曾經有個人給我說過,當年有個男的追她,天天給她發天氣預報,但是女神不會看天氣預報啊?或者她不會抬頭望望天啊?于是秉持著舔到最后應有盡有,偷懶是人類進步的最大動力這兩大原則,我為女神訓練出了一個專屬的衣服穿搭神經網路,
整個專案已開源至github:https://github.com/Balding-Lee/PyTorch-MLP-for-personalized-dress-matching,
目錄
- 1 資料獲取
- 2 資料處理
- 3 模型定義與訓練
- 3.1 模型定義
- 3.2 評價指標與損失函式
- 3.3 訓練模型
- 3.4 模型評估
- 4 測驗API
1 資料獲取
資料爬取的網站為:http://www.tianqihoubao.com/lishi/chengdu/month/202001.html,從2020年1月爬取到了2021年10月,由于網站服務器較垃圾,導致2020年9月資料沒有爬取下來,一共575條資料,通過人工標注的方式,將這575條資料分到了11類中,由于一個人一天不止會穿一件衣服(因為有衣服,褲子,鞋子),所以每條資料中都會有多個1的出現,
爬取的資料如下:
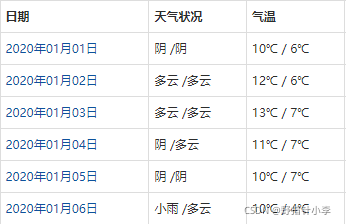
包括的特征有:季節、當日最高氣溫、當日最低氣溫、早晨的天氣、晚間的天氣,
2 資料處理
資料處理的目標主要是為了能夠把資料給嵌入到神經網路輸入層中,除了基本的切割與清理無關字符以外,我們需要著重處理的特征有:季節、早晨的天氣、晚間的天氣,
因為這些資料都是離散資料,所以最簡單的方式就是通過one-hot編碼的方式對其進行嵌入,首先我們用最簡單的規則來對日期進行劃分,其中11 - 02為冬天,02 - 05為春天,05 - 08為夏天,08 - 11為秋天,這樣其實是不太準確的,如果想要盡可能準確,則應該把每一年的立春立秋這些給爬取下來,而對應的天氣,我們則不用特殊處理,只需將兩者合并起來再去重,這樣處理下來,季節和天氣的資料分別為:
seasons = ['春', '夏', '秋', '冬']
weathers = ['中雨', '多云', '大暴雨', '大雨', '小雨', '晴', '暴雨', '陰', '陣雨', '雷陣雨']
由于后續我們還需要onehot編碼格式,所以這里我們不直接采用sklearn的OneHotEncoder對所有資料直接編碼,而是尋找id與onehot編碼之間的映射關系:
def get_id_char_mapping(char_list):
"""
獲得id與詞的映射關系
:param char_list: list
詞串列
:return idx2char: dict
{id1: 'char1', id2: 'char2', ...}
id與詞之間的映射關系
:return char2idx: dict
{'char1': id1, 'char2': id2, ...}
詞與id之間的映射關系
"""
idx2char, char2idx = {}, {}
char_set = set(char_list) # 去重
for i, char_ in enumerate(char_set):
idx2char[i] = char_
char2idx[char_] = i
return idx2char, char2idx
def get_seq2idx(sequence, char2idx):
"""
將序列資料映射為id
:param sequence: list
序列資料
:param char2idx: dict
{'char1': id1, 'char2': id2, ...}
詞與id之間的映射關系
:return sequence2idx: list
映射為id后的序列資料
"""
sequence2idx = []
for char_ in sequence:
sequence2idx.append(char2idx[char_])
return sequence2idx
def onehot_encode_seq(onehot_encoder, sequence):
"""
對序列進行one-hot編碼
:param onehot_encoder: ndarray
onehot編碼器
:param sequence: list
需要編碼的序列
:return onehot: ndarray
onehot編碼后的序列
"""
onehot = np.zeros((len(sequence), len(onehot_encoder)))
for i, id_ in enumerate(sequence):
onehot[i] = onehot_encoder[id_]
return onehot
def encode_data(seasons, weather_mornings, weather_nights):
"""
對資料進行編碼, 將季節和天氣編碼為one-hot
季節: shape: (4, 4)
天氣: shape: ()
:param seasons: list
季節
:param weather_mornings: list
早晨天氣
:param weather_nights: list
晚間天氣
:return season_onehot: ndarray
shape: (num_days, 4)
季節的one-hot編碼
:return weather_mornings_onehot: ndarray
shape: (num_days, 10)
早晨天氣的one-hot編碼
:return weather_nights_onehot: ndarray
shape: (num_days, 10)
晚間天氣的one-hot編碼
"""
onehot_encoder = OneHotEncoder() # one-hot編碼器
idx2season, season2idx = get_id_char_mapping(seasons)
season_onehot_encoder = onehot_encoder.fit_transform(
np.array(list(idx2season.keys())).reshape(-1, 1)
).toarray() # 獲得season的one-hot編碼
season_seq2idx = get_seq2idx(seasons, season2idx) # 將sequence轉為id
# 根據id與one-hot的映射關系將sequence轉為one-hot編碼
season_onehot = onehot_encode_seq(season_onehot_encoder, season_seq2idx)
weather = []
weather.extend(weather_mornings)
weather.extend(weather_nights)
idx2weather, weather2idx = get_id_char_mapping(weather)
weather_onehot_encoder = onehot_encoder.fit_transform(
np.array(list(idx2weather.keys())).reshape(-1, 1)
).toarray()
weather_mornings_seq2idx = get_seq2idx(weather_mornings, weather2idx)
weather_nights_seq2idx = get_seq2idx(weather_nights, weather2idx)
weather_mornings_onehot = onehot_encode_seq(weather_onehot_encoder,
weather_mornings_seq2idx)
weather_nights_onehot = onehot_encode_seq(weather_onehot_encoder,
weather_nights_seq2idx)
return season_onehot, weather_mornings_onehot, weather_nights_onehot
這里我們還是傳統的處理方式,先做一個id與詞之間的映射關系,通過該映射關系,得到其onehot編碼,以季節舉例,會得到如下的結果:
idx2season = {0: '夏', 1: '秋', 2: '春', 3: '冬'}
season2idx = {'夏': 0, '秋': 1, '春': 2, '冬': 3}
season_onehot_encoder = array([[1., 0., 0., 0.],
[0., 1., 0., 0.],
[0., 0., 1., 0.],
[0., 0., 0., 1.]])
也就是說夏的onehot編碼為season_onehot_encoder[0],這個0正好對應season2idx中夏的值,我們有了這個映射關系后,就可以將整個輸入序列都編碼為onehot了,首先將資料集中的所有季節全部映射為id,再根據這個id來找season_onehot_encoder中的onehot編碼,而weather也是同理,只不過由于資料集中weather_morning與weather_night中有幾個標簽是不一樣的,為了保證輸入層輸入的統一性,所以在onehot編碼時是將兩者給合并起來再做的去重處理,而onehot編碼時則是單獨進行編碼,
當進行完以上的處理后,我們需要將這些單獨處理好的資料拼接起來作為輸入層資料,我們來分析下資料的維度,針對某一天,根據以上的編碼后,我們會發現輸入層層數是26 = 4 + 2 + 10 + 10,其中4代表季節的onehot編碼,兩個10分別代表了早晨天氣和晚間天氣的onehot編碼,而2代表了最高氣溫與最低氣溫這兩個標量,而對于每組資料的維度是如下的:
season_onehot: (575, 4)
highest_temps: (575, 1)
lowest_temps: (575, 1)
weather_mornings_onehot: (575, 10)
weather_nights_onehot: (575, 10)
其中575是sequence length,我們自然而然想到的就是向量的水平拼接:
inputs = np.hstack((season_onehot, highest_temps))
inputs = np.hstack((inputs, lowest_temps))
inputs = np.hstack((inputs, weather_mornings_onehot))
inputs = np.hstack((inputs, weather_nights_onehot))
拼接后inputs的維度為:
inputs: (575, 26)
3 模型定義與訓練
3.1 模型定義
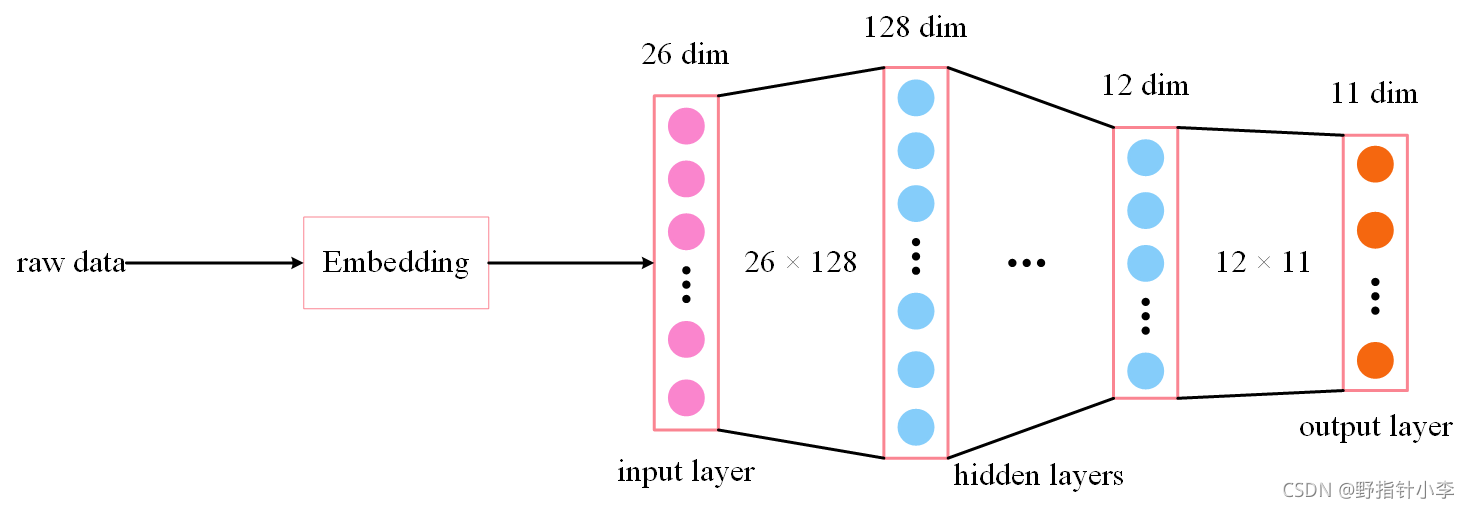
Embedding在第二節已經介紹過了,對于隱藏層而言,第一個隱藏層是128維,最后一個隱藏層是12維,至于這兩層中間,我嘗試過不加隱藏層;一層64維隱藏層;一層64維,一層32維,最后實驗結果證明,效果最好的是
128
×
64
×
12
128 \times 64 \times 12
128×64×12的組合,最后這個12維的隱藏層主要是用于學習上身、褲子、鞋子在春夏秋冬的概率,模型定義的代碼如下:
class MLP(nn.Module):
def __init__(self, num_inputs, num_outputs):
super().__init__()
self.linear1 = nn.Linear(num_inputs, 128)
self.linear_add1 = nn.Linear(128, 64)
# self.linear_add2 = nn.Linear(64, 32)
self.linear2 = nn.Linear(64, 12)
self.linear3 = nn.Linear(12, num_outputs)
self.sigmoid = nn.Sigmoid()
self.dropout = nn.Dropout(0.01)
self.softmax = nn.Softmax()
def forward(self, inputs):
"""
前向傳播
:param inputs: tensor
shape: (batch_size, 26)
:return: tensor
shape: (batch_size, 11)
"""
out1 = self.sigmoid(self.linear1(inputs))
out1 = self.dropout(out1)
out_add1 = self.sigmoid(self.linear_add1(out1))
out_add1 = self.dropout(out_add1)
# out_add2 = self.sigmoid(self.linear_add2(out_add1))
# out_add2 = self.dropout(out_add2)
out2 = self.sigmoid(self.linear2(out_add1))
out2 = self.dropout(out2)
return self.softmax(self.linear3(out2))
隱藏層通過sigmoid做激活函式,輸出層用softmax激活,由于資料量過少,所以dropout設定為的0.01,
3.2 評價指標與損失函式
由于該問題是個多標簽分類問題,所以傳統的分類問題的損失函式交叉熵是沒辦法使用的,具體問題詳見我上篇博客:《Pytorch學習筆記(5)——交叉熵報錯RuntimeError: 1D target tensor expected, multi-target not supported》,于是這里就采用了最傳統的均方誤差做損失函式,
同樣,sklearn中傳統的評價指標也不適用于該型別問題(雖然sklearn.metrics中的average_precision_score可以解決多標簽分類問題(官方檔案:sklearn.metrics.average_precision_score),但是我總覺得不是acc的評價指標感覺怪怪的),所以這里我自己定義了一個準確率的評價指標,
由于我們做的東西,目的是根據天氣來推薦當天的穿著,那么我就設定了一個閾值 ? \epsilon ?,大于 ? \epsilon ? 的為推薦的穿著,小于 ? \epsilon ? 的則不推薦,由于有11個類別,平攤下來每個類別出現的概率是 9 % 9\% 9%,所以我設定 ? = 0.1 \epsilon = 0.1 ?=0.1,而準確率的代碼為:
def get_accuracy(y_hat, y, epsilon):
"""
獲得準確率
判斷y_hat每個元素與閾值的大小, 再與y做比較
:param y_hat: tensor
預測資料
:param y: tensor
真實資料
:param epsilon: float
閾值
:return: float
準確率
"""
return ((y_hat >= epsilon).float() == y).float().mean().item()
該代碼可以用以下例子來簡單理解:
y_hat = tensor([2.7865e-05, 7.7470e-06, 5.3148e-01, 3.0976e-04, 1.9971e-05,
3.3148e-06, 1.3452e-01, 6.2689e-02, 1.3991e-01, 1.3103e-01, 5.4364e-06])
y = tensor([0, 1, 0, 0, 1, 0, 0, 1, 1, 0, 0])
(y_hat >= epsilon) = tensor([False, False, True, False, False, False, True, False, True, True, False])
(y_hat >= epsilon).float() = tensor([0., 0., 1., 0., 0., 0., 1., 0., 1., 1., 0.])
((y_hat >= epsilon).float() == y) = tensor([True, False, False, True, False,
True, False, False, True, False, True])
((y_hat >= epsilon).float() == y).float() = tensor([1., 0., 0., 1., 0., 1., 0., 0., 1., 0., 1.])
((y_hat >= epsilon).float() == y).float().mean() = tensor(0.4545)
3.3 訓練模型
訓練模型就平淡無奇了,就是傳統的模型訓練方法,唯一要注意的就是,由于資料量過少,我就按照6 : 2 : 2的比例來劃分訓練集 : 驗證集 : 測驗集,但是train_test_split又沒有劃分驗證集的方法,所以我用以下兩步來做的劃分:
X_train, X_dt, y_train, y_dt = train_test_split(inputs, labels, test_size=0.4,
random_state=0)
X_dev, X_test, y_dev, y_test = train_test_split(X_dt, y_dt, test_size=0.5,
random_state=0)
3.4 模型評估
關于訓練準確率、誤差,驗證準確率、誤差,我就用layer2的結果來做展示,如下:
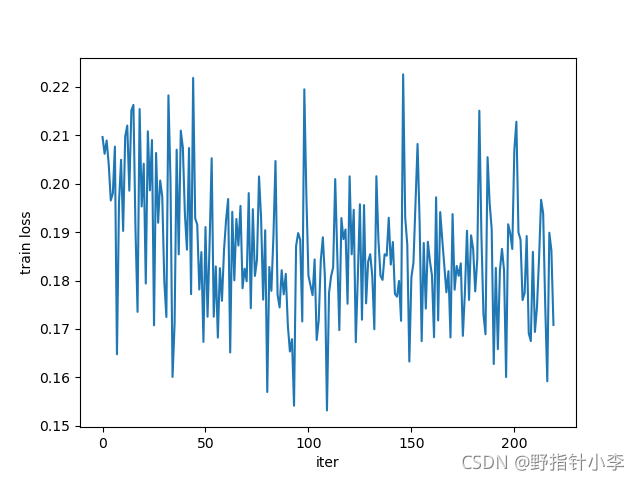
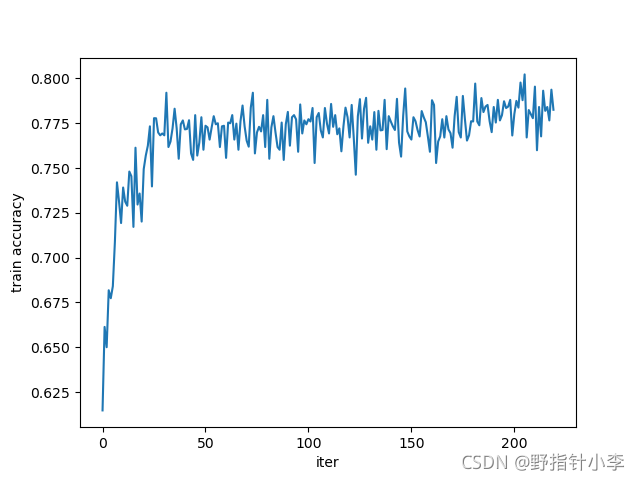
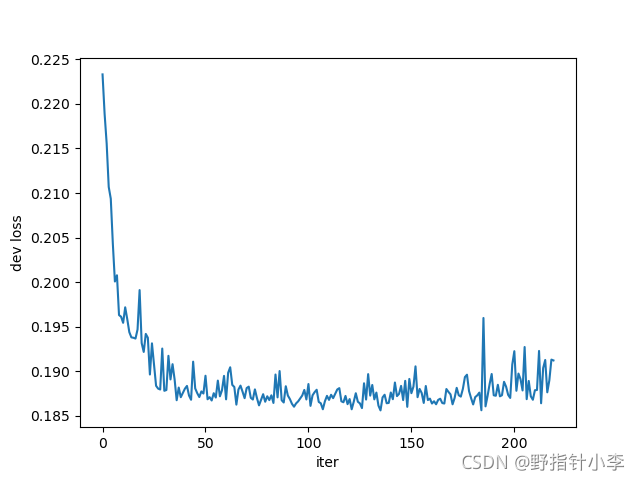
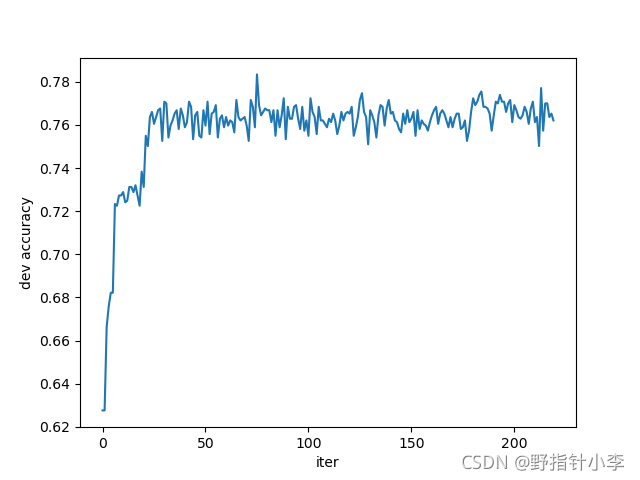
從上到下依次為:訓練集損失,訓練集準確率,驗證集損失,驗證集準確率,可以發現訓練集的損失震蕩很嚴重,或者說下降的很少(因為縱坐標的范圍還不到
10
%
10\%
10%),這些就是欠擬合造成的,也就是說因為資料量過少導致的,
而在測驗集上的損失與準確率為:
layer1: test accuracy 0.756522, test loss 0.188675
layer2: test accuracy 0.766798, test loss 0.186148
layer3: test accuracy 0.739130, test loss 0.194097
可以發現,在測驗集上,有三層隱藏層的神經網路(對應layer2)是性能最好的,
4 測驗API
當模型訓練好了之后,我封裝了個介面可以測驗效果:
model = MLP(26, 11)
model.load_state_dict(torch.load('./data/parameters_layer2.pkl'))
model.eval()
with torch.no_grad():
pred = model(input_)
dress_idx = torch.nonzero((pred >= epsilon).float()) # 提取出非零的元素下標
print('今日適合穿: ', end='')
for idx in dress_idx:
print(titles[idx], end=' ')
效果如下:

測驗不同資料,對應輸入輸出為:
python mlp.py -s 夏 -hi 34 -l 28 -m 晴 -n 晴
今日適合穿: T恤(短) 牛仔褲 帆布鞋 老爹鞋
python mlp.py -s 春 -hi 20 -l 18 -m 晴 -n 多云
今日適合穿: T恤(短) 牛仔褲 帆布鞋 老爹鞋
python mlp.py -s 秋 -hi 14 -l 11 -m 小雨 -n 多云
今日適合穿: 衛衣 牛仔褲 老爹鞋
python mlp.py -s 冬 -hi 5 -l 1 -m 多云 -n 陣雨
今日適合穿: 羽絨服 毛衣
就看得出來,至少輸出還是比較合理的,但是依舊有問題,比如最后一條并沒有輸出褲子和鞋子該穿啥,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/342013.html
標籤:AI
上一篇:人工智能學習路線