關注公眾號,發現CV技術之美
本文分享 CVPR2021 Oral 論文『HOTR: End-to-End Human-Object Interaction Detection with Transformers』,由 Kakao 提出端到端的Human-Object 互動檢測模型《HOTR》不再需要后處理步驟!
詳細資訊如下:

論文鏈接:https://arxiv.org/abs/2104.13682
專案鏈接:https://github.com/kakaobrain/HOTR
導言:

Human-Object Interaction(HOI)檢測是識別影像中“人-物-互動”的任務,涉及到:1)互動作用中的主體(人)和目標(物件)的定位;2)以及互動標簽的分類, 大多數現有的方法都通過檢測人和物件實體,然后單獨推斷檢測到的每一對實體的關系來間接解決這個任務,
在本文中,作者提出了一個新的框架HOTR,直接基于Transformer編碼器-解碼器結構從影像中預測一組<人、物件、互動>的三元組,通過集合預測,本文的方法有效地利用了影像中固有的語意關系,不需要耗時的后處理步驟,大大提高了該任務的速度,本文提出的演算法在兩個HOI檢測基準資料集測驗中實作了SOTA的性能,并且在目標檢測之后的處理時間只需要1ms,
01
Motivation
Human-Object互動(HOI)檢測任務為預測影像中的<人、物件、互動>三元組的任務,以前的方法通過首先執行目標檢測,并將檢測到的<人、物件>對進行單獨的后處理來預測互動關系,來間接地解決這個任務,但是這種方式非常耗時,并且計算量也非常大,
為了克服HOI檢測器中的冗余計算,最近的方法也提出了并行的HOI檢測器,這些方法可以顯式地定位與任何一個檢測框的互動,通過將區域相互作用與目標檢測結果相關聯,以完成<人、物體、相互作用>三元組的生成,然而,這種方法這種依賴于一些啟發式的設計,比如距離、IoU,來進行human和object之間的匹配,
目前的HOI檢測作業主要存在兩方面的局限性:1)它們需要額外的后處理步驟 ,如抑制相近的重復預測和啟發式的閾值,2)雖然物件之間的建模關系有助于目標檢測,但目前HOI檢測的作業仍然沒有考慮物件之間高級和復雜的互動 ,
基于上面的問題,本文提出了一種快速、準確的HOI演算法HOTR(Human-Object interaction TRansformer),它用DETR中集合預測的方法同時預測場景中的人-物件互動,作者設計了一種基于Transformer的編碼器-解碼器結構來預測一組HOI三元組,這使模型能夠克服以前作業的兩個局限性,
首先,直接的集合預測使HOTR能夠消除手工設計的后處理階段 ,本文的模型以一種端到端方式訓練,通過與Ground-Truth的<人,物體,互動>集合的匹配預測損失函式來優化模型,
其次,Transformer的自注意機制使該模型利用了人和物件之間的背景關系關系以及它們的互動作用 ,從而使得本文的模型更適用于復雜的場景理解,
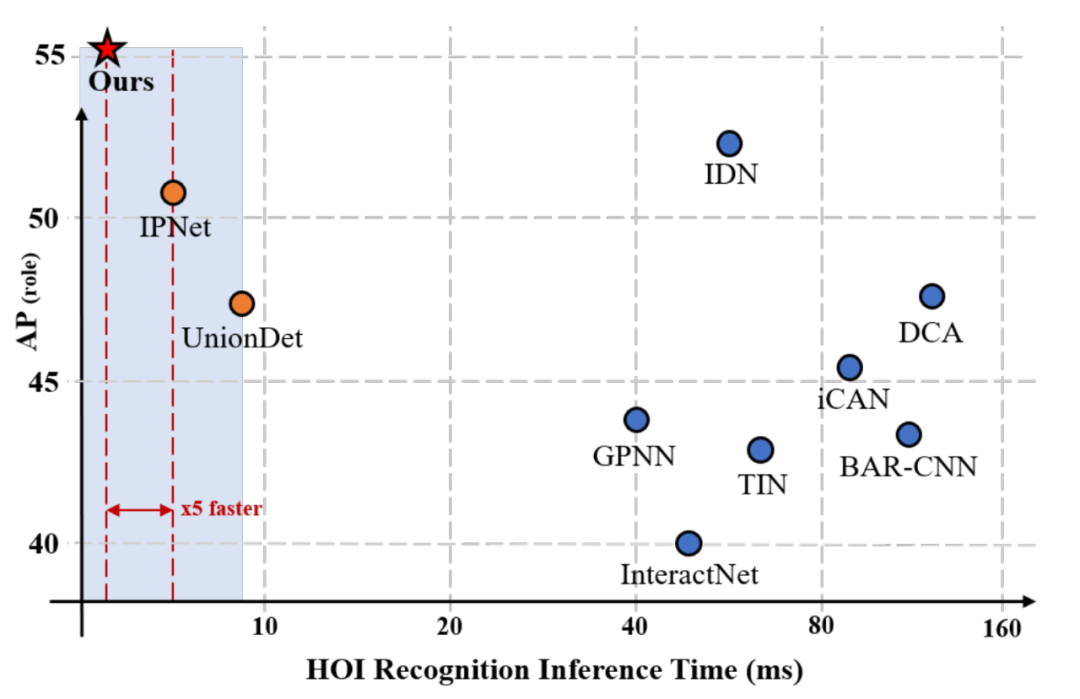
作者在兩個HOI檢測基準資料集(V-COCO和HICO-DET資料集)上評估了本文的模型,與順序和并行的HOI檢測器相比,本文提出的模型在這兩個資料集上實作了SOTA的性能,此外,本文的方法比的其他HOI檢測演算法要快得多,因為它通過直接集合預測消除了耗時的后處理,結果如上圖所示,
02
方法
本文的目標是以端到端的方式建模?人、物件、互動? 之間固有的語意關系,來預測一組?人、物件、互動? 三元組,為了實作這一目標,作者將HOI檢測表述為集合預測問題(類似DETR),在本節中,作者首先討論如何將用于目標檢測的集合預測結構直接擴展到HOI檢測的問題,
然后,作者提出了本文結構HOTR,它并行地預測一組檢測的 目標 ,并將互動作用中的人和物件關聯起來,而Transformer中的自注意用于互動作用之間的關系建模,最后,作者給出了本文模型的訓練細節,包括用于HOI檢測的匈牙利匹配和本文的損失函式,
2.1. Detection as Set Prediction
Object Detection as Set Prediction
DETR將目標檢測作為一個集合預測問題來進行訓練,由于目標檢測包括每個物件的分類和定位,因此DETR中的transformer編碼器-解碼器結構將N個query轉換為了N個目標類別和邊界框的預測,
HOI Detection as Set Prediction
與目標檢測類似,HOI檢測可定義為一組預測問題,其中每個預測包括人區域(即,互動主體)和物件區域(即,互動目標)的定位,以及互動型別的多標簽分類,一個簡單的方法是修改DETR的MLP head,從而使得模型能夠預測來人檢測框、物件檢測框和動作分類,
然而,這種結構帶來了一個新的問題,即同一物件的定位需要通過多個query進行冗余的預測(例如,如果同一個人坐在椅子上在計算機上作業,則兩個不同的查詢必須推斷出同一個人的冗余回歸),
2.2. HOTR architecture
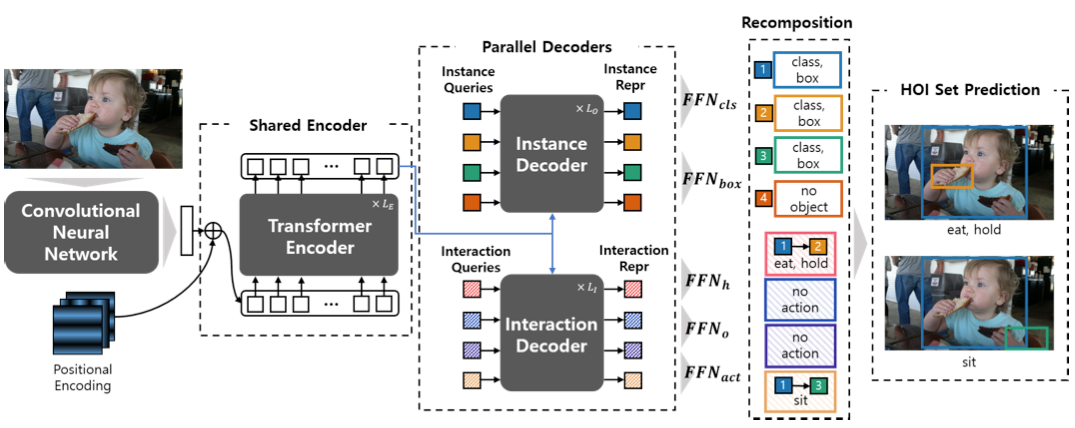
本文的HOTR結構如上圖所示,是一個Transformer編碼器-解碼器結構,具有共享的編碼器和兩個并行的解碼器(即實體解碼器和互動解碼器),基于兩個解碼器的結果,使用本文提出的HO指標(HO Pointers) 生成最終HOI三元組,
Transformer Encoder-Decoder architecture
與DETR類似,全域背景關系特征由主干CNN和共享編碼器從輸入影像中提取,隨后,將兩組查詢向量(即,實體查詢和互動查詢)送到兩個并行解碼器(即,實體解碼器和互動解碼器)中,實體解碼器將實體查詢轉換為實體表示以進行目標檢測 ,而互動解碼器將互動查詢轉換為互動表示用于互動檢測,
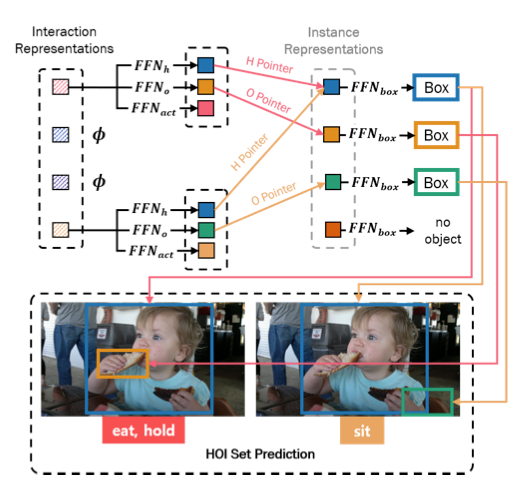
作者將前饋網路(FFN)用于互動表示,并獲得人指標(Human Pointer)、物件指標(Object Pointer)和互動型別(interaction type),如上圖所示,也就是說,互動表示通過使用人指標和物件指標(HO指標)指向相關實體表示來定位人員和物件區域,而不是直接回歸邊界框,與直接回歸方法相比,這樣的結構有幾個優點:
在直接回歸方法中,相同物件的定位因互動的不同會存在不同 ,本文的結構通過使用單獨的實體和互動表示并使用HO指標將它們關聯起來來解決這個問題,
此外,本文的結構允許更有效地學習目標和人的定位,而無需在每次互動中重復學習定位 ,
HO Pointers
上圖展示了HO指標如何關聯實體解碼器和互動解碼器的預測結果,HO指標(即人指標和物件指標)包含互動中人和物件的對應實體表示的索引,當互動解碼器將K個互動查詢轉換為K個互動表示之后,互動表示送入到兩個前饋網路,獲得向量和,人指標和物件指標分別代表與所有實體特征表示相似度最高的人和物件的下標 ,計算如下:
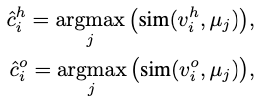
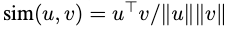
Recomposition for HOI Set Prediction
到目前為止,我們已經計算出了以下變數:1)N個實體特征表示;2)K個互動特征表示和相對應的HO指標,在給定γ互動類的情況下,用于檢測框回歸和動作分類的前饋網路分別表示為:和:γ,然后,通過以下方式獲得第i個互動表示的最終HOI預測:
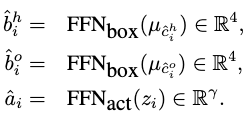
這樣,我們就得到了HOTR最終預測,形式上是K個三元組的集合,,,分別表示?人、物件、互動?,
2.3. Training HOTR
在本節中,作者首先介紹了本文用到的匈牙利匹配演算法,用于獲得Ground Truth HOI三元組和HOI集合預測之間的唯一匹配,然后,基于匹配結果,定義HO指標與最終訓練的損失函式,
Hungarian Matching for HOI Detection
HOTR預測了K個HOI三元組,它由human box、object box和a個類別的動作分類組成,其中,K的值通常大于影像中互動對的數量,這一點與DETR相似,
設Y表示Ground Truth的HOI三元組的集合,代表模型的K個預測,由于K的數量通常比圖片中的互動數量要多,所有Y中不足的部分會用?來進行pad,為了找到這兩個集合之間的二部匹配,作者搜索了K個元素的排列:
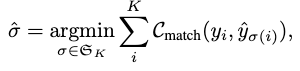
其中,是Ground Truth和下標為σ的預測之間的成對匹配損失,然而,采用?hbox、obox、action?的形式,而σ采用?hidx,oidx,action?的形式,因此我們需要修改一下損失函式,
設:為ground- truth ?hidx,oidx?到ground-truth ?hbox,obox?的映射函式,用于目標檢測的最優分配,使用逆映射:,可以從ground-truth ?hbox,obox?得到ground- truth ?hidx,oidx?,
設表示一組歸一化的實體表示μμ,為Human Pointer的softmax預測集合,計算如下:
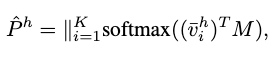
的表示Object Pointer的softmax預測集合,定義與Human Pointer相似,
給定ground-truth,,,并將ground-truth box轉換為下標:???,匹配損失函式計算如下:
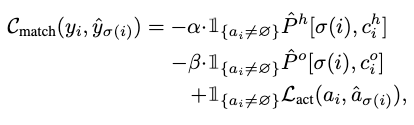
Final Set Prediction Loss for HOTR
然后,作者計算了以上所有匹配對的匈牙利損失,其中HOI三元組的損失具有定位損失和動作分類損失,如下所示:
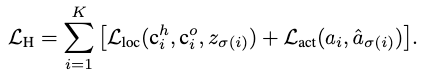
定位損失的具體計算如下:
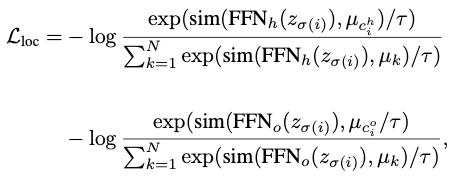
其中τ是控制損失函式平滑度的超引數,
Defining No-Interaction with HOTR
在DETR中,最大化無物件類的Softmax輸出的概率自然會抑制其他類的概率,然而,在HOI檢測中,動作分類是多標簽分類,其中每個動作被視為單獨的二分類,由于缺少可以抑制冗余預測的顯式類,HOTR會得到同一個?human,object?對的多個預測,因此,HOTR設定學習互動性的顯式類(如果對之間存在互動,則為1,否則為0),抑制低互動性分數的冗余對的預測,
03
實驗
3.1. Quantitative Analysis
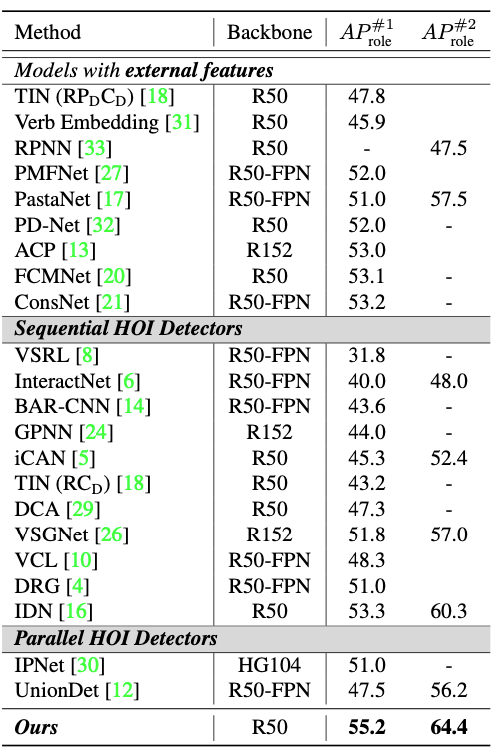
上表顯示了本文方法在V-COCO資料集上和其他SOTA方法的對比,可以看出,本文的方法在性能上遠超以前的SOTA方法,
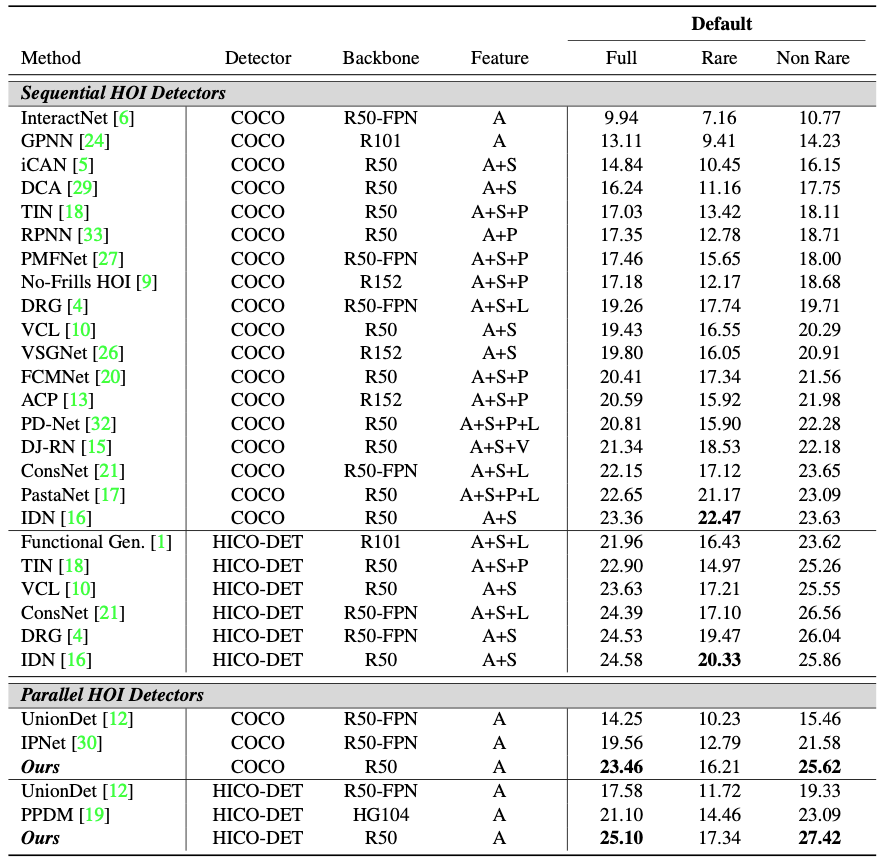
上表顯示了本文方法在HICO-DET資料集上和其他SOTA方法的對比,在全體測驗集和常見的樣本上,本文方法的性能都比以前的方法要好,但是在出現比較少的樣本上,本文的方法不如一些以前的方法,
3.2. Ablation Study
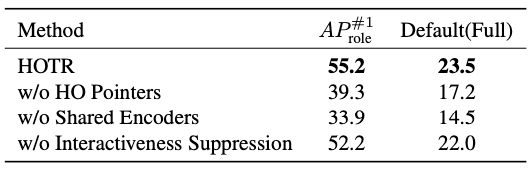
With vs Without HO Pointers
在HOTR中,互動表示通過使用人指標和物件指標(HO指標)指向相關實體表示來定位人和物件區域,而不是直接回歸邊界框,從上表可以看出,HO指標對于性能的提升還是非常重要的,
Shared Encoder vs Separate Encoders
在本文中,作者采用了共享的Encoder,為了探究共享Encoder的作用,作者還試了用分開的Encoder,結果如上圖所示,可以看出,共享的Encoder能夠達到更高的性能,
With vs Without Interactiveness Suppression
HOTR設定了一個學習互動性的顯式類,來抑制對概率較低的冗余對的預測,上表顯示,為互動性設定顯式類有助于提升最終的性能,
04
總結
本文提出了用于解決human-object互動問題中的第一個基于Transformer的集合預測方法HOTR,HOTR的集合預測方法消除了以前HOI檢測器手工設計的后處理步驟,同時能夠對相互作用之間的相關性進行建模,
為了使得Transformer能夠適應HOI檢測任務,作者提出了多種HOTR的訓練和推理技術:采用并行解碼器進行HOI分解訓練 ,基于相似度的層重組進行推理 ,以及抑制互動性,作者還開發了一種新的基于集合的匹配來檢測HOI,它將互動表示與實體表示相關聯,在HOI檢測任務中,HOTR在兩個基準資料集上實作了SOTA的性能,并且推理時間低于1ms,明顯快于以前的并行HOI檢測器(5~9ms),
個人覺得,這篇文章與EMNLP2021的《On Pursuit of Designing Multi-modal Transformer for Video Grounding》有異曲同工之妙,避免了以前方法手工設計的后處理模塊,基于DETR的思想,將整個任務處理為一個端到端的方式,大大提升了模型的精度和推理速度,
▊ 作者簡介
研究領域:FightingCV公眾號運營者,研究方向為多模態內容理解,專注于解決視覺模態和語言模態相結合的任務,促進Vision-Language模型的實地應用,
知乎/公眾號:FightingCV

END
歡迎加入「人物互動」交流群👇備注:HOI

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/341993.html
標籤:其他