目錄
- Beam Search快速理解及代碼決議(上)
- Beam Search
- 貪心搜索
- Beam Search
- Beam Search代碼決議
- 準備初始輸入
- 序列擴展
- 準備輸出
- 總結
- Beam Search
- Beam Search快速理解及代碼決議(下)
- Beam Search的問題
- 解決對策
- 隨機采樣
- top-k采樣
- 核采樣(Nucleus sampling)
- 懲罰重復
- 代碼決議
- 參考資料
Beam Search快速理解及代碼決議(上)
Beam Search
簡單介紹一下在文本生成任務中常用的解碼策略Beam Search(集束搜索),
生成式任務相比普通的分類、tagging等NLP任務會復雜不少,在生成的時候,模型的輸出是一個時間步一個時間步依次獲得的,而且前面時間步的結果還會影響后面時間步的結果,也就是說,每一個時間步,模型給出的都是基于歷史生成結果的條件概率,為了生成完整的句子,需要一個稱為解碼的額外動作來融合模型多個時間步的輸出,而且使得最終得到的序列的每一步條件概率連乘起來最大,
在文本生成任務中,每一個時間步可能的輸出種類稱為字典大小(vocabulary size,我們用V表示),進行T步隨機的生成可能獲得的結果總共有V^T種,拿中文文本生成來說,V 的值大約是5000-6000,即常用漢字的個數,在如此大的基數下,遍歷整個生成空間是不現實的,
貪心搜索
每一個時間步都取出一個條件概率最大的輸出,如圖:

Beam Search
思路也很簡單,就是稍微放寬一些考察的范圍,在每一個時間步,不再只保留當前分數最高的1個輸出,而是保留num_beams個,當num_beams=1時集束搜索就退化成了貪心搜索,

Beam Search示意圖
- 在第一個時間步,A和C是最優的兩個,因此得到了兩個結果[A],[C],其他三個就被拋棄了;
- 第二步會基于這兩個結果繼續進行生成,在A這個分支可以得到5個候選人,[AA],[AB],[AC],[AD],[AE],C也同理得到5個,此時會對這10個進行統一排名,再保留最優的兩個,即圖中的[AB]和[CE];
- 第三步同理,也會從新的10個候選人里再保留最好的兩個,最后得到了[ABD],[CED]兩個結果, 可以發現,beam search在每一步需要考察的候選人數量是貪心搜索的num_beams倍,因此是一種犧牲時間換性能的方法,
Beam Search代碼決議
Beam Search的原理雖然簡單,但實際實作的時候卻有很多細節要考慮,下面要決議這個實作出自于NLP界著名Python包Transformers[1],我為了說明方便做了一些改動,
一個正確且高效的演算法需要處理的問題大概有兩個:
- 充分利用硬體,可以處理批量資料,且盡量使用并行計算少用回圈
- 處理好長短不同的生成結果
下面是基礎版的beam search函式定義,其中context是編碼器編碼獲得的向量,batch_size是每批資料中包含的樣本量,bos_token_id是句子開頭標志的token id,pad_token_id是用于填充的token id,eos_token_id是句子結束標志的token id,這里給引數填上的默認值和我們后面講解時使用的例子是一致的,
def beam_search_generate(context,
batch_size=3,
max_length=20,
min_length=2,
num_beams=2,
bos_token_id=101,
pad_token_id=0,
eos_token_id=102,
):
pass
在函式中主要執行以下三個步驟:
- 準備初始輸入
- 在當前生成的序列長度未達到
max_length時擴展生成序列 - 準備最終輸出的序列
準備初始輸入
# 建立beam容器,每個樣本一個
generated_hyps = [
BeamHypotheses(num_beams, max_length, length_penalty, early_stopping=early_stopping)
for _ in range(batch_size)
]
# 每個beam容器的得分,共batch_size*num_beams個
beam_scores = torch.zeros((batch_size, num_beams), dtype=torch.float, device=encoder_input_ids.device)
beam_scores = beam_scores.view(-1)
# 每個樣本是否完成生成,共batch_size個
done = [False for _ in range(batch_size)]
# 為了并行計算,一次生成batch_size*num_beams個序列
# 第一步自動填入bos_token
input_ids = torch.full(
(batch_size*num_beams, 1),
bos_token_id,
dtype=torch.long,
device=next(self.parameters()).device,
)
# 當前長度設為1
cur_len = 1
其中BeamHypotheses是一個容器類,每個樣本系結一個,每個容器中會維護num_beams個當前最優的序列,當往容器中添加一個序列而導致序列數大于num_beams的時候,它會自動踢掉分數最低的那個序列,類代碼如下,
class BeamHypotheses(object):
def __init__(self, num_beams, max_length, length_penalty):
self.max_length = max_length - 1 # ignoring bos_token
self.num_beams = num_beams
self.beams = []
self.worst_score = 1e9
def __len__(self):
return len(self.beams)
def add(self, hyp, sum_logprobs):
score = sum_logprobs / len(hyp) ** self.length_penalty
if len(self) < self.num_beams or score > self.worst_score:
# 可更新的情況:數量未飽和或超過最差得分
self.beams.append((score, hyp))
if len(self) > self.num_beams:
# 數量飽和需要刪掉一個最差的
sorted_scores = sorted([(s, idx) for idx, (s, _) in enumerate(self.beams)])
del self.beams[sorted_scores[0][1]]
self.worst_score = sorted_scores[1][0]
else:
self.worst_score = min(score, self.worst_score)
def is_done(self, best_sum_logprobs, cur_len=None):
"""
相關樣本是否已經完成生成,
best_sum_logprobs是新的候選序列中的最高得分,
"""
if len(self) < self.num_beams:
return False
else:
if cur_len is None:
cur_len = self.max_length
cur_score = best_sum_logprobs / cur_len ** self.length_penalty
# 是否最高分比當前保存的最低分還差
ret = self.worst_score >= cur_score
return ret
序列擴展
序列擴展是beam search的核心程序,我們特地畫了一張圖來解釋這個版本的實作策略,
序列擴展示意圖,下面對照這個圖來講解代碼,
while cur_len < max_length:
# 將編碼器得到的背景關系向量和當前結果輸入解碼器,即圖中1
output = decoder.decode_next_step(context, input_ids)
# 輸出矩陣維度為:(batch*num_beams)*cur_len*vocab_size
# 取出最后一個時間步的各token概率,即當前條件概率
# (batch*num_beams)*vocab_size
scores = next_token_logits = output[:, -1, :]
###########################
# 這里可以做一大堆操作減少重復 #
###########################
# 計算序列條件概率的,因為取了log,所以直接相加即可,得到圖中2矩陣
# (batch_size * num_beams, vocab_size)
next_scores = scores + beam_scores[:, None].expand_as(scores)
# 為了提速,將結果重排成圖中3的形狀
next_scores = next_scores.view(
batch_size, num_beams * vocab_size
) # (batch_size, num_beams * vocab_size)
# 取出分數最高的token(圖中黑點)和其對應得分
# sorted=True,保證回傳序列是有序的
next_scores, next_tokens = torch.topk(next_scores, 2 * num_beams, dim=1, largest=True, sorted=True)
# 下一個時間步整個batch的beam串列
# 串列中的每一個元素都是三元組
# (分數, token_id, beam_id)
next_batch_beam = []
# 對每一個樣本進行擴展
for batch_idx in range(batch_size):
# 檢查樣本是否已經生成結束
if done[batch_idx]:
# 對于已經結束的句子,待添加的是pad token
next_batch_beam.extend([(0, pad_token_id, 0)] * num_beams) # pad the batch
continue
# 當前樣本下一個時間步的beam串列
next_sent_beam = []
# 對于還未結束的樣本需要找到分數最高的num_beams個擴展
# 注意,next_scores和next_tokens是對應的
# 而且已經按照next_scores排好順序
for beam_token_rank, (beam_token_id, beam_token_score) in enumerate(
zip(next_tokens[batch_idx], next_scores[batch_idx])
):
# get beam and word IDs
# 這兩行可參考圖中3進行理解
beam_id = beam_token_id // vocab_size
token_id = beam_token_id % vocab_size
effective_beam_id = batch_idx * num_beams + beam_id
# 如果出現了EOS token說明已經生成了完整句子
if (eos_token_id is not None) and (token_id.item() == eos_token_id):
# if beam_token does not belong to top num_beams tokens, it should not be added
is_beam_token_worse_than_top_num_beams = beam_token_rank >= num_beams
if is_beam_token_worse_than_top_num_beams:
continue
# 往容器中添加這個序列
generated_hyps[batch_idx].add(
input_ids[effective_beam_id].clone(), beam_token_score.item(),
)
else:
# add next predicted word if it is not eos_token
next_sent_beam.append((beam_token_score, token_id, effective_beam_id))
# 擴展num_beams個就夠了
if len(next_sent_beam) == num_beams:
break
# 檢查這個樣本是否已經生成完了,有兩種情況
# 1. 已經記錄過該樣本結束
# 2. 新的結果沒有使結果改善
done[batch_idx] = done[batch_idx] or generated_hyps[batch_idx].is_done(
next_scores[batch_idx].max().item(), cur_len=cur_len
)
# 把當前樣本的結果添加到batch結果的后面
next_batch_beam.extend(next_sent_beam)
# 如果全部樣本都已經生成結束便可以直接退出了
if all(done):
break
# 把三元組串列再還原成三個獨立串列
beam_scores = beam_scores.new([x[0] for x in next_batch_beam])
beam_tokens = input_ids.new([x[1] for x in next_batch_beam])
beam_idx = input_ids.new([x[2] for x in next_batch_beam])
# 準備下一時刻的解碼器輸入
# 取出實際被擴展的beam
input_ids = input_ids[beam_idx, :]
# 在這些beam后面接上新生成的token
input_ids = torch.cat([input_ids, beam_tokens.unsqueeze(1)], dim=-1)
# 更新當前長度
cur_len = cur_len + 1
# end of length while
準備輸出
上面那個while回圈跳出意味著已經生成了長度為max_length的文本,比較理想的情況是所有的句子都已經生成出了eos_token_id,即句子生成結束了,但并不是所有情況都這樣,對于那些”意猶未盡“的樣本,我們需要先手動結束,
# 將未結束的生成結果結束,并置入容器中
for batch_idx in range(batch_size):
# 已經結束的樣本不需處理
if done[batch_idx]:
continue
# 把結果加入到generated_hyps容器
for beam_id in range(num_beams):
effective_beam_id = batch_idx * num_beams + beam_id
final_score = beam_scores[effective_beam_id].item()
final_tokens = input_ids[effective_beam_id]
generated_hyps[batch_idx].add(final_tokens,final_score)
經過上面的處理,所有生成好的句子都已經保存在generated_hyps容器中,每個容器內保存著num_beams個序列,最后就是輸出期望個數的句子,
# select the best hypotheses,最終輸出
# 每個樣本回傳幾個句子
output_num_return_sequences_per_batch = 1
# 記錄每個回傳句子的長度,用于后面pad
sent_lengths = input_ids.new(output_batch_size)
best = []
# 對每個樣本取出最好的output_num_return_sequences_per_batch個句子
for i, hypotheses in enumerate(generated_hyps):
sorted_hyps = sorted(hypotheses.beams, key=lambda x: x[0])
for j in range(output_num_return_sequences_per_batch):
effective_batch_idx = output_num_return_sequences_per_batch * i + j
best_hyp = sorted_hyps.pop()[1]
sent_lengths[effective_batch_idx] = len(best_hyp)
best.append(best_hyp)
# 如果長短不一則pad句子,使得最后回傳結果的長度一樣
if sent_lengths.min().item() != sent_lengths.max().item():
sent_max_len = min(sent_lengths.max().item() + 1, max_length)
# 先把輸出矩陣填滿PAD token
decoded = input_ids.new(output_batch_size, sent_max_len).fill_(pad_token_id)
# 填入真正的內容
for i, hypo in enumerate(best):
decoded[i, : sent_lengths[i]] = hypo
# 填上eos token
if sent_lengths[i] < max_length:
decoded[i, sent_lengths[i]] = eos_token_id
else:
# 所有生成序列都還沒結束,直接堆疊即可
decoded = torch.stack(best).type(torch.long).to(next(self.parameters()).device)
# 回傳的結果包含BOS token
return decoded
總結
好了,上面就是最基礎的beam search演算法,這樣生成出來的結果已經會比貪心搜索好一些,但還是會遇到諸如詞語重復這樣的問題,其實已經有很多針對重復問題的研究,還有下篇,
Beam Search快速理解及代碼決議(下)
Beam Search的問題
先解釋一下什么要對Beam Search進行改進,因為Beam Search雖然比貪心強了不少,但還是會生成出空洞、重復、前后矛盾的文本,如果你有文本生成經驗,一定對這些現象并不陌生,在語言模型還不像如今的BERT、GPT這么厲害的時候,這種現象更加明顯,
沒有經驗也沒關系,我們來看一個論文里面的例子,輸入模型的引文(context)
"The study, published in the Proceedings of the They were cattle called Bolivian Cavalleros; they live in a National Academy of Sciences of the United States of remote desert uninterrupted by town, and they speak huge, America (PNAS), was conducted by researchers from the beautiful, paradisiacal Bolivian linguistic thing. They say, Universidad Nacional Autónoma de México (UNAM) and
GPT-2模型, Beam Search, num_beams=32的生成結果:
'Lunch, marge.' They don't tell what the lunch is," director the Universidad Nacional Autónoma de México Professor Chuperas Omwell told Sky News. "They've only (UNAM/Universidad Nacional Autónoma de been talking to scientists, like we're being interviewed by TV México/Universidad Nacional Autónoma de reporters. We don't even stick around to be interviewed by México/Universidad Nacional Autónoma de TV reporters. Maybe that's how they figured out that they're México/Universidad Nacional Autónoma de ...”
可以發現即使是如今最頂級的語言模型加上足夠長的引文輸入,還是無法得到高質量的生成結果,
論文認為這種問題是由于這種試圖最大化序列條件概率的解碼策略從根上就有問題,他們對比了給定同樣引文的情況下人類續寫和機器生成的詞用語言模型計算出來的概率,如下圖所示,人類選擇的詞(橙線)并不是像機器選擇的(藍線)那樣總是那些條件概率最大的詞,從生成的結果也可以看出,機器生成的結果有大量重復,
機器選詞和人類選詞的概率對比圖
解決對策
人們其實嘗試了各種辦法對Beam Search進行改進,其實都很好理解,這篇論文總結的也比較到位,
隨機采樣
第一種方法是用隨機采樣(sampling)代替取概率最大的詞,采樣的依據就是解碼器輸出的詞典中每個詞的概率分布,相比于按概率“掐尖”,這樣會增大所選詞的范圍,引入更多的隨機性,當時那篇論文的結論就是這種隨機采樣的方法遠好于Beam Search,但這其實也是有條件的,隨機采樣容易產生前后不一致的問題,而在開放閑聊領域,生成文本的長度都比較短,這種問題就被自然的淡化了,
采樣的時候有一個可以控制的超引數,稱為溫度(temperature, ),解碼器的輸出層后面通常會跟一個softmax函式來將輸出概率歸一化,通過改變 可以控制概率分布的形貌,softmax的公式如下,當 大的時候,概率分布趨向平均,隨機性增大;當 小的時候,概率密度趨向于集中,即強者愈強,隨機性降低,會更多地采樣出“放之四海而皆準”的詞匯,
top-k采樣
這個方法就是在采樣前將輸出的概率分布截斷,取出概率最大的k個詞構成一個集合,然后將這個子集詞的概率再歸一化,最后從新的概率分布中采樣詞匯,這個辦法據說可以獲得比Beam Search好很多的效果,但也有一個問題,就是這個k不太好選,
While top-k sampling leads to considerably higher quality text than either beam search or sampling from the full distribution, the use of a constant k is sub-optimal across varying contexts.
為啥呢?因為這個概率分布變化比較大,有時候可能很均勻(flat),有的時候比較集中(peaked),對于集中的情況還好說,當分布均勻時,一個較小的k容易丟掉很多優質候選詞,但如果k定的太大,這個方法又會退化回普通采樣,
兩種分布,左邊是均勻的,右邊是集中的
核采樣(Nucleus sampling)
首先表示我不確定這個翻譯是不是對的,
這是這篇論文提出的方式,也是相比前面那些都更好的采樣方式,這個方法不再取一個固定的k,而是固定候選集合的概率密度和在整個概率分布中的比例,也就是構造一個最小候選集V ,使得
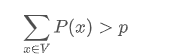
選出來這個集合之后也和top-k采樣一樣,重新歸一化集合內詞的概率,并把集合外詞的概率設為0,這種方式也稱為top-p采樣,
論文有一個圖,對比了這幾種采樣方式的效果,
效果對比圖,紅字是前后不符,藍字是重復,Nucleus效果拔群,
懲罰重復
為了解決重復問題,還可以通過懲罰因子將出現過詞的概率變小或者強制不使用重復詞來解決,懲罰因子來自于同樣廣為流傳的《CTRL: A Conditional Transformer Language Model for Controllable Generation》[2],如果大家感興趣的話后面可以專門寫一期可控文本生成方向的解讀,
代碼決議
其實上述各種采樣方式在HuggingFace的庫里都已經實作了(感動!),我們來看一下代碼,
先看top-k和top-p采樣
1 # 代碼輸入的是logits,而且考慮很周全(我感覺漏了考慮k和p都給了的情況,這應該是不合適的)
2 # 巧妙地使用了torch.cumsum
3 # 避免了一個詞都選不出來的尷尬情況
4 def top_k_top_p_filtering(logits, top_k=0, top_p=1.0, filter_value=https://www.cnblogs.com/nickchen121/p/-float("Inf"), min_tokens_to_keep=1):
5 """ Filter a distribution of logits using top-k and/or nucleus (top-p) filtering
6 Args:
7 logits: logits distribution shape (batch size, vocabulary size)
8 if top_k > 0: keep only top k tokens with highest probability (top-k filtering).
9 if top_p < 1.0: keep the top tokens with cumulative probability >= top_p (nucleus filtering).
10 Nucleus filtering is described in Holtzman et al. (http://arxiv.org/abs/1904.09751)
11 Make sure we keep at least min_tokens_to_keep per batch example in the output
12 From: https://gist.github.com/thomwolf/1a5a29f6962089e871b94cbd09daf317
13 """
14 if top_k > 0:
15 top_k = min(max(top_k, min_tokens_to_keep), logits.size(-1)) # Safety check
16 # Remove all tokens with a probability less than the last token of the top-k
17 indices_to_remove = logits < torch.topk(logits, top_k)[0][..., -1, None]
18 logits[indices_to_remove] = filter_value
19
20 if top_p < 1.0:
21 sorted_logits, sorted_indices = torch.sort(logits, descending=True)
22 cumulative_probs = torch.cumsum(F.softmax(sorted_logits, dim=-1), dim=-1)
23
24 # Remove tokens with cumulative probability above the threshold (token with 0 are kept)
25 sorted_indices_to_remove = cumulative_probs > top_p
26 if min_tokens_to_keep > 1:
27 # Keep at least min_tokens_to_keep (set to min_tokens_to_keep-1 because we add the first one below)
28 sorted_indices_to_remove[..., :min_tokens_to_keep] = 0
29 # Shift the indices to the right to keep also the first token above the threshold
30 sorted_indices_to_remove[..., 1:] = sorted_indices_to_remove[..., :-1].clone()
31 sorted_indices_to_remove[..., 0] = 0
32
33 # scatter sorted tensors to original indexing
34 indices_to_remove = sorted_indices_to_remove.scatter(1, sorted_indices, sorted_indices_to_remove)
35 logits[indices_to_remove] = filter_value
36 return logits
再看看重復懲罰
1 # 輸入的同樣是logits(lprobs)
2 # 同時輸入了之前出現過的詞以及懲罰系數(大于1的)
3 # 考慮到了logit是正和負時處理方式應該不一樣
4 def enforce_repetition_penalty_(self, lprobs, batch_size, num_beams, prev_output_tokens, repetition_penalty):
5 """repetition penalty (from CTRL paper https://arxiv.org/abs/1909.05858). """
6 for i in range(batch_size * num_beams):
7 for previous_token in set(prev_output_tokens[i].tolist()):
8 # if score < 0 then repetition penalty has to multiplied to reduce the previous token probability
9 if lprobs[i, previous_token] < 0:
10 lprobs[i, previous_token] *= repetition_penalty
11 else:
12 lprobs[i, previous_token] /= repetition_penalty
最后是重復詞去除
1 # 這個函式將會回傳一個不可使用的詞表
2 # 生成n-gram的巧妙方式大家可以借鑒一下
3 # 下面是一個3-gram的例子
4 # a = [1,2,3,4,5]
5 # for ngram in zip(*[a[i:] for i in range(3)]):
6 # print(ngram)
7 def calc_banned_tokens(prev_input_ids, num_hypos, no_repeat_ngram_size, cur_len):
8 # Copied from fairseq for no_repeat_ngram in beam_search"""
9 if cur_len + 1 < no_repeat_ngram_size:
10 # return no banned tokens if we haven't generated no_repeat_ngram_size tokens yet
11 return [[] for _ in range(num_hypos)]
12 generated_ngrams = [{} for _ in range(num_hypos)]
13 for idx in range(num_hypos):
14 gen_tokens = prev_input_ids[idx].numpy().tolist()
15 generated_ngram = generated_ngrams[idx]
16 # 就是這巧妙的一句
17 for ngram in zip(*[gen_tokens[i:] for i in range(no_repeat_ngram_size)]):
18 prev_ngram_tuple = tuple(ngram[:-1])
19 generated_ngram[prev_ngram_tuple] = generated_ngram.get(prev_ngram_tuple, []) + [ngram[-1]]
20 def _get_generated_ngrams(hypo_idx):
21 # Before decoding the next token, prevent decoding of ngrams that have already appeared
22 start_idx = cur_len + 1 - no_repeat_ngram_size
23 ngram_idx = tuple(prev_input_ids[hypo_idx, start_idx:cur_len].numpy().tolist())
24 return generated_ngrams[hypo_idx].get(ngram_idx, [])
25 banned_tokens = [_get_generated_ngrams(hypo_idx) for hypo_idx in range(num_hypos)]
26 return banned_tokens
以上這些代碼應該在哪里呼叫相信看上一篇文章的朋友都應該知道了,這里就放出來最核心的差異,
1 if do_sample:
2 # 這是今天的采樣方式
3 _scores = scores + beam_scores[:, None].expand_as(scores) # (batch_size * num_beams, vocab_size)
4 # Top-p/top-k filtering,這一步重建了候選集
5 _scores = top_k_top_p_filtering(
6 _scores, top_k=top_k, top_p=top_p, min_tokens_to_keep=2
7 ) # (batch_size * num_beams, vocab_size)
8 # re-organize to group the beam together to sample from all beam_idxs
9 _scores = _scores.contiguous().view(
10 batch_size, num_beams * vocab_size
11 ) # (batch_size, num_beams * vocab_size)
12
13 # Sample 2 next tokens for each beam (so we have some spare tokens and match output of greedy beam search)
14 probs = F.softmax(_scores, dim=-1)
15 # 采樣
16 next_tokens = torch.multinomial(probs, num_samples=2 * num_beams) # (batch_size, num_beams * 2)
17 # Compute next scores
18 next_scores = torch.gather(_scores, -1, next_tokens) # (batch_size, num_beams * 2)
19 # sort the sampled vector to make sure that the first num_beams samples are the best
20 next_scores, next_scores_indices = torch.sort(next_scores, descending=True, dim=1)
21 next_tokens = torch.gather(next_tokens, -1, next_scores_indices) # (batch_size, num_beams * 2)
22 else:
23 # 這是昨天的beam search方式
24 # 直接將log概率相加求條件概率
25 next_scores = scores + beam_scores[:, None].expand_as(scores) # (batch_size * num_beams, vocab_size)
26
27 # re-organize to group the beam together (we are keeping top hypothesis accross beams)
28 next_scores = next_scores.view(
29 batch_size, num_beams * vocab_size
30 ) # (batch_size, num_beams * vocab_size)
31
32 next_scores, next_tokens = torch.topk(next_scores, 2 * num_beams, dim=1, largest=True, sorted=True)
OK,謝謝各位看到這里,祝大家生成出高質量的文本!
參考資料
[1] The Curious Case of Neural Text Degeneration: https://arxiv.org/abs/1904.09751
[2] CTRL: A Conditional Transformer Language Model for Controllable Generation: https://arxiv.org/abs/1909.05858
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/345525.html
標籤:其他
上一篇:百億級小檔案存盤,JuiceFS 在自動駕駛行業的最佳實踐
下一篇:獵頭小姐姐眼中的“渣男”候選人