文章目錄
- CNN存在的問題
- Spatial Transformer
- 方法
- Localisation Network
- Parameterised Sampling Grid
- Differentiable Image Sampling
- 例程
- 附錄
- 幾種常用的線性變換
- 雙線性插值
CNN存在的問題
CNN定義了非常強大的分類模型,但是仍然受到缺乏在計算和引數效率上對輸入資料空間不變性能力的限制,即,當輸入影像因隨機平移、縮放、旋轉、混亂而失真時,CNN模型的分類準確率將會下降,
Spatial Transformer
它是對CNN的改進, 增加了一個Spatial Transformer 模塊, 可以對網路內的資料進行空間操作(spatial manipulation). 這個模塊可以插入到現有的CNN模塊中, 使得網路能夠主動的空間變換feature maps, 通過訓練確定特定輸入對應的空間變換
使用空間變換器的結果是模型能夠學習到了對平移、縮放、旋轉和更多通用的warping的不變性,得到最先進的性能.
它在這幾個方面可以受益:
- 影像分類
- co-localisation(共同定位?), 給定一個包含相同但未知的類的不同實體的影像, 它可以被用于localise, … 不太理解這個地方2333
- spatial attention: spatial transformer可以用于需要注意力機制的任務
方法
The spatial transformer被分成3個部分, 第一個是localisation network, 它把feature map作為輸入, 通過一系列隱層, 輸出一些應該被用于spatial transformation的引數,
在第二部分 grid generator中, 這些被預測的引數被用于創造sampling grid, 這是一組點, 輸入的map應該被這些點采樣成transformed output
最后feature map和 sampling grid 作為sampler的輸入, 產生在grid points從輸入采樣的輸出map
總結來說:
它完成的是一個將輸入特征圖進行一定的變換的程序,而具體如何變換,是通過在訓練程序中學習來的,更通俗地將,該模塊在訓練階段學習如何對輸入資料進行變換更有益于模型的分類,然后在測驗階段應用已經訓練好的網路對輸入資料進行執行相應的變換,從而提高模型的識別率,
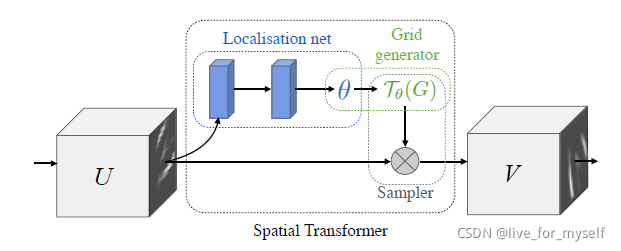
Localisation Network
U
∈
R
H
?
W
?
C
U\text∈ R^{H*W*C}
U∈RH?W?C: 輸入特征圖
θ
\theta
θ: 被用在feature map上的 transformation
T
θ
T_{\theta}
Tθ? 的引數,
θ
=
f
l
o
c
(
U
)
\theta \text= f_{loc}(U)
θ=floc?(U),
t
h
e
t
a
theta
theta的大小依賴于transformation的型別, 比如對于二維仿射變換是6維度
對于仿射變換的相關知識參照附錄
localisation network function f l o c ( ) f_{loc}() floc?() 可以是任何形式, fc 或者CNN都行, 但是最后應該有個regression layer來產生 θ \theta θ
Parameterised Sampling Grid
該層利用Localisation 層輸出的變換引數 θ \theta θ,將輸入的特征圖進行變換
例如輸出特征圖上某一位置 ( x i t , y i t ) (x^t_i, y^t_i) (xit?,yit?)根據變換引數 θ θ θ映射到輸入特征圖上某一位置 ( x i s , y i s ) (x^s_i,y^s_i) (xis?,yis?),具體如下:
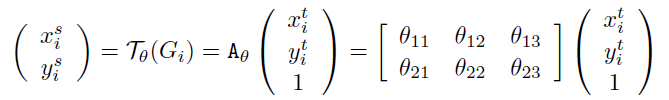
這里使用高度和寬度的歸一化坐標
Differentiable Image Sampling
為了對輸入feature map進行變換, 采樣器需使用采樣點 T θ ( G ) T_{\theta}(G) Tθ?(G) 的集合與輸入特征圖U一起來生成采樣的輸出特征圖, 輸出公式如下:
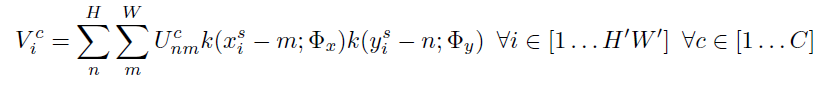
Φ x , Φ y \Phi_x, \Phi_y Φx?,Φy? 是一個通用的采樣內核k()的引數,它定義了影像的插值(例如,雙線性, 整數),
U
n
m
C
U_{nm}^C
UnmC?is the value at location (n;m) in channel c of the input
V
i
c
V_i^c
Vic? is the output value for pixel i at location
(
x
i
t
;
y
i
t
)
(x^t_i; y^t_i )
(xit?;yit?) in channel c
請注意,每個輸入通道的采樣是相同的,因此每個通道都以相同的方式進行轉換(這保留了通道之間的空間一致性)
文章指出, 任何可以定義梯度的采樣器都可以使用,比如:
整數采樣核
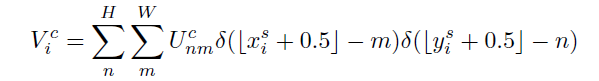
雙線性sampling kernel
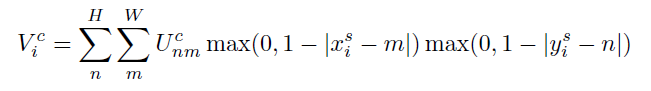
對應的導數為:
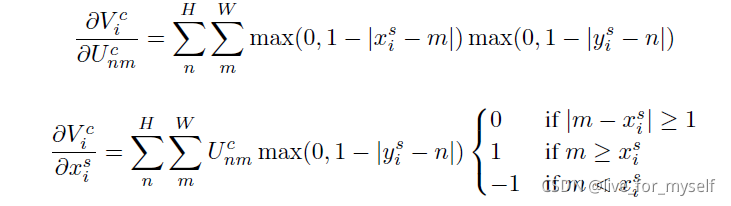
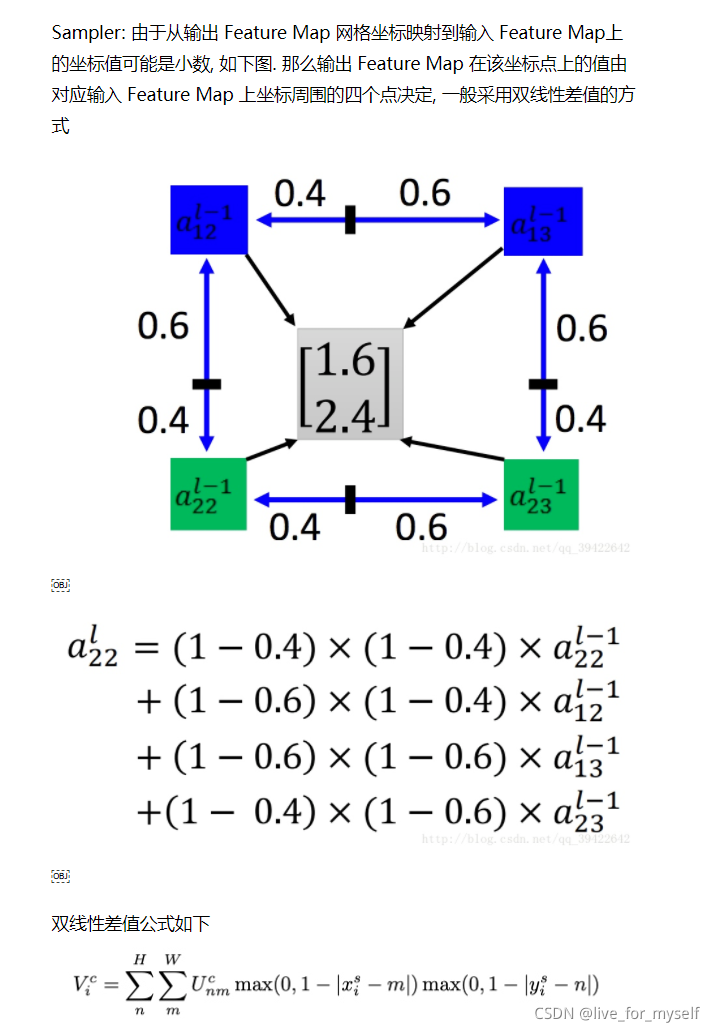
例程
在pytorch框架中, F.affine_grid 與 F.grid_sample(torch.nn.functional as F)聯合使用來對影像進行變形,
F.affine_grid 根據形變引數產生sampling grid,F.grid_sample根據sampling grid對影像進行變形,
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.conv2_drop = nn.Dropout2d()
self.fc1 = nn.Linear(320, 50)
self.fc2 = nn.Linear(50, 10)
# Spatial transformer localization-network
self.localization = nn.Sequential(
nn.Conv2d(1, 8, kernel_size=7),
nn.MaxPool2d(2, stride=2),
nn.ReLU(True),
nn.Conv2d(8, 10, kernel_size=5),
nn.MaxPool2d(2, stride=2),
nn.ReLU(True)
)
# Regressor for the 3 * 2 affine matrix
self.fc_loc = nn.Sequential(
nn.Linear(10 * 3 * 3, 32),
nn.ReLU(True),
nn.Linear(32, 3 * 2)
)
# Initialize the weights/bias with identity transformation
self.fc_loc[2].weight.data.zero_()
self.fc_loc[2].bias.data.copy_(torch.tensor([1, 0, 0, 0, 1, 0], dtype=torch.float))
# Spatial transformer network forward function
def stn(self, x):
xs = self.localization(x)
xs = xs.view(-1, 10 * 3 * 3)
theta = self.fc_loc(xs)
theta = theta.view(-1, 2, 3)
grid = F.affine_grid(theta, x.size())
x = F.grid_sample(x, grid)
return x
def forward(self, x):
# transform the input
x = self.stn(x)
# Perform the usual forward pass
x = F.relu(F.max_pool2d(self.conv1(x), 2))
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
x = x.view(-1, 320)
x = F.relu(self.fc1(x))
x = F.dropout(x, training=self.training)
x = self.fc2(x)
return F.log_softmax(x, dim=1)
model = Net().to(device)
附錄
此處參見仿射變換
幾種常用的線性變換

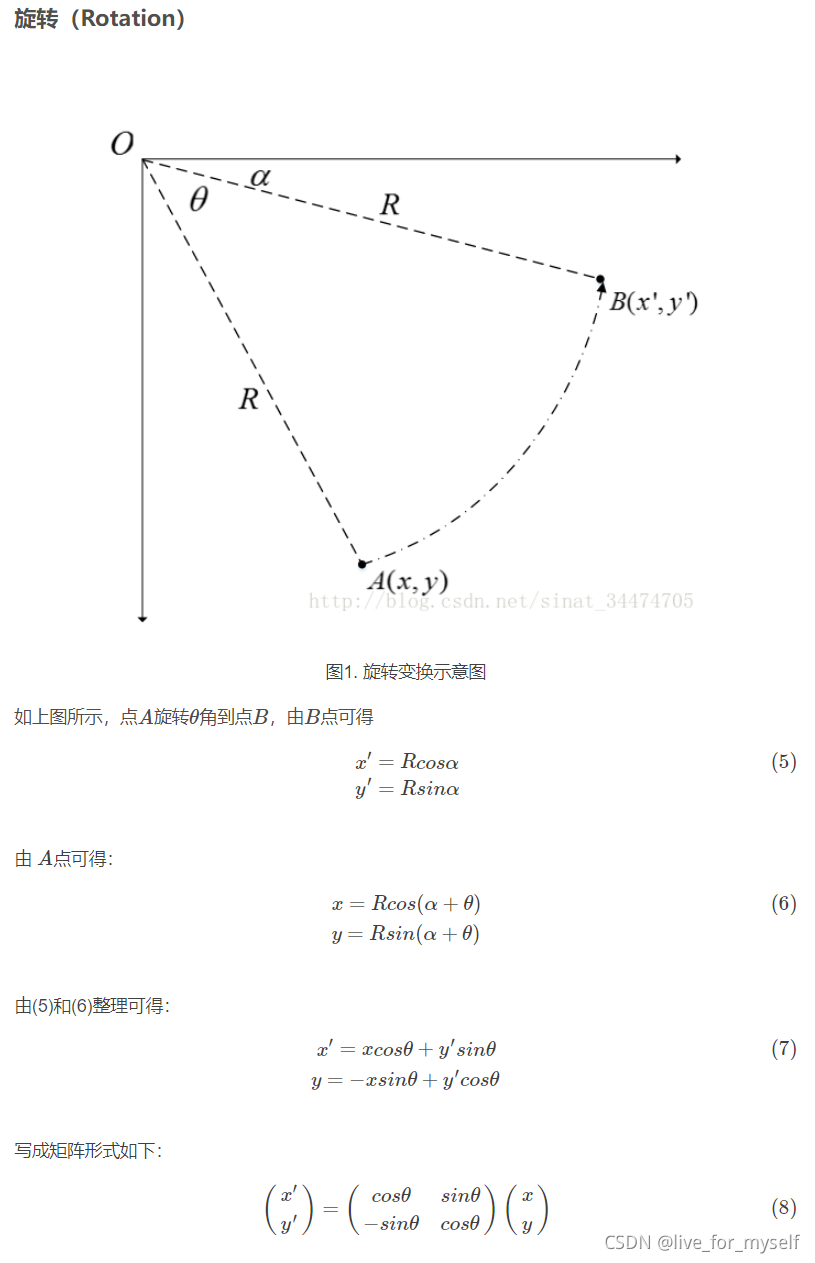
- 這里可以倒著理解, 比如從B點逆時針旋轉, 就好算很多

雙線性插值
在對影像進行仿射變換時,會出現一個問題,當原影像中某一點的坐標映射到變換后影像時,坐標可能會出現小數(如下圖所示),而我們知道,影像上某一像素點的位置坐標只能是整數,那該怎么辦?這時候雙線性插值就起作用了,
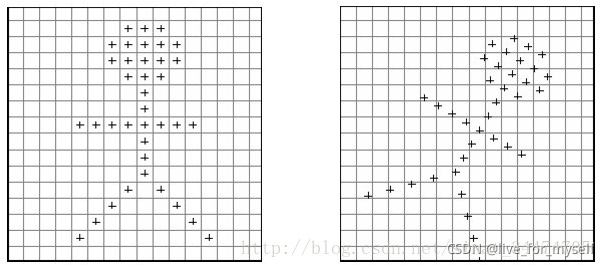
雙線性插值的基本思想是通過某一點周圍四個點的灰度值來估計出該點的灰度值
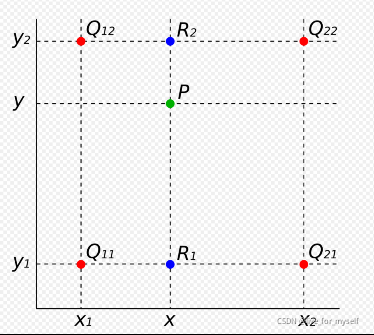
在實作時我們通常將變換后影像上所有的位置映射到原影像計算(這樣做比正向計算方便得多),即依次遍歷變換后影像上所有的像素點,根據仿射變換矩陣計算出映射到原影像上的坐標(可能出現小數),然后用雙線性插值,根據該點周圍4個位置的值加權平均得到該點值,程序可用如下公式表示:
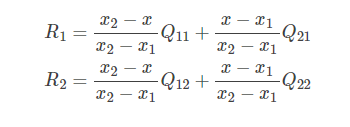
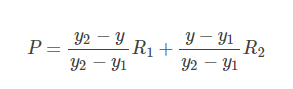
把R1, R2代入, 得:
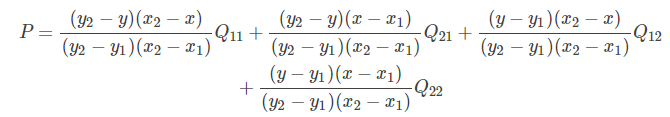
因為
Q
11
,
Q
12
,
Q
21
,
Q
22
Q_{11},Q_{12},Q_{21},Q_{22}
Q11?,Q12?,Q21?,Q22? 是相鄰的四個點,所以
y
2
?
y
1
=
1
,
x
2
?
x
1
=
1
y_2?y_1=1, x_2?x_1=1
y2??y1?=1,x2??x1?=1,則上式可化簡為:
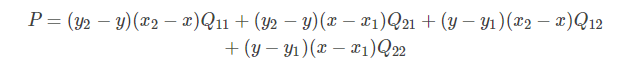
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/341994.html
標籤:其他
上一篇:CVPR2021 Oral | HOTR:不再需要后處理!Kakao Brain提出端到端Human-Object互動檢測模型...