HDFS
—核心引數
1.1 NameNode
記憶體生產配置
1
)
NameNode
記憶體計算
每個檔案塊大概占用
150byte
,一臺服務器
128G
記憶體為例,能存盤多少檔案塊呢?
128 * 1024 * 1024 * 1024 / 150Byte
≈
9.1
億
G MB
KB Byte
2
)
Hadoop2.x
系列,配置
NameNode
記憶體
NameNode
記憶體默認
2000m
,如果服務器記憶體
4G
,
NameNode
記憶體可以配置
3g
,在
hadoop-env.sh
檔案中配置如下,
HADOOP_NAMENODE_OPTS=-Xmx3072m
3
)
Hadoop3.x
系列,配置
NameNode
記憶體
(
1
)
hadoop-env.sh
中描述
Hadoop
的記憶體是動態分配的
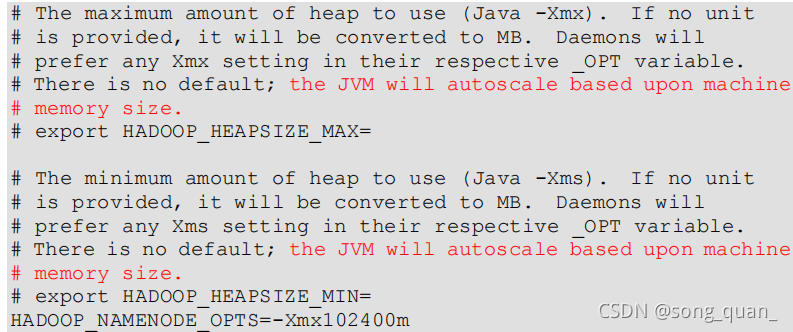
(2)查看
NameNode
占用記憶體
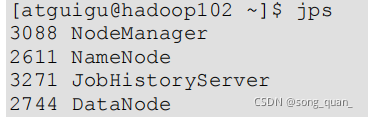

(3)查看
DataNode
占用記憶體

查看發現
hadoop102
上的
NameNode
和
DataNode
占用記憶體都是自動分配的,且相等,
不是很合理,
經驗參考:

具體修改:
hadoop-env.sh
export HDFS_NAMENODE_OPTS="-Dhadoop.security.logger=INFO,RFAS
-
Xmx1024m"
export HDFS_DATANODE_OPTS="-Dhadoop.security.logger=ERROR,RFAS
-Xmx1024m"
1.2 NameNode
心跳并發配置
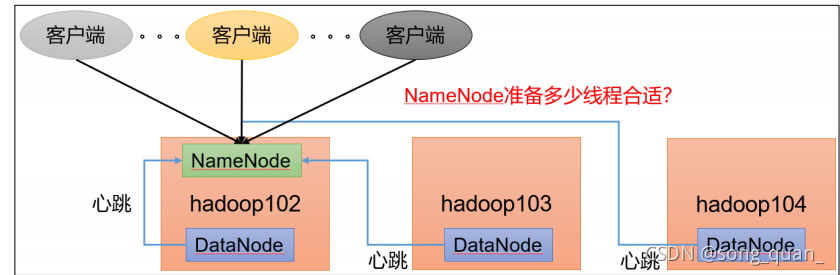
1
)
hdfs-site.xml

數)為
3
臺時,此引數設定為
21
,
計算并發連接數
開啟回收站配置
開啟回收站功能,可以將洗掉的檔案在不超時的情況下,恢復原資料,起到防止誤洗掉、
備份等作用,
1
)回收站作業機制
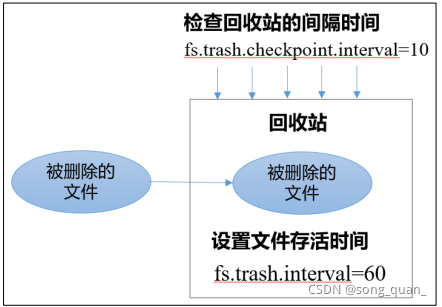
2)開啟回收站功能引數說明
(
1
)默認值
fs.trash.interval = 0
,
0
表示禁用回收站;其他值表示設定檔案的存活時間,
(2)默認值
fs.trash.checkpoint.interval = 0
,檢查回收站的間隔時間,如果該值為
0
,則該
值設定和
fs.trash.interval
的引數值相等,(有時間差,檢查的時間檔案還存在)
(3)要求
fs.trash.checkpoint.interval <= fs.trash.interval
,
3
)啟用回收站
修改
core-site.xml
,配置垃圾回收時間為
1
分鐘,
<property>
<name>fs.trash.interval</name>
<value>1</value>
</property>
4
)查看回收站
回收站目錄在
HDFS
集群中的路徑:
/user/atguigu/.Trash/….
5
)注意:通過網頁上直接洗掉的檔案也不會走回收站,
6
)通程序式洗掉的檔案不會經過回收站,需要呼叫
moveToTrash()
才進入回收站
Trash trash = New Trash(conf);
trash.moveToTrash(path);
7
)只有在命令列利用
hadoop fs -rm
命令洗掉的檔案才會走回收站,
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs
-rm
-r
/user/atguigu/input
2021-07-14 16:13:42,643 INFO fs.TrashPolicyDefault: Moved:
'hdfs://hadoop102:9820/user/atguigu/input' to trash at:
hdfs://hadoop102:9820/user/atguigu/.Trash/Current/user/atguigu
/input
8
)恢復回收站資料
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -mv
/user/atguigu/.Trash/Current/user/atguigu/input
/user/atguigu/input
HDFS
—集群壓測
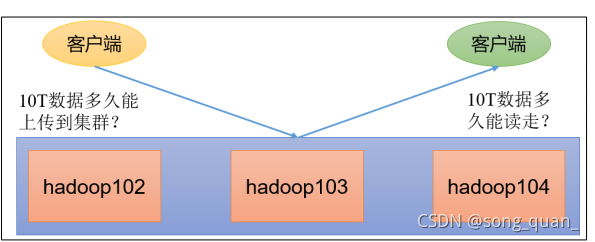
在企業中非常關心每天從
Java
后臺拉取過來的資料,需要多久能上傳到集群?消費者
關心多久能從
HDFS
上拉取需要的資料?
為了搞清楚
HDFS
的讀寫性能,生產環境上非常需要對集群進行壓測,
HDFS
的讀寫性能主要受
網路和磁盤
影響比較大,為了方便測驗,將
hadoop102
、
hadoop103
、
hadoop104
虛擬機網路都設定為
100mbps
,
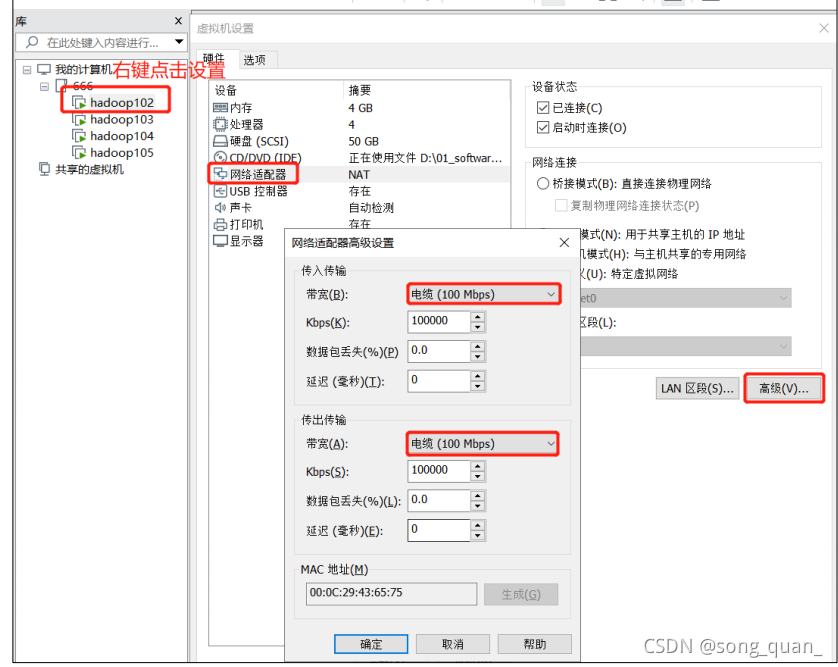
100Mbps 單位是 bit;10M/s 單位是 byte ; 1byte=8bit,100Mbps/8=12.5M/s,
測驗網速:來到
hadoop102
的
/opt/module
目錄,創建一個
[atguigu@hadoop102 software]$ python -m SimpleHTTPServer
測驗
HDFS
寫性能
0)寫測驗底層原理
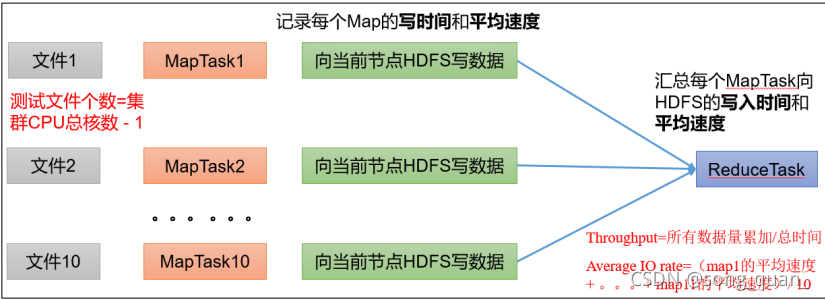
兩個匯總方式,一個是每個節點寫速度相加(分量/分時間),另外一種(總量/總時間)
1)測驗內容:向 HDFS 集群寫 10 個 128M 的檔案
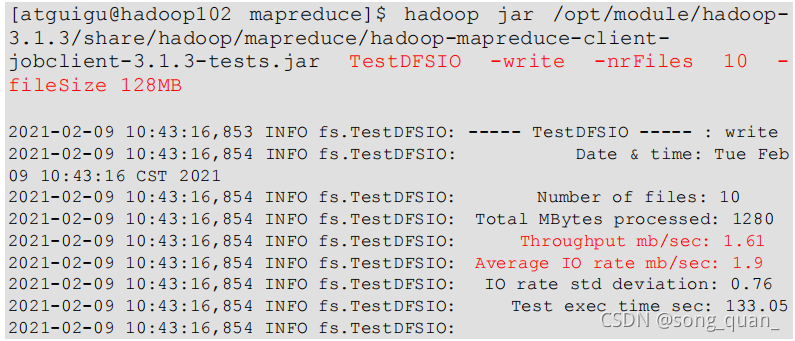
注意:
nrFiles n
為生成
mapTask
的數量,生產環境一般可通過
hadoop103:8088
查看
CPU
核數,設定為(
CPU
核數
- 1
)
引數解釋
?
Number of files
:生成
mapTask
數量,一般是集群中(
CPU
核數
-1
),我們測驗虛
擬機就按照實際的物理記憶體
-1
分配即可
?
Total MBytes processed
:單個
map
處理的檔案大小
?
Throughput mb/sec:
單個
mapTak
的吞吐量
計算方式:處理的總檔案大小
/
每一個
mapTask
寫資料的時間累加
集群整體吞吐量:生成
mapTask
數量
*
單個
mapTak
的吞吐量
?
Average IO rate mb/sec::
平均
mapTak
的吞吐量
計算方式:每個
mapTask
處理檔案大小
/
每一個
mapTask
寫資料的時間
全部相加除以
task
數量
?
IO rate std deviation:
方差、反映各個
mapTask
處理的差值,越小越均衡
(上圖測驗寫結果為1.6mb/s單個maptask)
(
1
)可以在
yarn-site.xml
中設定虛擬記憶體檢測為
false
<!--
是否啟動一個執行緒檢查每個任務正使用的虛擬記憶體量,如果任務超出分配值,則
直接將其殺掉,默認是
true -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
(
2
)分發配置并重啟
Yarn
集群
(yarn的資源檢測中會計算虛擬記憶體,實際的使用,會超過所分配的資源,被yarn停掉)
3
)測驗結果分析
(
1
)由于副本
1
就在本地,所以該副本不參與測驗

一共參與測驗的檔案:
10
個檔案
* 2
個副本
= 20
個()
壓測后的速度:
1.61
實測速度:
1.61M/s * 20
個檔案
≈ 32M/s
三臺服務器的帶寬:
12.5 + 12.5 + 12.5 ≈ 30m/s(100mb帶寬/8bety=12.5mb/b,一臺機器的上傳速度)
所有網路資源都已經用滿,
如果實測速度遠遠小于網路,并且實測速度不能滿足作業需求,可以考慮采用固態硬碟
或者增加磁盤個數,
(2)如果客戶端不在集群節點,那就三個副本都參與計算
測驗
HDFS
讀性能
1
)測驗內容:讀取
HDFS
集群
10
個
128M
的檔案
[atguigu@hadoop102 mapreduce]$ hadoop jar /opt/module/hadoop-
3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-client
jobclient-3.1.3-tests.jar TestDFSIO
-read -nrFiles 10 -fileSize
128MB
2021-02-09 11:34:15,847 INFO fs.TestDFSIO: ----- TestDFSIO ----- : read
2021-02-09 11:34:15,847 INFO fs.TestDFSIO: Date & time: Tue Feb
09 11:34:15 CST 2021
2021-02-09 11:34:15,847 INFO fs.TestDFSIO: Number of files: 10
2021-02-09 11:34:15,847 INFO fs.TestDFSIO: Total MBytes processed: 1280
2021-02-09 11:34:15,848 INFO fs.TestDFSIO: Throughput mb/sec:
200.28
2021-02-09 11:34:15,848 INFO fs.TestDFSIO: Average IO rate mb/sec:
266.74
2021-02-09 11:34:15,848 INFO fs.TestDFSIO: IO rate std deviation: 143.12
2021-02-09 11:34:15,848 INFO fs.TestDFSIO: Test exec time sec: 20.83
2
)洗掉測驗生成資料
[atguigu@hadoop102 mapreduce]$ hadoop jar /opt/module/hadoop-
3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-client
jobclient-3.1.3-tests.jar TestDFSIO -clean
3
)測驗結果分析:為什么讀取檔案速度大于網路帶寬?由于目前只有三臺服務器,且有三
個副本,資料讀取就近原則,相當于都是讀取的本地磁盤資料,沒有走網路,
HDFS
—多目錄(企業使用方案為HA,聯邦)
NameNode
多目錄配置
1
)
NameNode
的本地目錄可以配置成多個,
且每個目錄存放內容相同
,增加了可靠性

2
)具體配置如下
(
1
)在
hdfs-site.xml
檔案中添加如下內容

注意:因為每臺服務器節點的磁盤情況不同,所以這個配置配完之后,可以選擇不分發
(2)停止集群,洗掉三臺節點的
data
和
logs
中所有資料,

(3)格式化集群并啟動,

3)查看結果

檢查 name1 和 name2 里面的內容,發現一模一樣,
DataNode
多目錄配置
1
)
DataNode
可以配置成多個目錄,
每個目錄存盤的資料不一樣
(資料不是副本)

2
)具體配置如下
在
hdfs-site.xml
檔案中添加如下內容

3)查看結果
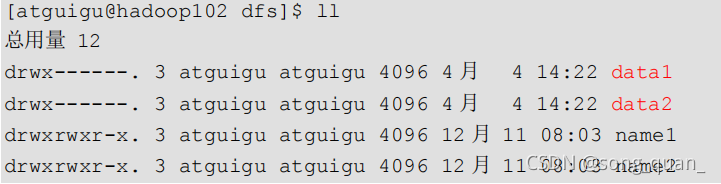
4)向集群上傳一個檔案,再次觀察兩個檔案夾里面的內容發現不一致(一個有數一個沒有)

集群資料均衡之磁盤間資料均衡
生產環境,由于硬碟空間不足,往往需要增加一塊硬碟,剛加載的硬碟沒有資料時,可
以執行磁盤資料均衡命令,(
Hadoop3.x
新特性)

(
1
)生成均衡計劃
(
我們只有一塊磁盤,不會生成計劃
)
hdfs diskbalancer -plan hadoop103
(2)執行均衡計劃
hdfs diskbalancer -execute hadoop103.plan.json
(3)查看當前均衡任務的執行情況
hdfs diskbalancer -query hadoop103
(4)取消均衡任務
hdfs diskbalancer -cancel hadoop103.plan.json
HDFS
—集群擴容及縮容
添加白名單
白名單:表示在白名單的主機
IP
地址可以,用來存盤資料,
企業中:配置白名單,可以盡量防止黑客惡意訪問攻擊,
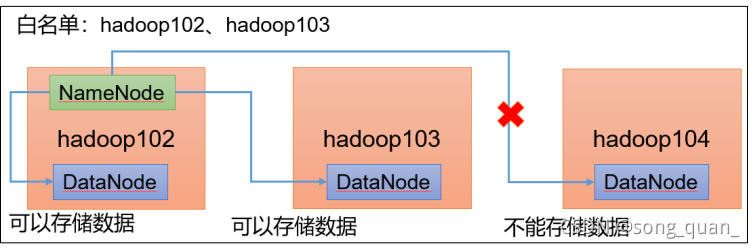
配置白名單步驟如下:
1
)在
NameNode
節點的
/opt/module/hadoop-3.1.3/etc/hadoop
目錄下分別創建
whitelist
和
blacklist
檔案
(
1
)創建白名單
[atguigu@hadoop102 hadoop]$ vim whitelist
在
whitelist
中添加如下主機名稱,假如集群正常作業的節點為
102 103
hadoop102
hadoop103
(2)創建黑名單
[atguigu@hadoop102 hadoop]$ touch blacklist
保持空的就可以
2
)在
hdfs-site.xml
組態檔中增加
dfs.hosts
配置引數
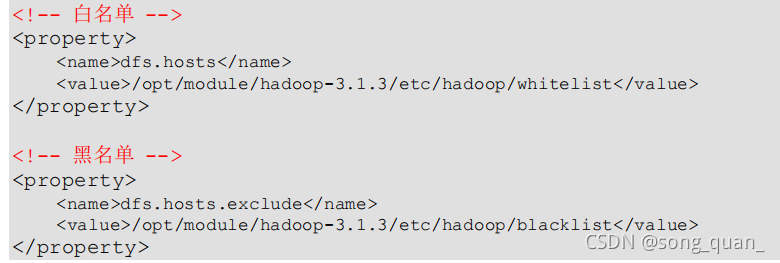
3
)分發組態檔
whitelist
,
hdfs-site.xml
[atguigu@hadoop104 hadoop]$ xsync hdfs-site.xml whitelist
4
)第一次添加白名單必須重啟集群,不是第一次,只需要重繪
NameNode
節點即可
[atguigu@hadoop102 hadoop-3.1.3]$
myhadoop.sh stop
[atguigu@hadoop102 hadoop-3.1.3]$
myhadoop.sh start
5
)在
web
瀏覽器上查看
DN
,
http://hadoop102:9870/dfshealth.html#tab-datanode
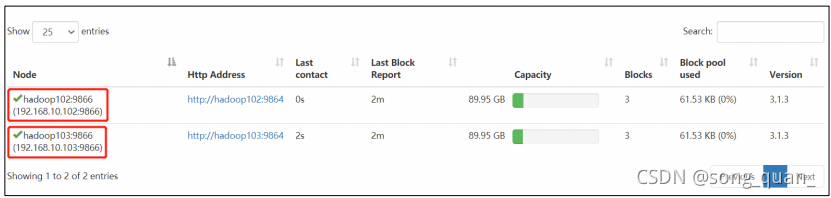
6)在 hadoop104 上執行上傳資料資料失敗
[atguigu@hadoop104 hadoop-3.1.3]$ hadoop fs -put NOTICE.txt /
7
)二次修改白名單,增加
hadoop104
[atguigu@hadoop102 hadoop]$ vim whitelist
修改為如下內容
hadoop102
hadoop103
hadoop104
8
)重繪
NameNode
[atguigu@hadoop102 hadoop-3.1.3]$
hdfs dfsadmin -refreshNodes
Refresh nodes successful
9
)在
web
瀏覽器上查看
DN
,
http://hadoop102:9870/dfshealth.html#tab-datanode
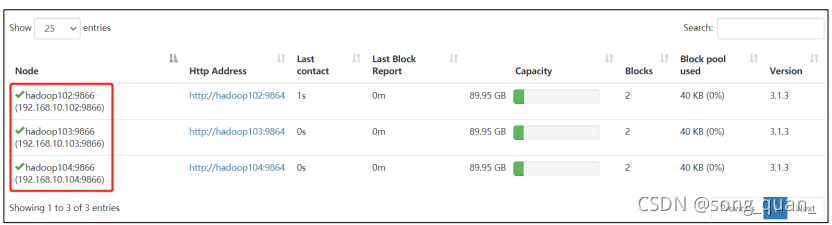
服役新服務器
1
)需求
隨著公司業務的增長,資料量越來越大,原有的資料節點的容量已經不能滿足存盤資料
的需求,需要在原有集群基礎上動態添加新的資料節點,
2
)環境準備
(
1
)在
hadoop100
主機上再克隆一臺
hadoop105
主機
(2)修改
IP
地址和主機名稱

(3)
拷貝
hadoop102
的
/opt/module
目錄和
/etc/profile.d/my_env.sh
到
hadoop105
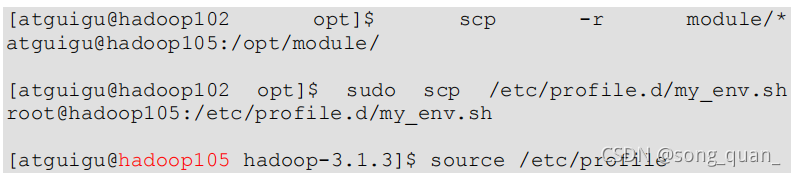
(4)洗掉 hadoop105 上 Hadoop 的歷史資料,data 和 log 資料
[atguigu@hadoop105 hadoop-3.1.3]$ rm -rf data/ logs/
(5)配置
hadoop102
和
hadoop103
到
hadoop105
的
ssh
無密登錄
[atguigu@
hadoop102
.ssh]$ ssh-copy-id hadoop105
[atguigu@
hadoop103
.ssh]$ ssh-copy-id hadoop105
3
)服役新節點具體步驟
(
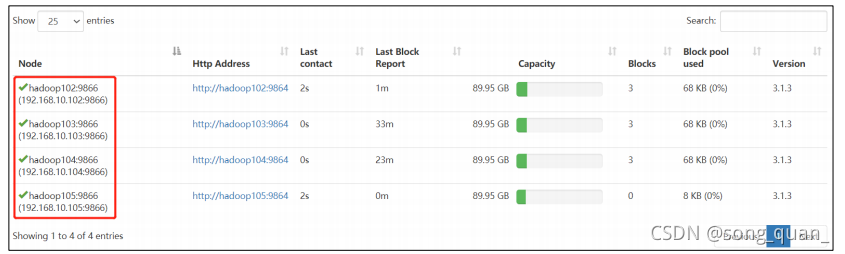
1
)直接啟動
DataNode
,即可關聯到集群

4)在白名單中增加新服役的服務器
(
1
)在白名單
whitelist
中增加
hadoop104
、
hadoop105
,并重啟集群
[atguigu@hadoop102 hadoop]$ vim whitelist
修改為如下內容
hadoop102
hadoop103
hadoop104
hadoop105
(2)分發
[atguigu@hadoop102 hadoop]$ xsync whitelist
(3)重繪
NameNode
[atguigu@hadoop102 hadoop-3.1.3]$
hdfs dfsadmin -refreshNodes
Refresh nodes successful
5
)在
hadoop105
上上傳檔案
[atguigu@hadoop105 hadoop-3.1.3]$ hadoop
fs
-put
/opt/module/hadoop-3.1.3/LICENSE.txt /
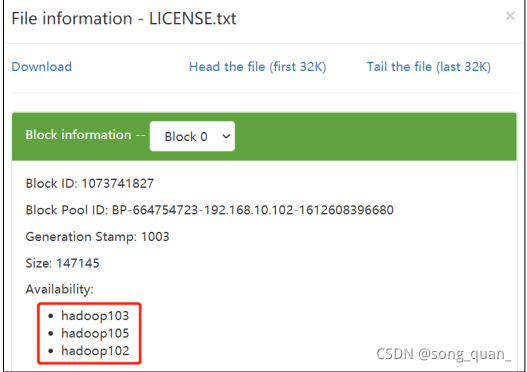
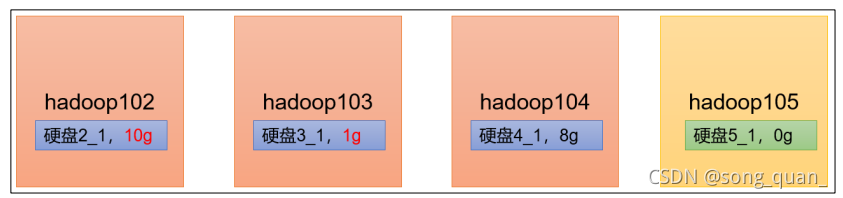
服務器間資料均衡
1
)企業經驗:
在企業開發中,如果經常在
hadoop102
和
hadoop104
上提交任務,且副本數為
2
,由于
資料本地性原則,就會導致
hadoop102
和
hadoop104
資料過多,
hadoop103
存盤的資料量小,
另一種情況,就是新服役的服務器資料量比較少,需要執行集群均衡命令
2)開啟資料均衡命令:
[atguigu@hadoop105 hadoop-3.1.3]$ sbin/start-balancer.sh -
threshold 10
對于引數
10
,代表的是集群中各個節點的磁盤空間利用率相差不超過
10%
,可根據實
際情況進行調整,
3
)停止資料均衡命令:
[atguigu@hadoop105 hadoop-3.1.3]$ sbin/stop-balancer.sh
注意:由于
HDFS
需要啟動單獨的
Rebalance Server
來執行
Rebalance
操作,所以盡量
不要在
NameNode
上執行
start-balancer.sh
,而是找一臺比較空閑的機器,
4.4
黑名單退役服務器
黑名單:表示在黑名單的主機
IP
地址不可以,用來存盤資料,
企業中:配置黑名單,用來退役服務器,
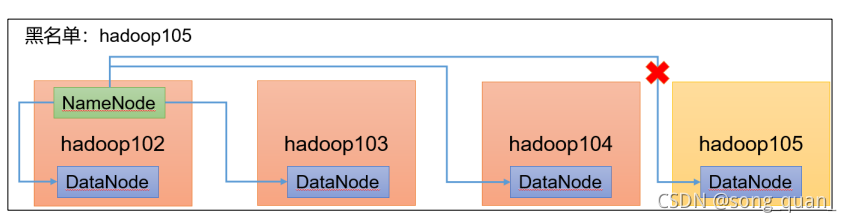
黑名單配置步驟如下:
1
)編輯
/opt/module/hadoop-3.1.3/etc/hadoop
目錄下的
blacklist
檔案
[atguigu@hadoop102 hadoop] vim blacklist
添加如下主機名稱(要退役的節點)
hadoop105
注意:如果白名單中沒有配置,需要在
hdfs-site.xml
組態檔中增加
dfs.hosts
配置引數

2
)分發組態檔
blacklist
,
hdfs-site.xml
[atguigu@hadoop104 hadoop]$ xsync hdfs-site.xml blacklist
3
)第一次添加黑名單必須重啟集群,不是第一次,只需要重繪
NameNode
節點即可
[atguigu@hadoop102 hadoop-3.1.3]$
hdfs dfsadmin -refreshNodes
Refresh nodes successful
4
)檢查
Web
瀏覽器,退役節點的狀態為
decommission in progress
(退役中),說明資料
節點正在復制塊到其他節點

5
)等待退役節點狀態為
decommissioned
(所有塊已經復制完成),停止該節點及節點資源
管理器,注意:如果副本數是
3
,服役的節點小于等于
3
,是不能退役成功的,需要修改
副本數后才能退役
6)如果資料不均衡,可以用命令實作集群的再平衡
[atguigu@hadoop102 hadoop-3.1.3]$ sbin/start-balancer.sh -
threshold 10
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/340682.html
標籤:其他
上一篇:大資料Hadoop集群運行程式