學習總結
(1)學習推薦系統中召回層的功能特點(要快速準確地過濾出相關物品,縮小候選集)和實作召回層的三個技術方案:簡單快速的單策略召回、業界主流的多路召回、深度學習推薦系統中最常用的 Embedding 召回,
(2)Embedding 召回卻可以把 Embedding 間的相似度作為唯一的判斷標準,因此它可以隨意限定召回的候選集大小(在線上服務的程序中,Embedding 相似性可通過余弦相似度計算),
文章目錄
- 學習總結
- 一、召回層和排序層的功能特點
- 二、3種召回方式
- 2.1 單策略召回
- 2.2 多路召回
- 2.3 基于 Embedding 的召回方法
- 三、作業
- 四、課后答疑
- Reference
記得前段時間百度CEO李彥宏在北大的演講提到工程的思維很重要,就說到用戶搜索關鍵字時,百度并不用對成百上千的網頁進行排序再提供給用戶(因為這樣用戶也不可能全部看完所有網頁),所以只對1000個網頁進行排序就能極大降低難度,
而同樣道理:如果利用比較復雜的推薦模型,特別是深度學習推薦模型,對 500 萬個短視頻打分,這個程序是非常消耗計算資源的,每秒幾十萬甚至上百萬的用戶同時請求服務器,逐個候選視頻打分產生的計算量,是任何集群都承受不了的,
召回層:在推薦物品候選集規模非常大的時候,召回層用來快速又準確地篩選掉不相關物品,從而節約排序時所消耗的計算資源,
一、召回層和排序層的功能特點
“召回層”處于推薦系統的線上服務模塊之中,推薦服務器從資料庫或記憶體中拿到所有候選物品集合后,會依次經過召回層、排序層、再排序層(也被稱為補充演算法層),才能夠產生用戶最終看到的推薦串列,
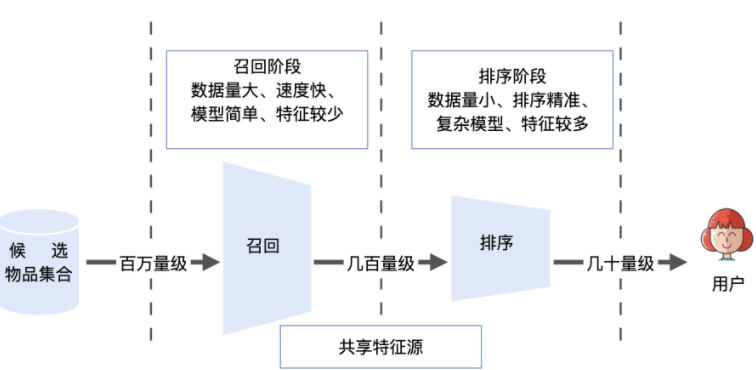
召回層就是要快速、準確地過濾出相關物品,縮小候選集;
排序層則要以提升推薦效果為目標,作出精準的推薦串列排序,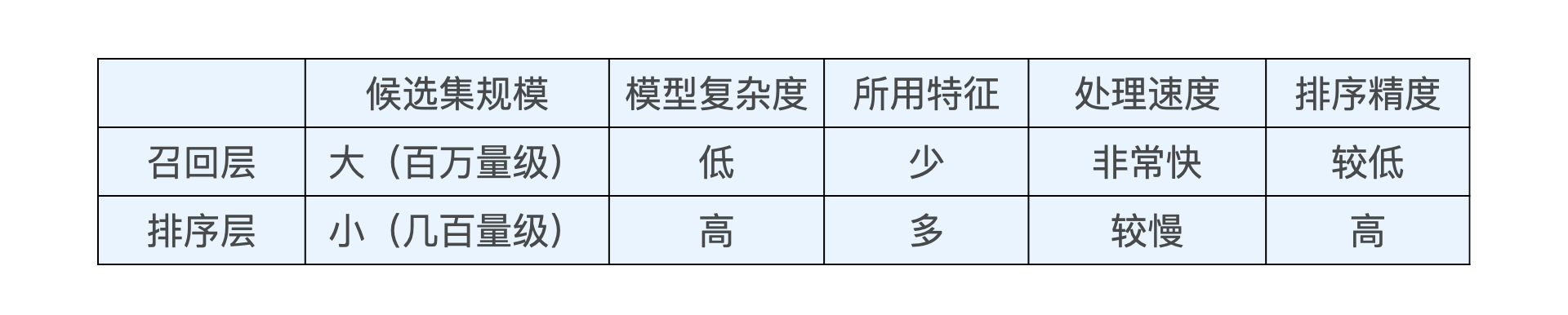
在設計召回層時,要同時權衡【計算速度】和【召回率】,
為了提高計算速度,我們需要使召回策略盡量簡單,而為了提高召回率或者說召回精度,讓召回策略盡量把用戶感興趣的物品囊括在內,這又要求召回策略不能過于簡單,否則召回物品就無法滿足排序模型的要求,
二、3種召回方式
2.1 單策略召回
單策略召回:通過制定一條規則或者利用一個簡單模型來快速地召回可能的相關物品,
缺點:不能滿足用戶的多元化興趣的需求,
這里的規則其實就是用戶可能感興趣的物品的特點,如在推薦電影的時候,我們首先要想到用戶可能會喜歡什么電影,按照經驗來說,很有可能是這三類,分別是大眾口碑好的、近期非常火熱的,以及跟我之前喜歡的電影風格類似的,
快速實作一個單策略召回層,比如在 SparrowRecSys 中,可以制定了這樣一條召回策略:如果用戶對電影 A 的評分較高,比如超過 4 分,那么我們就將與 A 風格相同,并且平均評分在前 50 的電影召回,放入排序候選集中,
//詳見SimilarMovieFlow class
public static List<Movie> candidateGenerator(Movie movie){
ArrayList<Movie> candidates = new ArrayList<>();
//使用HashMap去重
HashMap<Integer, Movie> candidateMap = new HashMap<>();
//電影movie包含多個風格標簽
for (String genre : movie.getGenres()){
//召回策略的實作
List<Movie> oneCandidates = DataManager.getInstance().getMoviesByGenre(genre, 100, "rating");
for (Movie candidate : oneCandidates){
candidateMap.put(candidate.getMovieId(), candidate);
}
}
//去掉movie本身
if (candidateMap.containsKey(movie.getMovieId())){
candidateMap.remove(movie.getMovieId());
}
//最終的候選集
return new ArrayList<>(candidateMap.values());
}
2.2 多路召回
多路召回策略:指采用不同的策略、特征或簡單模型,分別召回一部分候選集,然后把候選集混合在一起供后續排序模型使用的策略,
多路召回策略是在計算速度和召回率之間進行權衡的結果,
如電影推薦中使用多路召回策略,包括熱門電影、風格型別、高分評價、最新上映以及朋友喜歡等等,可以把一些推斷速度比較快的簡單模型(比如邏輯回歸,協同過濾等)生成的推薦結果放入多路召回層中,形成綜合性更好的候選集,具體就是分別執行這些策略,讓每個策略選取 Top K 個物品,最后混合多個 Top K 物品,就形成了最終的多路召回候選集,
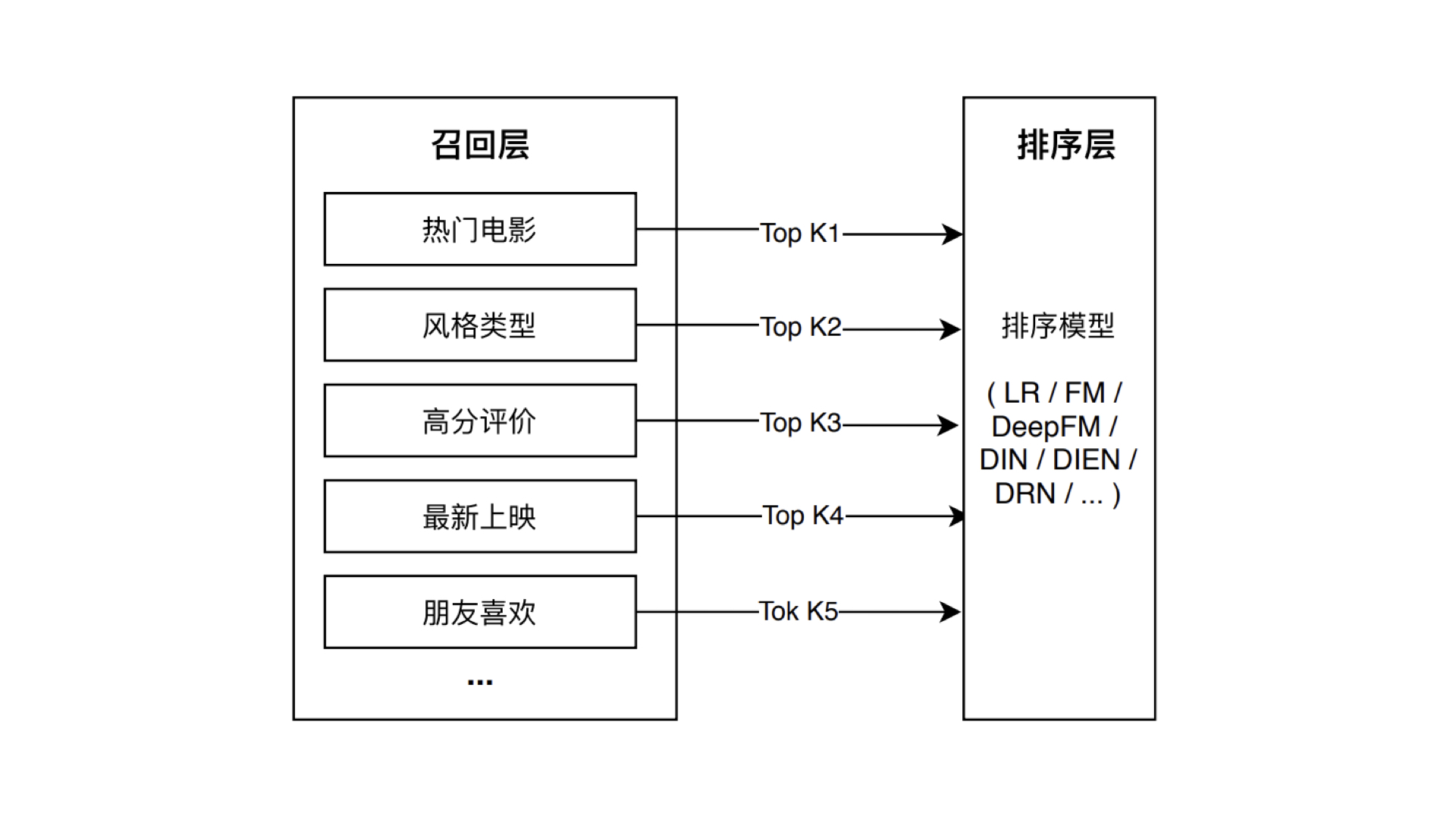
在 SparrowRecsys 中,就實作了由風格型別、高分評價、最新上映,這三路召回策略組成的多路召回方法:
public static List<Movie> multipleRetrievalCandidates(List<Movie> userHistory){
HashSet<String> genres = new HashSet<>();
//根據用戶看過的電影,統計用戶喜歡的電影風格
for (Movie movie : userHistory){
genres.addAll(movie.getGenres());
}
//根據用戶喜歡的風格召回電影候選集
HashMap<Integer, Movie> candidateMap = new HashMap<>();
for (String genre : genres){
List<Movie> oneCandidates = DataManager.getInstance().getMoviesByGenre(genre, 20, "rating");
for (Movie candidate : oneCandidates){
candidateMap.put(candidate.getMovieId(), candidate);
}
}
//召回所有電影中排名最高的100部電影
List<Movie> highRatingCandidates = DataManager.getInstance().getMovies(100, "rating");
for (Movie candidate : highRatingCandidates){
candidateMap.put(candidate.getMovieId(), candidate);
}
//召回最新上映的100部電影
List<Movie> latestCandidates = DataManager.getInstance().getMovies(100, "releaseYear");
for (Movie candidate : latestCandidates){
candidateMap.put(candidate.getMovieId(), candidate);
}
//去除用戶已經觀看過的電影
for (Movie movie : userHistory){
candidateMap.remove(movie.getMovieId());
}
//形成最終的候選集
return new ArrayList<>(candidateMap.values());
}
其他改進:多執行緒并行、建立標簽 / 特征索引、建立常用召回集快取等方法,
多路召回策略缺點:
比如,在確定每一路的召回物品數量時,往往需要大量的人工參與和調整,具體的數值需要經過大量線上 AB 測驗來決定,此外,因為策略之間的資訊和資料是割裂的,所以我們很難綜合考慮不同策略對一個物品的影響,
2.3 基于 Embedding 的召回方法
利用物品和用戶 Embedding 相似性來構建召回層,是深度學習推薦系統中非常經典的技術方案,優勢有三:
- 多路召回中使用的“興趣標簽”、“熱門度”、“流行趨勢”、“物品屬性”等資訊都可以作為 Embedding 方法中的附加資訊(Side Information),融合進最終的 Embedding 向量中 ,相當于考慮到了多路召回的多種策略,
- Embedding 召回的評分具有連續性,多路召回中不同召回策略產生的相似度、熱度等分值不具備可比性,所以我們無法據此來決定每個召回策略放回候選集的大小,但是,Embedding 召回卻可以把 Embedding 間的相似度作為唯一的判斷標準,因此它可以隨意限定召回的候選集大小,
- 在線上服務的程序中,Embedding 相似性的計算也相對簡單和直接,通過簡單的點積或余弦相似度的運算就能夠得到相似度得分,便于線上的快速召回,
public static List<Movie> retrievalCandidatesByEmbedding(User user){
if (null == user){
return null;
}
//獲取用戶embedding向量
double[] userEmbedding = DataManager.getInstance().getUserEmbedding(user.getUserId(), "item2vec");
if (null == userEmbedding){
return null;
}
//獲取所有影片候選集(這里取評分排名前10000的影片作為全部候選集)
List<Movie> allCandidates = DataManager.getInstance().getMovies(10000, "rating");
HashMap<Movie,Double> movieScoreMap = new HashMap<>();
//逐一獲取電影embedding,并計算與用戶embedding的相似度
for (Movie candidate : allCandidates){
double[] itemEmbedding = DataManager.getInstance().getItemEmbedding(candidate.getMovieId(), "item2vec");
double similarity = calculateEmbeddingSimilarity(userEmbedding, itemEmbedding);
movieScoreMap.put(candidate, similarity);
}
List<Map.Entry<Movie,Double>> movieScoreList = new ArrayList<>(movieScoreMap.entrySet());
//按照用戶-電影embedding相似度進行候選電影集排序
movieScoreList.sort(Map.Entry.comparingByValue());
//生成并回傳最終的候選集
List<Movie> candidates = new ArrayList<>();
for (Map.Entry<Movie,Double> movieScoreEntry : movieScoreList){
candidates.add(movieScoreEntry.getKey());
}
return candidates.subList(0, Math.min(candidates.size(), size));
}
三步生成了最終的候選集,
(1)第一步,我們獲取用戶的 Embedding,
(2)第二步,我們獲取所有物品的候選集,并且逐一獲取物品的 Embedding,計算物品 Embedding 和用戶 Embedding 的相似度,開銷最大的也是這一步(當物品集過大時(比如達到了百萬以上的規模),線性的運算也可能造成很大的時間開銷),
(3)第三步,我們根據相似度排序,回傳規定大小的候選集,
三、作業
(1)在 SparrowRecsys 中實作一個多執行緒版本的多路召回策略嗎?
- 在類
SimilarMovieProcess中實體化一個執行緒池ThreadPoolExecutor作為靜態成員變數 - 方法
multipleRetrievalCandidates中的候選集candidateMap使用ConcurrentHashMap替代HashMap - 風格型別、高分評價、最新上映三種召回的程序使用執行緒池實體(共三個執行緒)去執行
- 判斷三個執行緒執行完后回傳結果
(2)對于 Embedding 召回來說,怎么做才能提升計算 Embedding 相似度的速度?
【答】可以用區域敏感哈希,
四、課后答疑
(1)如果基于興趣標簽做召回,同一個物品,有多個標簽,而用戶也計算了出了多個興趣標簽,那么怎么做用戶的多興趣標簽與物品的最優匹配呢?還有物品的標簽有多層,那么怎么利用上一層的標簽呢?
【答】簡單的做法是把興趣標簽轉換成multihot向量,然后就可以計算出用戶和物品的相似度了,
復雜一點也可以計算每個興趣標簽的tfidf,為標簽分配權重后,再轉換成multihot向量,
如果標簽有多層,也不妨礙把多層標簽全部放到multihot向量中,高層標簽的權重可以適當降低,這也是思路之一,
(2)阿里的EGES演算法的論文,那個論文里面的EGES模型圖的最底層是Sparse feature,論文中是說這一層是比較傾向于用one- hot編碼的,不管side information的one-hot編碼,一般item的數量會很多很多,對item本身的向量表示直接用one-hot的話,那embedding matrix是不是會很大,這樣是合適的嗎?
【答】one-hot特征肯定會讓embedding matrix很大,但就是這樣使用的,因為我們就是想求解每一個維度上對應item的embedding,
這也就是為什么說embedding層是神經網路中最耗時的部分的原因,
Reference
(1)https://github.com/wzhe06/Reco-papers
(2)《深度學習推薦系統實戰》,王喆
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/342014.html
標籤:AI