1.vm虛擬機配置
宿主機:真機
NAT模式:(VM虛擬機里面設定)
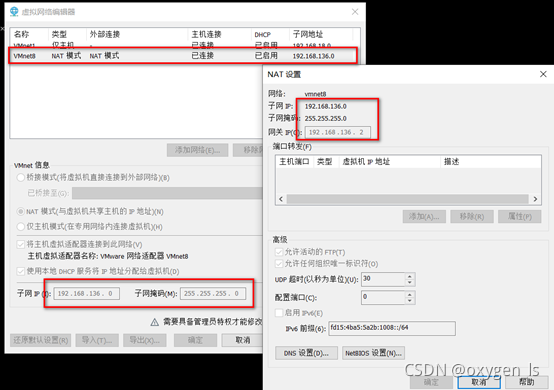
查看:你的NAT網段和網關是多少?
網段:192.168.136.0/24
網關:192.168.136.2
我的規劃:
NN1 192.168.136.200
DN1 192.168.136.201
DN2 192.168.136.202
CETNOS7 NN1 里面配置IP
ifconfig 查看網卡的名字--------ens33
root下面運行:
ifconfig ens33 192.168.136.200 netmask 255.255.255.0
2.創建hadoop sudu權限
下面的命令在root用戶下操作:
創建hadoop用戶
useradd hadoop
passwd hadoop
vim /etc/sudoers
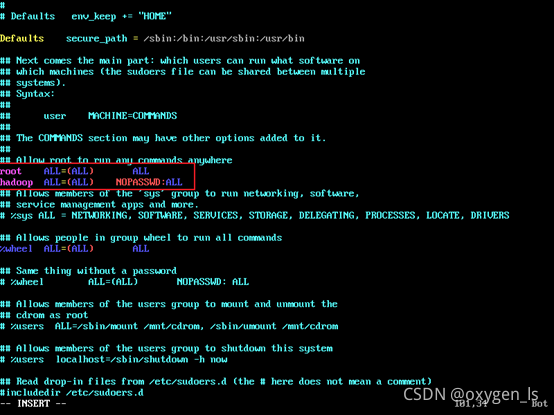
插入:
Hadoop ALL=(ALL) NOPASSWD:ALL
esc鍵+:wq!保存并退出
esc鍵+:q!退出
i插入
切換到hadoop用戶
su - hadoop ///”-”是用戶環境一同切換過去,
scp /etc/sudoers root @192.168.136.201:/etc/
scp /etc/sudoers root @192.168.136.202:/etc/
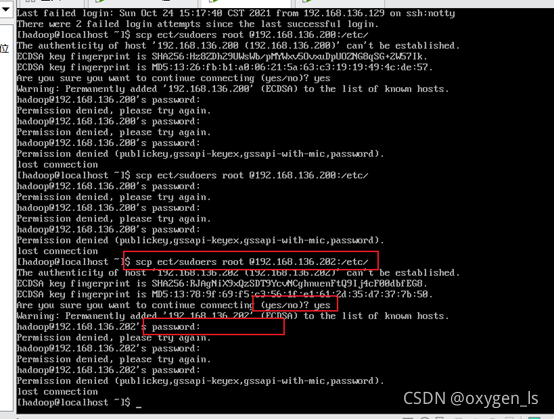
測驗
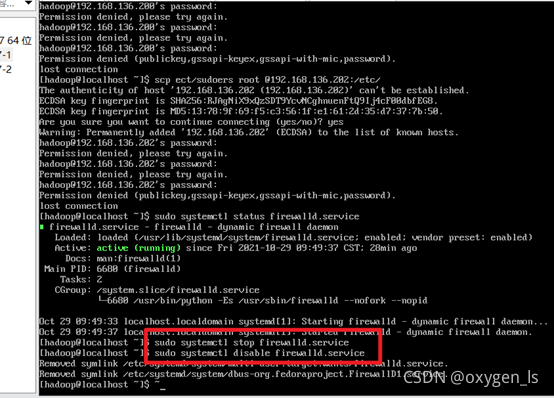
3.關閉防火墻
sudo systemctl status firewalld.service //查看防火墻的狀態
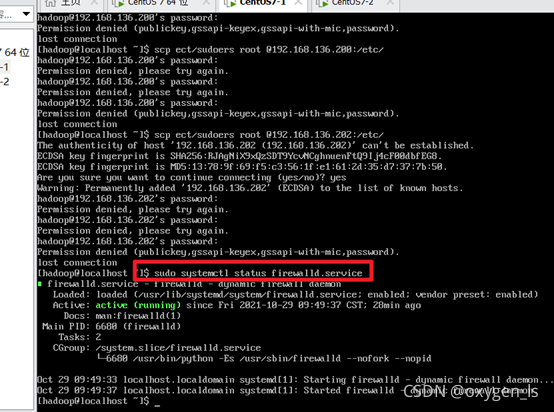
關閉防火墻:
sudo systemctl stop firewalld.service
sudo systemctl disable firewalld.service
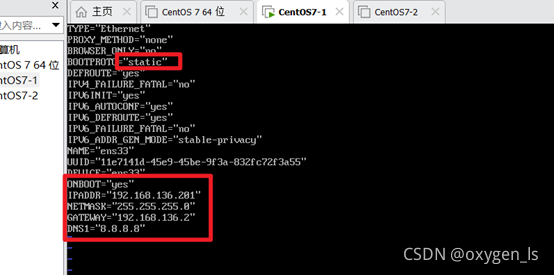
4.配置靜態IP
su
vi /etc/sysconfig/network-scripts/ifcfg-ens33
如下圖
 同理更改DN1,DN2的靜態IP,并sudo reboot看是否生效(有IP)
同理更改DN1,DN2的靜態IP,并sudo reboot看是否生效(有IP)
5.修改主機名
NN1 192.168.136.200
DN1 192.168.136.201
DN2 192.168.136.202
查看機器的名稱
hostname
修改名稱
vim /etc/hostname
將對應的主機名稱修改一下
查看名稱
cat /etc/hostname
同理更改DN1,DN2
6.修改IP和主機名的映射關系,主機IP映射如下
192.168.78.200 NN1
192.168.78.201 DN1
192.168.78.202 DN2
在下面這個檔案里面添加以上內容
vim /etc/hosts
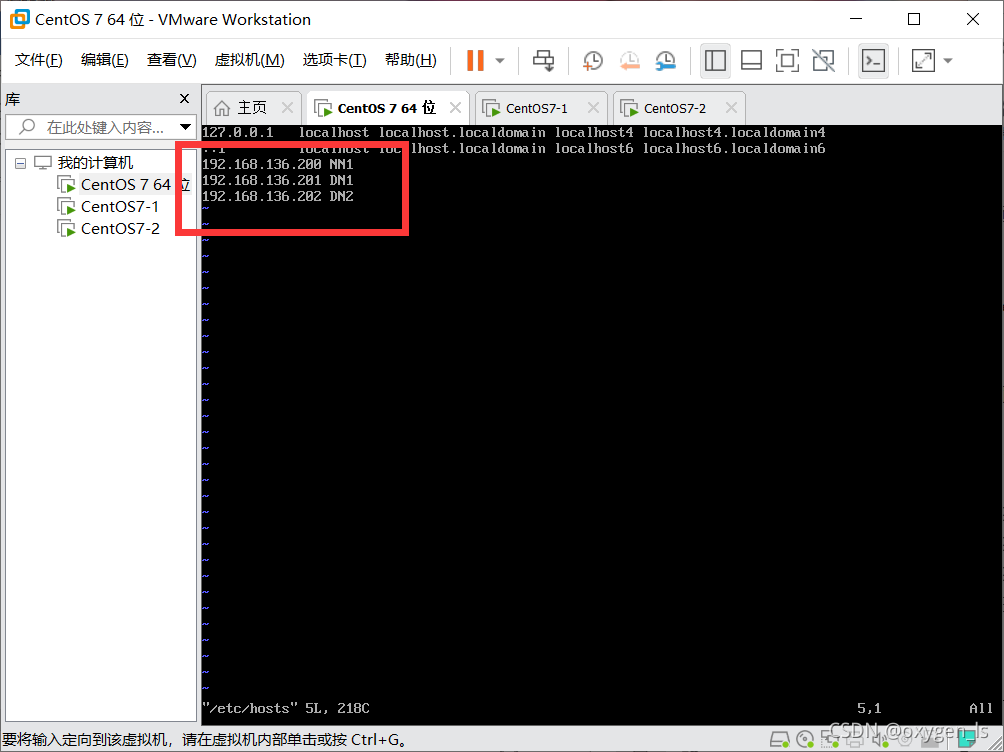
同理修改DN1,DN2
測驗:分別ping 主機的名字 ctl+z退出
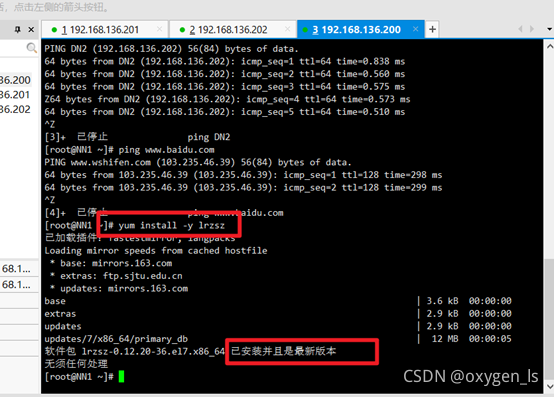
安裝插件:
yum install -y lrzsz
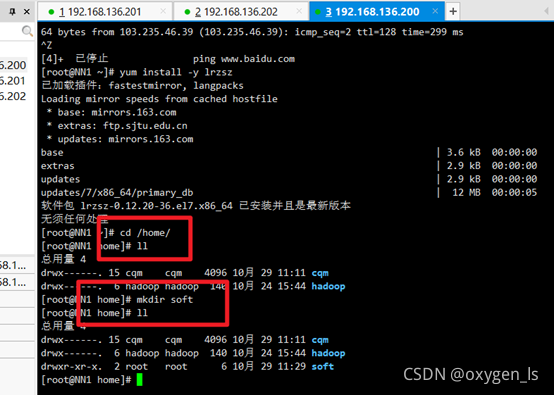
新建資源目錄:
cd /home/
ll
mkdir soft
ll
7.卸載OPENJDK,安裝新版JDK
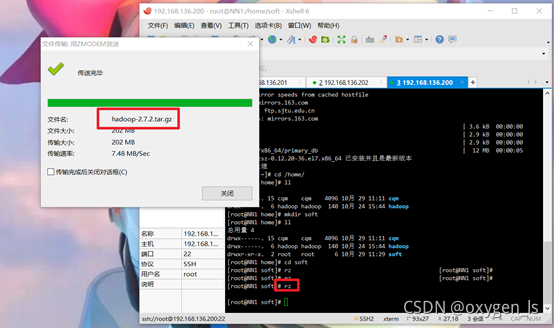
上傳jdk和hadoop命令:
rz
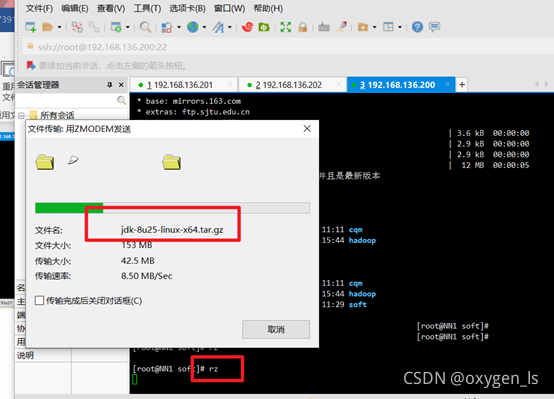
查看是否上傳成功:
ll
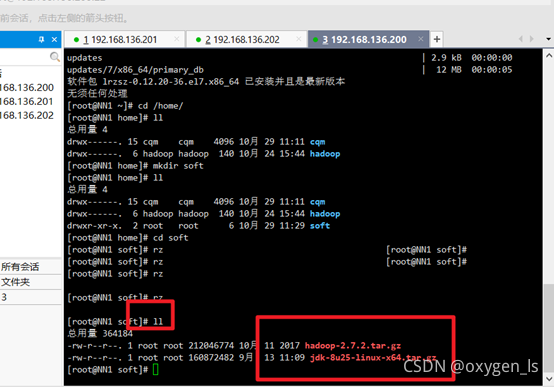
查看以前安裝的jdk:
rpm -qa | grep jdk
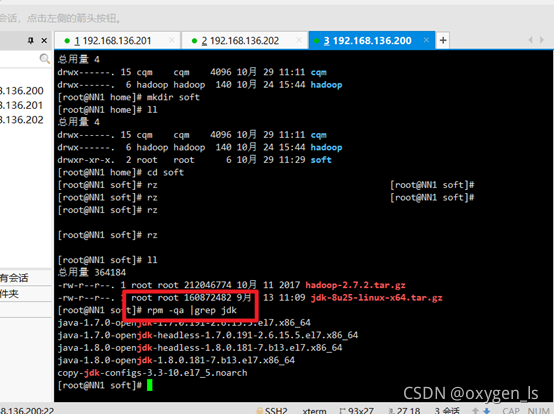
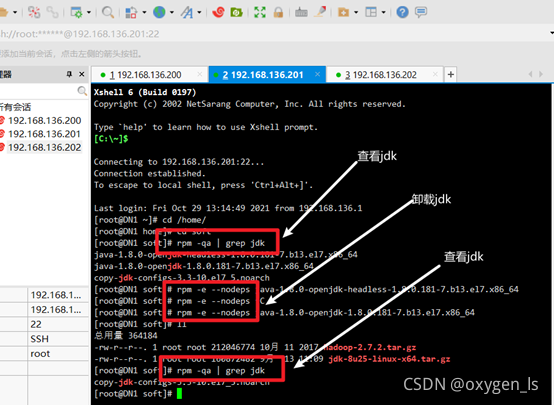
卸載原有的jdk,再查看:
rpm -e –nodeps +jdk名字
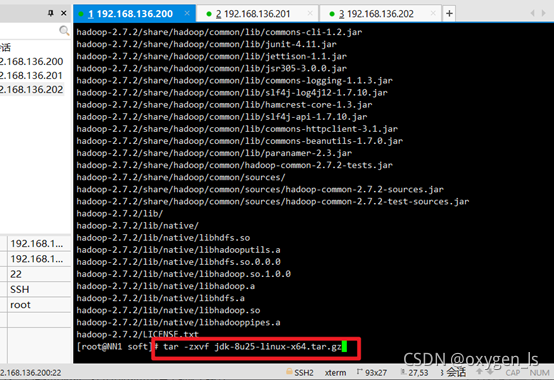
解壓jdk:
tar -zxvf +jdk名稱
解壓hadoop:
tar -zxvf +hadoop名稱
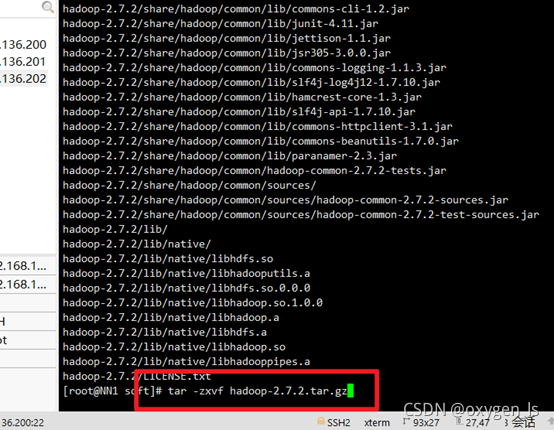
查看:
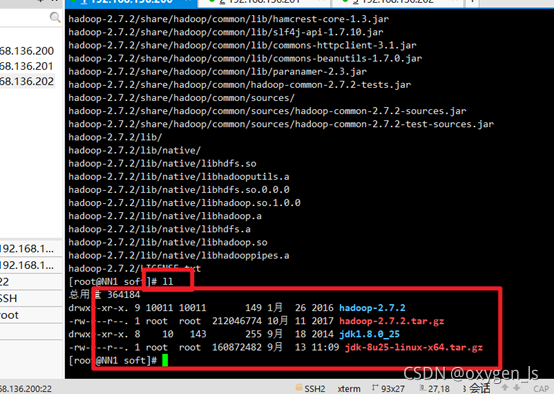
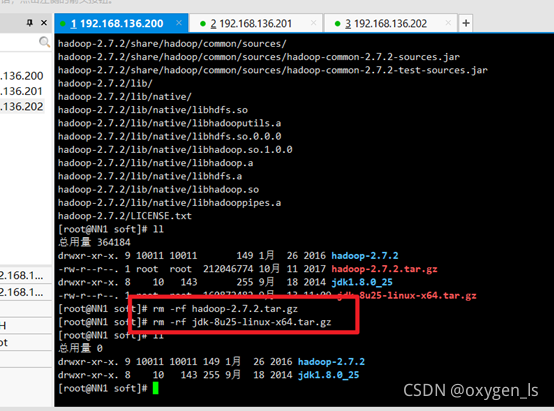
洗掉安裝包,留下解壓好的jdk和hadoop:
rm -rf +hadoop名稱
rm -rf +jdk名稱
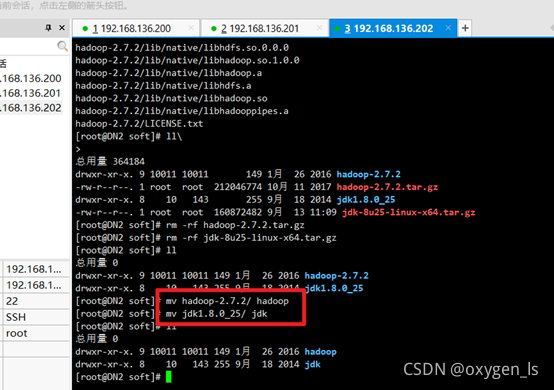
修改hadoop和jdk名稱:
mv hadoop-2.7.2/ hadoop
mv jdk1.8.0_25/ jdk
8.準備三臺CENTOS
完整克隆出另外兩臺電腦,并把IP,機器名更改后,再分別測驗一下,(新手建議不要克隆,三臺一起配置,加強記憶)
9.各節點無密鑰登錄配置(超簡單)
1.切換到hadoop用戶
su – hadoop
2.生成密鑰對,并將公鑰加入到授權檔案中
輸入:
cd ~/.ssh (如果沒有這個目錄,你先執行ssh localhost就會生成.ssh目錄)
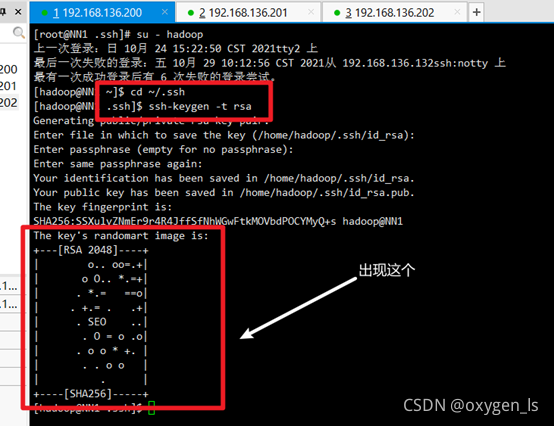
輸入:
ssh-keygen -t rsa
按三次回車后:
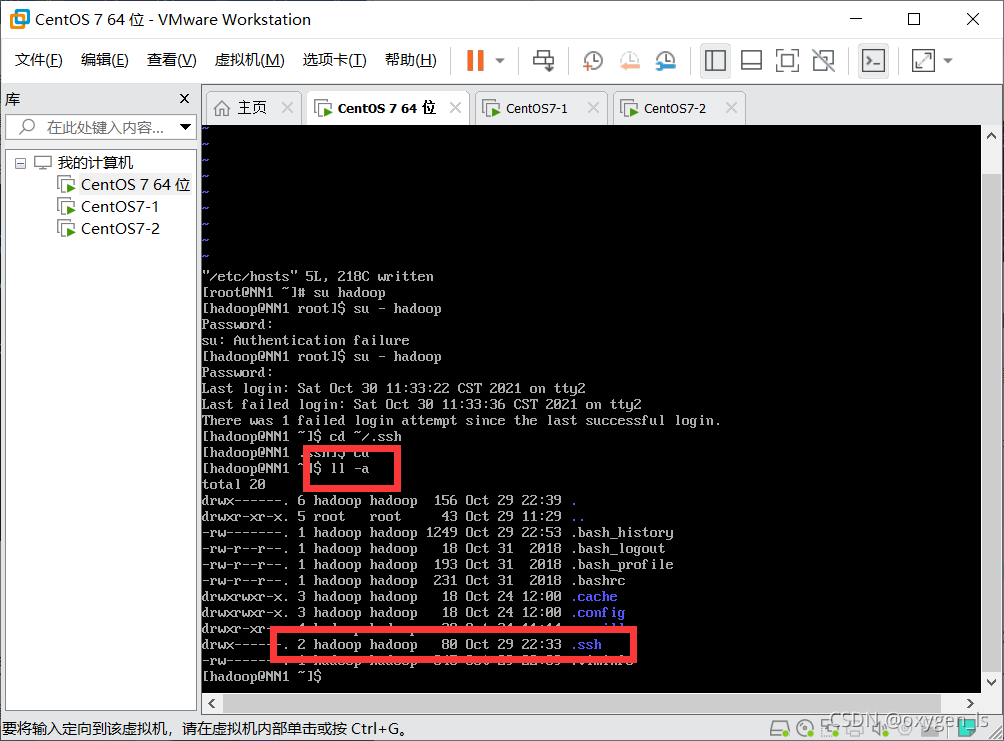
1.在hadoop目錄下輸入:
ll -a(查看生成的.ssh目錄)
2.進入檔案目錄
cd .ssh
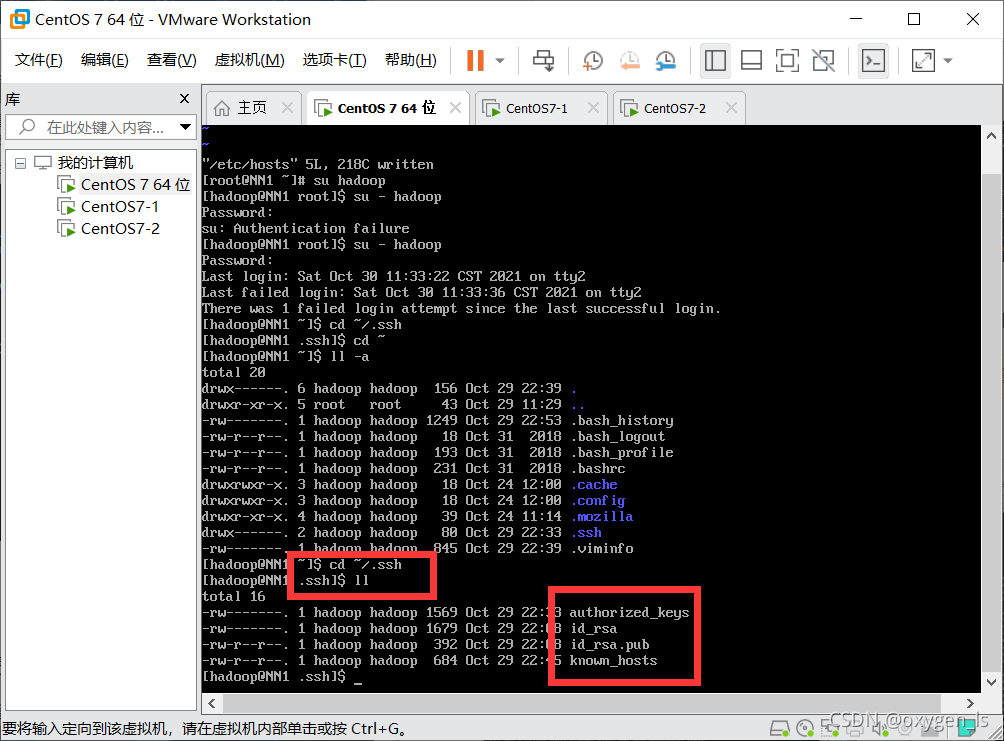
可以看到id_rsa是私鑰
id_rsa.pub是公鑰(私鑰自己用,公鑰給其他機器,一個公鑰對應一個私鑰)
3.將id_rsa.pub復制到新檔案authorized_keys檔案中:
cat id_rsa.pub >> authorized_keys
4.給這個authrized_keys檔案授權為600
chmod 600 authorized_keys
5.在其他節點上執行相同操作(dn1/dn2)
6.將其他節點(DN1/DN2)的authorized_keys的內容直接右鍵復制到上NN1的authorized_keys檔案里面
7.將NN1的authorized_keys直接復制到每個節點的hadoop用戶下
scp ~/.ssh/authorized_keys hadoop@DN1:~/.ssh
scp ~/.ssh/authorized_keys hadoop@DN2:~/.ssh
配置JDK
配置環境變數:
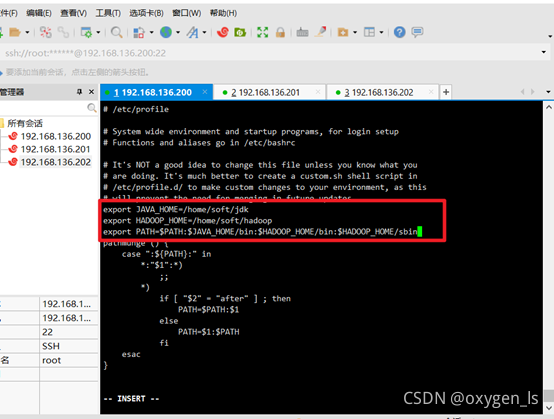
vi /etc/profile
添加:
export JAVA_HOME=/home/soft/jdk
export HADOOP_HOME=/home/soft/hadoop
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
執行檔案命令:
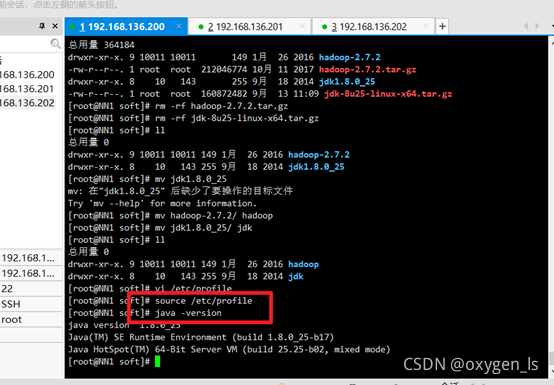
source /etc/profile
查看jdk版本:
java -version
配置HDFS
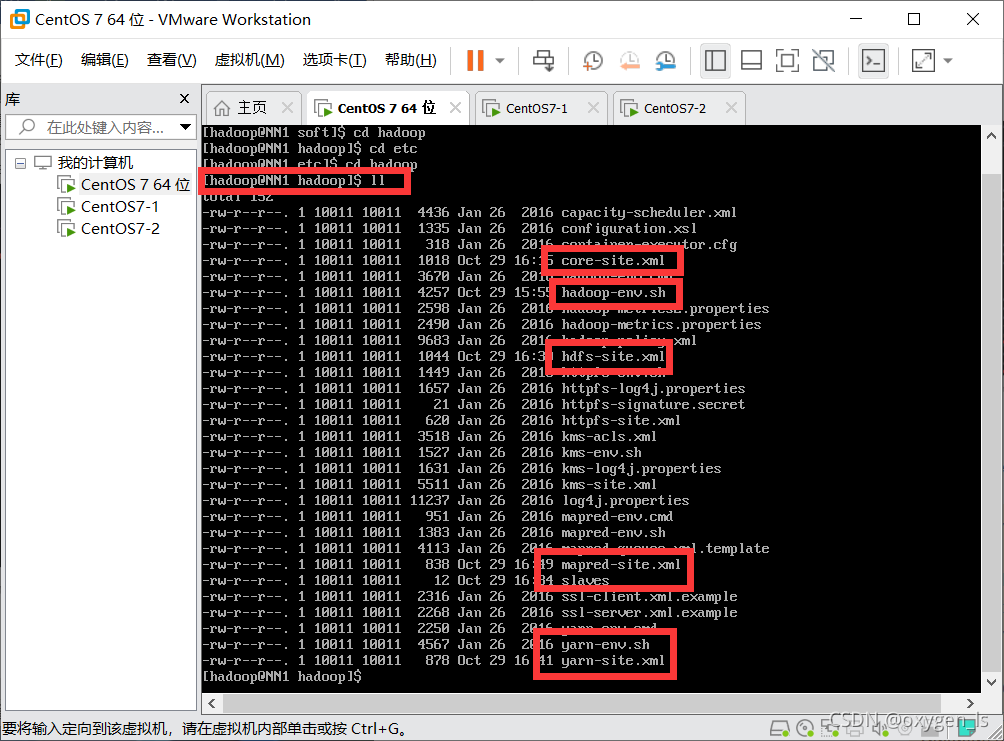
進入hadoop/etc/hadoop/目錄下:
cd hadoop/etc/hadoop/
查看有哪些檔案:
ll
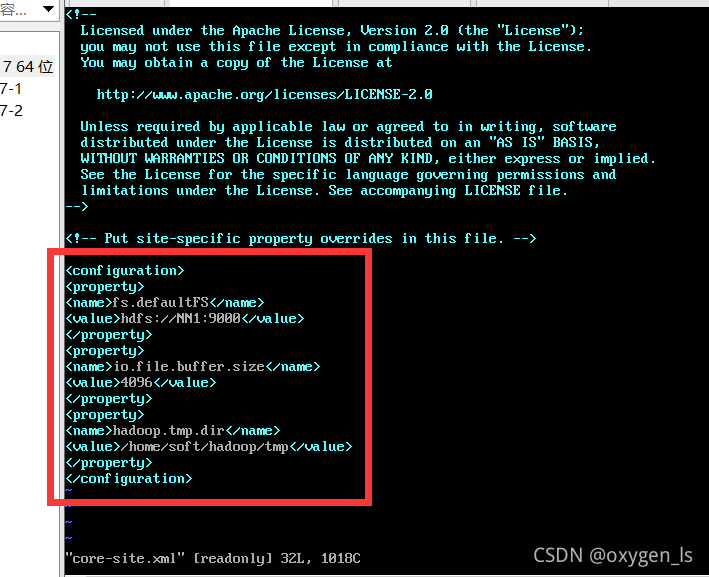
1.修改core-site.xml命令: vi core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://NN1:9000</value> //NN1為主機名
</property>
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/soft/hadoop/tmp</value>
</property>
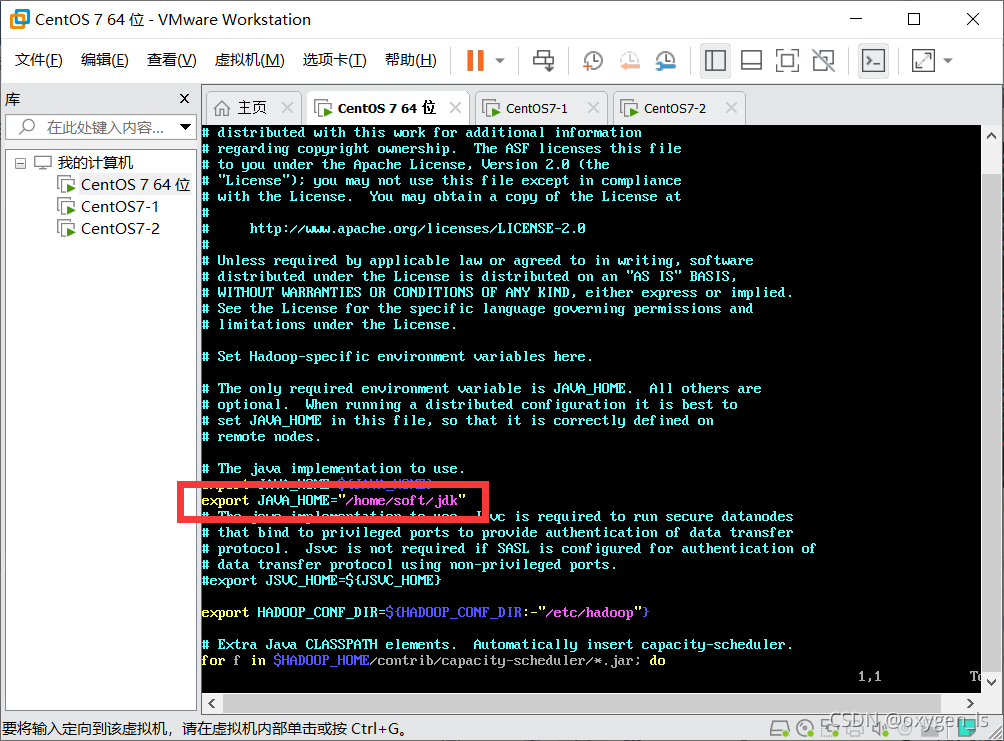
2.修改hadoop-env.sh檔案:vi hadoop-env.sh
添加一句:export JAVA_HOME=”/home/soft/jdk”
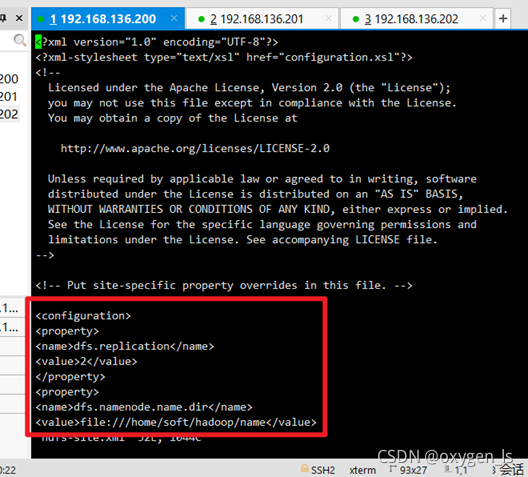
3.修改hdfs-site.xml命令:vi hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///home/soft/hadoop/name</value>
</property>
<property>
<name>dfs.datanode.dir</name>
<value>file:///home/soft/hadoop/data</value>
</property>
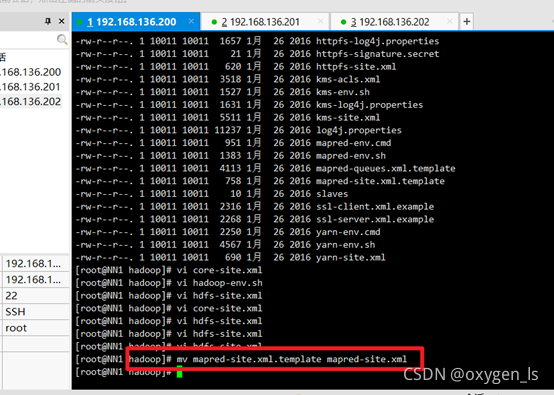
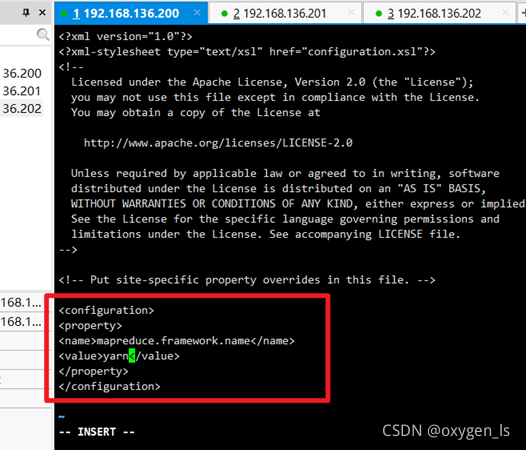
4.重命名mapred-site.xml.template更名為mapred-site.xml:
mv mapred-site.xml.template mapred-site.xml
修改mapred-site.xml:vi mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
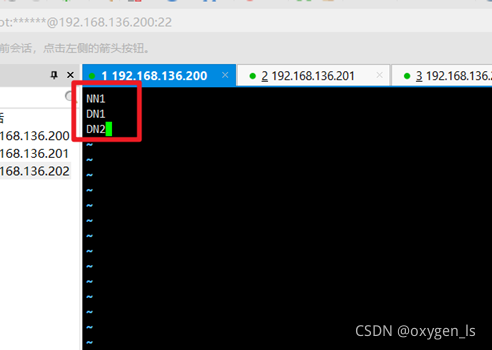
5.修改slaves檔案:
vi slaves
將主機名寫進去
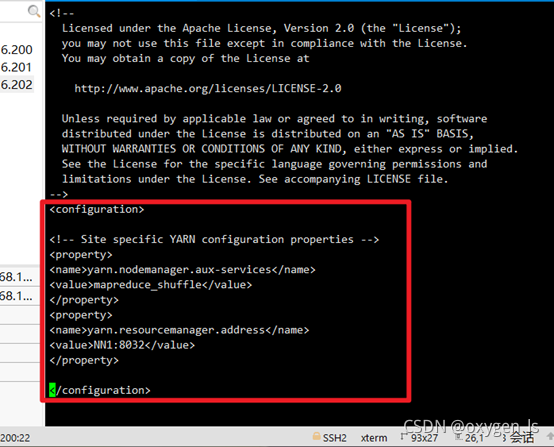
6.修改yarn-site.xml檔案:vi yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>NN1:8032</value>
</property>
至此虛擬機配置已經配置好了
新手一枚發現問題,歡迎指正~~
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/342153.html
標籤:其他
上一篇:kafka之訊息生成者基本知識
下一篇:Flink狀態管理與Checkpoint實戰——模擬電商訂單計算程序中宕機的場景,探索宕機恢復時如何精準繼續計算訂單