邏輯回歸
邏輯回歸應用于二分類問題,例如:

邏輯回歸的原理
輸入

邏輯回歸的輸入就是一個線性回歸的結果
激活函式
sigmoid函式:
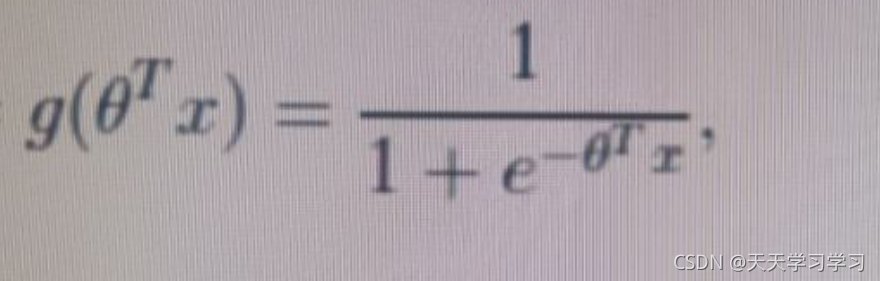
回歸的結果輸入到sigmoid函式當中
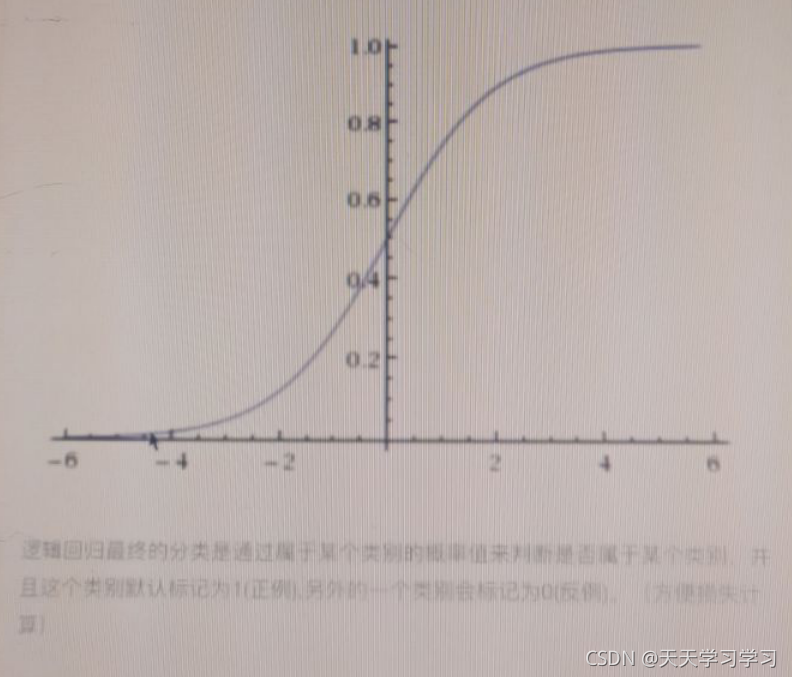
輸出的結果是一個在[0,1]當中的概率值,閾值默認為0.5(即大于0.5為是,小于0.5為否)
損失機器優化
在邏輯回歸中,稱之為對數擬然損失,公式如下:
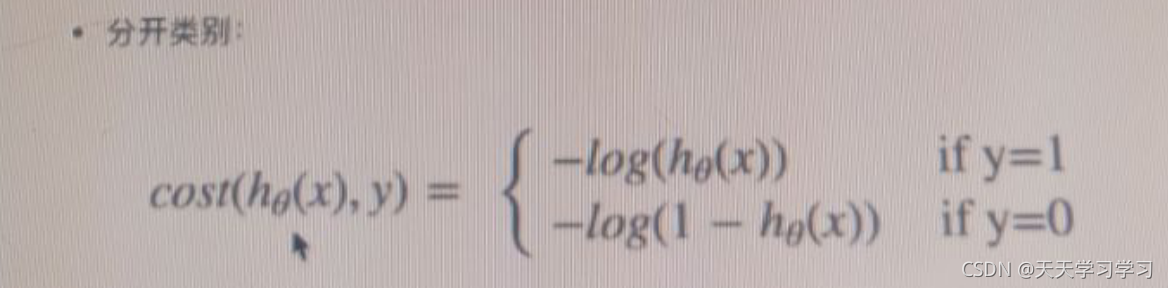
那么我們如何理解這個式子呢?
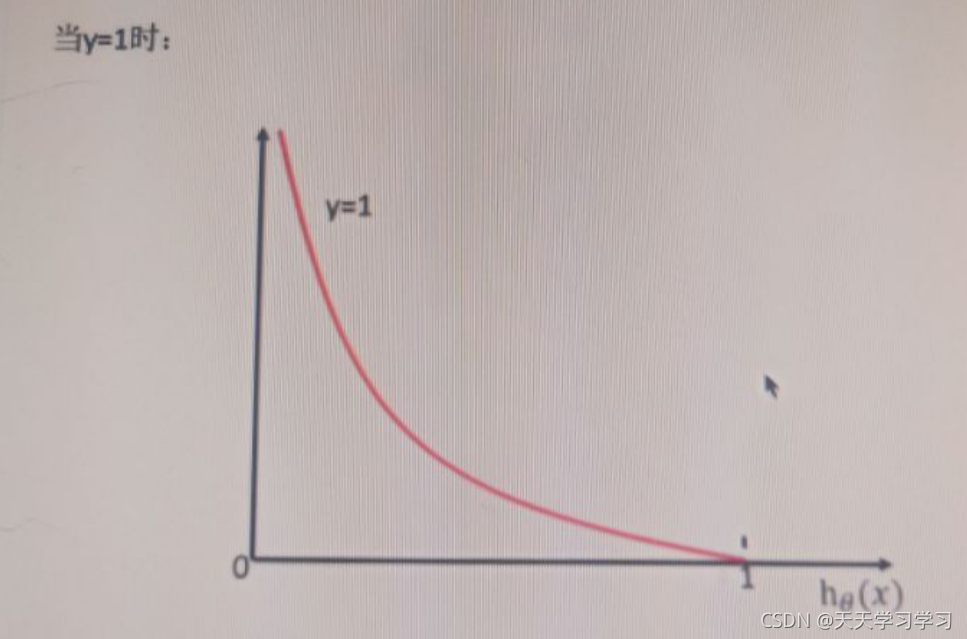
可以看到,當hg(x)==1時,損失函式的值為0,當hg(x)==0時,損失函式的值非常大,這滿足損失函式的定義
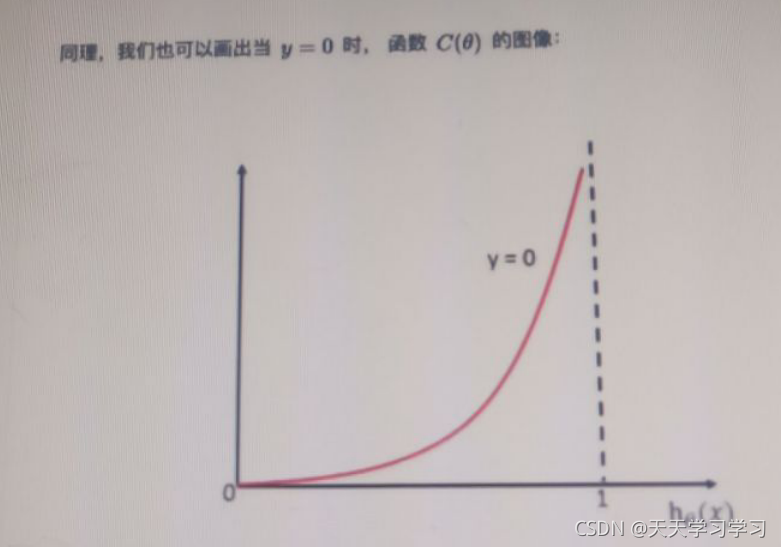
可以看到,當hg(x)==1時,損失函式的值為非常大,當hg(x)==0時,損失函式的值為0,這滿足損失函式的定義
損失函式的公式:
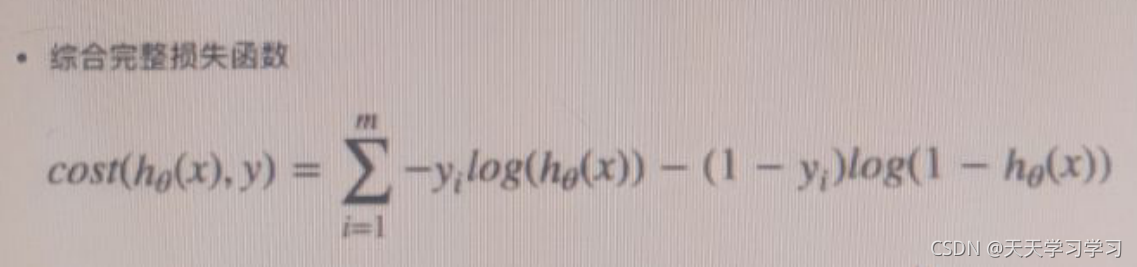
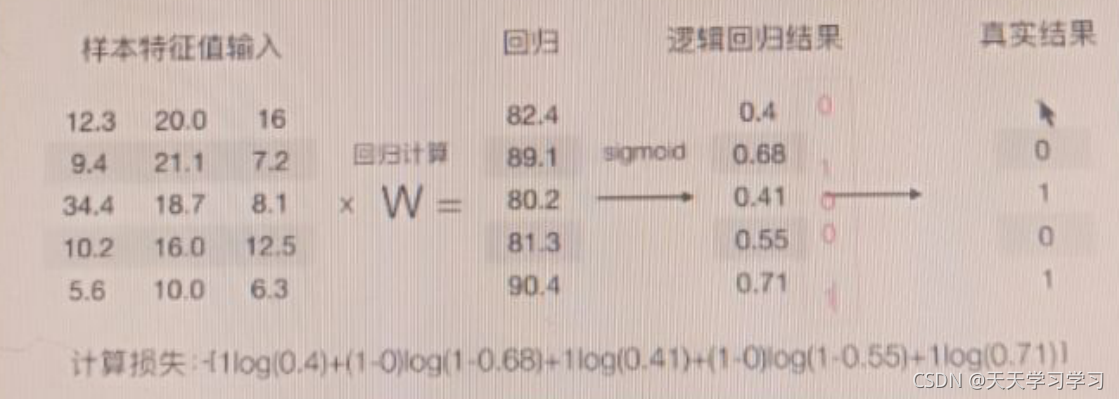
具體實體計算:
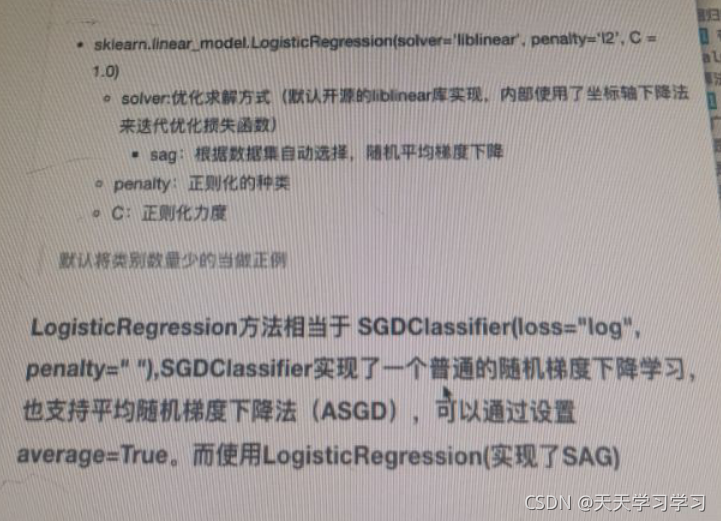
邏輯回歸的API
邏輯回歸分類的評估方法:
混淆矩陣
在分類任務下,預測結果與正確標記之間存在四種不同的組合,從而構成混淆矩陣,
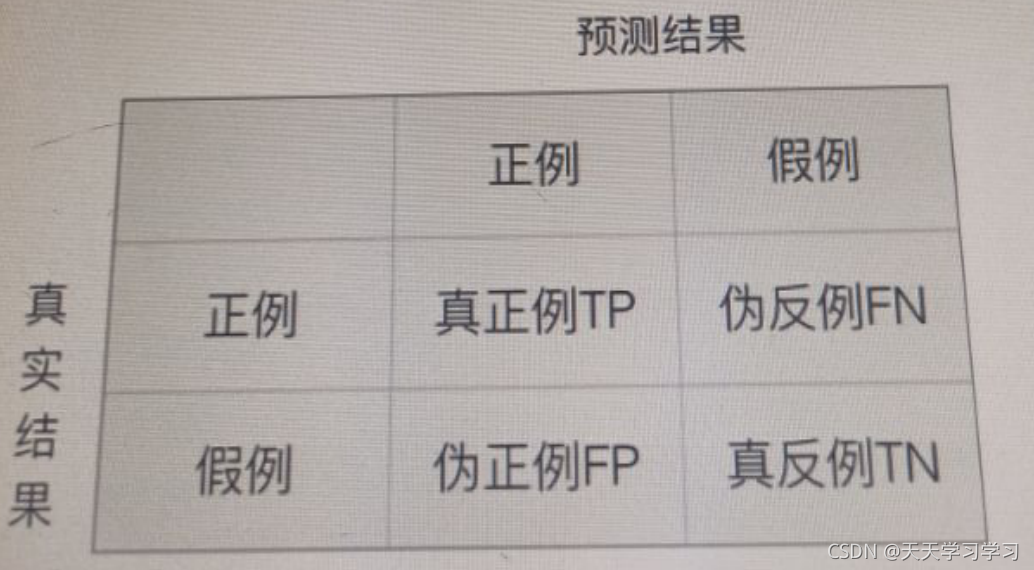
精確率
預測結果為正例樣本中真是為正例的比例,即 TP / TP+FP

召回率
真正為正例樣本中預測結果為正例的比例(對正樣本的區分能力)
即為 TP / TP + FN

F1-SCORE,反應了模型的穩健性

分類評估的API
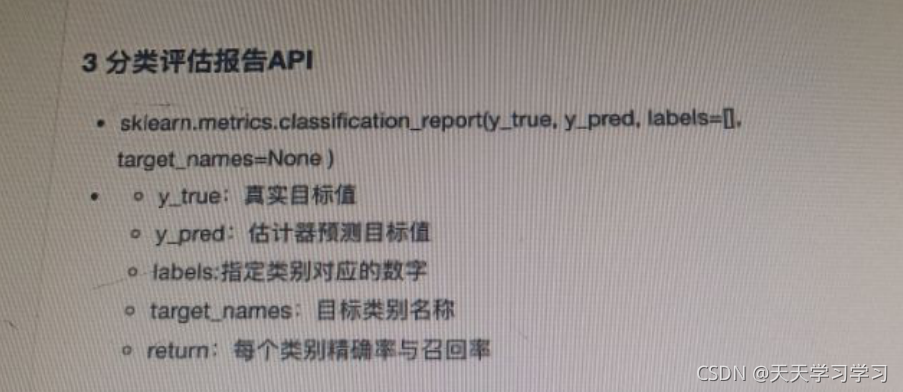
但是這還有一個問題:

ROC曲線與AUC指標
TPR

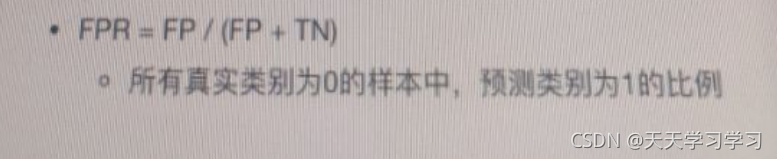
FPR
ROC曲線
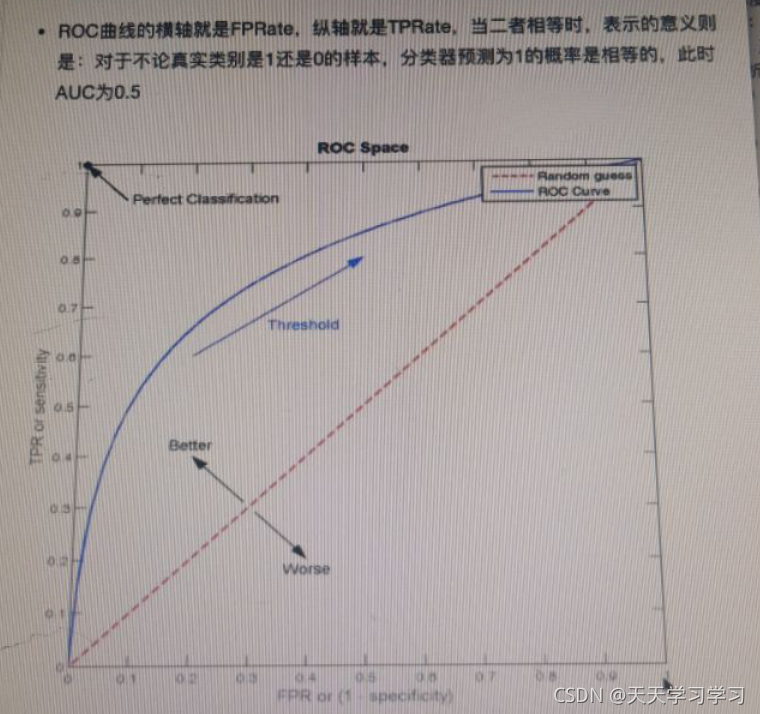

最終的AUC指標在[0.5,1]之間,并且越接近1越好,
AUC的API

總結:AUC只能用來評價二分類,AUC非常適合評價樣本不平衡中的分類器性能,
用邏輯回歸來預測癌細胞(代碼實體):
import pandas as pd
import numpy as np
# 1 讀取資料
path = "https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/breast-cancer-wisconsin.data"
coulum_name = ["Sample code number","Clump Thickness","Uniform of Cell Size","Uniformity of Cell Shape","Manginel Adhesien","Single Epithelial Cell Size"
,"Bare Nuclei","Bland Chromation","Normal Nucieoli","Mitoses","Class"]
data = pd.read_csv(path,names=coulum_name)
# 2 缺失值處理
#替換為 ——>np.nan
data = data.replace(to_replace="?",value=np.nan)
#洗掉缺失樣本
data.dropna(inplace = True)
data.isnull().any() #說明缺失值已經完全洗掉
# 3 劃分資料集
from sklearn.model_selection import train_test_split
#篩選特征值和目標值
data.head()
x = data.iloc[:, 1:-1]
y = data["Class"]
x_train,x_test,y_train,y_test = train_test_split(x, y)
# 4 特征工程--標準化
from sklearn.preprocessing import StandardScaler
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
#5 邏輯回歸預估器
from sklearn.linear_model import LogisticRegression
estimator = LogisticRegression()
estimator.fit(x_train,y_train)
#邏輯回歸模型的回歸系數和偏置
estimator.coef_
# 6 模型評估
#方法1:直接比對真實值和預測值
y_predict = estimator.predict(x_test)
print("y_predict:\n",y_predict)
print("直接比對真實值和預測值:\n",y_test == y_predict)
#方法2:計算準確率
score = estimator.score(x_test,y_test)
print("準確率為:\n",score)


#查看精確率,召回率,以及F1-score
from sklearn.metrics import classification_report
report = classification_report(y_test,y_predict,labels=[2,4],target_names=['良性','惡性'])
print(report)
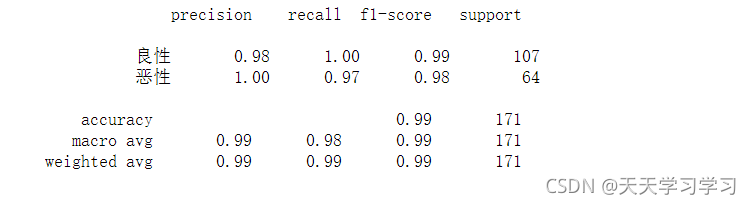
# 因為 y_true:每個樣本的真是類別,必須為0(反例),1(正例)標記
#將y_test轉換成 0 1
y_true = np.where(y_test > 3 , 1 , 0)
#匯入AUC模塊
from sklearn.metrics import roc_auc_score
roc_auc_score(y_true,y_predict)

模型的保存和加載
API:

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/348545.html
標籤:AI