TensorFlow Slim是Google提供的影像分類工具包,不僅提供一些方便介面,包含使用tf_slim訓練和評估幾個廣泛使用于影像識別的卷積神經網路 (CNN) 影像分類模型的代碼 ,還包含允許您從頭開始訓練模型或根據預先訓練的網路權重對其進行微調的腳本,是一個簡潔、方便的影像分類模型庫,
環境:python3.7 TensorFlow-1.15.0rc0 TensorFlow Models-v1.13.0
目錄
一、安裝配置TensorFlow Slim
1、下載TensorFlow源代碼和TensorFlow_Models源代碼檔案
2、配置環境
二、slim檔案夾解讀
三、使用TensorFlow Slim微調模型
1.微調模型的原理
2、準備資料集
3、資料集轉化成tfrecord格式
4、下載預訓練模型
5、訓練模型
6、驗證模型準確率
7、匯出模型
8、使用匯出來的模型進行識別影像
一、安裝配置TensorFlow Slim
1、下載TensorFlow源代碼和TensorFlow_Models源代碼檔案
tensorflow/tensorflow: An Open Source Machine Learning Framework for Everyone (github.com)
tensorflow/models: Models and examples built with TensorFlow (github.com)
這里不建議安裝TensorFlow2.x版本
TensorFlow2.x版本沒有contrib庫,也就無法使用tf_slim庫
2、配置環境
Slim源代碼在models\research\slim檔案夾中
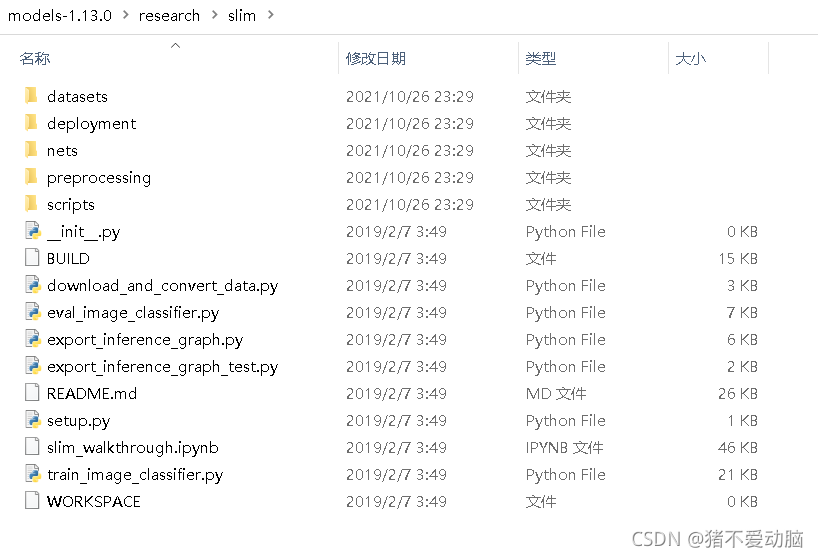 ?
?
在該目錄下打開cmd,輸入
python setup.py build
python setup.py install
![]() ?
?
 ?
?
沒有報錯,就是配置成功了
二、slim檔案夾解讀
datasets:定義了一些訓練時使用的資料集,并預設了一些常用資料集,定義自己資料集時,也必須在datasets檔案夾中進行定義
net:定義了一些常用的影像識別網路結構
preprocessing:針對不同網路結構,定義了對影像進行預處理方法
scripts:包含了一些訓練的案例腳本
deployment:部署,通過創建clone方式實作跨機器的分布訓練,可以在多CPU和多GPU上實作運算的同步或者異步,
train_image_classifier.py:訓練模型的入口代碼
eval_image_classifier.py:驗證模型性能的入口代碼
download_and_convert_data.py:下載并傳換資料集格式的入口代碼
export_inference_graph.py:匯出網路結構的入口代碼
setup.py:slim運行所需環境配置的入口代碼
slim_walkthrough.ipynb:tf_slim演示代碼,可在jupyter-notebook上打開
README.md:slim使用說明檔案
BUILD:用于建立包含用于加載、訓練和評估基于TF Slim的模型的檔案
WORKSPACE:用于建立運行slim的依賴項
使用之前建議先看下README.md和slim_walkthrough.ipynb檔案
三、使用TensorFlow Slim微調模型
1.微調模型的原理
屬于遷移學習的一種技術,采用預訓練模型應用到自己的資料集上,無需再修改其網路結構,對模型輸出層進行修改,并隨機初始化該層的模型引數,
2、準備資料集
這里采用Garbage Classification (12 classes) | Kaggle
這個垃圾分類資料集提供了12個類別
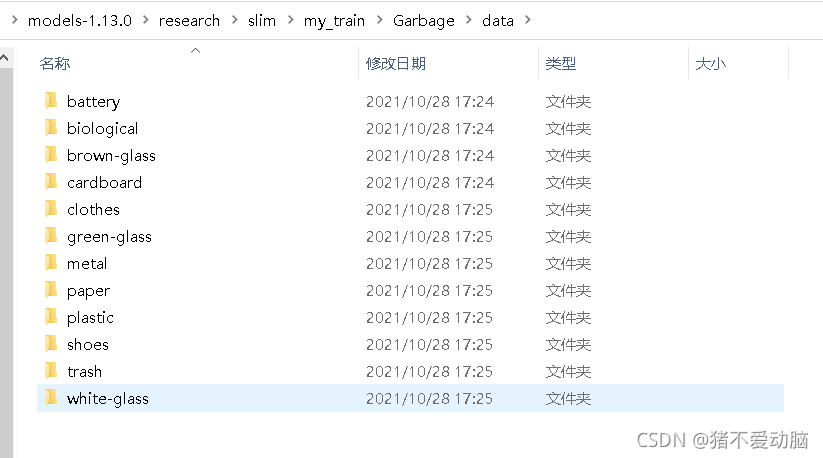
建立自己的訓練檔案夾,放入下載好的資料集,這里在slim目錄下,建立my_train/Garbage/data:
3、資料集轉化成tfrecord格式
進入到slim/datasets檔案夾下
新建garbage.py,將flower.py內容復制進去,修改以下部分
_FILE_PATTERN = 'flowers_%s_*.tfrecord' #flowers改為garbage
SPLITS_TO_SIZES = {'train': 3320, 'validation': 350}
_NUM_CLASSES = 5 #5改為12打開dataset_factory.py,修改以下部分
新建download_and_convert_garbage.py 將download_and_convert_flowers.py內容復制過去,修改以下部分
# The number of images in the validation set.
_NUM_VALIDATION = 350 #分割驗證集資料量,這里我改為3100
def _get_filenames_and_classes(dataset_dir):
"""Returns a list of filenames and inferred class names.
Args:
dataset_dir: A directory containing a set of subdirectories representing
class names. Each subdirectory should contain PNG or JPG encoded images.
Returns:
A list of image file paths, relative to `dataset_dir` and the list of
subdirectories, representing class names.
"""
flower_root = os.path.join(dataset_dir, 'flower_photos') #這里因為我的資料集照片在data目錄下,所以這里的flower_photos改為data
directories = []
class_names = []
for filename in os.listdir(flower_root):
path = os.path.join(flower_root, filename)
if os.path.isdir(path):
directories.append(path)
class_names.append(filename)
def _get_dataset_filename(dataset_dir, split_name, shard_id):
output_filename = 'flowers_%s_%05d-of-%05d.tfrecord' % (
split_name, shard_id, _NUM_SHARDS) #這里的flowers改為garbage
return os.path.join(dataset_dir, output_filename)
dataset_utils.download_and_uncompress_tarball(_DATA_URL, dataset_dir) #不用下載,這一行注釋掉,
_clean_up_temporary_files(dataset_dir) #注釋掉這一行,否則會清理掉資料集最后在slim目錄下打開download_and_convert_data.py
#在前面加入
from datasets import download_and_convert_garbage
elif FLAGS.dataset_name == 'cifar10':
download_and_convert_cifar10.run(FLAGS.dataset_dir)
elif FLAGS.dataset_name == 'mnist':
download_and_convert_mnist.run(FLAGS.dataset_dir)
#加入以下兩行
elif FLAGS.dataset_name == 'garbage':
download_and_convert_garbage.run(FLAGS.dataset_dir)
在slim目錄下打開cmd ,輸入python download_and_convert_data.py --dataset_name=garbage --dataset_dir=C:\Users\User\Desktop\models-1.13.0\research\slim\my_train\Garbage\
具體引數可以進入download_and_convert_data.py查看
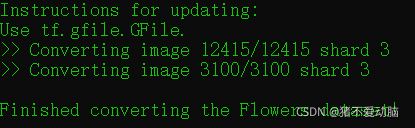 12415是我的訓練集,3100是驗證集
12415是我的訓練集,3100是驗證集
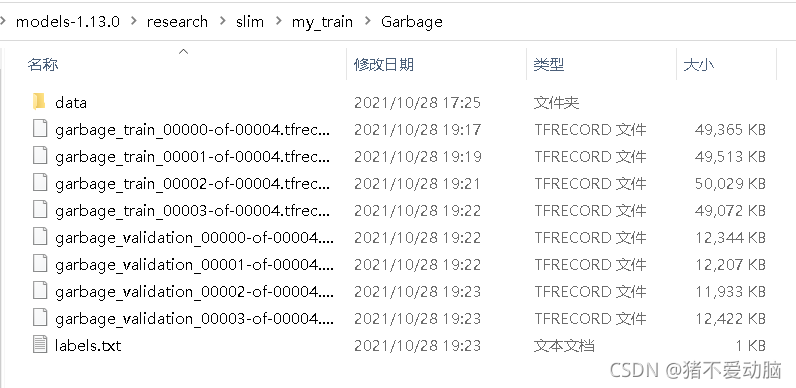
在Garbage目錄下可以看到生成的tfrecord格式檔案和labels.txt,可以進入labels.txt看看有沒有正確生成
4、下載預訓練模型
在README.md里面可以看到
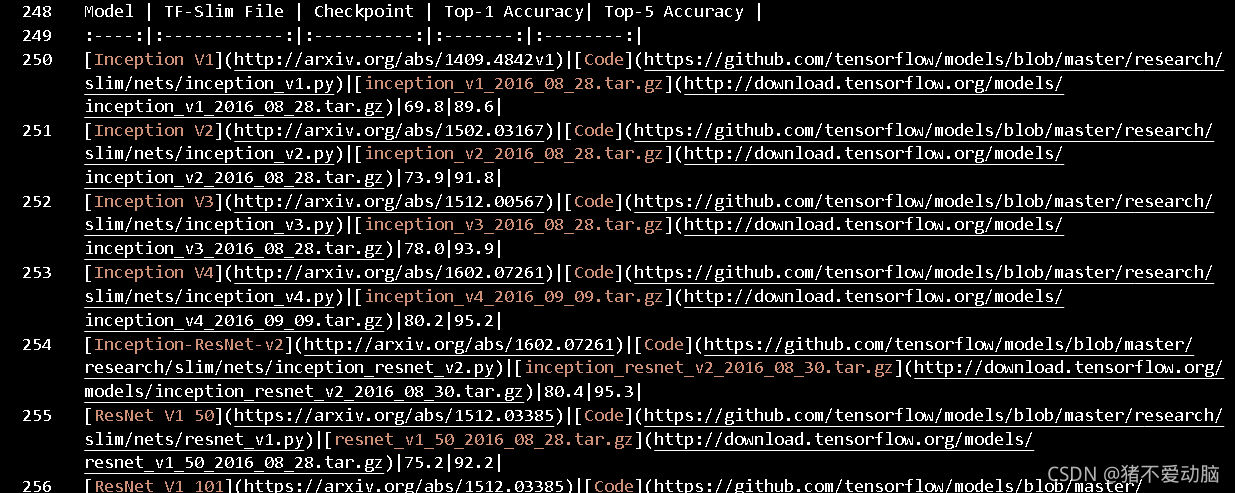
這里使用到Inception V3所以到以下地址進行下載
http://download.tensorflow.org/models/inception_v3_2016_08_28.tar.gz
訓練會用到壓縮包里的inception_v3.ckpt
5、訓練模型
在Garbage目錄下,新建檔案夾train_dir:待會兒放置訓練程序中的檔案,eval_dir:放置驗證模型的檔案,datasets:將之前生成的tfrecord格式檔案放進去
回到slim目錄下,打開cmd
輸入python train_image_classifier.py --train_dir=C:\Users\User\Desktop\models-1.13.0\research\slim\my_train\Garbage\train_dir --dataset_name=garbage --dataset_split_name=train --dataset_dir=C:\Users\User\Desktop\models-1.13.0\research\slim\my_train\Garbage\datasets --model_name=inception_v3 --checkpoint_path=C:\Users\User\Desktop\models-1.13.0\research\slim\my_train\inception_v3_2016_08_28\inception_v3.ckpt --checkpoint_exclude_scopes=InceptionV3/Logits,InceptionV3/AuxLogits --trainable_scopes=InceptionV3/Logits,InceptionV3/AuxLogits --max_number_of_steps=3000 --batch_size=32 --learning_rate=0.005 --learning_rate_decay_type=fixed --save_interval_secs=300 --save_summaries_secs=3 --log_every_n_steps=10 --optimizer=rmsprop --weight_decay=0.00004
--train_dir:保存訓練日志
--dataset_name、--dataset_split_name:指定訓練集--dataset_dir:指定訓練資料集保存位置
--model_name:使用模型名稱 --checkpoint_path:預訓練模型保存位置
--checkpoint_exclude_scopes:恢復預訓練模型時,指定不恢復的層(可以在net檔案夾中對應網路查看)
--trainable_scopes:指定模型中微調的層,不設定就是對所有層訓練
--max_number_of_steps:最大訓練次數 --batch_size:每步使用的batch數量
--learning_rate:學習率 --learning_rate_decay_type:學習率是否自動下降,此處使用固定的學習率
--save_interval_secs:設定每次間隔保存當前模型的時間
--save_summaries_secs:設定每次寫入日志的間隔時間(可以用TensorBoard打開)
--log_every_n_steps:設定間隔步數在螢屏上顯示
--optimizer:指定優化器 --weight_decay:設定模型中所有引數的二次正則化超引數
具體引數解釋進入 train_image_classifier.py中查看

如果報以上錯誤:tensorflow.python.framework.errors_impl.InvalidArgumentError:說明輸入引數有誤,這里是使用CPU訓練,這里還提示了was explicitly assigned to /device:GPU:0 but available devices are [ /job:localhost/replica:0/task:0/device:CPU:0 ]
所以進入到train_image_classifier.py查看
tf.app.flags.DEFINE_boolean('clone_on_cpu', False,
'Use CPUs to deploy clones.') #因為我是用CPU訓練,這里的False改為True再次運行,出現以下狀況,說明開始正常訓練,等就完事,
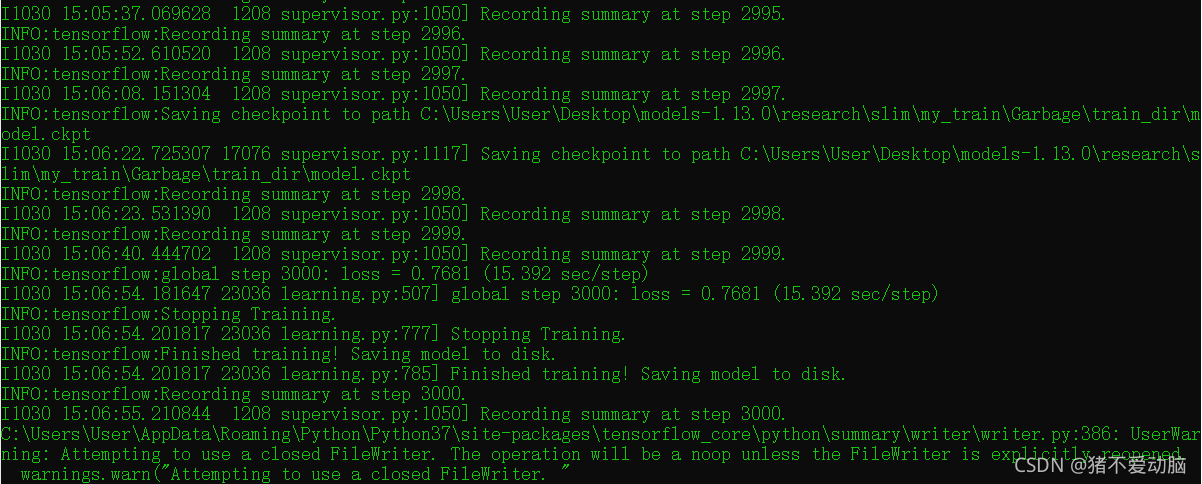
訓練結束
6、驗證模型準確率
在slim目錄下打開cmd,輸入:python eval_image_classifier.py --checkpoint_path=C:\Users\User\Desktop\models-1.13.0\research\slim\my_train\Garbage\train_dir --eval_dir=C:\Users\User\Desktop\models-1.13.0\research\slim\my_train\Garbage\eval_dir --dataset_name=garbage --dataset_split_name=validation --dataset_dir=C:\Users\User\Desktop\models-1.13.0\research\slim\my_train\Garbage\datasets --model_name=inception_v3
具體引數解釋進入 eval_image_classifier.py中查看
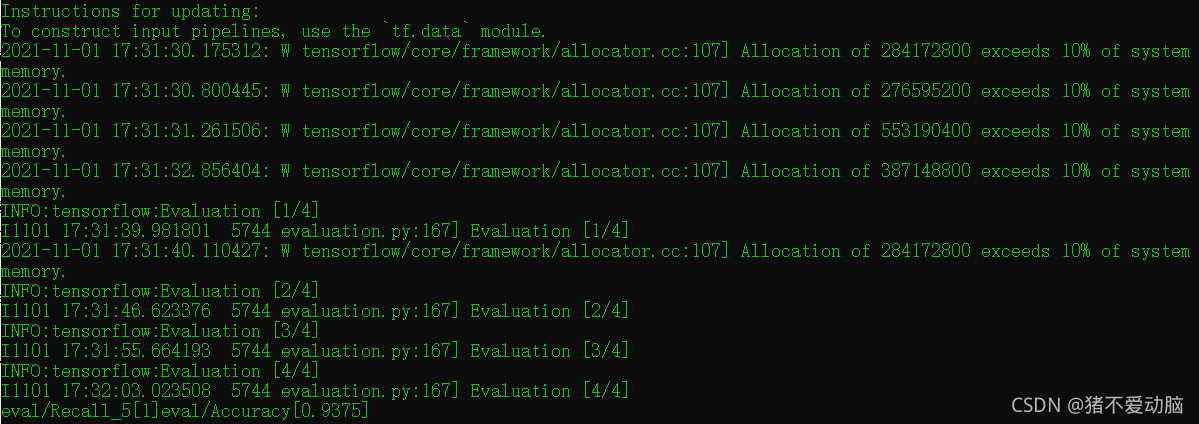
Recall_5表示Top 5的準確率,也就是分類前五個就算是對的,Accuray表示模型的分類準確率
7、匯出模型
匯出網路模型結構:
在slim目錄下打開cmd,輸入:python export_inference_graph.py --alsologtostderr --model_name=inception_v3 --output_file=C:\Users\User\Desktop\models-1.13.0\research\slim\my_train\Garbage\inception_v3_inf_graph.pb --dataset_name=garbage
運行結束后,會在slim\my_train\Garbage目錄下生成inception_v3_inf_graph.pb
保存模型引數:
這里使用到freeze_graph.py,這個檔案在下載好的TensorFlow源代碼tensorflow\python\tools目錄下,在其目錄下打開cmd,輸入:python freeze_graph.py --input_graph C:\Users\User\Desktop\models-1.13.0\research\slim\my_train\Garbage\inception_v3_inf_graph.pb --input_checkpoint C:\Users\User\Desktop\models-1.13.0\research\slim\my_train\Garbage\train_dir\model.ckpt-3000 --input_binary true --output_node_names InceptionV3/Predictions/Reshape_1 --output_graph C:\Users\User\Desktop\models-1.13.0\research\slim\my_train\Garbage\frozen_graph.pb
--input_checkpoint:指定將哪個checkpoint引數載入網路結構中,這里建議指定訓練檔案下checkpoint最大的步數
--output_graph:在匯出的模型中,指定一個輸出結點
具體引數解釋進入 freeze_graph.py中查看
運行結束后,會在slim\my_train\Garbage目錄下生成frozen_graph.pb
8、使用匯出來的模型進行識別影像
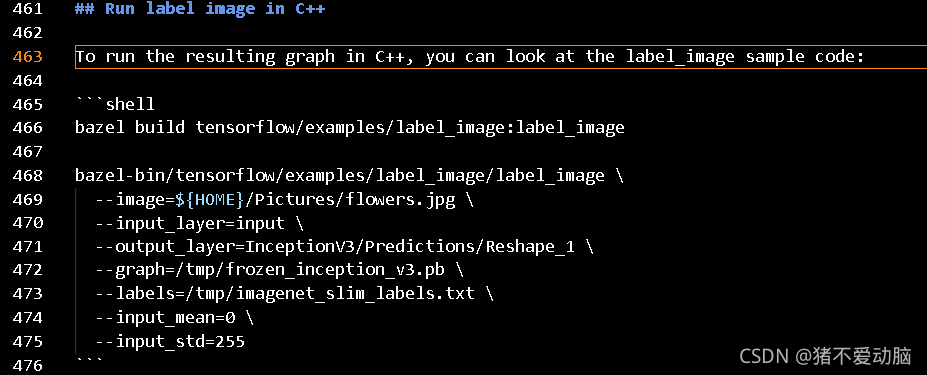
這里如果支持C++編譯的話,可以采用README.md里的方法
這里提供了何之源大神的代碼:
# Copyright 2015 The TensorFlow Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import argparse
import os.path
import re
import sys
import tarfile
import numpy as np
from six.moves import urllib
import tensorflow as tf
FLAGS = None
class NodeLookup(object):
def __init__(self, label_lookup_path=None):
self.node_lookup = self.load(label_lookup_path)
def load(self, label_lookup_path):
node_id_to_name = {}
with open(label_lookup_path) as f:
for index, line in enumerate(f):
node_id_to_name[index] = line.strip()
return node_id_to_name
def id_to_string(self, node_id):
if node_id not in self.node_lookup:
return ''
return self.node_lookup[node_id]
def create_graph():
"""Creates a graph from saved GraphDef file and returns a saver."""
# Creates graph from saved graph_def.pb.
with tf.gfile.FastGFile(FLAGS.model_path, 'rb') as f:
graph_def = tf.GraphDef()
graph_def.ParseFromString(f.read())
_ = tf.import_graph_def(graph_def, name='')
def preprocess_for_eval(image, height, width,
central_fraction=0.875, scope=None):
with tf.name_scope(scope, 'eval_image', [image, height, width]):
if image.dtype != tf.float32:
image = tf.image.convert_image_dtype(image, dtype=tf.float32)
# Crop the central region of the image with an area containing 87.5% of
# the original image.
if central_fraction:
image = tf.image.central_crop(image, central_fraction=central_fraction)
if height and width:
# Resize the image to the specified height and width.
image = tf.expand_dims(image, 0)
image = tf.image.resize_bilinear(image, [height, width],
align_corners=False)
image = tf.squeeze(image, [0])
image = tf.subtract(image, 0.5)
image = tf.multiply(image, 2.0)
return image
def run_inference_on_image(image):
"""Runs inference on an image.
Args:
image: Image file name.
Returns:
Nothing
"""
with tf.Graph().as_default():
image_data = tf.gfile.FastGFile(image, 'rb').read()
image_data = tf.image.decode_jpeg(image_data)
image_data = preprocess_for_eval(image_data, 299, 299)
image_data = tf.expand_dims(image_data, 0)
with tf.Session() as sess:
image_data = sess.run(image_data)
# Creates graph from saved GraphDef.
create_graph()
with tf.Session() as sess:
softmax_tensor = sess.graph.get_tensor_by_name('InceptionV3/Logits/SpatialSqueeze:0')
predictions = sess.run(softmax_tensor,
{'input:0': image_data})
predictions = np.squeeze(predictions)
# Creates node ID --> English string lookup.
node_lookup = NodeLookup(FLAGS.label_path)
top_k = predictions.argsort()[-FLAGS.num_top_predictions:][::-1]
for node_id in top_k:
human_string = node_lookup.id_to_string(node_id)
score = predictions[node_id]
print('%s (score = %.5f)' % (human_string, score))
def main(_):
image = FLAGS.image_file
run_inference_on_image(image)
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument(
'--model_path',
type=str,
)
parser.add_argument(
'--label_path',
type=str,
)
parser.add_argument(
'--image_file',
type=str,
default='battery1.jpg',
help='Absolute path to image file.'
)
parser.add_argument(
'--num_top_predictions',
type=int,
default=5,
help='Display this many predictions.'
)
FLAGS, unparsed = parser.parse_known_args()
tf.compat.v1.app.run(main=main, argv=[sys.argv[0]] + unparsed)
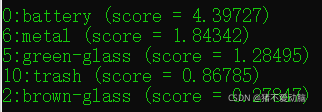
新建一個classify_image_inception_v3.py檔案,copy以上代碼進去,在該檔案目錄下打開cmd,輸入:python classify_image_inception_v3.py --model_path C:\Users\User\Desktop\models-1.13.0\research\slim\my_train\Garbage\frozen_graph.pb --label_path C:\Users\User\Desktop\models-1.13.0\research\slim\my_train\Garbage\labels.txt --image_file test.jpg

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/345625.html
標籤:AI