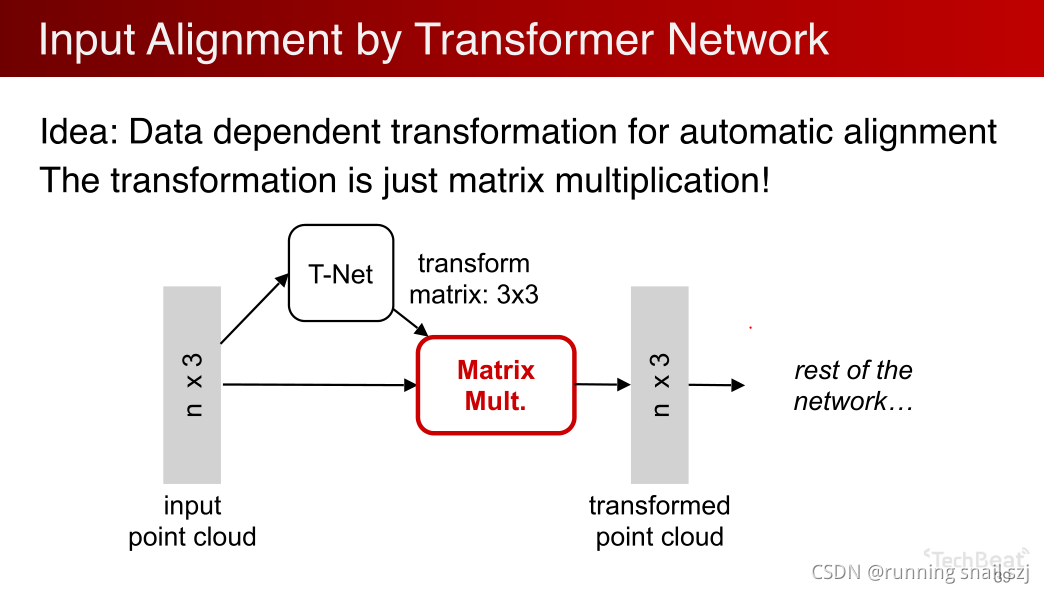
實際中,點云是一個很容易做幾何變換的資料,不像圖片中要設計一個transform的network要涉及到很多插值等操作,點云里很簡單,只要做一個矩陣的乘法就可以,比如對一個正交化的變化僅僅是一個3×3的矩陣乘法,實作很簡單,
推廣這個操作,不僅是輸入時做這個變換,我們還可以在點的中間特征做這個變換,比如我們剛開始有幾層網路已經把每個點變換成了k維,有一個N×K維的矩陣,每個點有k維的特征,我們可以用另外一個網路生成一個k×k的變換,我們可以用對個特征做一個特征空間的變換,也可以通過矩陣乘法方式實作,這樣變換完我們得到另一組特征,用接下來的網路進行處理,在優化程序中,因為高維的變換優化起來難度高,我們加一個Regularization loss(正則化損失),比如我們希望這個矩陣盡可能的接近一個正交矩陣,
PointNet Classification Network
現在我們看如何把這些變換的網路和我們原始的PointNet結合起來,得到我們最終的分類網路和分割網路?
一步一步來看:
給定輸入的點云,n×3,
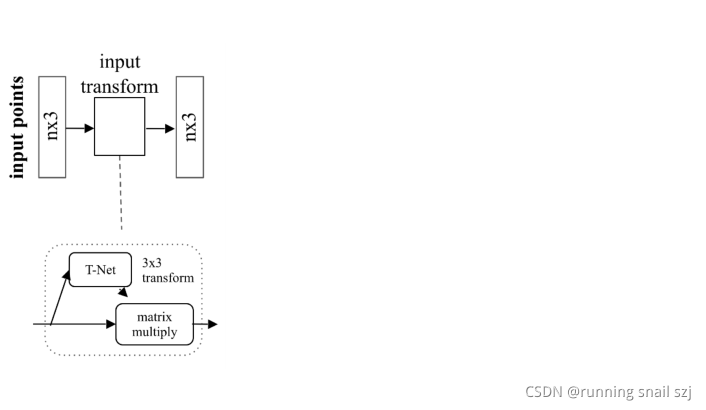
先做輸入的幾何變換,通過一個變換網路生成一個3×3的矩陣做變換,
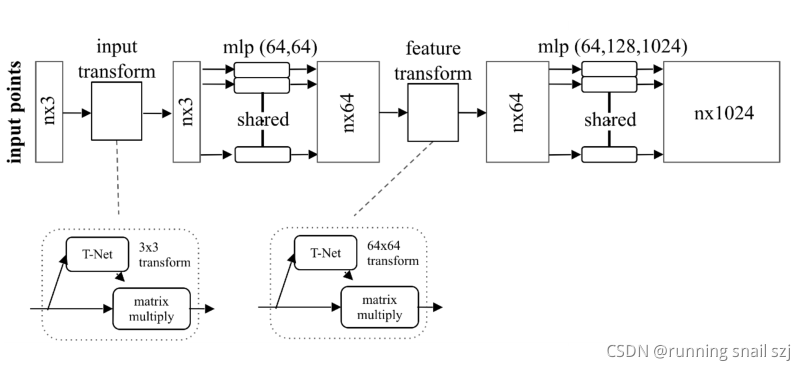
然后通過mlp把每個點投影到64維的高維空間,
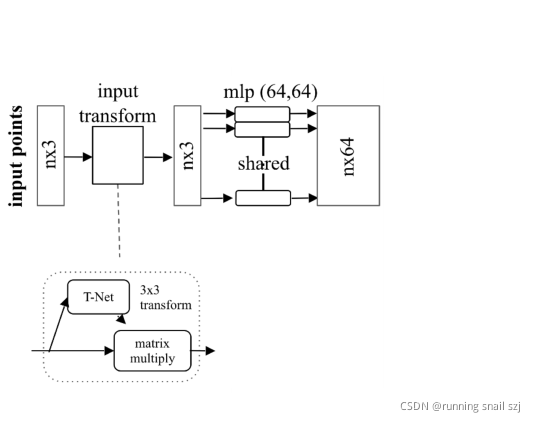
然后在64維中再做一個高維空間的變換,把他變換到更歸一化的64維空間,
然后我們繼續做mlp,把這64維繼續映射到1024維,
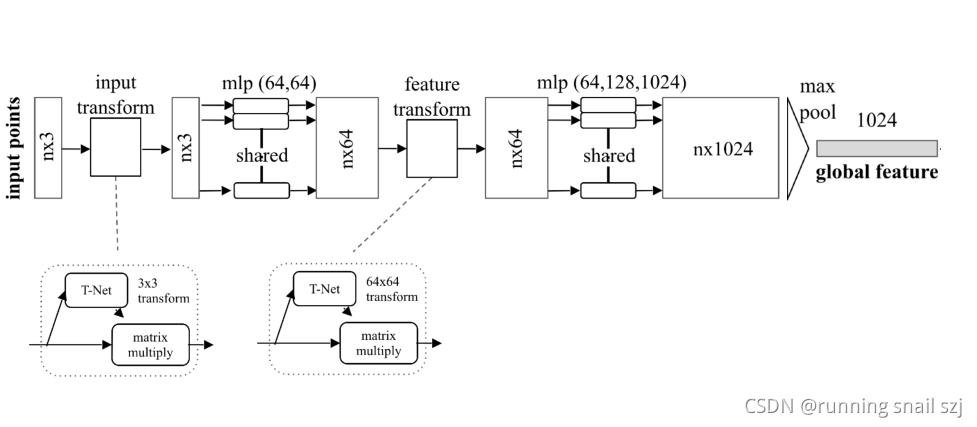
在這1024維中我們可以做對稱性的操作,就是有最大化池化max pool來實作,得到一個global feature全域特征,有1024維,
全域特征繼續處理,我們可以通過級聯的全連接網路,最后生成k個output scores,針對k的class,進行k的class分類,
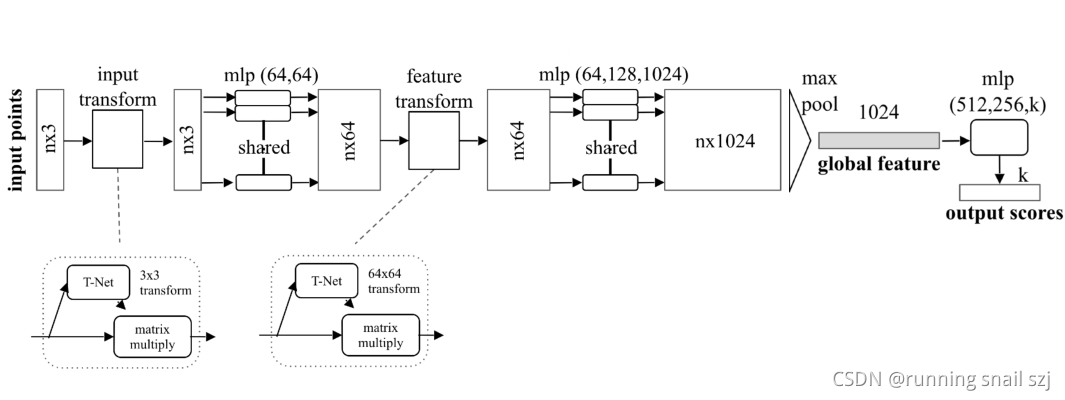
以上就是對點云的分類網路,那如何做對點云的分割呢?
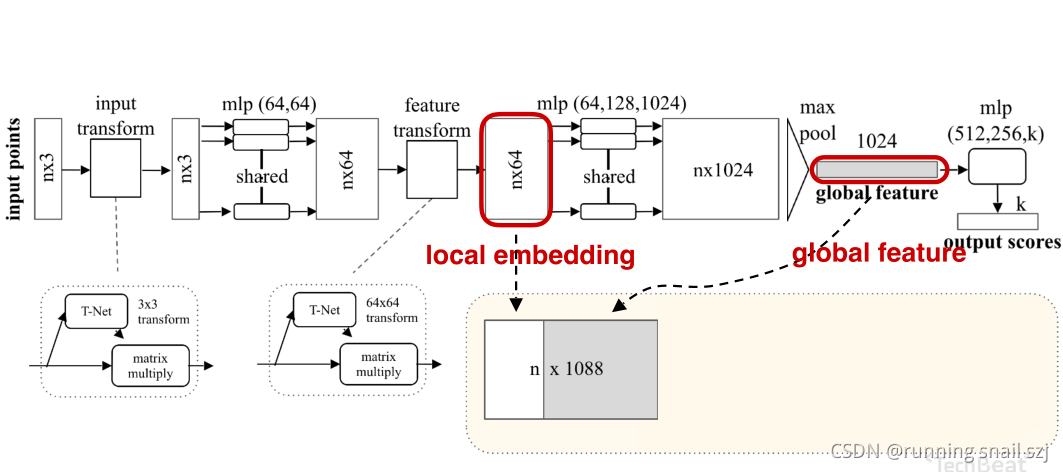
分割可以理解為對每個點的分類問題,如果我們知道每個點的分類,就可以對這個點進行固定類別的分割,通過全域坐標沒法對每個點分割,我們可以把單個點的特征和全域坐標結合起來實作分割的功能,
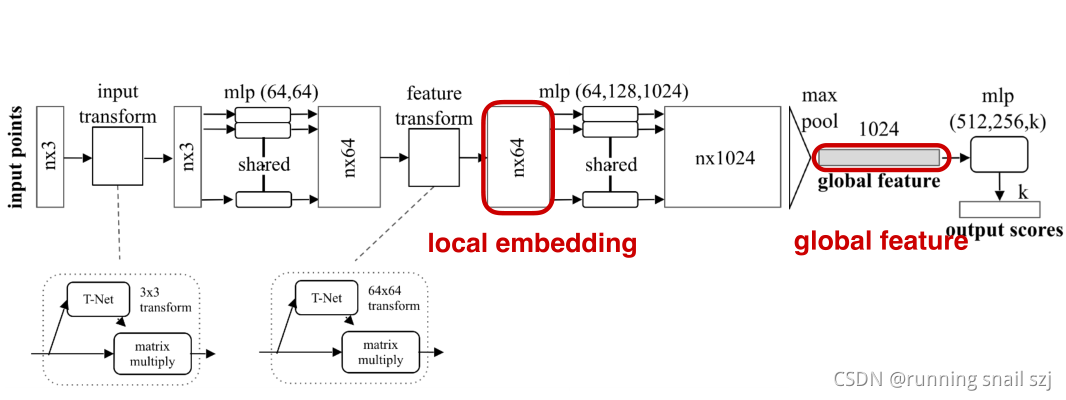
最簡單的做法,我們可以把全域的特征進行進行重復n遍,每一個和原來單個點的特征連接在一起,相當于單個點在全域特征中進行一次檢索,他單個點在全域特征中看自己處于哪一個位置,就可以判斷單個點屬于哪一個類,
對每一個連接起來的特征做mlp的變換
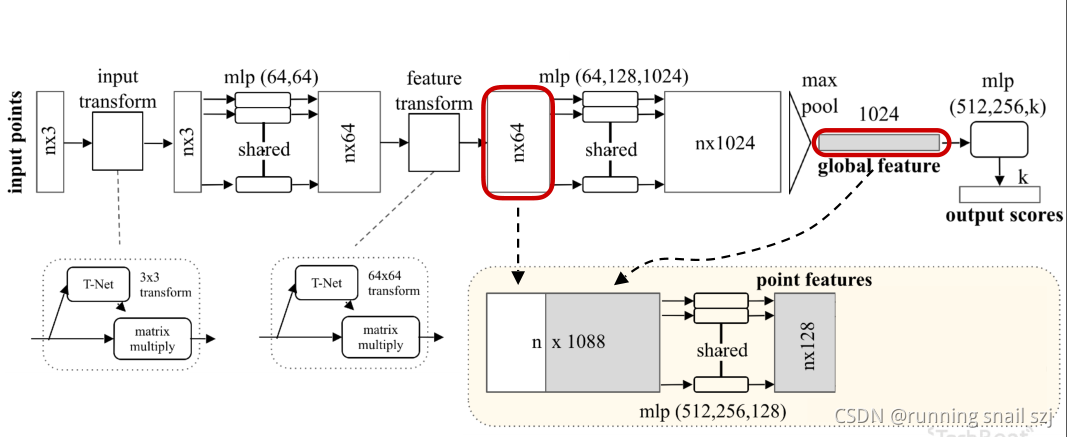
最后把每個點分類成m類,相當于輸出m個scores
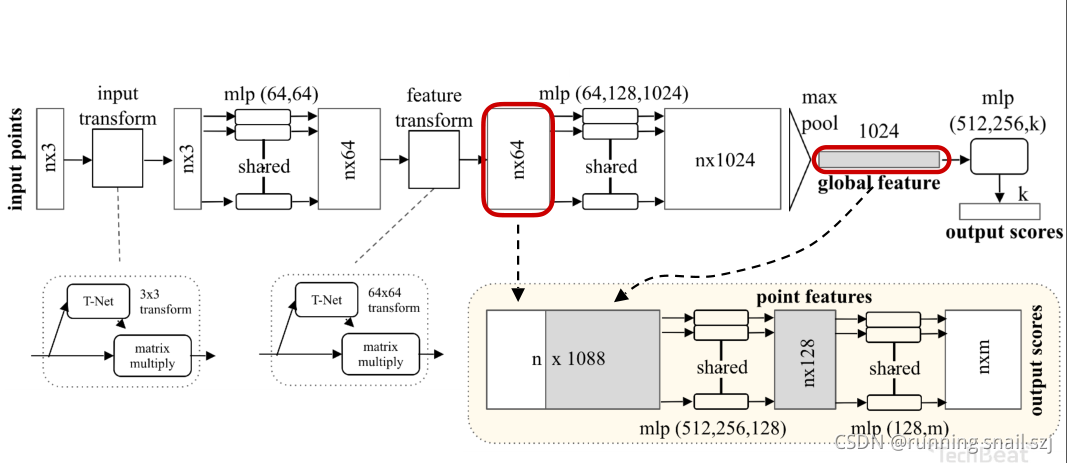
以上為一個分割網路,
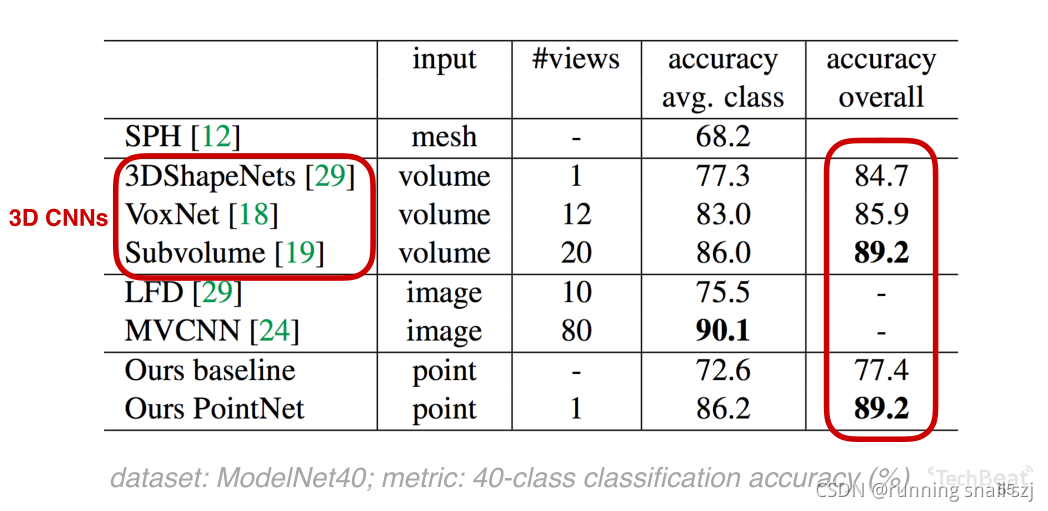
Results on Object Classification
看一下上面網路的結果如何,
這是up主在點云深度學習中最早的一個作業,但是最早的作業和原來的3DCNN一些成熟的相比,在40個物體分類的問題上已經取得了很好的結果,
物體部件分割的可視化,左邊為不全的物體Partial Inputs,右邊為完整的物體Complete Inputs的分割,可以看到耳機可以分割成三個部分(線、架子、耳套),

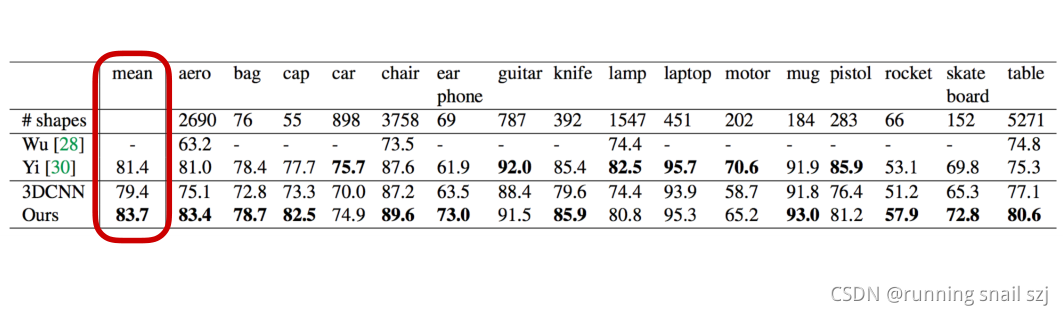
結果上也是明顯好于原來的3DCNN
下面是場景分割的結果,第一行展示的是帶有顏色的點云,雖然表示成圖片,實際上是三維的點云,第二行顯示的是網路分割的結果,可以分割成不同的區域,比如地面藍色、墻壁淡藍色、椅子紅色,

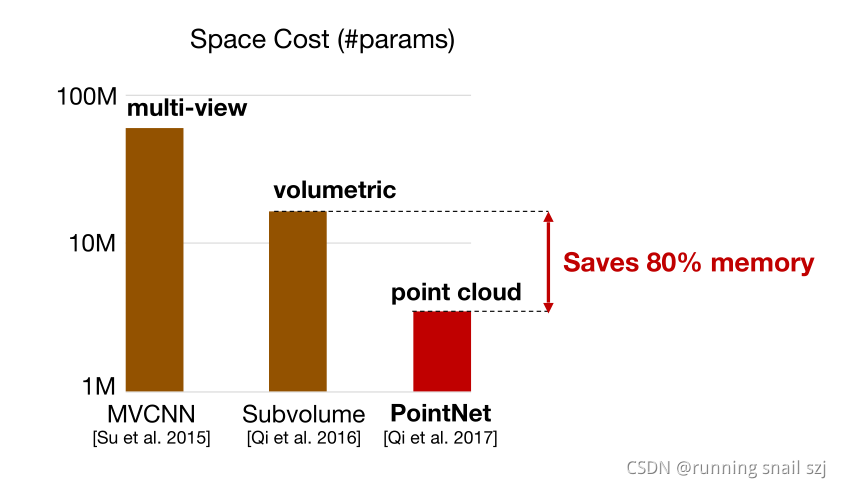
PointNet不僅在理論上很有優異性,而且在實驗室效果很好,而且是一個輕量快速高效的模型,和傳統的基于多視角2DCNN、和基于3D柵格volumetricCNN的方法比,point能大幅提升空間利用效率和計算速度,和經典的volumetric相比可以剩下80%記憶體,
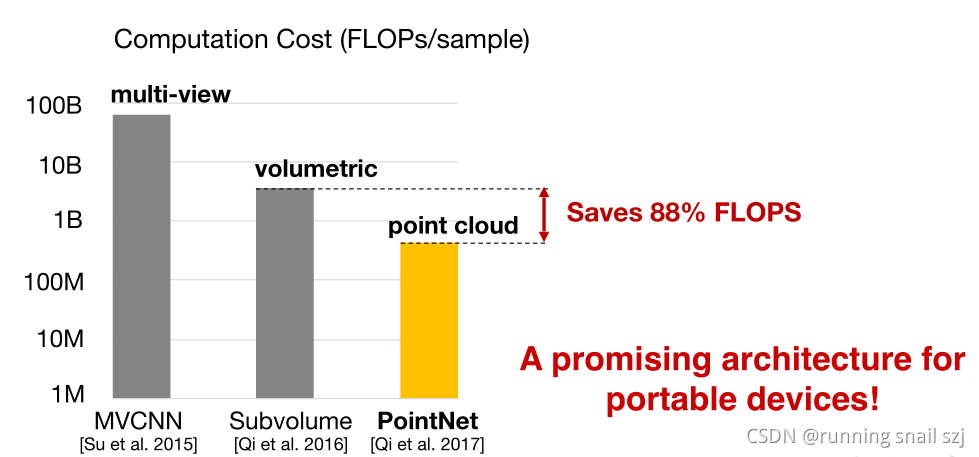
計算上也可以剩下88%的計算量,高效性可用于移動或可穿戴設備
同時對資料的丟失很魯棒,在40分類的問題上,我們看到有50%的點丟失時,pointnet分類精度僅有2%的影響,
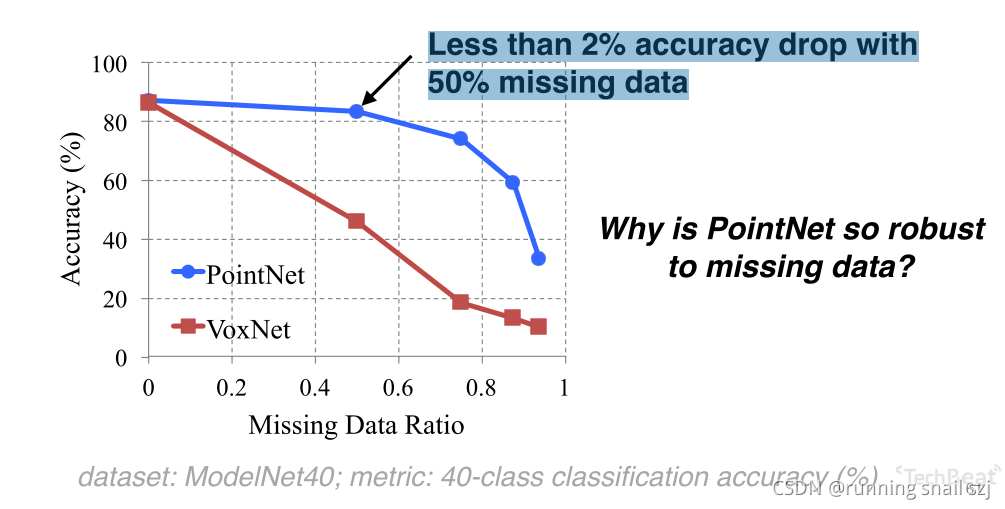
為什么PointNet對于資料的丟失這么魯棒呢?
我們可以通過一個可視化去理解:
第一行為原始的點云輸入,我們有一個最大池化的操作,實際上有些點的特征非常小,經過maxpool后他對全域特征沒做任何貢獻,
其中只有一些Critcal Point關鍵點展示出幾何骨骼的輪廓,這些點保存就可以分類正確,即第二行的點,
所以PointNet對資料的丟失很魯棒,

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/340639.html
標籤:AI