自動駕駛是最近幾年的熱門領域,專注于自動駕駛技術的創業公司、新造車企業、傳統車廠都在這個領域投入了大量的資源,推動著 L4、L5 級別自動駕駛體驗能盡早進入我們的日常生活,
自動駕駛技術實作的核心環節是自動駕駛模型的訓練,訓練資料是由汽車實際采集回來的真實道路駕駛視頻,資料規模有數 PB 到數十 PB 之多,在模型訓練之前,先要對這些原始視頻進行處理,截取其中的關鍵幀保存為照片,然后再由專業資料標注團隊在圖片上標記關鍵資訊,比如紅綠燈、道路標記等,最終經過標記的數十億圖片和標記資料成為真正要「喂給」訓練框架的內容,
熟悉分布式系統和分布式存盤的朋友一定知道,LOSF(Lots of Small Files,海量小檔案)是存盤領域的大難題,而在人工智能 CV(Computer Vision)領域中基于 LOSF 的訓練又是剛需,包括自動駕駛、人臉識別、物體檢測等細分領域,
本篇文章來自 JuiceFS 某自動駕駛行業客戶的架構實踐,在百億規模小檔案訓練場景下進行了一系列成功的探索,希望能為相關行業的應用帶來一些參考和啟發,
百億小檔案管理的極致挑戰
自動駕駛系統的訓練資料集大多有數十億到數百億小檔案(小于 1MiB 的檔案),一次訓練通常需要數千萬到數億檔案,而且訓練 worker 每一次生成 mini-batch 都需要頻繁訪問存盤系統,其中大部分是對元資料的請求,因此,元資料性能直接影響模型訓練的效率,
這就要求存盤系統不僅要具備管理百億檔案的能力,還必須在高并發請求下,保持低時延、高吞吐的元資料性能,
在存盤系統選型中,物件存盤是能夠承載百億規模檔案的,但是缺少原生目錄支持、缺少完整 POSIX 語意支持、元資料性能弱這三方面的問題讓物件存盤并不適合海量小檔案訓練場景,
在一些常見的分布式檔案系統架構設計中,HDFS 并不適合存盤小檔案,雖然可以采用 Scale-Up NameNode 和聯邦(federation)的方式容納一定規模的資料,但要存盤百億級小檔案依然是一件非常困難的事情;CephFS 的 MDS 雖然有 Scale-Out 能力,但單行程的并發處理能力不高,隨著 MDS 集群規模的增長行程間協調開銷增大,使得整體性能達不到線性增長,
雖然在 TensorFlow 中支持將多個小檔案合并成大檔案的 TFRecord 格式來降低訓練程序中對存盤系統的元資料負載壓力,但是在自動駕駛領域,這種方案降低了資料集隨機取樣的精度,而且其它訓練框架(如 PyTorch)也不兼容,造成很多不便,
JuiceFS 如何解決?
JuiceFS 是面向云原生環境設計的開源分布式檔案系統,JuiceFS 的創新在于:
- 可以用任意物件存盤作為資料持久層,保存資料內容,無論任何公有云、私有云環境,只要有物件存盤服務,都能用 JuiceFS;
- 100% 兼容 POSIX、HDFS、S3 三大主流訪問協議,能對接所有應用;
- 元資料引擎是可插拔架構,支持包括 Redis、TiKV、MySQL 等多種資料庫作為存盤引擎,同時,也提供兼具高性能和海量存盤的商用元資料引擎,
JuiceFS 的商用元資料引擎采用 Raft 演算法組成分布式集群,保證資料的可靠性、一致性和高可用性,元資料全部存盤在節點的記憶體中,保證低時延回應,元資料引擎采用動態目錄樹方案進行橫向擴展,每個分片(shard)是一個獨立的 Raft 組,檔案系統目錄樹可以任意劃分,分配到需要的分片中,自動均衡與手動均衡相結合,分片機制對于客戶端訪問透明,
靈活配置快取大幅提升訓練效率
既然訓練任務需要頻繁訪問存盤系統,每次經過網路的開銷疊加起來也是不小的冗余,目前工業界都在探索存盤與計算分離后的快取加速方案,JuiceFS 已經內置了快取能力,客戶端訪問過的資料,可以自動快取在該節點指定的存盤介質上,下次訪問就能直接命中快取,不用再通過網路讀取,同樣,元資料也會自動快取到客戶端記憶體中,
快取機制在使用上是透明的,無需改變現有應用,只要在 JuiceFS 客戶端掛載時添加幾個引數,說明快取的路徑、容量等資訊即可,快取對于訓練加速的效果非常明顯,可以參考我們另外一篇文章「如何借助 JuiceFS 為 AI 模型訓練提速 7 倍」,快取不僅能加速訓練,還能顯著減少物件存盤 API 的呼叫,從而降低費用開銷,
對于分布式訓練平臺來說,相同的訓練資料可能會被不同的任務共享,這些任務不一定會被調度到同一個節點上,如果是分布在不同節點那快取資料還能共享嗎?利用 JuiceFS 的「快取資料共享」特性,多個訓練節點共同組成一個快取集群,在這個集群中的訓練任務都可以共享快取資料,也就是說當訓練任務所處的節點沒有命中快取時,能夠通過同一集群中的其它節點來獲取資料,而不用去請求遠端的物件存盤,
訓練節點可能不是一個靜態的資源,特別是在容器平臺里,生命周期的變換是很快的,是否會影響快取資料共享的效果呢?這就要引出下一個問題,
快取機制在彈性集群中的挑戰
每一家自動駕駛領域的公司都有很多演算法研究員、工程師,他們的演算法要共享公司的計算資源完成訓練和驗證,從平臺角度講,資源彈性伸縮是一個提高整體利用率的好方法,按需給每個訓練任務分配資源,避免浪費,
但在這種彈性伸縮的集群中,前面提到的本地快取資料會受到一定影響,雖然快取集群通過一致性哈希確保了當集群成員發生變化時,需要遷移的資料盡量少,但是對于大規模的訓練集群來說這樣的資料遷移還是會對整體的訓練效率造成影響,
有沒有一種方法既能滿足訓練集群資源彈性伸縮的需求,又不顯著影響模型訓練效率呢?
這就需要 JuiceFS 獨有的「獨立快取集群」特性了,
所謂獨立快取集群,就是將負責存盤快取資料的節點獨立部署,提供常駐的快取資料服務,這樣不會受訓練集群動態變化的影響,讓訓練任務有更高、更穩定的快取命中率,
整體系統的架構如下圖所示:
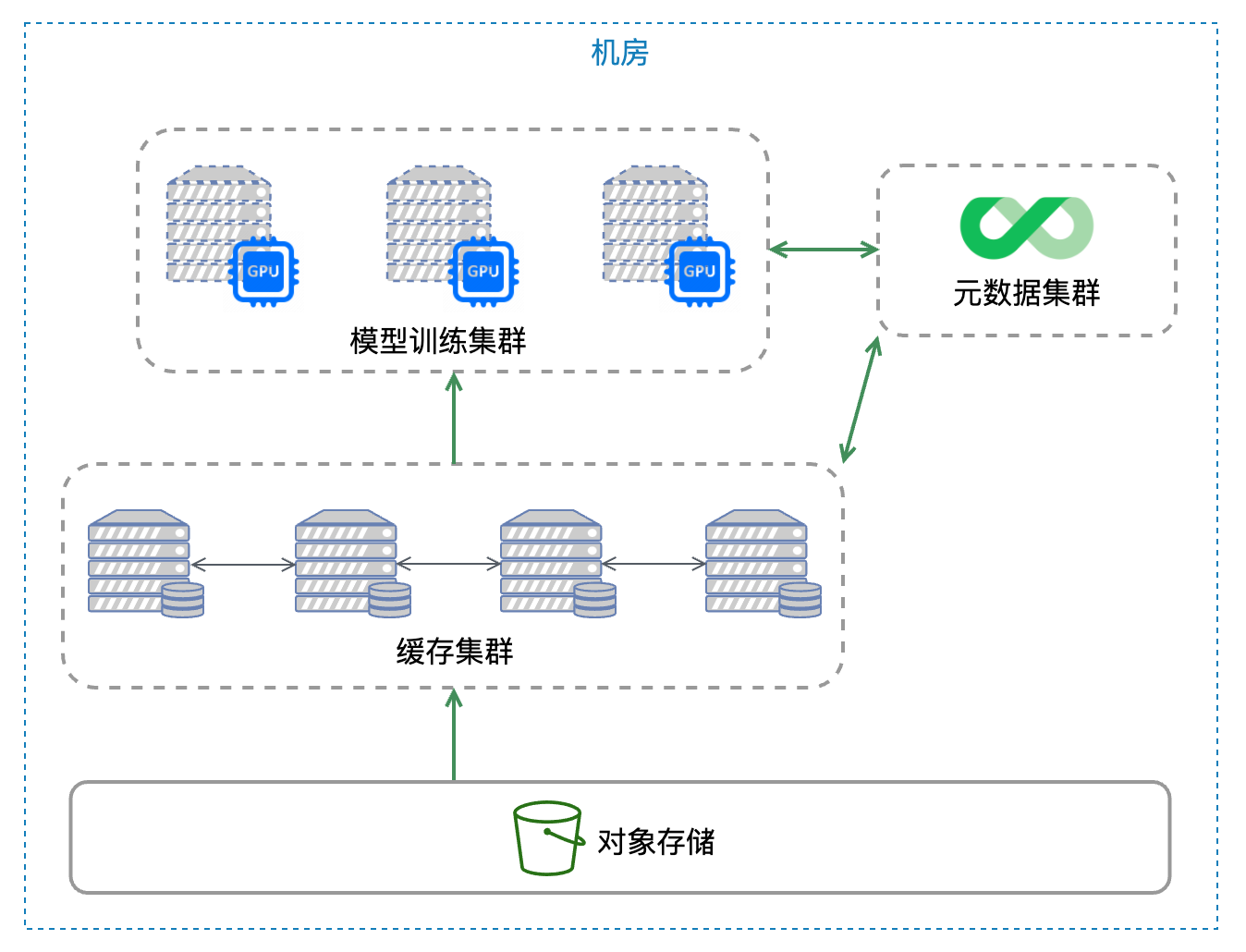
比如有一個動態的訓練集群 A 和專門用來做快取的集群 B,他們都需要使用相同的掛載引數 --cache-group=CACHEGROUP 來構建一個快取組,其中集群 A 的節點掛載時需要加上 --no-sharing 引數,當集群 A 的應用讀資料時,如果當前節點的記憶體和快取盤上沒有該快取資料,它就會根據一致性哈希從集群 B 中選擇一個節點來讀取資料,
此時整個系統由 3 級快取構成:訓練節點的系統快取、訓練節點的磁盤快取、快取集群 B 中的快取,用戶可以根據具體應用的訪問特點配置各個層級的快取介質和容量,
為了確保當磁盤損壞時不會對訓練任務產生影響,JuiceFS 還提供了快取資料容災能力,如果快取節點的磁盤意外損壞,更換新的磁盤后 JuiceFS 可以自動重建需要的快取資料,
如何實作混合云中的降本增效?
自動駕駛的訓練任務需要大量的 GPU 資源,在充分利用的情況下,自己在機房中采購 GPU,可以比使用公有云便宜不少,這也是目前很多自動駕駛公司的選擇,但是,在機房中自建存盤系統則沒這么簡單,會遇到兩個挑戰:
- 資料增長快,采購很難跟上擴容速度,一次買太多,又會造成浪費;
- 維護大規模的存盤集群,必須面對磁盤損壞等問題,運維成本高,效率低;
相比自建存盤系統,公有云上的物件存盤服務可以彈性伸縮,無限擴容,單位成本便宜,資料的可靠性和服務的可用性相比機房自建存盤都更高,是存盤海量資料的不錯選擇,
JuiceFS 非常適合這種 IDC 機房 + 公有云的混合云架構,用戶將自己的 IDC 機房與公有云專線連接,資料通過 JuiceFS 持久化到公有云物件存盤中,在 IDC 機房里設定一個快取集群,起到快取資料加速訓練的效果,相比每次從物件存盤訪問資料,既能節省專線帶寬,還能節省物件存盤 API 呼叫費用,
當混合云架構結合 JuiceFS 之后,既享受了云存盤帶來的便利,又通過自建 IDC 降低了 GPU 成本,對于訓練平臺的使用者、維護者來說都非常簡單方便,滿足企業多樣化的基礎設施架構設計需求,
多機房的資料同步與管理
在這個實踐案例中,客戶有兩個 IDC,相距上千公里,訓練任務也會被分配到兩個 IDC 中,因此資料集也需要在兩個 IDC 中被訪問,之前,客戶是手工維護將資料集復制到兩個 IDC 中,使用 JuiceFS 后,「資料鏡像」特性可以省去此前的手工勞動,資料實時同步,滿足多地協同作業的需求,
具體來說,資料鏡像功能需要在兩個 IDC 中都部署 JuiceFS 的元資料集群,當資料鏡像啟用后,原始檔案系統會自動將元資料復制到鏡像區域,鏡像檔案系統被掛載后,客戶端會從原始檔案系統的物件存盤拉取資料,寫入到鏡像檔案系統的物件存盤,鏡像檔案系統掛載后,資料會優先從本地的物件存盤讀取,如果因同步未完成而出現讀取失敗,則會嘗試從原始檔案系統的物件存盤讀取,
啟用資料鏡像后,所有資料可以自動復制到兩個物件存盤中,起到異地災備的作用,如果不需要異地災備,在鏡像區域可以不配置物件存盤,只進行元資料的復制,資料可以提前預熱到鏡像區域的獨立快取集群來加速訓練,這樣可以省去一份物件存盤的成本,本案例中的客戶就采用了此方案,
全方位資料安全保護
不管是為了實作輔助駕駛還是真正的自動駕駛,日常都需要通過路采車收集大量的路采資料,這些資料會再經過一些處理流程二次加工以后最終存盤到企業的存盤系統中,自動駕駛企業對于這些資料的安全性和可靠性有著極高的要求,因此資料保護是一個非常關鍵的問題,
我們首先來看看企業上云以后的安全問題,很多時候企業對于上云會存在一定的資料安全擔憂,特別是當涉及到一些敏感資料時,JuiceFS 提供的「資料加密」特性同時支持傳輸中加密(encryption in transit)和靜態加密(encryption at rest),保障上云程序中各個環節的資料安全性,
其次可能面臨的是資料管理問題,為了防止資料泄漏或誤操作,企業可能需要針對不同團隊、不同用戶進行權限管理和控制,JuiceFS 托管服務通過「訪問令牌」可以限定某個 IP 范圍的讀寫權限以及可訪問的子目錄,掛載之后,JuiceFS 支持基于「用戶/用戶組」 的權限管理模型,可以靈活針對團隊或者個人進行權限設定,
如果某個用戶已經具備訪問某些資料的權限,也還是需要進一步對資料進行保護,比如用戶可能誤洗掉或者誤更新資料,對于誤洗掉,JuiceFS 托管服務提供的「回收站」功能可以確保資料被洗掉以后的一段時間內能夠再次恢復,
但是如果資料被誤更新了或者因為某種原因損壞了,即使有回收站也無濟于事,此時 JuiceFS 的「實時資料保護」特性就非常有用了,這個功能的實作原理是保留一定時間的 Raft 日志,這樣當資料誤更新發生時可以通過回放歷史日志的方式將當時的元資料恢復,同時由于 JuiceFS 寫入物件存盤的檔案是分塊(block)存盤,更新檔案不會修改歷史的 block 而是生成新的 block,因此只要物件存盤上的歷史 block 還沒有被洗掉就可以完整恢復資料,就像一個可以隨時時光倒流的「時間機器」一樣!
總結
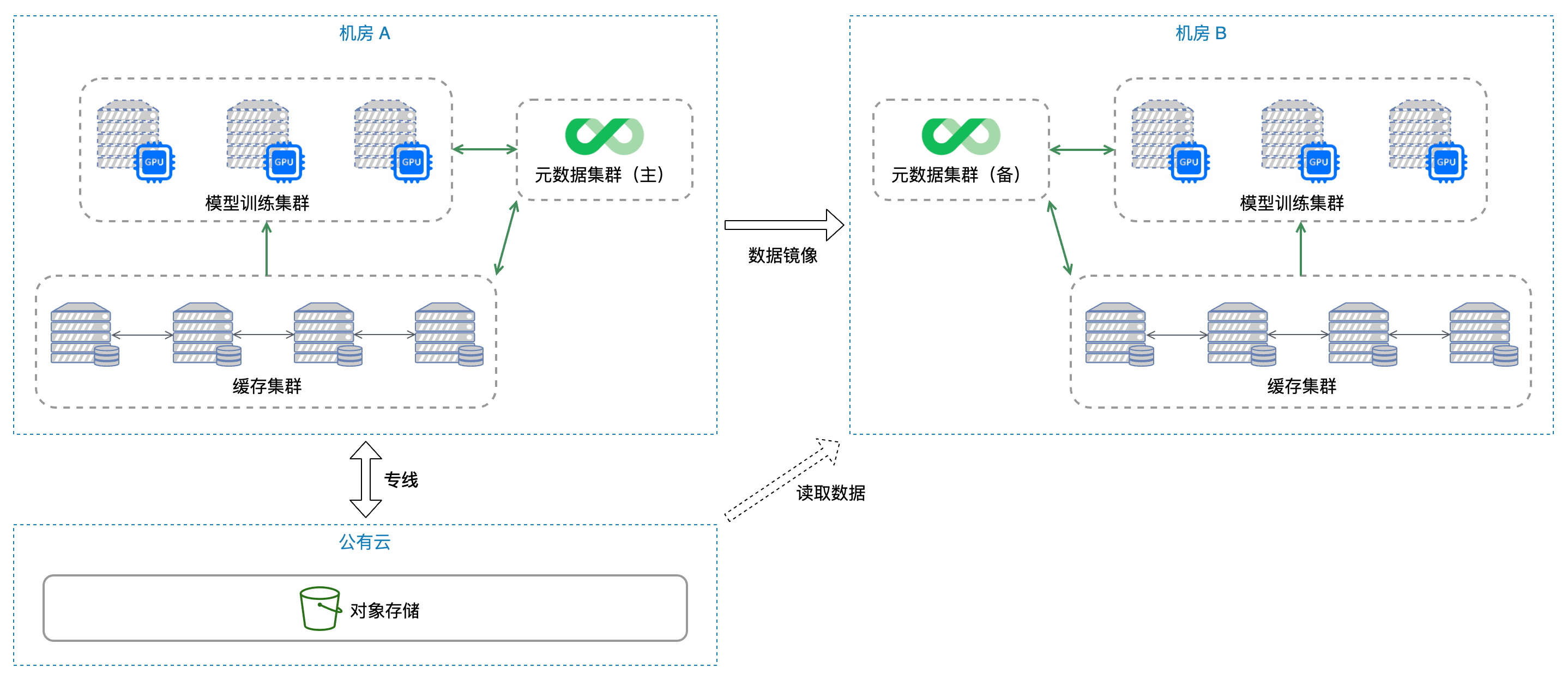
完整架構設計
下圖是本案例的整體架構圖,在機房 A、B 中都部署了 JuiceFS 的元資料集群以及對應的獨立快取集群,模型訓練時將會優先通過快取集群讀取資料集,如果快取沒有命中再從物件存盤讀取資料,在實際測驗中,因為快取命中率非常高,機房 B 幾乎不需要跨機房訪問物件存盤,
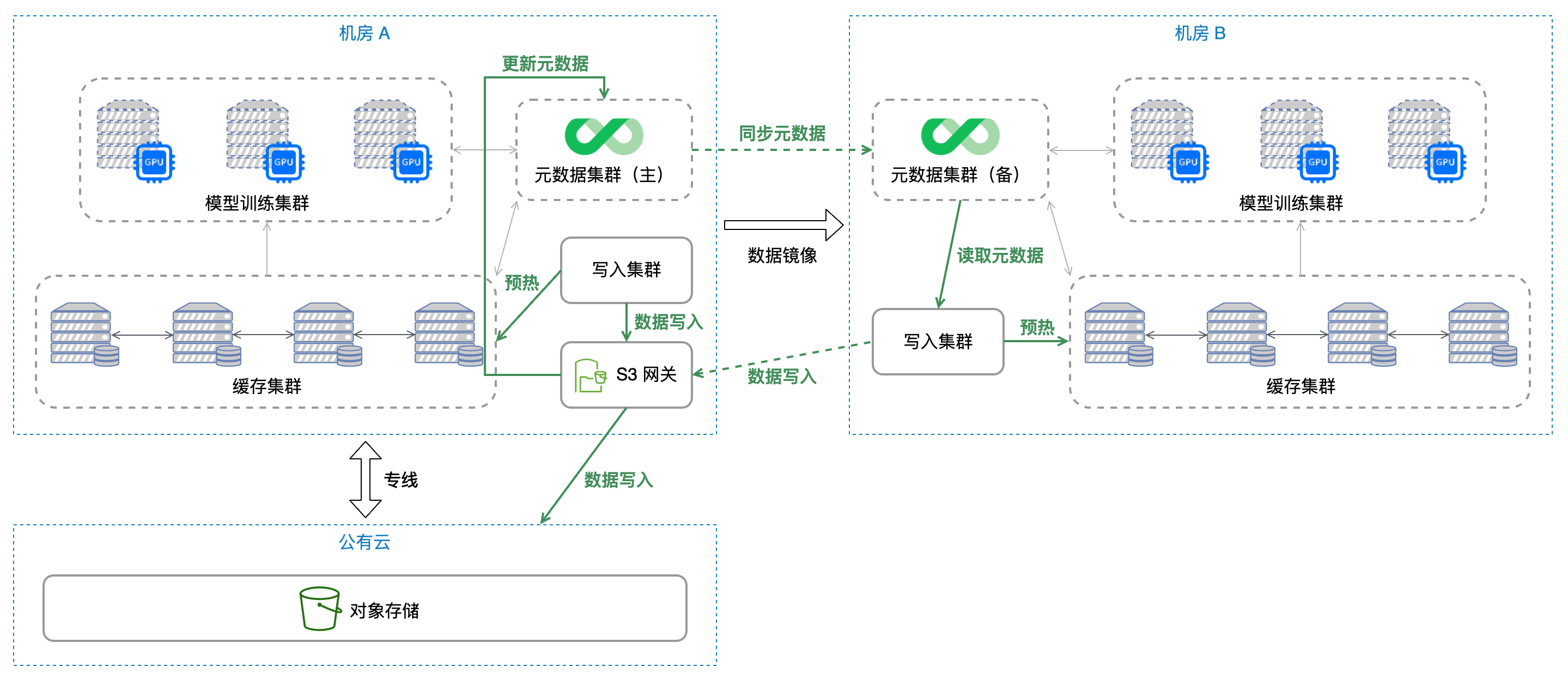
下圖描述了資料寫入流程,客戶通過 JuiceFS 提供的 S3 網關寫入資料,當新資料寫入以后,就會按照前面介紹的資料鏡像流程來將元資料復制到另一個機房,同時在兩個機房中都有對應的任務負責預熱獨立快取集群,確保新資料能夠及時建立快取,
客戶收益
這套方案已經上線到客戶生產環境中,下面列一些重要指標:
- 已經存盤了數十億的檔案,仍在持續增長;
- JuiceFS 元資料在數十萬 QPS 壓力下依然能提供 1ms 時延回應;
- 模型訓練吞吐數十 GiB/s;
- 獨立快取集群命中率 95%+;
- 兩個 IDC 之間資料同步的平均時延在數十毫秒級別,
通過升級到基于 JuiceFS 的存盤系統,客戶不僅能夠輕松管理好海量資料集,同時借助 JuiceFS 的獨立快取集群特性保證了模型訓練的效率,運維成本顯著降低的同時,機房 + 公有云的混合云架構相比單一公有云的架構 TCO 也更低,既能利用機房高性價比的計算資源,也能結合公有云上彈性的存盤資源,
得益于 JuiceFS 完全兼容 POSIX 的特性,客戶在遷移程序中,訓練任務的代碼不需要做任何修改,
通過 JuiceFS 的資料鏡像特性,自動地將資料從一個機房同步到另一個機房,解決多地協作問題,也滿足了企業異地災備的需求,
推薦閱讀:
Elasticsearch 存盤成本省 60%,稿定科技干貨分享
專案地址: Github (https://github.com/juicedata/juicefs)如有幫助的話歡迎關注我們喲! (0?0?)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/345524.html
標籤:其他