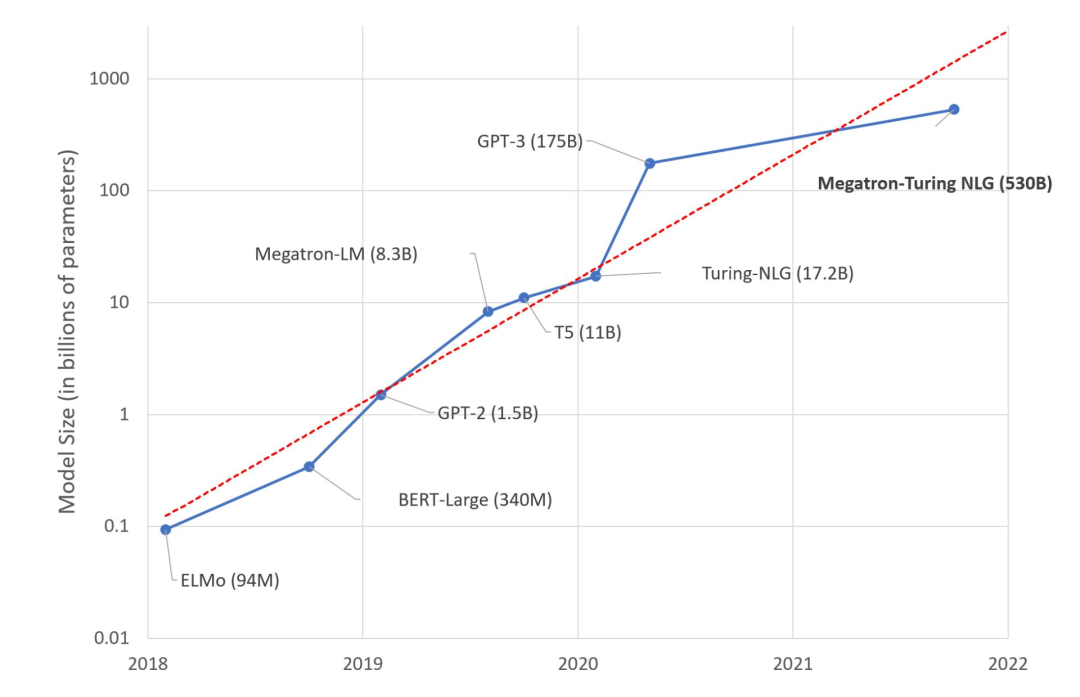
前不久,微軟和英偉達推出包含5300億引數的語言模型MT-NLG,這是一款基于 Transformer 的模型被譽為“世界上最大、最強的生成語言模型”,
毫無疑問,這是一場令人印象深刻的機器學習工程展示,
然而,我們是否應該對這種大型模型趨勢感到興奮?
大腦深度學習
研究人員估計,人腦平均包含 860 億個神經元和 100 萬億個突觸,可以肯定的是,并非所有這些都用于語言,有趣的是,GPT-4 預計有大約 100 萬億個引數……
盡管這個對比很粗糙,但是難道不應該懷疑構建與人腦大小差不多的語言模型是否是一個長期可行的方法?
當然,我們的大腦是經過數百萬年進化產生的奇妙裝置,而深度學習模型才有幾十年的歷史,盡管如此,直覺應該告訴我們,有些東西是無法計算的,
深度學習、還是深度錢包?
在龐大的文本資料集上訓練一個 5300 億引數的模型,毫無疑問的是需要龐大的基礎設施,
事實上,微軟和英偉達使用了數百臺 DGX-A100 的 GPU 服務器,每件售價高達 199,000 美元,再加上網路設備、主機等成本,任何想要復制這個實驗的人都必須花費近 1 億美元,
哪些公司有業務例子可以證明在深度學習基礎設施上花費 1 億美元是合理的?或者甚至是1000萬美元?很少,
那么這些模型到底是為誰準備的呢?
GPU 集群
盡管其工程才華橫溢,但在 GPU 上訓練深度學習模型是一種費力的事情,
根據服務器引數表顯示,每臺 DGX 服務器可以消耗高達 6.5 千瓦的電量,當然,資料中心(或服務器)至少需要同樣多的散熱能力,
除非你是史塔克家族的人,需要拯救臨冬城,否則散熱是必須處理的另一個問題,
此外,隨著公眾對氣候和社會責任問題的認識不斷提高,公司還需要考慮到他們的碳足跡,馬薩諸塞大學 2019 年的一項研究,“在 GPU 上訓練 BERT 大致相當于一次跨美飛行”,
而 BERT-Large 擁有 3.4 億個引數,訓練起來的碳足跡究竟有多大?想想都害怕,
構建和推廣這些龐大的模型是否有助于公司和個人理解和使用機器學習呢?
相反,如果把重點放在可操作性更高的技術上,就可以用來構建高質量的機器學習解決方案,
使用預訓練模型
在絕大多數情況下,并不需要自定義模型體系結構,
一個好的起點是尋找已針對您要解決的任務(例如,總結英文文本)進行預訓練的模型,
然后,快速嘗試一些模型來預測自己的資料,如果引數標明某個引數良好,那么就完成了!如果需要更高的準確性,應該考慮對模型進行微調,
使用較小的模型
在評估模型時,應該選擇能夠提供所需精度的最小模型,它將更快地預測并需要更少的硬體資源來進行訓練和推理,
這也不是什么新鮮事,熟悉計算機視覺的人會記得 SqueezeNet 于 2017 年問世時,與 AlexNet 相比,模型大小減少了 50 倍,同時達到或超過了其準確性,
自然語言處理社區也在努力縮小規模,使用知識蒸餾等遷移學習技術,DistilBERT 可能是其最廣為人知的成就,
與原始 BERT 模型相比,它保留了 97% 的語言理解能力,同時模型體積縮小了 40%,速度提高了 60%,相同的方法已應用于其他模型,例如 Facebook 的 BART,
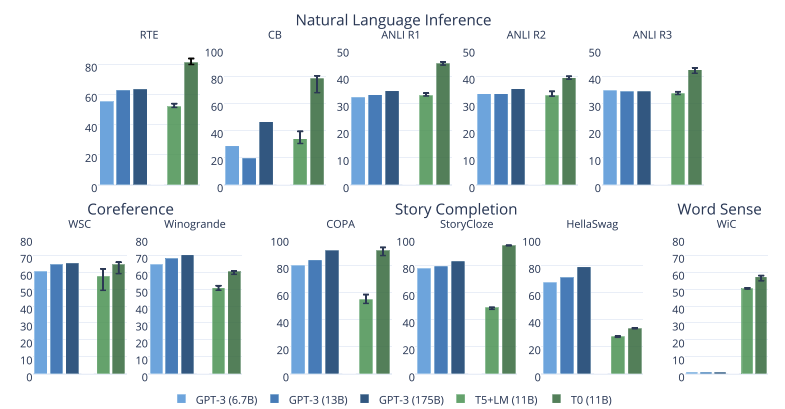
Big Science 專案的最新模型也令人印象深刻,如下圖所示,他們的 T0 模型在許多任務上都優于 GPT-3,同時模型大小縮小了 16 倍,
微調模型
如果需要專門化一個模型,不需要從頭開始訓練模型,相反,應該對其進行微調,也就是說,僅在自己的資料上訓練幾個時期,
使用遷移學習的好處,比如:
-
需要收集、存盤、清理和注釋的資料更少
-
實驗和資料迭代的速度更快
-
獲得產出所需的資源更少
換句話說:省時、省錢、省硬體資源、拯救世界!
使用基于云的基礎設施
不管喜歡與否,云計算公司都知道如何構建高效的基礎設施,研究表明,基于云的基礎設施比替代方案更具能源和碳效率,Earth.org 表示,雖然云基礎設施并不完美,但仍然比替代方案更節能,并促進對環境有益的服務和經濟增長,”
在易用性、靈活性和即用即付方面,云當然有很多優勢,
優化模型
從編譯器到虛擬機,軟體工程師長期以來一直使用工具來自動優化硬體代碼,
然而,機器學習社區仍在為這個話題苦苦掙扎,這是有充分理由的,優化模型的大小和速度是一項極其復雜的任務,其中涉及以下技術:
-
硬體:大量面向加速訓練任務(Graphcore、Habana)和推理任務(Google TPU、AWS Inferentia)的專用硬體,
-
剪枝:洗掉對預測結果影響很小或沒有影響的模型引數,
-
融合:合并模型層(比如卷積和激活),
-
量化:以較小的值存盤模型引數(比如使用8位存盤,而不是32位存盤)
幸運的是,自動化工具已經開始出現,例如 Optimum 開源庫和 Infinity,這是一種容器化解決方案,可以以 1 毫秒的延遲提供 Transformers 的準確性,
結論
在過去的幾年里,大型語言模型的規模每年都以 10 倍的速度增長,這看起來像另一個摩爾定律,
如果機器學習沿著模型巨大化這條路走下去,會導致收益遞減、成本增加、復雜度增加等,
這是所期待的人工智能未來的樣子嗎?
與其追逐萬億引數模型,不如把更多經歷放在構建解決現實世界問題的實用且高效的解決方案,豈不是更好?
參考鏈接:
https://huggingface.co/blog/large-language-models#deep-learning-deep-pockets
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/345624.html
標籤:AI