文章目錄
- 生產者
- 一 訊息提供者開發
- 1.1 程序
- 1.2 代碼實作
- 1.3 重點配置引數
- 1.4 訊息的發送
- 二 原理決議
- 2.1基本知識
- 2.2 攔截器
- 2.2.1 基本結構
- 2.2.2 自定義攔截器
- 2.3 序列化器
- 2.3.1 基本方法
- 2.3.2 自定義序列化器
- 2.4 磁區器
- 2.4.1 基本方法
- 2.4.2 自定義磁區器
- 2.5 訊息累加器
- 2.1 基本知識
- 2.6 Sender執行緒
生產者
一 訊息提供者開發
1.1 程序
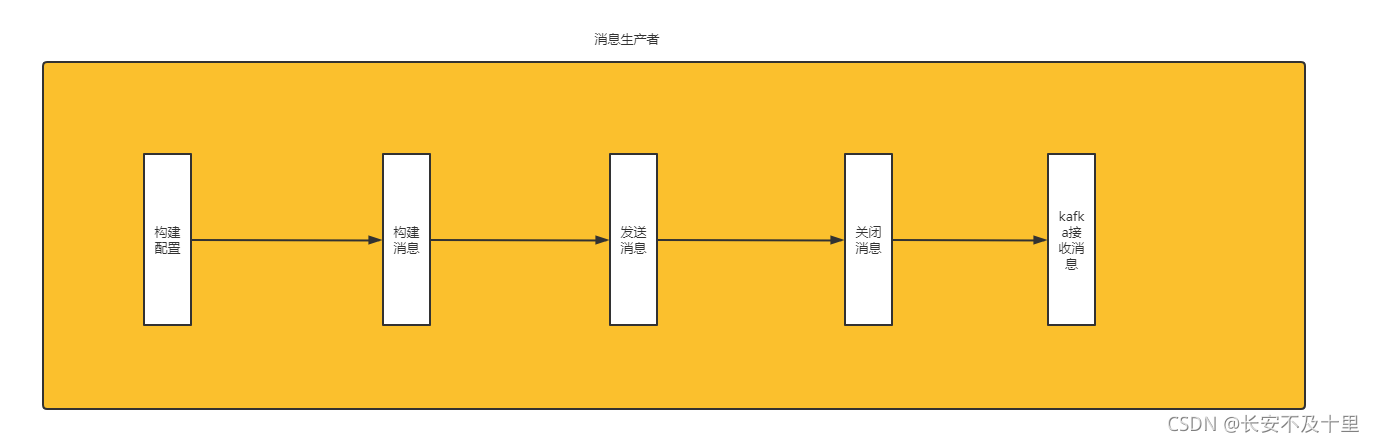
1.2 代碼實作
/**
* @Author shu
* @Date: 2021/10/22/ 16:25
* @Description 生成者
**/
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.producer.*;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
public class MySimpleProducer {
private final static String TOPIC_NAME = "my-replicated-topic";
//分組
private final static String CONSUMER_GROUP_NAME = "testGroup";
public static void main(String[] args) throws ExecutionException, InterruptedException {
//1.設定引數
Properties props = new Properties();
//主機
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "ip:9093");
//分組
props.put(ConsumerConfig.GROUP_ID_CONFIG, CONSUMER_GROUP_NAME);
//把發送的key從字串序列化為位元組陣列
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
//把發送訊息value從字串序列化為位元組陣列
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
//ack默認
props.put(ProducerConfig.ACKS_CONFIG,"1");
//快取區默認大小
props.put(ProducerConfig.BUFFER_MEMORY_CONFIG,33554432);
//拉取資料默認大小
props.put(ProducerConfig.BATCH_SIZE_CONFIG,16384);
//如果資料未滿16k,也提交
props.put(ProducerConfig.LINGER_MS_CONFIG,10);
//2.創建?產訊息的客戶端,傳?引數
Producer<String,String> producer = new KafkaProducer<String, String>(props);
//3.創建訊息
//key:作?是決定了往哪個磁區上發,value:具體要發送的訊息內容
ProducerRecord<String,String> producerRecord = new ProducerRecord<>(TOPIC_NAME,"message","四川");
//4.發送訊息,得到訊息發送的元資料并輸出
RecordMetadata metadata = producer.send(producerRecord).get();
System.out.println( "topic-" + metadata.topic() + "|partition-" + metadata.partition() + "|offset-" + metadata.offset());
}
}
1.3 重點配置引數
-
bootstrap.servers:該引數用來指定生產者客戶端連接Kafka集群所需的broker地址清單,具體的內容格式為host1:port1,host2:port2,可以設定一個或多個地址,中間以逗號隔開, -
key.serializer 和 value.serializer:broker 端接收的訊息必須以位元組陣列(byte[])的形式存在,key.serializer和value.serializer這兩個引數分別用來指定key和value序列化操作的序列化器,這兩個引數無默認值,注意這里必須填寫序列化器的全限定名, -
ack:0意味著producer不等待broker同步完成的確認,繼續發送下一條(批)資訊,1意味著producer要等待leader成功收到資料并得到確認,才發送下一條message,-1意味著producer得到follwer確認,才發送下一條資料,- 綜合性能與效率來看,kafka默認ack為1
-
buffer-memory:Kafka的客戶端發送資料到服務器,不是來一條就發一條,而是經過緩沖的,也就是說,通過KafkaProducer發送出去的訊息都是先進入到客戶端本地的記憶體緩沖里,然后把很多訊息收集成一個一個的Batch,再發送到Broker上去的,這樣性能才可能高,默認32M, -
batch-size:kafka一次拉取大小,默認16k -
retries:重試次數
# lead機器
spring.kafka.bootstrap-servers=ip:9093
#########producer############
# ack
spring.kafka.producer.acks=1
# 拉取大小
spring.kafka.producer.batch-size=16384
# 重試次數
spring.kafka.producer.retries=10
# 緩沖區大小
spring.kafka.producer.buffer-memory=33554432
# 序列化
spring.kafka.producer.key-serializer= org.apache.kafka.common.serialization.StringSerializer
spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer
1.4 訊息的發送
在創建完生產者實體之后,接下來的作業就是構建訊息,即創建ProducerRecord物件,
//3.創建訊息
//key:作?是決定了往哪個磁區上發,value:具體要發送的訊息內容
ProducerRecord<String,String> producerRecord = new ProducerRecord<>(TOPIC_NAME,"message","四川");
ProducerRecord方法
//成員變數
private final String topic;//主題
private final Integer partition;//磁區
private final Headers headers;//header
private final K key;
private final V value;
private final Long timestamp;//時間
//構造器
public ProducerRecord(String topic, Integer partition, Long timestamp, K key, V value, Iterable<Header> headers) {
if (topic == null)
throw new IllegalArgumentException("Topic cannot be null.");
if (timestamp != null && timestamp < 0)
throw new IllegalArgumentException(
String.format("Invalid timestamp: %d. Timestamp should always be non-negative or null.", timestamp));
if (partition != null && partition < 0)
throw new IllegalArgumentException(
String.format("Invalid partition: %d. Partition number should always be non-negative or null.", partition));
this.topic = topic;
this.partition = partition;
this.key = key;
this.value = value;
this.timestamp = timestamp;
this.headers = new RecordHeaders(headers);
}
public ProducerRecord(String topic, Integer partition, Long timestamp, K key, V value) {
this(topic, partition, timestamp, key, value, null);
}
public ProducerRecord(String topic, Integer partition, K key, V value, Iterable<Header> headers) {
this(topic, partition, null, key, value, headers);
}
public ProducerRecord(String topic, Integer partition, K key, V value) {
this(topic, partition, null, key, value, null);
}
public ProducerRecord(String topic, K key, V value) {
this(topic, null, null, key, value, null);
}
public ProducerRecord(String topic, V value) {
this(topic, null, null, null, value, null);
}
KafkaProducer方法
//構造器
public KafkaProducer(final Map<String, Object> configs) {
this(configs, null, null, null, null, null, Time.SYSTEM);
}
public KafkaProducer(Map<String, Object> configs, Serializer<K> keySerializer, Serializer<V> valueSerializer) {
this(configs, keySerializer, valueSerializer, null, null, null, Time.SYSTEM);
}
public KafkaProducer(Properties properties) {
this(propsToMap(properties), null, null, null, null, null, Time.SYSTEM);
}
public KafkaProducer(Properties properties, Serializer<K> keySerializer, Serializer<V> valueSerializer) {
this(propsToMap(properties), keySerializer, valueSerializer, null, null, null,
Time.SYSTEM);
}
//發送方法
@Override
public Future<RecordMetadata> send(ProducerRecord<K, V> record) {
return send(record, null);
}
@Override
public Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback) {
// intercept the record, which can be potentially modified; this method does not throw exceptions
ProducerRecord<K, V> interceptedRecord = this.interceptors.onSend(record);
return doSend(interceptedRecord, callback);
}
執行完send()方法之后直接呼叫get()方法,這樣可以獲取一個RecordMetadata物件,在RecordMetadata物件里包含了訊息的一些元資料資訊,比如當前訊息的主題、磁區號、磁區中的偏移量(offset)、時間戳等,如果在應用代碼中需要這些資訊,
//4.發送訊息,得到訊息發送的元資料并輸出
RecordMetadata metadata = producer.send(producerRecord).get();
System.out.println( "topic-" + metadata.topic() + "|partition-" + metadata.partition() + "|offset-" + metadata.offset())
二 原理決議
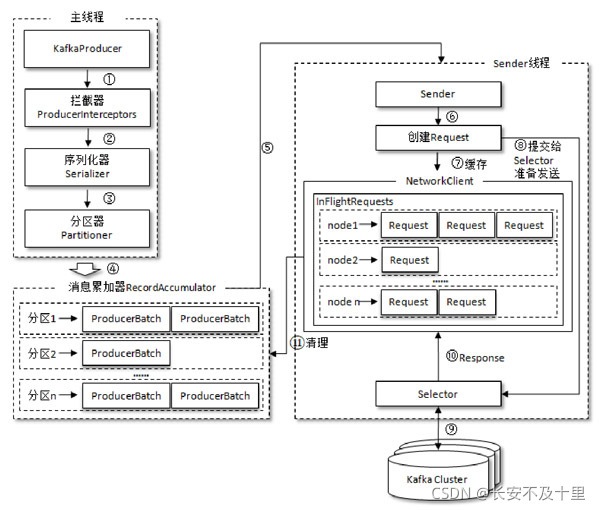
訊息在通過send()方法發往broker的程序中,有可能需要經過攔截器(Interceptor)、序列化器(Serializer)和磁區器(Partitioner)的一系列作用之后才能被真正地發往 broker,
2.1基本知識
//成員變數
private final String clientId;
// Visible for testing
final Metrics metrics;
//磁區器
private final Partitioner partitioner;
private final int maxRequestSize;
private final long totalMemorySize;
private final ProducerMetadata metadata;
//累加器
private final RecordAccumulator accumulator;
//Sender執行緒
private final Sender sender;
private final Thread ioThread;
private final CompressionType compressionType;
private final Sensor errors;
private final Time time;
// 序列化器
private final Serializer<K> keySerializer;
private final Serializer<V> valueSerializer;
//組態檔
private final ProducerConfig producerConfig;
private final long maxBlockTimeMs;
//攔截器
private final ProducerInterceptors<K, V> interceptors;
private final ApiVersions apiVersions;
//事務管理器
private final TransactionManager transactionManager;
-
整個生產者客戶端由兩個執行緒協調運行,這兩個執行緒分別為主執行緒和Sender執行緒(發送執行緒),
-
在主執行緒中由
KafkaProducer創建訊息,然后通過可能的攔截器、序列化器和磁區器的作用之后快取到訊息累加器(RecordAccumulator,也稱為訊息收集器)中,Sender 執行緒負責從RecordAccumulator中獲取訊息并將其發送到Kafka中, -
RecordAccumulator主要用來快取訊息以便 Sender 執行緒可以批量發送,進而減少網路傳輸的資源消耗以提升性能, -
RecordAccumulator快取的大小可以通過生產者客戶端引數buffer.memory配置,默認值為33554432B,即32MB, -
如果生產者發送訊息的速度超過發送到服務器的速度,則會導致生產者空間不足,這個時候
KafkaProducer的send()方法呼叫要么被阻塞,要么拋出例外,這個取決于引數max.block.ms的配置,此引數的默認值為60000,即60秒, -
訊息在網路上都是以位元組(Byte)的形式傳輸的,在發送之前需要創建一塊記憶體區域來保存對應的訊息,在Kafka生產者客戶端中,通過java.io.ByteBuffer實作訊息記憶體的創建和釋放,
-
不過頻繁的創建和釋放是比較耗費資源的,在
RecordAccumulator的內部還有一個BufferPool,它主要用來實作ByteBuffer的復用,以實作快取的高效利用, -
ProducerBatch的大小和batch.size引數也有著密切的關系, -
在新建
ProducerBatch時評估這條訊息的大小是否超過batch.size引數的大小,如果不超過,那么就以batch.size引數的大小來創建ProducerBatch, -
Sender執行緒從RecordAccumulator中獲取快取的訊息之后,會進一步將原本<磁區,Deque<ProducerBatch>>的保存形式轉變成<Node,List<ProducerBatch>的形式,其中Node表示Kafka集群的broker節點, -
在轉換成
<Node,List<ProducerBatch>>的形式之后,Sender還會進一步封裝成<Node,Request>的形式,這樣就可以將Request請求發往各個Node了,這里的Request是指Kafka的各種協議請求,對于訊息發送而言就是指具體的ProduceRequest -
請求在從Sender執行緒發往Kafka之前還會保存到
InFlightRequests中,InFlightRequests保存物件的具體形式為Map<NodeId,Deque<Request>>,它的主要作用是快取了已經發出去但還沒有收到回應的請求(NodeId是一個String 型別,表示節點的 id 編號),可以限制連接大小, -
InFlightRequests還可以獲得leastLoadedNode,即所有Node中負載最小的那一個,這里的負載最小是通過每個Node在InFlightRequests中還未確認的請求決定的,未確認的請求越多則認為負載越大,優先發送負載最小的,避免因網路擁塞等例外而影響整體的進度,
2.2 攔截器
2.2.1 基本結構
- 攔截器(Interceptor)是早在Kafka 0.10.0.0中就已經引入的一個功能,Kafka一共有兩種攔截器:生產者攔截器和消費者攔截器
- 生產者攔截器既可以用來在訊息發送前做一些準備作業,比如按照某個規則過濾不符合要求的訊息、修改訊息的內容等,也可以用來在發送回呼邏輯前做一些定制化的需求,比如統計類作業,
public Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback) {
ProducerRecord<K, V> interceptedRecord = this.interceptors.onSend(record);
return doSend(interceptedRecord, callback);
}
configure(Map<String, ?> configs)
該方法在初始化資料的時候被呼叫,用于獲取生產者的配置資訊onSend(ProducerRecord<K, V>)
該方法在訊息被序列化之前呼叫,并傳入要發送的訊息記錄,用戶可以在該方法中對訊息記錄進行任意的修改,包括訊息的key和value以及要發送的主題和磁區等,
/**
當客戶端將記錄發送到 KafkaProducer 時,在鍵和值被序列化之前呼叫, 該方法呼叫ProducerInterceptor.onSend(ProducerRecord)方法, 從第一個攔截器的 onSend() 回傳的 ProducerRecord 傳遞給第二個攔截器 onSend(),在攔截器鏈中依此類推, 從最后一個攔截器回傳的記錄就是從這個方法回傳的, 此方法不會拋出例外, 任何攔截器方法拋出的例外都會被捕獲并忽略, 如果鏈中間的攔截器(通常會修改記錄)拋出例外,則鏈中的下一個攔截器將使用前一個未拋出例外的攔截器回傳的記錄呼叫,
**/
public ProducerRecord<K, V> onSend(ProducerRecord<K, V> record) {
ProducerRecord<K, V> interceptRecord = record;//集合
for (ProducerInterceptor<K, V> interceptor : this.interceptors) {
try {
interceptRecord = interceptor.onSend(interceptRecord);
} catch (Exception e) {
// do not propagate interceptor exception, log and continue calling other interceptors
// be careful not to throw exception from here
if (record != null)
log.warn("Error executing interceptor onSend callback for topic: {}, partition: {}", record.topic(), record.partition(), e);
else
log.warn("Error executing interceptor onSend callback", e);
}
}
return interceptRecord;
}
-
onAcknowledgement(RecordMetadata metadata, Exception exception)
該方法在發送到服務器的記錄已被確認或者記錄發送失敗時呼叫(在生產者回呼邏輯觸發之前),可以在metadata物件中獲取訊息的主題、磁區和偏移量等資訊,在exception物件中獲取訊息的例外資訊,@Override public void onAcknowledgement(RecordMetadata metadata, Exception exception) { int partition = metadata.partition(); String topic = metadata.topic(); long offset = metadata.offset(); String str = metadata.toString(); long timestamp = metadata.timestamp(); } -
close()該方法用于關閉攔截器并釋放資源,當生產者關閉時將呼叫該方法,
2.2.2 自定義攔截器
package com.Interceptor;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerInterceptor;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import java.util.Map;
/**
* @Author shu
* @Date: 2021/10/30/ 11:40
* @Description 時間攔截器,發送訊息之前,在訊息內容前面加入時間戳
**/
public class TimeInterceptor implements ProducerInterceptor<String, String> {
/**
* 獲取生產者配置資訊
*/
@Override
public void configure(Map<String, ?> configs) {
System.out.println(configs.get(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG));
}
/**
* 該方法在訊息發送之前呼叫
* 對原訊息記錄進行修改,在訊息內容最前邊添加時間戳
* @param record 生產者發送的訊息記錄,并自動傳入
* @return 修改后的訊息記錄
*/
@Override
public ProducerRecord<String, String> onSend(ProducerRecord<String, String> record) {
System.out.println("TimeInterceptor-------onSend方法被呼叫");
// 創建一個新的record,把時間戳寫到訊息體的最前面
ProducerRecord<String, String> proRecord = new ProducerRecord<String, String>(
record.topic(), record.key(), System.currentTimeMillis() + "," + record.value().toString());
return proRecord;
}
/**
* 該方法在訊息發送完畢后呼叫
* 當發送到服務器的記錄已被確認,或者記錄發送失敗時,將呼叫次方法
*/
@Override
public void onAcknowledgement(RecordMetadata recordMetadata, Exception exception) {
System.out.println("TimeInterceptor-------onAcknowledgement方法被呼叫");
}
/**
* 當攔截器關閉時呼叫該方法
*/
@Override
public void close() {
System.out.println("TimeInterceptor-------close方法被呼叫");
}
}
2.3 序列化器
2.3.1 基本方法
- 生產者需要用序列化器
(Serializer)把物件轉換成位元組陣列才能通過網路發送給Kafka,而在對側,消費者需要用反序列化器(Deserializer)把從 Kafka 中收到的位元組陣列轉換成相應的物件, - 除了用于String型別的序列化器,還有
ByteArray、ByteBuffer、Bytes、Double、Integer、Long這幾種型別
byte[] serializedKey;
try {
serializedKey = keySerializer.serialize(record.topic(), record.headers(), record.key());
}
- 序列話
public class BytesSerializer implements Serializer<Bytes> {
public byte[] serialize(String topic, Bytes data) {
if (data == null)
return null;
return data.get();
}
}
public class ByteBufferSerializer implements Serializer<ByteBuffer> {
public byte[] serialize(String topic, ByteBuffer data) {
if (data == null)
return null;
data.rewind();
if (data.hasArray()) {
byte[] arr = data.array();
if (data.arrayOffset() == 0 && arr.length == data.remaining()) {
return arr;
}
}
byte[] ret = new byte[data.remaining()];
data.get(ret, 0, ret.length);
data.rewind();
return ret;
}
}
- 基本方法
/**
配置這個類,
*/
default void configure(Map<String, ?> configs, boolean isKey) {
// intentionally left blank
}
/**
將data轉換為位元組陣列
*/
byte[] serialize(String topic, T data);
/**
將data轉換為位元組陣列
*/
default byte[] serialize(String topic, Headers headers, T data) {
return serialize(topic, data);
}
/**
關閉序列化
**/
@Override
default void close() {
}
2.3.2 自定義序列化器
public class JsonSerializer implements Serializer<Object> {
@Override
public byte[] serialize(String s, Object object) {
return JSON.toJSONBytes(object);
}
}
2.4 磁區器
2.4.1 基本方法
- 訊息經過序列化之后就需要確定它發往的磁區,如果訊息
ProducerRecord中指定了partition欄位,那么就不需要磁區器的作用,因為partition代表的就是所要發往的磁區號, - 如果訊息
ProducerRecord中沒有指定partition欄位,那么就需要依賴磁區器,根據key這個欄位來計算partition的值,磁區器的作用就是為訊息分配磁區,
int partition = partition(record, serializedKey, serializedValue, cluster);
tp = new TopicPartition(record.topic(), partition);


- 基本方法
package org.apache.kafka.clients.producer.internals;
import java.util.List;
import java.util.Map;
import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;
import org.apache.kafka.common.PartitionInfo;
import org.apache.kafka.common.utils.Utils;
public class DefaultPartitioner implements Partitioner {
private final StickyPartitionCache stickyPartitionCache = new StickyPartitionCache();
//初始化配置
public void configure(Map<String, ?> configs) {}
//計算磁區
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
if (keyBytes == null) {
return stickyPartitionCache.partition(topic, cluster);
}
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
// hash the keyBytes to choose a partition
return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
}
//資源釋放
public void close() {}
//如果當前粘性磁區的批處理已完成,請更改粘性磁區, 或者,如果沒有確定粘性磁區,則設定一個
public void onNewBatch(String topic, Cluster cluster, int prevPartition) {
stickyPartitionCache.nextPartition(topic, cluster, prevPartition);
}
}
2.4.2 自定義磁區器
public class PhonenumPartitioner implements Partitioner{
@Override
public void configure(Map<String, ?> configs) {
// TODO nothing
}
/**
* 自定義kafka磁區主要解決用戶磁區資料傾斜問題 提高并發效率(假設 3 磁區)
* @param topic 訊息佇列名
* @param key 用戶傳入key
* @param keyBytes key位元組陣列
* @param value 用戶傳入value
* @param valueBytes value位元組資料
* @param cluster 當前kafka節點數
* @return 如果3個節點數 回傳 0 1 2 如果5個 回傳 0 1 2 3 4 5
*/
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
// 得到 topic 的 partitions 資訊
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
// 模擬某客服
if(key.toString().equals("10000") || key.toString().equals("11111")) {
// 放到最后一個磁區中
return numPartitions - 1;
}
String phoneNum = key.toString();
return phoneNum.substring(0, 3).hashCode() % (numPartitions - 1);
}
@Override
public void close() {
// TODO nothing
}
}
2.5 訊息累加器
2.1 基本知識
- 在主執行緒中由
KafkaProducer創建訊息,然后通過可能的攔截器、序列化器和磁區器的作用之后快取到訊息累加器(RecordAccumulator,也稱為訊息收集器)中,Sender 執行緒負責從RecordAccumulator中獲取訊息并將其發送到Kafka中,
RecordAccumulator.RecordAppendResult result = accumulator.append(tp, timestamp, serializedKey,
serializedValue, headers, interceptCallback, remainingWaitMs, true);
- 基本方法
/**
logContext – 用于日志記錄的日志背景關系
batchSize – 分配MemoryRecords實體時使用的大小
壓縮 – 記錄的壓縮編解碼器
lingerMs – 在宣告尚未完全準備好發送的記錄實體之前添加的人為延遲時間, 這允許更多記錄到達的時間, 由于更多的批處理(因此更少、更大的請求),設定非零 lingerMs 將犧牲一些延遲以獲得可能更好的吞吐量,
retryBackoffMs – 在收到錯誤時重試生產請求的人為延遲時間, 這樣可以避免在短時間內耗盡所有重試,
指標 - 指標
time - 要使用的時間實體
apiVersions – 為當前連接的代理請求 API 版本
transactionManager – 共享事務狀態物件,用于跟蹤每個磁區的生產者 ID、時期和序列號
**/
//構造器
public RecordAccumulator(LogContext logContext,
int batchSize,
CompressionType compression,
int lingerMs,
long retryBackoffMs,
int deliveryTimeoutMs,
Metrics metrics,
String metricGrpName,
Time time,
ApiVersions apiVersions,
TransactionManager transactionManager,
BufferPool bufferPool) {}
/**
向累加器添加一條記錄,回傳追加結果
附加結果將包含未來的元資料,以及附加批次是否已滿或是否創建新批次的標志
tp – 此記錄要發送到的主題/磁區
timestamp – 記錄的時間戳
key – 記錄的鍵
value – 記錄的值
headers – 記錄的標題
callback – 用戶提供的回呼,在請求完成時執行
maxTimeToBlock – 為使緩沖記憶體可用而阻塞的最長時間(以毫秒為單位)
abortOnNewBatch – 一個布林值,指示在創建新批次之前回傳并在嘗試再次追加之前運行磁區程式的 onNewBatch 方法
**/
//追加記錄
public RecordAppendResult append(TopicPartition tp,
long timestamp,
byte[] key,
byte[] value,
Header[] headers,
Callback callback,
long maxTimeToBlock,
boolean abortOnNewBatch) throws InterruptedException {
try {
//獲取主題的雙端佇列
Deque<ProducerBatch> dq = getOrCreateDeque(tp);
synchronized (dq) {
if (closed)
throw new KafkaException("Producer closed while send in progress");
RecordAppendResult appendResult = tryAppend(timestamp, key, value, headers, callback, dq);
if (appendResult != null)
return appendResult;
}
}
//獲取給定主題磁區的雙端佇列
private final ConcurrentMap<TopicPartition, Deque<ProducerBatch>> batches;
private Deque<ProducerBatch> getOrCreateDeque(TopicPartition tp) {
Deque<ProducerBatch> d = this.batches.get(tp);
if (d != null)
return d;
d = new ArrayDeque<>();
Deque<ProducerBatch> previous = this.batches.putIfAbsent(tp, d);
if (previous == null)
return d;
else
return previous;
}
//嘗試附加到 ProducerBatch, 如果它已滿,我們回傳 null 并創建一個新批次, 我們還關閉了記錄追加的批處理,以釋放壓碩訓沖區等資源,
private RecordAppendResult tryAppend(long timestamp, byte[] key, byte[] value, Header[] headers,
Callback callback, Deque<ProducerBatch> deque) {
ProducerBatch last = deque.peekLast();
if (last != null) {
FutureRecordMetadata future = last.tryAppend(timestamp, key, value, headers, callback, time.milliseconds());
if (future == null)
last.closeForRecordAppends();
else
return new RecordAppendResult(future, deque.size() > 1 || last.isFull(), false, false);
}
return null;
}
ProducerBatch的大小和batch.size引數也有著密切的關系,當一條訊息(ProducerRecord)流入RecordAccumulator時,會先尋找與訊息磁區所對應的雙端佇列(如果沒有則新建),再從這個雙端佇列的尾部獲取一個ProducerBatch(如果沒有則新建),查看ProducerBatch中是否還可以寫入這個ProducerRecord,如果可以則寫入,如果不可以則需要創建一個新的ProducerBatch,在新建ProducerBatch時評估這條訊息的大小是否超過batch.size引數的大小,如果不超過,那么就以batch.size引數的大小來創建ProducerBatch,這樣在使用完這段記憶體區域之后,可以通過BufferPool的管理來進行復用;如果超過,那么就以評估的大小來創建ProducerBatch,這段記憶體區域不會被復用,
2.6 Sender執行緒
- Sender 從
RecordAccumulator中獲取快取的訊息之后,會進一步將原本<磁區,Deque<ProducerBatch>>的保存形式轉變成<Node,List<ProducerBatch>的形式,其中Node表示Kafka集群的broker節點,
// 構造器
public Sender(LogContext logContext,
KafkaClient client,
ProducerMetadata metadata,
RecordAccumulator accumulator,
boolean guaranteeMessageOrder,
int maxRequestSize,
short acks,
int retries,
SenderMetricsRegistry metricsRegistry,
Time time,
int requestTimeoutMs,
long retryBackoffMs,
TransactionManager transactionManager,
ApiVersions apiVersions) {}
//喚醒sender執行緒
if (result.batchIsFull || result.newBatchCreated) {
log.trace("Waking up the sender since topic {} partition {} is either full or getting a new batch", record.topic(), partition);
this.sender.wakeup();
}
/* the state of each nodes connection */
private final KafkaClient client;
/**
* Wake up the selector associated with this send thread
*/
public void wakeup() {
this.client.wakeup();
}
//訊息累加器中檢查已準備號的資料,轉換成set<node>
public ReadyCheckResult ready(Cluster cluster, long nowMs) {
Set<Node> readyNodes = new HashSet<>();
long nextReadyCheckDelayMs = Long.MAX_VALUE;
Set<String> unknownLeaderTopics = new HashSet<>();
boolean exhausted = this.free.queued() > 0;
for (Map.Entry<TopicPartition, Deque<ProducerBatch>> entry : this.batches.entrySet()) {
Deque<ProducerBatch> deque = entry.getValue();
synchronized (deque) {
// When producing to a large number of partitions, this path is hot and deques are often empty.
// We check whether a batch exists first to avoid the more expensive checks whenever possible.
ProducerBatch batch = deque.peekFirst();
if (batch != null) {
TopicPartition part = entry.getKey();
Node leader = cluster.leaderFor(part);
if (leader == null) {
// This is a partition for which leader is not known, but messages are available to send.
// Note that entries are currently not removed from batches when deque is empty.
unknownLeaderTopics.add(part.topic());
} else if (!readyNodes.contains(leader) && !isMuted(part, nowMs)) {
long waitedTimeMs = batch.waitedTimeMs(nowMs);
boolean backingOff = batch.attempts() > 0 && waitedTimeMs < retryBackoffMs;
long timeToWaitMs = backingOff ? retryBackoffMs : lingerMs;
boolean full = deque.size() > 1 || batch.isFull();
boolean expired = waitedTimeMs >= timeToWaitMs;
boolean sendable = full || expired || exhausted || closed || flushInProgress();
if (sendable && !backingOff) {
readyNodes.add(leader);
} else {
long timeLeftMs = Math.max(timeToWaitMs - waitedTimeMs, 0);
// Note that this results in a conservative estimate since an un-sendable partition may have
// a leader that will later be found to have sendable data. However, this is good enough
// since we'll just wake up and then sleep again for the remaining time.
nextReadyCheckDelayMs = Math.min(timeLeftMs, nextReadyCheckDelayMs);
}
}
}
}
}
return new ReadyCheckResult(readyNodes, nextReadyCheckDelayMs, unknownLeaderTopics);
}
/*
* The set of nodes that have at least one complete record batch in the accumulator
*/
public final static class ReadyCheckResult {
public final Set<Node> readyNodes;
public final long nextReadyCheckDelayMs;
public final Set<String> unknownLeaderTopics;
public ReadyCheckResult(Set<Node> readyNodes, long nextReadyCheckDelayMs, Set<String> unknownLeaderTopics) {
this.readyNodes = readyNodes;
this.nextReadyCheckDelayMs = nextReadyCheckDelayMs;
this.unknownLeaderTopics = unknownLeaderTopics;
}
}
//sender執行緒發送生成者資料
private long sendProducerData(long now) {
Cluster cluster = metadata.fetch();
// get the list of partitions with data ready to send(拿出訊息累加器的資料)
RecordAccumulator.ReadyCheckResult result = this.accumulator.ready(cluster, now);
//洗掉我們還沒有準備節點
Iterator<Node> iter = result.readyNodes.iterator();
long notReadyTimeout = Long.MAX_VALUE;
while (iter.hasNext()) {
Node node = iter.next();
if (!this.client.ready(node, now)) {
iter.remove();
notReadyTimeout = Math.min(notReadyTimeout, this.client.pollDelayMs(node, now));
}
}
//創建生成者請求
Map<Integer, List<ProducerBatch>> batches = this.accumulator.drain(cluster, result.readyNodes, this.maxRequestSize, now);
addToInflightBatches(batches);
if (guaranteeMessageOrder) {
// Mute all the partitions drained
for (List<ProducerBatch> batchList : batches.values()) {
for (ProducerBatch batch : batchList)
this.accumulator.mutePartition(batch.topicPartition);
}
}
if (!result.readyNodes.isEmpty()) {
log.trace("Nodes with data ready to send: {}", result.readyNodes);
// if some partitions are already ready to be sent, the select time would be 0;
// otherwise if some partition already has some data accumulated but not ready yet,
// the select time will be the time difference between now and its linger expiry time;
// otherwise the select time will be the time difference between now and the metadata expiry time;
pollTimeout = 0;
}
//發送請求
sendProduceRequests(batches, now);
}
/**
* Transfer the record batches into a list of produce requests on a per-node basis
*/
private void sendProduceRequests(Map<Integer, List<ProducerBatch>> collated, long now) {
for (Map.Entry<Integer, List<ProducerBatch>> entry : collated.entrySet())
sendProduceRequest(now, entry.getKey(), acks, requestTimeoutMs, entry.getValue());
}
//從給定的記錄批次創建生產請求
private void sendProduceRequest(long now, int destination, short acks, int timeout, List<ProducerBatch> batches) {
String nodeId = Integer.toString(destination);
ClientRequest clientRequest = client.newClientRequest(nodeId, requestBuilder, now, acks != 0,
requestTimeoutMs, callback);
client.send(clientRequest, now);
log.trace("Sent produce request to {}: {}", nodeId, requestBuilder);
}
// 我們可以進入NetworkClient類中
private void doSend(ClientRequest clientRequest, boolean isInternalRequest, long now, AbstractRequest request) {
Send send = request.toSend(destination, header);
InFlightRequest inFlightRequest = new InFlightRequest(
clientRequest,
header,
isInternalRequest,
request,
send,
now);
this.inFlightRequests.add(inFlightRequest);
selector.send(send);
}
//在下面就進入通信部分
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/342152.html
標籤:其他
上一篇:Kafka問題優化之消費重復問題
下一篇:超詳細超簡單的搭建三臺虛擬機集群