Flink任務問題分析與性能調優
作者: 吳培堅——虎牙實時計算平臺研發工程師
1 性能分析:
Flink調優對于問題的定性很重要,只有先確定問題性質才能針對性優化,首先要明白,Flink是分布式流計算框架,可簡單理解為多個相互通訊的有狀態java行程,其調優本質跟普通的java程式大同小異,
1.1 問題定位的基礎:
只有具備良好的的監控資料支持,才能感知問題/例外的發生并對其快速定位,
監控指標主要分為以下三個維度:
- Flink框架: 框架本身內嵌了很多方便運維調優的統計資訊,極大方便了性能問題的定位,如:日志、反壓系數、資料partition策略、資料傳輸指標、gc資訊、延遲指標…
- 系統指標:作業系統本身的指標資訊,如:oomkilled頻率(容器環境)、記憶體用量、cpu負載、磁盤網路I/O…
- 行程/執行緒資訊:TaskManager行程內的運行時資訊,各執行緒算力負載資訊、執行緒調度資訊、Rocksdb執行緒負載…
1.2 性能問題主要歸為兩類:
- 穩定性: 此類一般是行程例外退出、jvm oom、容器節點記憶體溢位導致行程被作業系統殺死的oomkilled問題、容器pod驅逐、主機宕機等導致節點丟失任務頻繁重啟,
- 處理性能: 由于資源不足、i/o阻塞、程式邏輯等,導致的計算任務處理性能低下,穩定性低的任務往往也會有處理性能問題,
2 如何定位
2.1 穩定性問題:
穩定性問題非常直觀,最終影響就是導致任務頻繁的重啟,這里只例舉一些代表性原因:
原因及確定方式:
- 記憶體使用超出節點規格觸發oomkilled,查看節點oomkilled記錄,從節點記憶體指標可看出記憶體使用量達到100%后回落, 一般是記憶體不足、Rocksdb托管的記憶體溢位,
- TaskManager行程由于程式錯誤退出:查看具體丟失的taskmanager日志,可以看到TaskManager行程退出且正常關閉資源, 一般是程式代碼不夠魯棒、記憶體配置問題導致,
- GC導致心跳超時:查看GC指標,GC日志,
- k8s驅逐:上述排查無異,查看k8s驅逐記錄, 宿主機宕機、高負載節點驅逐(一般出現在高峰期)
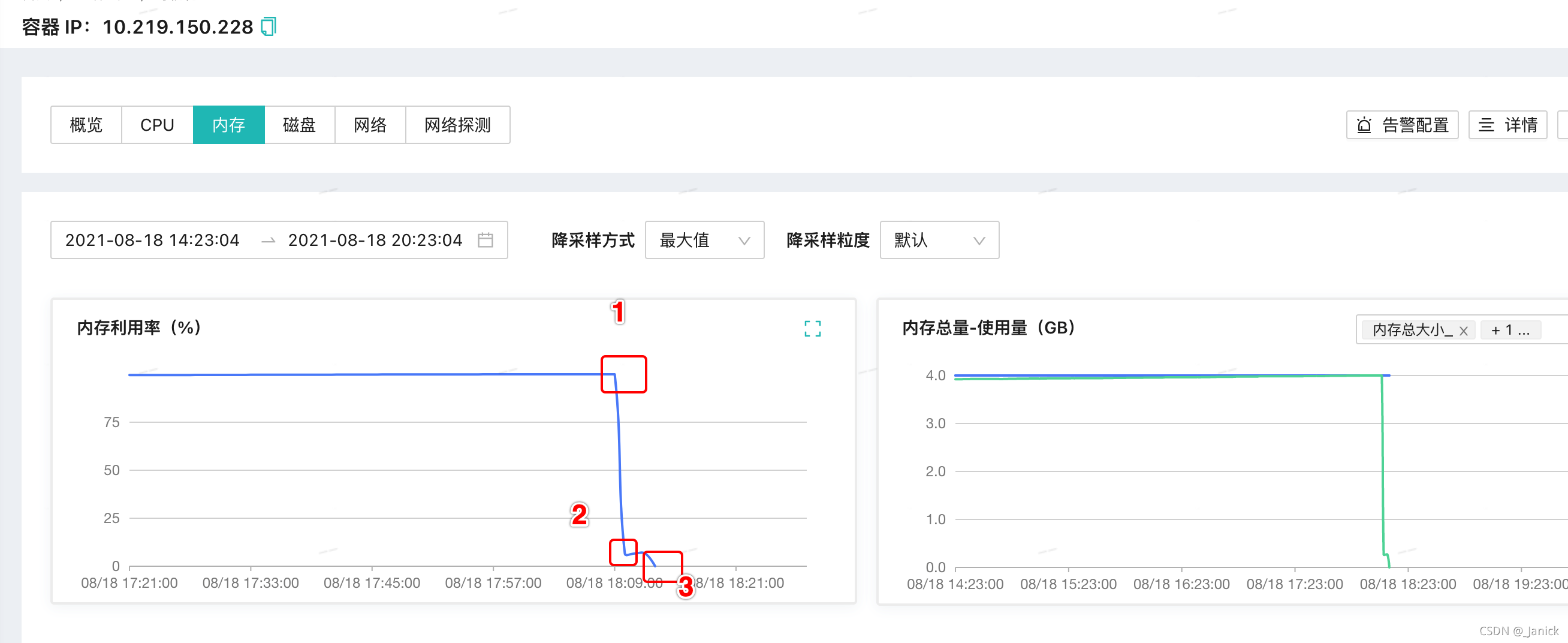
如下圖示Pod記憶體使用在1處達到100%,2顯示TaskManager行程被作業系統kill,在3處洗掉pod后無監控點,這種都是節點出現oomkilled,
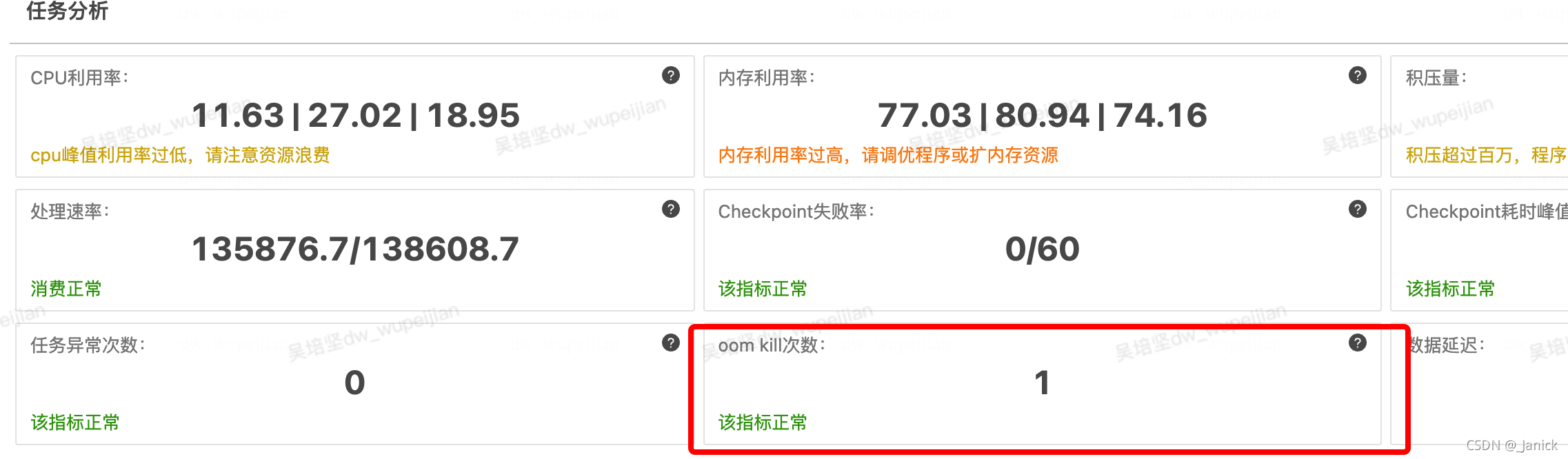
出現oomkilled時候,用戶會收到告警,同時在"任務儀盤表頁面-任務分析模塊",會顯示最近一天統計的oomkilled次數,
- 如何判定是Rocksdb導致記憶體溢位?
通過jemalloc分析可以看到大部分記憶體占用都消耗在Rocksdb的未壓縮block上,基本上可以確定為Rocksdb導致,
2.2 吞吐性能問題:
吞吐性能未達到期望要求,可表現為:資料積壓、任務出現反壓、idleTimeMsPerSecond指標持續為0、checkpoint超時失敗,
2.2.1 主要原因:
-
資源不足,CPU、網路帶寬、磁盤/網路IO、磁盤容量都有可能成為瓶頸,通常情況都是CPU算力不夠,表現為多個TaskManager長時間高負載;
-
CPU資源無法跑滿:
- TaskManager之間負載(資料或者Task)不均衡,表現為部分TaskManager高負載,部分相對空閑;
- Task執行緒高負載:不同Task的處理能力往往各不相同,資源充足的情況下,單執行緒處理瓶頸只在CPU的單核處理能力上,因此短板Task將會成為整個Flink任務的性能瓶頸,指標上表現為TaskManager整體利用率不高,但單Task處理執行緒負載達到100%;
-
CPU資源非正常損耗,由于Full-GC、Rocksdb Compaction/Flush例外等導致的對Flink Task執行緒CPU資源的搶占,
-
Rocksdb狀態讀寫延遲,表現為Task執行緒在Rocksdb讀寫(get/write)上高負載,可通過Rocksdb日志分析;1.13以上版本可通過開啟state-access-latency-tracking指標進行采樣,
2.2.2 如何定位
Tips: 在非高峰期可以通過,減少處理并發(增加單并發資料量)、減少NetworkBufferPool(提高反壓敏感度),測驗任務的高峰處理能力,
- 定位短板Task:可通過 反壓、
idleTimeMsPerSecond指標定位任務性能瓶頸所在的Task, 若Source Task不存在反壓但資料存在積壓,則Source Task為性能瓶頸(往往是資料【反】序列化操作), - 若短板Task所在TaskManager節點整體高負載,則考慮資源是否資源不足;
- 查看短板Task各個SubTask資料負載與反壓系數,若資料負載與反壓系數高度相關則考慮是否資料傾斜問題導致;
- 查看短板Task各個SubTask在各個TaskManager節點的分布情況與反壓系數,若SubTask高度集中的節點,反壓系數越高,則考慮是否Task不均衡導致(參照Flink調度策略優化:Task均衡中問題所示);
- 通過拆分Task中Chaining起來的Operator,查看短板Task執行緒堆疊負載等,定位到具體的執行方法,
3. 調優策略
3.1 吞吐性能調優
3.1.1 平衡資料分布:
- 使用Rescale/Rebalance代替Forward;
- 選擇更為分散的(組合)欄位用于keyby;
- 對key加鹽、解鹽處理;
3.1.2 平衡Task分布:
優化方式參照Flink調度策略優化:Task均衡
3.1.3 降低shuffle損耗
同一Task內的Flink算子資料是在執行緒內傳輸,不通Task之間的算子往往都是走網路傳輸(同個TaskManager內走本地),
盡量將算子chaining起來,減少跨網傳輸與資料序列化/反序列化損耗,
3.1.4 單一職責原則:
- 一個Flink任務由多個Task之間的SubTask組成,一個執行緒執行一個Flink SubTask,上下游SubTask之間通過生產者-消費者模型進行資料傳輸,
SubTask處理太慢會導致整個流程都延遲, 所以算子邏輯盡量簡單,只做一件事(反例:在map中對list迭代、在filter中加載檔案); - 此外,由于一個執行緒執行一個Flink SubTask,Subtask的處理能力受限于單核,對于CPU密集的操作最好拆分到不同Task中充分利用多核CPU的處理能力.
- eg: 很多用戶實作
SourceFunction時候除了拉取資料邏輯,還會對資料進行反序列化操作并提前過濾資料,
這種會導致一個問題:當資料源來自訊息中間件,假設topic磁區數是4,source并行度是10,任務消費的時候最多只有4個Source Subtask進行資料處理,
這時資料拉取任務與反序列化操作共享一個CU,無論資源如何擴,任務吞吐都不會有所提升, - 正確姿勢: source只拉資料,rebalance到下游Task,在下游Task進行資料決議與清洗操作,這樣下游算子才能利用到擴容帶來的資源,
3.1.5 狀態讀寫優化:
參照 3.3.4
3.2 穩定性提高
根本目的是提高節點穩定性,降低taskManager的丟失導致任務重啟頻率
3.2.1 容器環境問題:
- 宿主機宕機無法避免,對于資料延遲敏感的任務,建議冗余一兩個空跑節點,以便任務快速恢復,
- 宿主機因負載均衡主動驅逐:pod設定為有狀態、無狀態pod提高優先級降低pod驅逐概率; pod驅逐策略優化,引入冷卻時間,避免對相同任務的pod多次驅逐,
3.2.2 記憶體問題(oomkilled):
- Rocksdb memtables溢位,Rocksdb老版本對memtables部分的記憶體使用缺乏管控,
- Rocksdb iterator并發高的場景下鎖定記憶體中的部分資料導致記憶體超用
應對方式:
- 擴大托管記憶體:擴大記憶體規格/節點數;提高
taskmanager.memory.managed.fraction配比, - 升級flink至1.12: memtables 記憶體不受管控,新版本rocksdb新增Write Buffer Manager,能有效限制memtables使用,
- 對于非時間域(沒開窗)上的聚合操作,Flink不會清理自動狀態,需要自行配置狀態的過期時間,
- 使用jemalloc做為記憶體分配器,
- 減少在狀態(RocksDB)上的迭代遍歷操作,eg: 盡量使用增量計算(AggFuction) 替代 WindowProcessFunction,
- 本地磁盤使用SSD替換機械硬碟,RocksDB在SSD上有更好的性能;
- 增加jvm overheap/關閉rocksdb 記憶體托管: rocksdb iterator并發高的場景下鎖定記憶體中的部分資料導致記憶體超用,增大預留空間給予超用,
- 開啟rocksdb metrics,rocksdb 日志,精細化調整rocksdb配置: 平衡 【寫放大<—>讀放大<—>空間放大】三者
3.3.3 程式問題:
- FullGC頻繁: 提高堆記憶體配比;dump下現場分析記憶體占用,
- TaskManager行程由于程式錯誤退出: 分析日志例外堆疊,養成良好編程習慣,不要吞例外資訊,
3.3.4 Rocksdb調優
- 非必須不要調整rocksdb引數:
- 使用默認的flink托管rocksdb記憶體可以滿足大部分場景下的需求
- rocksdb引數調整比較復雜,調優需要對其記憶體模型與機制有清晰的了解,否者可能會越調性能越差
- 一旦調整了rocksdb引數,隨著業務資料變化,往往引數配置也需要隨之調整,會加重運維作業
什么情況下需要手動調整rocksdb記憶體呢:
- 3.2.2中 1-5 都無法解決記憶體oomkilled情況;
- 資料處理執行緒在Rocksdb讀寫上存在延遲;
-
RocksDB監控指標 RocksDB-Metrics
-
RocksBD核心配置:
含義 引數名 推薦值 默認值 是否開啟rocksdb記憶體托管 state.backend.rocksdb.memory.managed rocksdb執行checkpoint執行緒數 state.backend.rocksdb.checkpoint.transfer.thread.num 非必要無需更改 flush/compaction 執行緒數 state.backend.rocksdb.thread.num 與Taskmanager core數一致 LSM動態分層 state.backend.rocksdb.compaction.level.use-dynamic-size 單個memtable大小 state.backend.rocksdb.writebuffer.size memtable總個數 state.backend.rocksdb.writebuffer.count 不可變memtable達到多少個開始合并 state.backend.rocksdb.writebuffer.number-to-merge block大小 state.backend.rocksdb.block.blocksize block cache(讀緩沖)大小 state.backend.rocksdb.block.cache-size 單個sst檔案大小 state.backend.rocksdb.compaction.level.target-file-size-base 首層最大size state.backend.rocksdb.compaction.level.max-size-level-base
4 場景分析
4.1 狀態讀寫阻塞
資料處理對狀態讀寫頻繁的任務比較容易出現這種問題,
4.1.1 現場分析:
任務做普通的資料清洗與視窗聚合操作,峰值資料量為100w/s,狀態超過500GB,資源規格 45 * 【4core8gb】,
- 剛啟動任務運行正常,一段時間后吞吐快速下降,checkpoint因為barriar阻塞在管道中延遲導致checkpoint例外,有些會出現記憶體溢位觸發oomkilled,
- windowing aggregate function 上游task反壓嚴重,
- taskManager節點整體cpu利用率不高(取決于資料傾斜程度),但存在個別節點cpu利用率不穩定
- 對cpu負載比較高的節點抽樣分析,執行windowing aggregate function的執行緒cpu利用率接近100%,jstack分析堆疊長時間處于rocksdb讀寫操作
- 磁盤讀/寫不穩定,存在短時間大量磁盤讀操作(壓縮導致),且rocksdb:low 執行緒 負載高,
rocksdb:low 為compaction執行緒,rocksdb:high為flush執行緒
- 查看rocksdb日志,發現存在Write Stalls,若使用了Flink1.13及以上版本可通過
State Backends Latency Tracking Options 直觀監控狀態延遲
4.1.2 處理方案:
關閉rocksdb記憶體托管,避免記憶體溢位,只有關閉托管自定義rocksdb配置才能生效;
通過將memtables設為6個128mb,number-to-merge 設為3,來減少寫放大;
state.backend.rocksdb.thread.num設為4提高flush效率與壓縮性能;
增大sst檔案size與L0壓縮閾值,降低壓縮頻率,
案例需要資料脫敏,整理完再做補充
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/345693.html
標籤:其他
上一篇:DWD層 (用戶行為日志)