本文作者來自MLSQL社區 & Kyligence 機器學習平臺工程師 Andie Huang
背景 Background
對于演算法業務團隊來說,將訓練好的模型部署成服務的業務場景是非常常見的,通常會應用于三個場景:
- 部署到流式程式里,比如風控需要通過流式處理來實時監控,
- 部署到批任務中
- 部署成API服務
然而在現實世界中,很多演算法工程師都會遇到需要花費很多精力在模型部署工程上的問題,
- 平臺割裂,訓練和部署是在不同平臺完成的,
- 配合問題,部署一個模型,需要研發工程師,運維配合,才能完成這件事,
- 技術問題,一般地,大資料里的批流亦或是Web服務一般用Java/Scala/C++偏多些,而AI演算法模型一般都是通過Python來生成的,存在語言障礙,
傳統上,想要把演算法部署成服務,會用到如下方法:
-
比如基于 Tornado 框架把一個 python 模型部署成 RestfulAPI 的服務,或者如果是 Tensorflow 訓練的模型可以用 Tensorflow Serving 的方式結合 Docker 去部署成 RPC/ Restful API 服務,這些能夠幫助用戶實作模型部署的意圖,只是不同的方式都會存在優缺點以及問題;
-
比如用 Python/C++ 開發的模型,要做成 RestfulAPI 或者想做成流批處理可能得跨語言平臺,一般想到用 Spark,這個時候就需要動用 JNI,而跨語言行程之間又面臨資料傳輸的效率問題等;
傳統的這些方法,無法統一完成批,流,web服務的部署,無法解決平臺割裂,無法解決協作問題,
與傳統方式不同,MLSQL 通過融合Ray框架,通過UDF 打通了大資料和Python的生態隔離,完成了訓練和模型部署的統一,同時也完美解決了Python模型部署的三個問題,
Ray 是 UC Berkeley RISELab 新推出的高性能的面對 AI 的分布式執行框架[1,2],它使用了和傳統分布式計算系統不一樣的架構和對分布式計算的抽象方式,具有比 Spark 更優異的計算性能,
下面詳細介紹幾種比較流行的傳統模型部署方式的流程,用戶所面臨的痛點,以及 MLSQL 的部署方案與之對比的優點
傳統模型部署方法
基于 Tornado 的模型部署
傳統的 Tornado 方式的模型部署,鏈路較長,首先用戶需要在訓練節點里,訓練好模型,并且寫好預測代碼,然后將模型以及預測代碼持久化成 pickle 檔案,由于訓練節點和預測節點是分離的,所以需要中間的存盤系統作為媒介,以便服務端 server 拉取模型和預測代碼,服務端拉取模型后需要將模型反序列化,用 tornado 拉起模型服務,

【總結】這種方式在流程上是簡單易懂,但是也存在很多問題,給部署工程師帶來很大的困擾,首先部署工程師除了要負責部署模型,還需要考慮負載均衡,節點監控,維護成本,資源浪費等額外的問題上,同時,基于 Tornado 部署成的 restful api 服務,性能在 QPS 比較大的場景里(e.g., 搜索,推薦,廣告等)難以達到要求,
MLSQL 注冊 UDF 的解決方案較 Tornado 而言,較為輕便,其巧妙地利用了Ray對資源的控制,為開發者省下集群管理,資源分配和調度甚至是負載均衡等額外作業,開發者只需要根據不同任務的需求,設定cpu即可,
基于 Tensorflow Serving 的模型部署
為了服務開發者將訓練好的 Tensorflow 模型部署線上生產環境,Google 提供了 TensorFlow Serving,可以將訓練好的模型直接上線并提供服務,大概作業流程如下:模型檔案存盤在存盤系統中,source 模塊會創建一個 Loader,加載模型資訊,Source 會通知 DynamicManager 模塊有新的模型需要加載,Manger 模塊會根據 VersionPolicy 的演算法制定模型更新策略,來確定 Loader 加載是否加載最新的模型,當客戶端請求模型時候,可以指定模型版本,也可以用最新的模型,
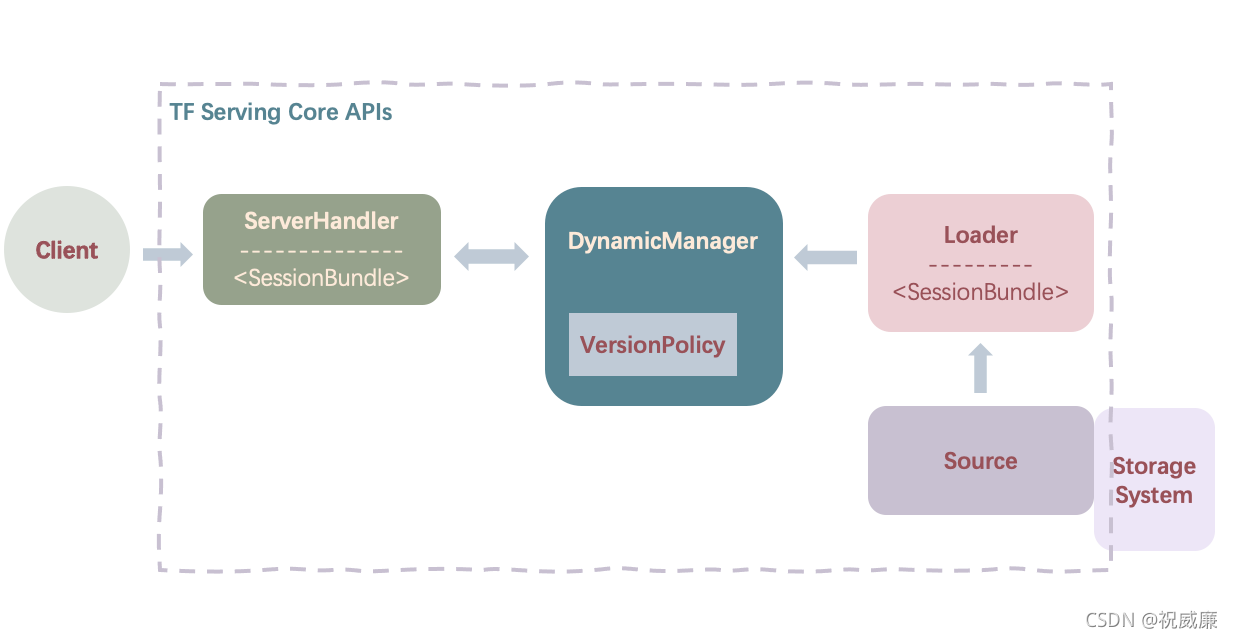
【總結】Tensorflow 的 Serving 模塊對比 Tornado 部署模型服務而言,輕便了許多,同時其模型版本管理模塊很大程度解決了模型版本管理和自更新的問題,相比上一種方式,部署工程師節省了開發模型自更新演算法和模型管理模塊的時間,但是 Google Tensorflow Serving 的許多用戶仍然存在使用上的痛點,比如,最直觀的,資料處理和特征工程部分仍然無法直接部署服務端,需要在客戶端進行處理,此外,若想引入流批處理生資料,還需要接入流批處理(例如 Spark or Flink)等處理框架,
與 Tensorflow Serving 不同的是,MLSQL 選擇 Ray 作為計算框架,天然支持分布式計算,無論是對離線的訓練,還是在線部署都能很好的支持分布式計算,對于在線特征工程部分,也充分利用了 Ray 的分布式計算,以及對 pands 和 numpy 天然支持的優勢,能夠高效地進行在線生資料的分布式處理,再喂給模型得到打分結果,
MLSQL 模型部署 UDF 函式
MLSQL 的執行引擎是基于 Spark 的,如果能夠把一個模型注冊成一個 Spark 的 UDF,然后結合其他函式,我們便能通過函陣列合完成一個端到端的預測流程, MLSQL 已經支持使用 Java/Scala 來寫 UDF,而且可以使用 MLSQL 語法來完成注冊,解決了以前開發 UDF 需要重啟服務的痛點,
比如使用 Scala 寫 UDF 的代碼類似這樣:
register ScriptUDF.`` as arrayLast where
lang="scala"
and code='''def apply(a:Seq[String])={
a.last
}'''
and udfType="udf";
select arrayLast(split("a.b.c",".")) as c as output;
將內置演算法訓練好的模型注冊成 UDF 的代碼是這樣的:
register RandomForest.`/tmp/model` as model_predict;
select vec_array(model_predict(features)) from mock_data as output;
與此同時,我們可以看到,MLSQL 模型部署操作暴露給用戶的仍然是類 SQL 的語法,可以非常方便快速地讓工程師上手,降低工程師的作業量提升模型部署效率,
但是我們知道大部分演算法可能都是使用 Python 來開發的,而且比如深度學習模型,模型檔案都可能非常大,也就是我們其實需要一個帶狀態的 UDF,這是有挑戰的,但得益于
- MLSQL 已經支持 Python 腳本的執行,引入 Ray 后,Python 腳本的分布式執行也不是問題了,計算性能和可擴展性上都有了保證,
- MLSQL 利用 Arrow 做資料傳輸格式,使的資料在跨語言行程傳輸的性能得到保證
- MLSQL 內置的增強資料湖支持目錄以表的形式存盤,這樣可以很好的把模型通過表的方式保存在資料湖里,支持版本以及更新覆寫,同時也方便了 Spark / Ray 之間的模型傳輸,
有了前面這些基礎,我們就可以使用和內置演算法一樣的方式將一個 Python 的模型注冊成一個 UDF 函式,這樣可以將模型應用于批,流,以及 Web 服務中,
【總結】MLSQL 基于 Ray 的計算框架進行 AI 模型的部署能夠具備以下幾個特點:
1)實作模型預測的分布式異步呼叫
2)充分利用Ray的內置功能,實作記憶體調度和負載均衡
3)對Pandas/Numpy 的分布式支持
4)對Python代碼的支持
5)預測性能出眾等
具體地,我們將在下個章節展示 MLSQL 基于 Ray 從模型訓練再到模型模型部署的全流程 demo,并展示 MLSQL 部署的背后原理,
如何利用 MLSQL 部署模型訓練
訓練一個 Tensorflow 模型
下面的代碼要在 notebook 模式下運行
首先,準備 minist 資料集
include lib.`github.com/allwefantasy/lib-core` where
force="true" and
libMirror="gitee.com" and -- proxy configuration.
alias="libCore";
-- dump minist data to object storage
include local.`libCore.dataset.mnist`;
!dumpData /tmp/mnist;
load parquet.`/tmp/mnist` as mnist_data;
在上面的示例中,通過 MLSQL 的模塊支持,引入第三方開發的 lib-core,從而獲得 !dumpData 命令獲取 minist 資料集,
接著就開始拿測驗資料 minist 進行訓練,下面是模型訓練代碼,在訓練代碼中,我們引入 Ray 來訓練:
#%python
#%input=mnist_data
#%schema=file
#%output=mnist_model
#%env=source /Users/allwefantasy/opt/anaconda3/bin/activate ray1.3.0
#%cache=true
import ray
import os
from tensorflow.keras import models,layers
from tensorflow.keras import utils as np_utils
from pyjava.api.mlsql import RayContext
from pyjava.storage import streaming_tar
from pyjava import rayfix
import numpy as np
ray_context = RayContext.connect(globals(),"127.0.0.1:10001")
data_servers = ray_context.data_servers()
def data():
temp_data = [item for item in RayContext.collect_from(data_servers)]
train_images = np.array([np.array(item["image"]) for item in temp_data])
train_labels = np_utils.to_categorical(np.array([item["label"] for item in temp_data]) )
train_images = train_images.reshape((len(temp_data),28*28))
return train_images,train_labels
@ray.remote
@rayfix.last
def train():
train_images,train_labels = data()
network = models.Sequential()
network.add(layers.Dense(512,activation="relu",input_shape=(28*28,)))
network.add(layers.Dense(10,activation="softmax"))
network.compile(optimizer="rmsprop",loss="categorical_crossentropy",metrics=["accuracy"])
network.fit(train_images,train_labels,epochs=6,batch_size=128)
model_path = os.path.join("tmp","minist_model")
network.save(model_path)
model_binary = [item for item in streaming_tar.build_rows_from_file(model_path)]
return model_binary
model_binary = ray.get(train.remote())
ray_context.build_result(model_binary)
最后把模型保存增強資料湖里:
save overwrite mnist_model as delta.`ai_model.mnist_model`;
模型部署
訓練好模型之后,我們就可以用 MLSQL 的 Register 語法將模型注冊成基于 Ray 的服務了,下面是模型注冊的代碼
把模型注冊成 UDF 函式
!python env "PYTHON_ENV=source /Users/allwefantasy/opt/anaconda3/bin/activate ray1.3.0";
!python conf "schema=st(field(content,string))";
!python conf "mode=model";
!python conf "runIn=driver";
!python conf "rayAddress=127.0.0.1:10001";
-- 加載前面訓練好的tf模型
load delta.`ai_model.mnist_model` as mnist_model;
-- 把模型注冊成udf函式
register Ray.`mnist_model` as model_predict where
maxConcurrency="8"
and debugMode="true"
and registerCode='''
import ray
import numpy as np
from pyjava.api.mlsql import RayContext
from pyjava.udf import UDFMaster,UDFWorker,UDFBuilder,UDFBuildInFunc
ray_context = RayContext.connect(globals(), context.conf["rayAddress"])
def predict_func(model,v):
train_images = np.array([v])
train_images = train_images.reshape((1,28*28))
predictions = model.predict(train_images)
return {"value":[[float(np.argmax(item)) for item in predictions]]}
UDFBuilder.build(ray_context,UDFBuildInFunc.init_tf,predict_func)
''' and
predictCode='''
import ray
from pyjava.api.mlsql import RayContext
from pyjava.udf import UDFMaster,UDFWorker,UDFBuilder,UDFBuildInFunc
ray_context = RayContext.connect(globals(), context.conf["rayAddress"])
UDFBuilder.apply(ray_context)
'''
;
-- 這個代碼可以將磁區數目減少,避免并發太高導致的排隊等待
-- load parquet.`/tmp/mnist` as mnist_data;
-- save mnist_data as parquet.`/tmp/minst-8` where fileNum="8";
load parquet.`/tmp/minst` as mnist_data;
select cast(image as array<double>) as image from mnist_data limit 100 as new_mnist_data;
select model_predict(array(image)) as predicted from new_mnist_data as output;
模型呼叫
模型注冊結束之后,如何呼叫注冊的模型呢?MLSQL 提供最簡易的類 SQL 陳述句做批量(Batch)查詢,具體操作如下展示
load parquet.`/tmp/minst` as mnist_data;
select cast(image as array<double>) as image from mnist_data limit 100 as new_mnist_data;
select model_predict(array(image)) as predicted from new_mnist_data as output;
在 MLSQL 里,是由 Pyjava 互通組件去完成 Java Executor 去呼叫 python worker 的,使得可以在 Java 里面去執行 Python 代碼,從而在 SQL 里實作 Python,并且實作資料的互通,
下面,我們針對模型注冊的例子,詳細介紹 MLSQL 里 UDF 注冊是怎么實作的,
PyJava UDF呼叫關系圖
如前面內容所述,對于一個已經訓練好了的模型,注冊成可呼叫的服務,主要需要做以下兩件事:
1)加載已經訓練好的模型
2)拿到需要預測的資料,進行資料處理,喂給模型,得到prediction score【也就是預測函式】,
PyJava 幫用戶做好了第一個流程,第二個流程需要用戶根據自己的使用場景進行自定義,
在 MLSQL 里,模型注冊成 UDF 函式的程序中,用戶主要用以下幾個類,包括 UDFBuilder,UDFMaster,UDF Worker 以及 UDFBuildInFunc,下圖描述了這幾個類之間的關系,
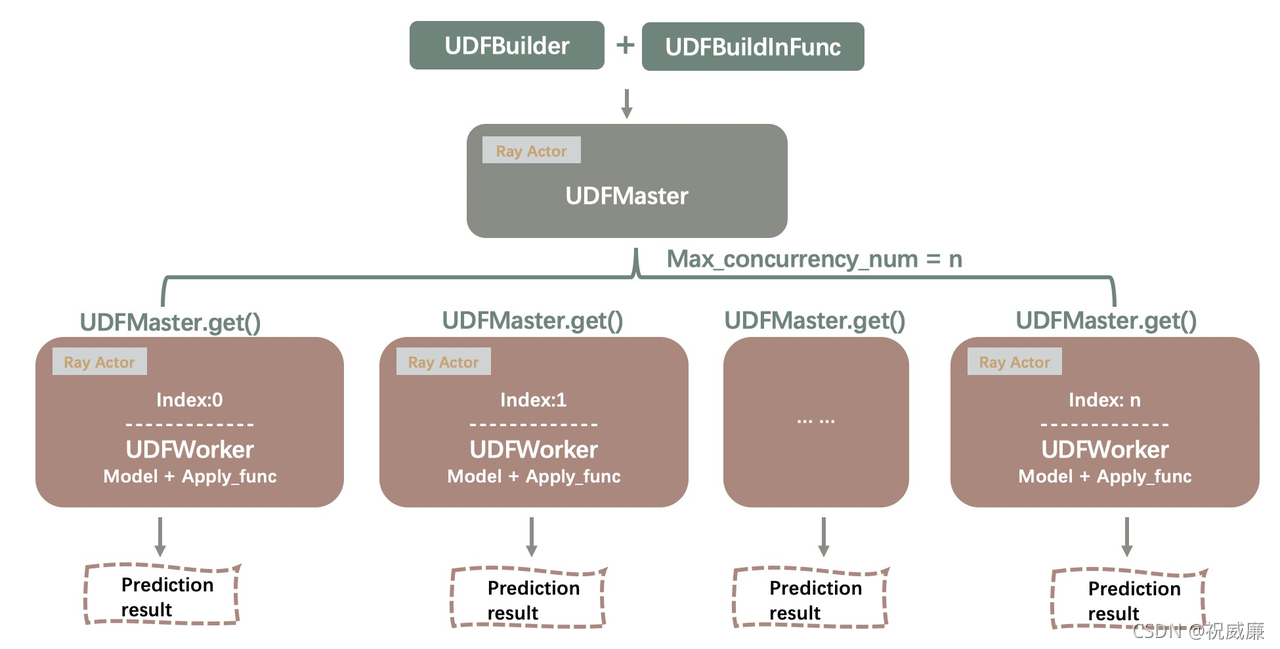
總的一句話,pyjava 用 UDFBuilder.build() 這個函式,去幫用戶實作模型的加載以及用戶自定義的預測函式,
UDFBuildInFunc 為用戶提供了模型初始化的通用邏輯,用戶即可以根據自己的業務場景自定義模型初始化函式,也可以呼叫 UDFBuidInFunc 的 init_tf 方法加載模型,
UDFBuilder 是一個靜態工具類,它通過 build 方法創建 Ray 的 actor UDFMaster,并把模型的加載函式以及模型的預測函式參考傳送到 UDFMaster 里,UDFMaster 里主要做 UDFWorker 的初始化,并將從 UDFBuilder 傳過來的模型加載函式和模型預測函式參考傳遞給 UDFWorker,而真正在做預測邏輯的則是 Ray 集群里的 UDFWorker節點,
在拉起的 Ray的節點中,每一個節點對應一個 UDFWorker,每一個 worker 都在呼叫 apply_func,也就是用戶自定義的預測代碼函式,節點里的預測代碼,通過函式參考的方式,從 UDFBuilder 傳遞到 Ray Actors (包括 UDFMaster 以及 UDFWorker),
具體詳細的函式引數介紹,請看 【UDFBuilder 與UDFBuildInFunc引數使用詳解】部分
MLSQL 執行 Python 的互動
我們都知道,MLSQL 本身背后的引擎是基于 Scala 實作的,而 Scala 又是 Java 系的,在大部分的 AI 場景中,模型預測以及預測前的資料處理很多都是基于 Python 實作的,那么在部署模型服務的時候,如何實作 java 行程與 python 行程的資料通訊呢?
下圖闡述了 MLSQL Engine 端實作 Java 行程與 Python 行程之間的通訊方式,在 MLSQL 中,Engine 端(Java Executor)創建 python worker 行程呼叫 pyjava,pyjava 的主要作業就是做 python worker 與 java executor 端的資料通訊(包括資料獲取和資料輸出,并且通過arrow格式 與Java行程進行資料傳輸),具體的互動流程如下圖所示:
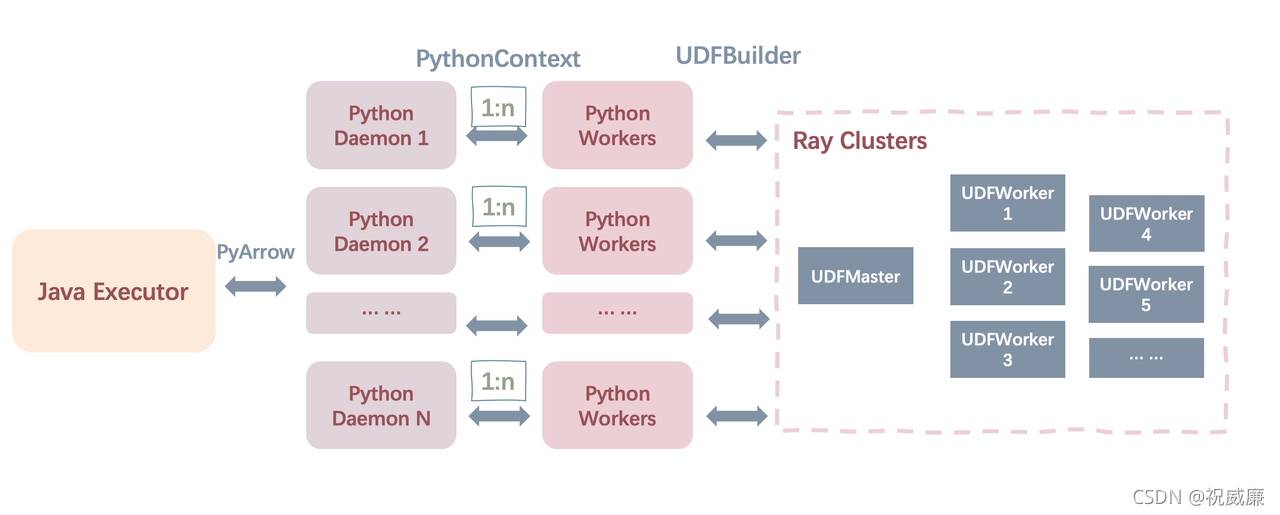
首先 MLSQL Engine 端會在啟動的 java 應用行程里呼叫 pyjava 模塊,pyjava 中 python SDK 部分的入口是 daemon.py 檔案,該入口檔案的主要功能是創建 python worker,同時擔任資料流的管道角色,worker 的核心邏輯包括,匯入ray, 設定自己的記憶體限制,讀取配置引數,讀取 python 腳本,執行python 腳本(通過 Arrow 傳遞 python 腳本資料),并執行,最后通過 Arrow 傳遞 python 執行結果(也就是本文提到的預測結果)給 MLSQL Engine 端,同時 python worker 執行的輸入資料(也就是本文場景下的模型預測輸入資料)借助 pyarrow 從 MLSQL engine 端獲取,
在 Python Daemon 執行緒中,通過 UDFBuilder 創建構造 Ray Actor 包括 UDFMaster 和 UDFWorker,如上一節所述,UDFMaster 主要充當管理 UDFWorker 節點的功能,真正預測的邏輯在 UDFWoker 的 Ray節點里執行,最后的執行結果通過 Ray 獲取 future 的方式回傳給 PythonContext,python worker再通過 pyarrow 回傳給 MLSQL Engine,
UDFBuilder 與 UDFBuildInFunc 引數使用詳解
UDFBuilder
UDFBuilder.build 這個函式有幾個引數,分別是 ray_context,init_func,apply_func,
ray_context:如上一節所述,PythonContext充當資料互動的作用,RayContext則是基于PythonContext之上的整合,目的是讓Ray集群做真正的資料處理的作業,RayContext可以給worker回傳ray的server地址,方便java executor獲取對應的future資料,
ray_context = RayContext.connect(globals(),"127.0.0.1:10001")
init_func: 模型初始化函式,可以是用戶自定義的模型初始化函式,如果沒有特別定制化的業務場景,可以直接復用 BuilderInFunc 的 init_tf 函式,UDFBuildInFunc 部分介紹了 init_func 的實作基本思路,
apply_func:模型預測函式,也就是用戶定義的接收到資料之后做的資料處理函式,以及喂給模型整個流程的函式,
def build(ray_context: RayContext,
init_func: Callable[[List[ClientObjectRef], Dict[str, str]], Any],
apply_func: Callable[[Any, Any], Any]) -> NoReturn:
UDFBuildInFunc
這里的 init_func 是函式的參考,所以僅需要傳遞一個函式的參考就可以,因為基本大部分的 AI 場景都是 load 模型,然后把模型存盤在某個 storage 里,因此,pyjava 的 UDF 模塊為用戶提供的通用的init_func,也就是 UDFBuildInFunc 里的 init_tf,這里的 init_tf 是 UDFBuildInFunc 的一個靜態函式,可以通過靜態呼叫就可以了,
再來看一下這個 init_tf,用戶需要傳遞的兩個值是,分別是 model_refs,以及 conf,對于 model_refs,它是一個 ray 存盤的 object 型別,也就是說,基于我們上一步在 ray 框架里訓練好的模型,可以通過 ray 的 get 方式獲取得到【因為上一步的 train,是基于 ray.remote 呼叫的,結果會產生】,
class UDFBuildInFunc(object):
@staticmethod
def init_tf(model_refs: List[ClientObjectRef], conf: Dict[str, str])
[1] https://zhuanlan.zhihu.com/p/111340572 Ray 分布式計算框架介紹
[2] Moritz, Philipp, et al. “Ray: A distributed framework for emerging AI applications.” 13th Symposium on Operating Systems Design and Implementation ({OSDI} 18). 2018.
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/345694.html
標籤:其他
上一篇:Flink任務問題分析與性能調優