什么是LSTM?
LSTM(長短期記憶人工神經網路),是一種可以學習長期依賴特殊的RNN(回圈神經網路),
傳統回圈網路RNN雖然可以通過記憶體,實作短期記憶,進行連續資料的預測,但是當連續資料的序列變長時,會使展開時間步過長,反向傳播更新引數時梯度要按時間步連續相乘,會導致梯度消失,故引入LSTM(長短期記憶人工神經網路),
LSTM的核心理念
回圈核
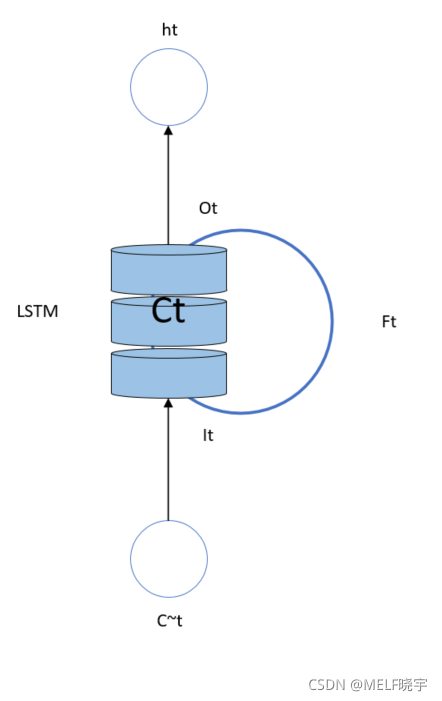
注:
i t i_t it?:輸入門(門限)
f t f_t ft?:遺忘門(門限)
o t o_t ot?:輸出門(門限)
C t C_t Ct?:細胞態(長期記憶)
h t h_t ht?:記憶體(短期記憶)
C t ~ \tilde {C_t} Ct?~?:候選態(歸納出的新知識)
輸入門、遺忘門、輸出門
i t = σ ( W i ? [ h t ? 1 , x t ] + b i ) f t = σ ( W f ? [ h t ? 1 , x t ] + b f ) o t = σ ( W o ? [ h t ? 1 , x t ] + b o ) i_t = \sigma(W_i·[h_{t-1},x_t] + b_i) \\ f_t = \sigma(W_f·[h_{t-1},x_t] + b_f) \\ o_t = \sigma(W_o·[h_{t-1},x_t] + b_o) it?=σ(Wi??[ht?1?,xt?]+bi?)ft?=σ(Wf??[ht?1?,xt?]+bf?)ot?=σ(Wo??[ht?1?,xt?]+bo?)
注:
x t x_t xt?:當前時刻輸入特征
h t ? 1 h_{t-1} ht?1?:上一時刻的短期記憶
W i W_i Wi?、 W f W_f Wf?、 W o W_o Wo?:待訓練引數矩陣
b i b_i bi?、 b f b_f bf?、 b o b_o bo?:待訓練偏置項
Sigmoid激活函式:使門限的范圍在0-1之間
細胞態
C t = f t ? C t ? 1 + i t ? C t ~ C_t = f_t * C_{t-1} + i_t *\tilde {C_t} Ct?=ft??Ct?1?+it??Ct?~?
注:
C t ? 1 C_{t-1} Ct?1?:上一時刻長期記憶
f t f_t ft?:遺忘門(門限)
C t ~ \tilde {C_t} Ct?~?:候選態(當前時刻歸納出的新知識)
i t i_t it?:輸入門(門限)
f t ? C t ? 1 f_t * C_{t-1} ft??Ct?1?:留存在腦中的過去的記憶
記憶體
h t = o t ? t a n h ( C t ) h_t = o_t * tanh(C_t) ht?=ot??tanh(Ct?)
注:
tanh()激活函式
o t o_t ot?:輸出門(門限)
C t C_t Ct?:細胞態(長期記憶)
候選態
C t ~ = t a n h ( W c ? [ h t ? 1 , x t ] + b c ) \tilde {C_t} = tanh(W_c ·[h_{t-1},x_t] + b_c) Ct?~?=tanh(Wc??[ht?1?,xt?]+bc?)
注:
W c W_c Wc?:待訓練引數矩陣
b c b_c bc?:待訓練偏置項
關于深入理解神經網路可以參考:理解神經網路
編程思路
- 匯入相關模塊
- 準備訓練集和測驗集資料
- 對資料集進行歸一化處理,使送入神經網路的資料分布在0-1之間
- 制作訓練集和測驗集的輸入特征和標簽,并打亂訓練集資料順序
- 將資料裝換為
RNN需要輸入的維度 - 搭建神經網路,設定記憶體個數,回圈計算層層數
- 配置訓練方法
- 設定斷點續訓
- 執行訓練程序
- 列印網路結構和引數統計,引數提取和loss可視化
代碼實作
import math
import os
import numpy as np
from keras.layers import LSTM, Dropout, Dense
from sklearn.preprocessing import MinMaxScaler
from tensorflow import optimizers
from tensorflow.keras import Sequential, callbacks
import tensorflow as tf
from sklearn.metrics import mean_squared_error, mean_absolute_error
class CgcpLSTM:
def __init__(self, name):
"""
建構式,初始化模型
:param data_list: 真實資料串列
"""
# 神經網路名稱
self.name = name
# 訓練集占總樣本的比例
self.train_all_ratio = 0.875
# 連續樣本點數
self.continuous_sample_point_num = 20
# 定義歸一化:歸一化到(0,1)之間
self.sc = MinMaxScaler(feature_range=(0, 1))
# 每次喂入神經網路的樣本數
self.batch_size = 64
# 資料集的迭代次數
self.epochs = 1000000
# 每多少次訓練集迭代,驗證一次測驗集
self.validation_freq = 1
# 配置模型
self.model = Sequential([
# LSTM層(記憶體個數,是否回傳輸出(True:每個時間步輸出ht,False:僅最后時間步輸出ht))
# 配置具有80個記憶體的LSTM層,每個時間步輸出ht
LSTM(80, return_sequences=True),
Dropout(0.2),
# 配置具有100個記憶體的LSTM層,僅在最后一步回傳ht
LSTM(100),
Dropout(0.2),
Dense(1)
])
# 配置訓練方法
# 該應用只觀測loss數值,不觀測準確率,所以刪去metrics選項,一會在每個epoch迭代顯示時只顯示loss值
self.model.compile(
optimizer=optimizers.Adam(0.001),
loss='mean_squared_error', # 損失函式用均方誤差
)
# 配置斷點續訓檔案
self.checkpoint_save_path = os.path.abspath(
os.path.dirname(__file__)) + "\\checkpoint\\" + self.name + "_LSTM_stock.ckpt"
if os.path.exists(self.checkpoint_save_path + '.index'):
print('-' * 20 + "加載模型" + "-" * 20)
self.model.load_weights(self.checkpoint_save_path)
# 斷點續訓,存盤最佳模型
self.cp_callback = callbacks.ModelCheckpoint(filepath=self.checkpoint_save_path,
save_weights_only=True,
save_best_only=True,
# monitor='val_accuracy',
monitor='val_loss',
)
def make_set(self, data_list):
"""
使用歷史資料制作訓練集和測驗集
:param data_list: 歷史資料串列
:return: train_set, test_set 歸一化處理后的訓練集合測驗集
"""
# 將歷史資料裝換為ndarray
if isinstance(data_list, list):
data_array = np.array(data_list)
elif isinstance(data_list, np.ndarray):
data_array = data_list
else:
raise Exception("資料源格式錯誤")
# 對一維矩陣進行升維操作
if len(data_array.shape) == 1:
data_array = data_array.reshape(data_array.shape[0], 1)
if data_array.shape[1] != 1:
raise Exception("資料源形狀有誤")
# 按照比例對資料進行分割
index = int(data_array.shape[0] * self.train_all_ratio)
train_set = data_array[:index, :]
test_set = data_array[index:, :]
print("train_set_shape:{}".format(train_set.shape))
# 對訓練集和測驗集進行歸一化處理
train_set, test_set = self.gui_yi(train_set, test_set)
print("訓練集長度:{}".format(len(train_set)))
print("測驗集長度:{}".format(len(test_set)))
return train_set, test_set
def gui_yi(self, train_set, test_set):
"""
對訓練集合測驗集進行歸一化處理
:param test_set: 未進行歸一化的訓練集資料
:param train_set: 未進行歸一化處理的測驗集資料
:return: train_set, test_set 歸一化處理后的訓練集合測驗集
"""
# 求得訓練集的最大值,最小值這些訓練集固有的屬性,并在訓練集上進行歸一化
train_set_scaled = self.sc.fit_transform(train_set)
# 利用訓練集的屬性對測驗集進行歸一化
test_set = self.sc.transform(test_set)
return train_set_scaled, test_set
def fan_gui_yi(self, data_set):
"""
逆歸一化
:param data_set: 需要還原的資料
:return:
"""
# 對資料進行逆歸一化還原
data_set = self.sc.inverse_transform(data_set)
return data_set
def train(self, x_train, y_train, x_test, y_test):
"""
訓練模型
:param x_train:
:param y_train:
:param x_test:
:param y_test:
:return:
"""
# 訓練模型
history = self.model.fit(x_train, y_train,
# 每次喂入神經網路的樣本數
batch_size=self.batch_size,
# 資料集的迭代次數
epochs=self.epochs,
validation_data=(x_test, y_test),
# 每多少次訓練集迭代,驗證一次測驗集
validation_freq=self.validation_freq,
callbacks=[self.cp_callback])
# 輸出模型各層的引數狀況
self.model.summary()
# 引數提取
self.save_args_to_file()
# 獲取模型當前loss值
loss = history.history['loss']
print("loss:{}".format(loss))
try:
val_loss = history.history['val_loss']
print("val_loss:{}".format(val_loss))
except:
pass
def save_args_to_file(self):
"""
引數提取,將引數保存至檔案
:return:
"""
# 指定引數存取目錄
file_path = os.path.abspath(
os.path.dirname(__file__)) + "\\weights\\"
# 目錄不存在則創建
if not os.path.exists(file_path):
os.makedirs(file_path)
# 打開文本檔案
file = open(file_path + self.name + "_weights.txt", 'w')
# 將引數寫入檔案
for v in self.model.trainable_variables:
file.write(str(v.name) + '\n')
file.write(str(v.shape) + '\n')
file.write(str(v.numpy()) + '\n')
file.close()
def test(self, x_test, test_set):
"""
預測測驗
:param x_test:
:param test_set: 測驗集
:return:
"""
# 測驗集輸入模型進行預測
predicted_stock_price = self.model.predict(x_test)
# 對預測資料還原---從(0,1)反歸一化到原始范圍
predicted_stock_price = self.fan_gui_yi(predicted_stock_price)
# 對真實資料還原---從(0,1)反歸一化到原始范圍
real_stock_price = self.fan_gui_yi(test_set[self.continuous_sample_point_num:])
# ##########evaluate##############
# calculate MSE 均方誤差 ---> E[(預測值-真實值)^2] (預測值減真實值求平方后求均值)
mse = mean_squared_error(predicted_stock_price, real_stock_price)
# calculate RMSE 均方根誤差--->sqrt[MSE] (對均方誤差開方)
rmse = math.sqrt(mean_squared_error(predicted_stock_price, real_stock_price))
# calculate MAE 平均絕對誤差----->E[|預測值-真實值|](預測值減真實值求絕對值后求均值)
mae = mean_absolute_error(predicted_stock_price, real_stock_price)
print('均方誤差: %.6f' % mse)
print('均方根誤差: %.6f' % rmse)
print('平均絕對誤差: %.6f' % mae)
def make_x_y_train_and_test(self, data_list):
"""
制作x_train(訓練集輸入特征), y_train(訓練集標簽), x_test(測驗集輸入特征), y_test(測驗集標簽)
:param data_list:
:return:
"""
# 獲取歸一化后的訓練集合測驗集
train_set, test_set = self.make_set(data_list=data_list)
# 初始化x_train(訓練集輸入特征), y_train(訓練集標簽), x_test(測驗集輸入特征), y_test(測驗集標簽)
x_train, y_train, x_test, y_test = [], [], [], []
# 利用for回圈,遍歷整個訓練集,提取訓練集中連續樣本為訓練集輸入特征和標簽
for i in range(self.continuous_sample_point_num, len(train_set)):
x_train.append(train_set[i - self.continuous_sample_point_num:i, 0])
y_train.append(train_set[i, 0])
# 對訓練集進行打亂
np.random.seed(7)
np.random.shuffle(x_train)
np.random.seed(7)
np.random.shuffle(y_train)
tf.random.set_seed(7)
# 將訓練集由list格式變為array格式
x_train, y_train = np.array(x_train), np.array(y_train)
# 使x_train符合RNN輸入要求:[送入樣本數, 回圈核時間展開步數, 每個時間步輸入特征個數],
x_train = self.change_data_to_rnn_input(x_train)
# 測驗集
# 利用for回圈,遍歷整個測驗集,提取訓練集中連續樣本為訓練集輸入特征和標簽
for i in range(self.continuous_sample_point_num, len(test_set)):
x_test.append(test_set[i - self.continuous_sample_point_num:i, 0])
y_test.append(test_set[i, 0])
# 測驗集變array并reshape為符合RNN輸入要求:[送入樣本數, 回圈核時間展開步數, 每個時間步輸入特征個數]
x_test, y_test = np.array(x_test), np.array(y_test)
print("x_test_shape:{}".format(x_test.shape))
x_test = self.change_data_to_rnn_input(x_test)
return train_set, test_set, x_train, y_train, x_test, y_test
def change_data_to_rnn_input(self, data_array):
"""
將資料轉變為RNN輸入要求的維度
:param data_array:
:return:
"""
# 對輸入型別進行轉換
if isinstance(data_array, list):
data_array = np.array(data_array)
elif isinstance(data_array, np.ndarray):
pass
else:
raise Exception("資料格式錯誤")
rnn_input = np.reshape(data_array, (data_array.shape[0], self.continuous_sample_point_num, 1))
return rnn_input
def predict(self, history_data):
"""
使用模型進行預測
:param history_data: 歷史資料list
:return:預測值
"""
# 將串列或陣列轉換為陣列并提取最后一組資料
if isinstance(history_data, list):
history_data_array = history_data[self.continuous_sample_point_num * -1:]
history_data_array = np.array(history_data_array)
elif isinstance(history_data, np.ndarray):
history_data_array = history_data[self.continuous_sample_point_num * -1:]
else:
raise Exception("資料格式錯誤")
# 對一維資料進行升維處理
if len(history_data_array.shape) == 1:
history_data_array = history_data_array.reshape(1, self.continuous_sample_point_num)
# 對資料形狀進行效驗
if history_data_array.shape[1] != self.continuous_sample_point_num:
raise Exception("資料形狀有誤")
# 對資料進行歸一化處理
history_data_array = history_data_array.T
history_data_array = self.sc.transform(history_data_array)
history_data_array = history_data_array.T
# 轉換為RNN需要的資料形狀
history_data_array = self.change_data_to_rnn_input(history_data_array)
# 測驗集輸入模型進行預測
predicted_stock_price = self.model.predict(history_data_array)
# 對預測資料還原---從(0,1)反歸一化到原始范圍
predicted_stock_price = self.fan_gui_yi(predicted_stock_price)
# 預測值
value = predicted_stock_price[-1][-1]
print("預測值:{}".format(value))
return value
if __name__ == '__main__':
data_list = [x for x in range(1000)]
# print(data_list)
# 初始化模型
model = CgcpLSTM(name="濃度預測")
# 獲取訓練和測驗的相關引數
train_set, test_set, x_train, y_train, x_test, y_test = model.make_x_y_train_and_test(data_list=data_list)
# 訓練模型
model.train(x_train, y_train, x_test, y_test)
# 對模型進行測驗
model.test(x_test, test_set)
# 利用模型進行預測
history = [x for x in range(50)]
model.predict(history)
參考文獻
人工智能實踐:Tensorflow筆記_中國大學MOOC(慕課):https://www.icourse163.org/learn/PKU-1002536002?tid=1462067447
理解 LSTM 網路:https://www.jianshu.com/p/9dc9f41f0b29
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/348546.html
標籤:AI
上一篇:機器學習之路14
下一篇:【slowfast 損失函式改進】深度學習網路通用改進方案:slowfast的損失函式(使用focal loss解決不平衡資料)改進