目錄
1 什么是分類問題?
2 為什么要使用邏輯斯蒂回歸?
3 Sigmid Founction(邏輯斯蒂回歸函式)
3.1 模型的改變
3.2 損失函式的改變(BCE Loss)
3.3 代碼的改變
1 什么是分類問題?
分類問題,與之前學習的線性回歸問題不同,輸出的是分類的概率值,在訓練程序中,計算它屬于每一個分類的所有概率,其中概率最大的那一種分類,就是我們要的輸出結果,
(在PyTorch中 torchvison包 提供一些主流的資料集,root:下載路徑,train:是選擇訓練集還是測驗集,download:是否需要下載,第一次使用需要下載),
現在我們將之前的學習問題,修改成分類問題,x表示學習時間,y表示通過率,0表示不通過,1表示通過,這也叫做”二分類問題“

2 為什么要使用邏輯斯蒂回歸?
在之前我們的學習中, 最終預測的是一個實數,而針對分類問題,我們要把
輸出的實數映射成一個0到1的概率(
[0,1] ),這個映射的程序就是本節課所學的邏輯斯蒂回歸,邏輯斯蒂回歸利用公式
,將實數域的數值映射到 [0.1]范圍內的概率,邏輯斯蒂函式的影像如下所示:
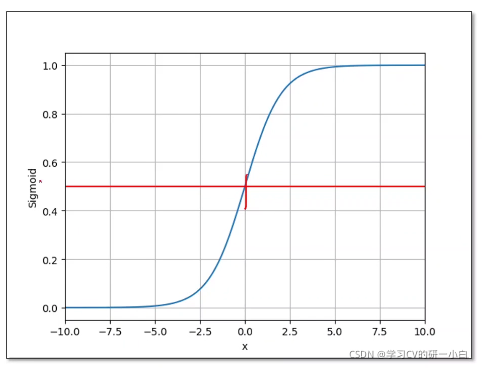
邏輯斯蒂函式在數學界被分為——飽和函式,
計算概率的方式:將原本計算的實數作為變數輸入到邏輯斯蒂函式中,輸出的就是映射之后的概率值,
3 Sigmid Founction(邏輯斯蒂回歸函式)
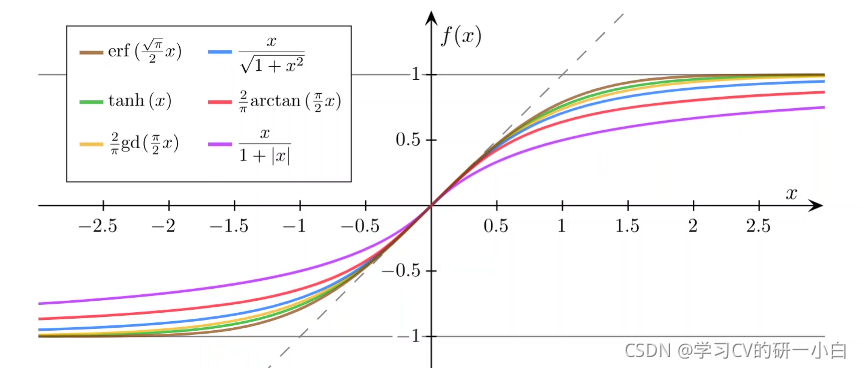
Sigmid Founction需要滿一下三個條件:
- 函式值有極限
- 是單調增函式
- 是飽和函式
Sigmid Founction中最具有典型性的函式就是邏輯斯蒂函式,其他的一些Sigmid Founction如下圖所示:
3.1 模型的改變
之前學習的函式與邏輯斯蒂回歸函式的計算圖的區別:可以看出邏輯斯蒂回歸函式在計算出之后,還多了一步——通過使用邏輯斯蒂回歸函式,把實數值映射到【0,1】的區間中,再輸出
,
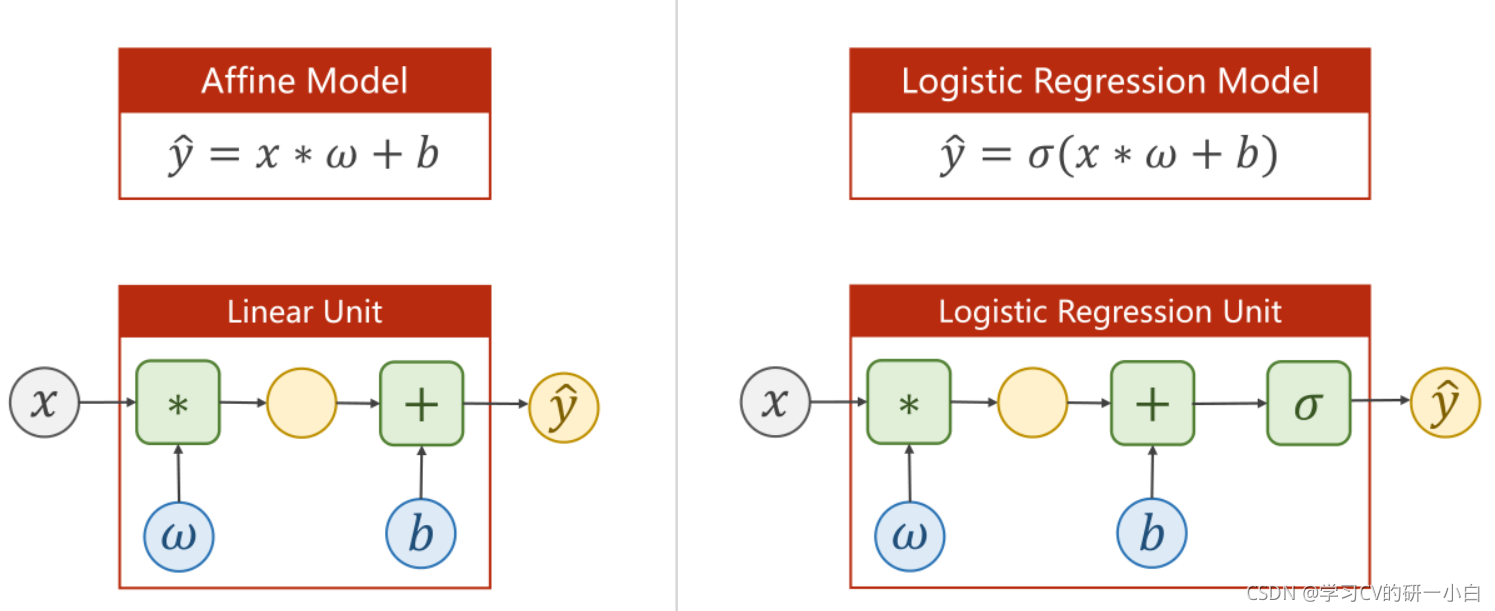
注:( 一般就代表邏輯斯蒂回歸)
3.2 損失函式的改變(BCE Loss)
之前學習的函式的損失:計算兩個實數值的差值,數軸上的距離
邏輯斯蒂回歸函式的損失:輸出的是一個分布,需要計算的是兩類分布之間的差異,在統計學中的計算方法有——KL散度,cross-entropy(交叉熵)等,這里我們使用的是cross-entropy(交叉熵)方法,
交叉熵:例如:現有兩個分布 和
,此時交叉熵公式為:
,
這個公式的值表示兩個分布之間的差異的大小,值越大,差異越小,在本例中,在公式前加了負號,目的是為了符合我們的平時思維,使Loss越小,差異越小,
具體解釋:在本例中,是二分類問題, 的取值只能是0或1,
的取值只能
,Loss函式如下:

- 當
時,
,此時
,因為
函式是單調遞增函式,此時
越大,也就是越接近1,
的值越小,差異越小;
- 當
時,
,此時
,因為
(有點繞,可以自己多推幾次)
最終我們計算的總和公式如下:
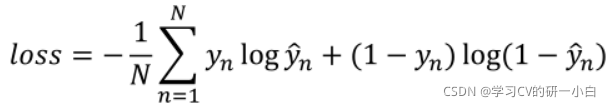
補充: 關于交叉熵的詳細解釋見鏈接:
一文搞懂交叉熵在機器學習中的使用,透徹理解交叉熵背后的直覺_史丹利復合田的博客-CSDN博客
3.3 代碼的改變
- def __init__沒有改變:原因是,
(邏輯斯蒂回歸函式)是一個沒有引數的函式,不需要在建構式中進行初始化,直接呼叫就可以;
- 資料集的改變:因為是二分類問題,
的取值只能是0或1;

- 模型的改變:由于PyTorch版本更新,不用再匯入torch.nn.functional包,可以直接使用包中的Sigmoid函式進行訓練,如下圖;
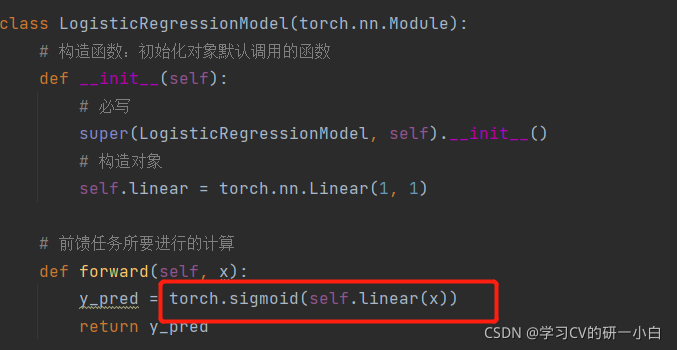
- 損失函式的改變:不再使用MSE損失函式,改為使用BCE損失函式,由于PyTorch版本更新,將 size_average=False 更改為 reduction='sum'

完整代碼如下:
import matplotlib.pyplot as plt
import torch
import matplotlib.pyplot as pl
import numpy as np
x_data = torch.Tensor([[1.0], [2.0], [3.0]])
y_data = torch.Tensor([[0], [0], [1]])
class LogisticRegressionModel(torch.nn.Module):
# 建構式:初始化物件默認呼叫的函式
def __init__(self):
# 必寫
super(LogisticRegressionModel, self).__init__()
# 構造物件
self.linear = torch.nn.Linear(1, 1)
# 前饋任務所要進行的計算
def forward(self, x):
y_pred = torch.sigmoid(self.linear(x))
return y_pred
# 實體化
model = LogisticRegressionModel()
# 損失函式物件
criterion = torch.nn.BCELoss(reduction='sum')
# 優化器物件
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# 進行訓練
for epoch in range(1000):
# 計算y hat
y_pred = model(x_data)
# 計算損失
loss = criterion(y_pred, y_data)
print(epoch, loss.item())
# 所有權重每次都梯度清零
optimizer.zero_grad()
# 反向傳播求梯度
loss.backward()
# 更新,step()更新函式
optimizer.step()
# 畫圖
x = np.linspace(0, 10, 200)
x_t = torch.Tensor(x).view((200, 1))
y_t = model(x_t)
y = y_t.data.numpy()
plt.plot(x, y)
plt.plot([0, 10], [0.5, 0.5], c='r')
plt.xlabel('Hours')
plt.ylabel('Probability of Pass')
plt.grid
plt.show()
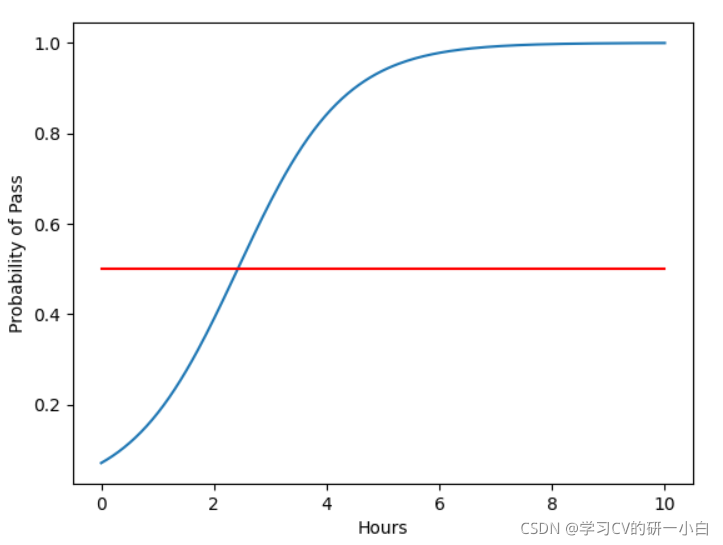
運行截圖如下:
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/345623.html
標籤:AI
上一篇:基于深度學習的云反演-文獻分析