Keras: Multiple Inputs and Mixed Data
在本教程中,您將學習如何將 Keras 用于多輸入和混合資料,
您將學習如何定義能夠接受多個輸入(包括數字、分類和影像資料)的 Keras 架構, 然后我們將在這個混合資料上訓練一個端到端的網路, 今天是我們關于 Keras 和回歸的三部分系列的最后一部分:
- 使用 Keras 進行基本回歸 訓練 Keras
- CNN 進行回歸預測
- 使用 Keras 進行多輸入和混合資料(今天的帖子)
在本系列博文中,我們探討了房價預測背景下的回歸預測, 我們使用的房價資料集不僅包括數字和分類資料,還包括影像資料——我們將多種型別的資料稱為混合資料,因為我們的模型需要能夠接受我們的多種輸入(不同型別) 并計算對這些輸入的預測,
在本教程的其余部分中,您將學習如何:
- 定義一個 Keras 模型,該模型能夠同時接受多個輸入,包括數值、分類和影像資料,
- 在混合資料輸入上訓練端到端 Keras 模型,
- 使用多輸入評估我們的模型,
要了解有關使用 Keras 進行多輸入和混合資料的更多資訊,請繼續閱讀!
Keras:多輸入和混合資料
在本教程的第一部分,我們將簡要回顧混合資料的概念以及 Keras 如何接受多個輸入,
從那里我們將審查我們的房價資料集和這個專案的目錄結構,
接下來,我將向您展示如何:
- 從磁盤加載數值、分類和影像資料,
- 預處理資料,以便我們可以在其上訓練網路,
- 準備混合資料,以便將其應用于多輸入 Keras 網路,
準備資料后,您將學習如何定義和訓練多輸入 Keras 模型,該模型在單個端到端網路中接受多種型別的輸入資料,
最后,我們將在測驗集上評估我們的多輸入和混合資料模型,并將結果與本系列之前的文章進行比較,
什么是混合資料?
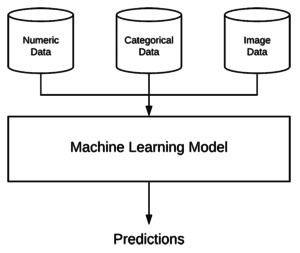
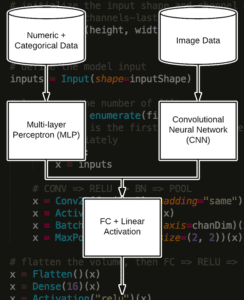
圖 1:借助 Keras 靈活的深度學習框架,可以定義一個包含 CNN 和 MLP 分支的多輸入模型來處理混合資料,
在機器學習中,混合資料是指具有多種型別的獨立資料的概念, 例如,假設我們是在醫院作業的機器學習工程師,以開發能夠對患者的健康狀況進行分類的系統, 對于給定的患者,我們會有多種型別的輸入資料,包括:
- 數字/連續值,例如年齡、心率、血壓
- 分類值,包括性別和種族
- 影像資料,例如任何 MRI、X 射線等,
所有這些值構成了不同的資料型別; 然而,我們的機器學習模型必須能夠攝取這種“混合資料”并對其進行(準確)預測,
在使用多種資料模式時,您會在機器學習文獻中看到術語“混合資料”, 開發能夠處理混合資料的機器學習系統可能極具挑戰性,因為每種資料型別可能需要單獨的預處理步驟,包括縮放、歸一化和特征工程, 處理混合資料仍然是一個非常開放的研究領域,并且通常嚴重依賴于特定的任務/最終目標,
我們將在今天的教程中處理混合資料,以幫助您了解與之相關的一些挑戰,
Keras 如何接受多個輸入?

圖 2:與其 Sequential API 不同,Keras 的函式式 API 允許使用更復雜的模型, 在這篇博文中,我們使用函式式 API 來支持我們創建具有多個輸入和混合資料的模型以進行房價預測的目標,
Keras 能夠通過其功能 API 處理多個輸入(甚至多個輸出), 與sequential API(您之前幾乎肯定已經通過 Sequential 類使用過)相反,函式式 API 可用于定義更復雜的non-sequential 模型,包括:
- 多輸入型號
- 多輸出型號
- 多輸入多輸出模型
- 有向無環圖
- 具有共享層的模型
例如,我們可以將一個簡單的序列神經網路定義為:
model = Sequential()
model.add(Dense(8, input_shape=(10,), activation="relu"))
model.add(Dense(4, activation="relu"))
model.add(Dense(1, activation="linear"))
這個網路是一個簡單的前饋神經網路,有 10 個輸入,第一個隱藏層有 8 個節點,第二個隱藏層有 4 個節點,最后一個輸出層用于回歸,
我們可以使用函式式 API 定義示例神經網路:
inputs = Input(shape=(10,))
x = Dense(8, activation="relu")(inputs)
x = Dense(4, activation="relu")(x)
x = Dense(1, activation="linear")(x)
model = Model(inputs, x)
請注意我們如何不再依賴 Sequential 類, 要了解 Keras 函式 API 的強大功能,請考慮以下代碼,其中我們創建了一個接受多個輸入的模型:
# define two sets of inputs
inputA = Input(shape=(32,))
inputB = Input(shape=(128,))
# the first branch operates on the first input
x = Dense(8, activation="relu")(inputA)
x = Dense(4, activation="relu")(x)
x = Model(inputs=inputA, outputs=x)
# the second branch opreates on the second input
y = Dense(64, activation="relu")(inputB)
y = Dense(32, activation="relu")(y)
y = Dense(4, activation="relu")(y)
y = Model(inputs=inputB, outputs=y)
# combine the output of the two branches
combined = concatenate([x.output, y.output])
# apply a FC layer and then a regression prediction on the
# combined outputs
z = Dense(2, activation="relu")(combined)
z = Dense(1, activation="linear")(z)
# our model will accept the inputs of the two branches and
# then output a single value
model = Model(inputs=[x.input, y.input], outputs=z)
在這里,您可以看到我們為 Keras 神經網路定義了兩個輸入:
- 輸入A:32-dim
- 輸入B : 128-dim
使用 Keras 的函式式 API 定義了一個簡單的 32-8-4 網路,
類似地,定義了一個 128-64-32-4 網路,
然后我們合并 x 和 y 的輸出, x 和 y 的輸出都是 4-dim,所以一旦我們將它們連接起來,我們就有一個 8-dim 向量, 然后,我們應用另外兩個完全連接的層,第一層有 2 個節點,然后是 ReLU 激活,而第二層只有一個具有線性激活的節點(即我們的回歸預測), 構建多輸入模型的最后一步是定義一個模型物件,它:
- 接受我們的兩個輸入
- 將輸出定義為最終的 FC 層集(即 z ),
如果您要使用 Keras 來可視化模型架構,它將如下所示:
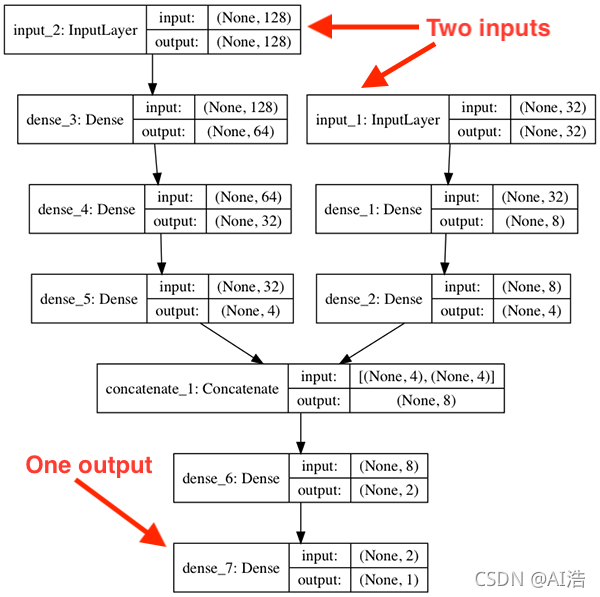
圖 3:該模型有兩個輸入分支,最終合并并產生一個輸出, Keras 函式式 API 支持這種型別的架構以及您可以想象的其他架構,
注意我們的模型有兩個不同的分支, 第一個分支接受我們的 128-d 輸入,而第二個分支接受 32-d 輸入, 這些分支彼此獨立運行,直到它們連接起來, 從那里從網路輸出單個值, 在本教程的其余部分,您將學習如何使用 Keras 創建多個輸入網路,
房價資料集

圖 4:房價資料集由數字/分類資料和影像資料組成, 使用 Keras,我們將構建一個支持多輸入和混合資料型別的模型, 結果將是預測房屋價格/價值的 Keras 回歸模型,
資料集地址:emanhamed/Houses-dataset: This is the first benchmark dataset for houses prices that contains both images and textual information that was introduced in our paper. (github.com)
該資料集包括數字/分類資料以及資料集中 535 個示例房屋中的每一個的影像資料, 數字和分類屬性包括:
- 臥室數量
- 浴室數量
- 面積(即平方英尺)
- 郵政編碼
每個房子總共提供了四張圖片:
- 臥室
- 浴室
- 廚房
- 房子的正面圖
今天,我們將使用 Keras 處理多個輸入和混合資料, 我們將接受數字/分類資料以及我們的影像資料到網路, 將定義網路的兩個分支來處理每種型別的資料, 然后將在最后合并分支以獲得我們最終的房價預測,
通過這種方式,我們將能夠利用 Keras 處理多個輸入和混合資料,
專案結構
$ tree --dirsfirst --filelimit 10
.
├── Housesdataset
│ ├── HousesDataset [2141 entries]
│ └── README.md
├── model
│ ├── __init__.py
│ ├── datasets.py
│ └── models.py
└── mixed_training.py
Houses-dataset 檔案夾包含我們在本系列中使用的 House Prices 資料集, 當我們準備好運行 mix_training.py 腳本時,您只需要提供一個路徑作為資料集的命令行引數(我將在結果部分向您展示這是如何完成的), 今天我們將回顧三個 Python 腳本:
model/datasets.py :處理加載和預處理我們的數值/分類資料以及我們的影像資料, 我們之前在過去兩周內審查了這個腳本,但今天我將再次引導您完成它,
model/models.py :包含我們的多層感知器(MLP)和卷積神經網路(CNN), 這些組件是我們的多輸入混合資料模型的輸入分支, 我們上周審查了這個腳本,今天我們也將簡要審查它,
mix_training.py :我們的訓練腳本將使用 pyimagesearch 模塊的便利功能來加載 + 拆分資料并將兩個分支連接到我們的網路 + 添加頭部, 然后它將訓練和評估模型,
加載數值和分類資料
打開 datasets.py 檔案并插入以下代碼:
# import the necessary packages
from sklearn.preprocessing import LabelBinarizer
from sklearn.preprocessing import MinMaxScaler
import pandas as pd
import numpy as np
import glob
import cv2
import os
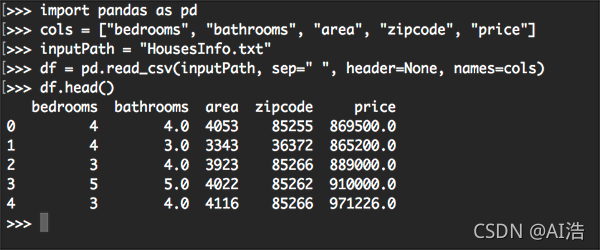
def load_house_attributes(inputPath):
# initialize the list of column names in the CSV file and then
# load it using Pandas
cols = ["bedrooms", "bathrooms", "area", "zipcode", "price"]
df = pd.read_csv(inputPath, sep=" ", header=None, names=cols)
# determine (1) the unique zip codes and (2) the number of data
# points with each zip code
zipcodes = df["zipcode"].value_counts().keys().tolist()
counts = df["zipcode"].value_counts().tolist()
# loop over each of the unique zip codes and their corresponding
# count
for (zipcode, count) in zip(zipcodes, counts):
# the zip code counts for our housing dataset is *extremely*
# unbalanced (some only having 1 or 2 houses per zip code)
# so let's sanitize our data by removing any houses with less
# than 25 houses per zip code
if count < 25:
idxs = df[df["zipcode"] == zipcode].index
df.drop(idxs, inplace=True)
# return the data frame
return df
匯入專案需要的包,
定義了 load_house_attributes 函式, 該函式通過 Pandas 的 pd.read_csv 以 CSV 檔案的形式從房價資料集中讀取數字/分類資料, 資料被過濾以適應不平衡, 一些郵政編碼僅由 1 或 2 個房屋表示,因此我們繼續洗掉郵政編碼中少于 25 個房屋的任何記錄, 結果是稍后更準確的模型, 現在讓我們定義 process_house_attributes 函式:
def process_house_attributes(df, train, test):
# initialize the column names of the continuous data
continuous = ["bedrooms", "bathrooms", "area"]
# performin min-max scaling each continuous feature column to
# the range [0, 1]
cs = MinMaxScaler()
trainContinuous = cs.fit_transform(train[continuous])
testContinuous = cs.transform(test[continuous])
# one-hot encode the zip code categorical data (by definition of
# one-hot encoding, all output features are now in the range [0, 1])
zipBinarizer = LabelBinarizer().fit(df["zipcode"])
trainCategorical = zipBinarizer.transform(train["zipcode"])
testCategorical = zipBinarizer.transform(test["zipcode"])
# construct our training and testing data points by concatenating
# the categorical features with the continuous features
trainX = np.hstack([trainCategorical, trainContinuous])
testX = np.hstack([testCategorical, testContinuous])
# return the concatenated training and testing data
return (trainX, testX)
此函式通過 sklearn-learn 的 MinMaxScaler將最小-最大縮放應用于連續特征,
然后,計算分類特征的單熱編碼,這次是通過 sklearn-learn 的 LabelBinarizer, 然后連接并回傳連續和分類特征,
加載影像資料集

圖 6:我們模型的一個分支接受單個影像 - 來自家中的四張影像的蒙太奇, 使用蒙太奇與輸入到另一個分支的數字/類別資料相結合,我們的模型然后使用回歸來預測具有 Keras 框架的房屋的價值,
下一步是定義一個輔助函式來加載我們的輸入影像, 再次打開 datasets.py 檔案并插入以下代碼:
def load_house_images(df, inputPath):
# initialize our images array (i.e., the house images themselves)
images = []
# loop over the indexes of the houses
for i in df.index.values:
# find the four images for the house and sort the file paths,
# ensuring the four are always in the *same order*
basePath = os.path.sep.join([inputPath, "{}_*".format(i + 1)])
housePaths = sorted(list(glob.glob(basePath)))
# initialize our list of input images along with the output image
# after *combining* the four input images
inputImages = []
outputImage = np.zeros((64, 64, 3), dtype="uint8")
# loop over the input house paths
for housePath in housePaths:
# load the input image, resize it to be 32 32, and then
# update the list of input images
image = cv2.imread(housePath)
image = cv2.resize(image, (32, 32))
inputImages.append(image)
# tile the four input images in the output image such the first
# image goes in the top-right corner, the second image in the
# top-left corner, the third image in the bottom-right corner,
# and the final image in the bottom-left corner
outputImage[0:32, 0:32] = inputImages[0]
outputImage[0:32, 32:64] = inputImages[1]
outputImage[32:64, 32:64] = inputImages[2]
outputImage[32:64, 0:32] = inputImages[3]
# add the tiled image to our set of images the network will be
# trained on
images.append(outputImage)
# return our set of images
return np.array(images)
load_house_images 函式有三個目標:
- 加載房價資料集中的所有照片, 回想一下,我們每個房子都有四張照片(圖 6),
- 從四張照片生成單個蒙太奇影像, 蒙太奇將始終按照您在圖中看到的方式排列,
- 將所有這些家庭蒙太奇附加到串列/陣列并回傳到呼叫函式,
我們定義了接受 Pandas 資料框和資料集 inputPath 的函式,
初始化影像串列, 我們將使用我們構建的所有蒙太奇影像填充此串列, 在我們的資料框中回圈房屋, 在回圈內部, 獲取當前房屋的四張照片的路徑,
執行初始化, 我們的 inputImages 將以串列形式包含每條記錄的四張照片, 我們的 outputImage 將是照片的蒙太奇(如圖 6 所示), 回圈 4 張照片: 加載、調整大小并將每張照片附加到 inputImages, 使用以下命令為四個房屋影像、創建平鋪(蒙太奇): 左上角的浴室圖片, 右上角的臥室圖片, 右下角的正面視圖, 左下角的廚房, 將平鋪/蒙太奇 outputImage 附加到影像, 跳出回圈,我們以 NumPy 陣列的形式回傳所有影像,
定義模型
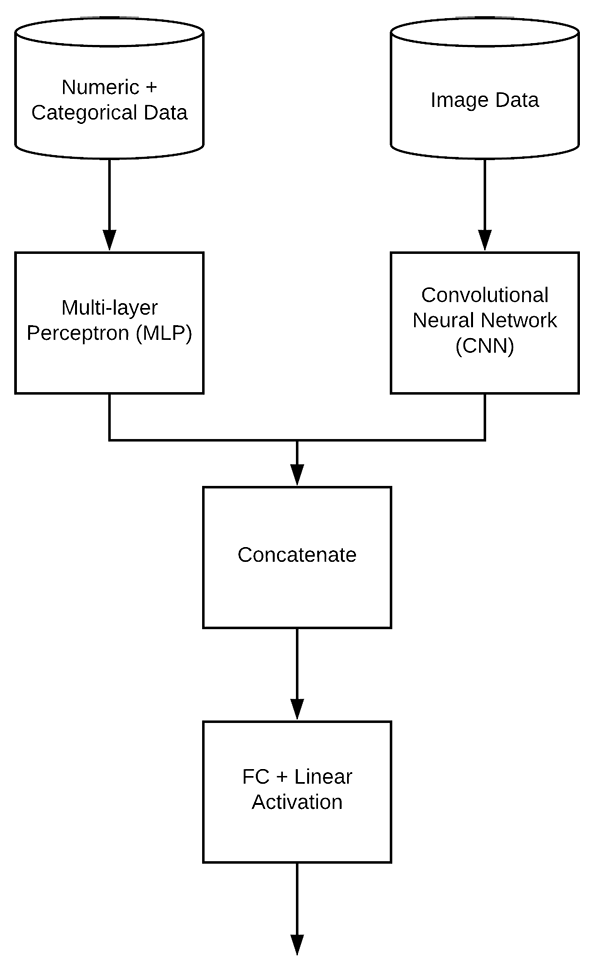
使用 Keras 的功能 API 構建的多輸入和混合資料網路,
為了構建多輸入網路,我們需要兩個分支: 第一個分支將是一個簡單的多層感知器 (MLP),旨在處理分類/數字輸入, 第二個分支將是一個卷積神經網路,用于對影像資料進行操作, 然后將這些分支連接在一起以形成最終的多輸入 Keras 模型, 我們將在下一節中構建最終的串聯多輸入模型——我們當前的任務是定義兩個分支,
打開models.py檔案并插入以下代碼:
# import the necessary packages
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import BatchNormalization
from tensorflow.keras.layers import Conv2D
from tensorflow.keras.layers import MaxPooling2D
from tensorflow.keras.layers import Activation
from tensorflow.keras.layers import Dropout
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Flatten
from tensorflow.keras.layers import Input
from tensorflow.keras.models import Model
def create_mlp(dim, regress=False):
# define our MLP network
model = Sequential()
model.add(Dense(8, input_dim=dim, activation="relu"))
model.add(Dense(4, activation="relu"))
# check to see if the regression node should be added
if regress:
model.add(Dense(1, activation="linear"))
# return our model
return model
匯入,您將在此腳本中看到每個匯入的函式/類,
分類/數值資料將由一個簡單的多層感知器 (MLP) 處理, MLP在create_mlp 定義, 在本系列的第一篇文章中詳細討論過,MLP 依賴于 Keras Sequential API,我們的 MLP 非常簡單,具有:
- 具有 ReLU 激活功能的全連接(密集)輸入層,
- 一個完全連接的隱藏層,也有 ReLU 激活,
- 最后,帶有線性激活的可選回歸輸出,
雖然我們在第一篇文章中使用了 MLP 的回歸輸出,但它不會在這個多輸入、混合資料網路中使用,您很快就會看到,我們將明確設定 regress=False,即使它也是默認值,回歸實際上稍后會在整個多輸入、混合資料網路的頭部執行(圖 7 的底部), 現在讓我們定義網路的右上角分支,一個 CNN:
def create_cnn(width, height, depth, filters=(16, 32, 64), regress=False):
# initialize the input shape and channel dimension, assuming
# TensorFlow/channels-last ordering
inputShape = (height, width, depth)
chanDim = -1
# define the model input
inputs = Input(shape=inputShape)
# loop over the number of filters
for (i, f) in enumerate(filters):
# if this is the first CONV layer then set the input
# appropriately
if i == 0:
x = inputs
# CONV => RELU => BN => POOL
x = Conv2D(f, (3, 3), padding="same")(x)
x = Activation("relu")(x)
x = BatchNormalization(axis=chanDim)(x)
x = MaxPooling2D(pool_size=(2, 2))(x)
create_cnn 函式處理影像資料并接受五個引數:
- width :輸入影像的寬度(以像素為單位),
- height :輸入影像有多少像素高,
- depth :輸入影像中的通道數, 對于RGB彩色影像,它是三個,
- 過濾器:逐漸變大的過濾器的元組,以便我們的網路可以學習更多可區分的特征,
- regress :一個布林值,指示是否將完全連接的線性激活層附加到 CNN 以用于回歸目的,
模型的輸入是通過 inputShape 定義的, 從那里我們開始回圈過濾器并創建一組 CONV => RELU > BN => POOL 層, 回圈的每次迭代都會附加這些層, 如果您不熟悉,請務必查看使用 Python 進行計算機視覺深度學習入門包中的第 11 章,以獲取有關這些層型別的更多資訊,
讓我們完成構建我們網路的 CNN 分支:
# flatten the volume, then FC => RELU => BN => DROPOUT
x = Flatten()(x)
x = Dense(16)(x)
x = Activation("relu")(x)
x = BatchNormalization(axis=chanDim)(x)
x = Dropout(0.5)(x)
# apply another FC layer, this one to match the number of nodes
# coming out of the MLP
x = Dense(4)(x)
x = Activation("relu")(x)
# check to see if the regression node should be added
if regress:
x = Dense(1, activation="linear")(x)
# construct the CNN
model = Model(inputs, x)
# return the CNN
return model
我們展平下一層,然后添加一個帶有 BatchNormalization 和 Dropout 的全連接層,
應用另一個全連接層來匹配來自多層感知器的四個節點, 匹配節點的數量不是必需的,但它確實有助于平衡分支,
檢查是否應附加回歸節點; 然后相應地添加它, 同樣,我們也不會在這個分支的末尾進行回歸, 回歸將在多輸入、混合資料網路的頭部執行(圖 7 的最底部),
最后,模型是根據我們的輸入和我們組裝在一起的所有層構建的x
, 然后我們可以將 CNN 分支回傳給呼叫函式, 現在我們已經定義了多輸入 Keras 模型的兩個分支,讓我們學習如何組合它們!
使用 Keras 進行多輸入
我們現在準備構建能夠處理多個輸入和混合資料的最終 Keras 模型, 這是分支合并的地方,也是“魔法”最終發生的地方,訓練也將在此腳本中進行, 創建一個名為 mix_training.py 的新檔案,打開它,并插入以下代碼:
# import the necessary packages
from pyimagesearch import datasets
from pyimagesearch import models
from sklearn.model_selection import train_test_split
from tensorflow.keras.layers import Dense
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.layers import concatenate
import numpy as np
import argparse
import locale
import os
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--dataset", type=str, required=True,
help="path to input dataset of house images")
args = vars(ap.parse_args())
首先處理我們的匯入和命令列引數, 值得注意的進口包括:
- 資料集:我們三個方便的函式,用于加載/處理 CSV 資料和加載/預處理房屋資料集中的房屋照片,
- 模型:我們的 MLP 和 CNN 輸入分支,它們將用作我們的多輸入混合資料,
- train_test_split :一個 scikit-learn 函式,用于構建我們的訓練/測驗資料拆分,
- concatenate :一個特殊的 Keras 函式,它將接受多個輸入,
- argparse :處理決議命令列引數,
加載數值/分類資料和影像資料:
# construct the path to the input .txt file that contains information
# on each house in the dataset and then load the dataset
print("[INFO] loading house attributes...")
inputPath = os.path.sep.join([args["dataset"], "HousesInfo.txt"])
df = datasets.load_house_attributes(inputPath)
# load the house images and then scale the pixel intensities to the
# range [0, 1]
print("[INFO] loading house images...")
images = datasets.load_house_images(df, args["dataset"])
images = images / 255.0
在這里,我們將 House Prices 資料集加載為 Pandas 資料,
然后我們加載了我們的影像并將它們縮放到范圍 [0, 1],
# partition the data into training and testing splits using 75% of
# the data for training and the remaining 25% for testing
print("[INFO] processing data...")
split = train_test_split(df, images, test_size=0.25, random_state=42)
(trainAttrX, testAttrX, trainImagesX, testImagesX) = split
# find the largest house price in the training set and use it to
# scale our house prices to the range [0, 1] (will lead to better
# training and convergence)
maxPrice = trainAttrX["price"].max()
trainY = trainAttrX["price"] / maxPrice
testY = testAttrX["price"] / maxPrice
# process the house attributes data by performing min-max scaling
# on continuous features, one-hot encoding on categorical features,
# and then finally concatenating them together
(trainAttrX, testAttrX) = datasets.process_house_attributes(df,
trainAttrX, testAttrX)
4:1的比例切分訓練集和測驗集, 從訓練集中找到 maxPrice 并相應地縮放訓練和測驗資料, 將定價資料設定在 [0, 1] 范圍內會導致更好的訓練和收斂,
最后,我們繼續通過對連續特征執行最小-最大縮放和對分類特征執行單熱編碼來處理我們的房屋屬性, process_house_attributes 函式處理這些操作并將連續特征和分類特征連接在一起,回傳結果,
連接網路分支完成多輸入 Keras 網路模型:
# create the MLP and CNN models
mlp = models.create_mlp(trainAttrX.shape[1], regress=False)
cnn = models.create_cnn(64, 64, 3, regress=False)
# create the input to our final set of layers as the *output* of both
# the MLP and CNN
combinedInput = concatenate([mlp.output, cnn.output])
# our final FC layer head will have two dense layers, the final one
# being our regression head
x = Dense(4, activation="relu")(combinedInput)
x = Dense(1, activation="linear")(x)
# our final model will accept categorical/numerical data on the MLP
# input and images on the CNN input, outputting a single value (the
# predicted price of the house)
model = Model(inputs=[mlp.input, cnn.input], outputs=x)
創建mlp 和 cnn 模型,請注意,regress=False,
然后我們將連接 mlp.output 和 cnn.output,我稱其為我們的組合輸入,因為它是網路其余部分的輸入(從圖 3 中,這是兩個分支聚集在一起的 concatenate_1 ), 網路中最后一層的組合輸入基于 MLP 和 CNN 分支的 8-4-1 FC 層的輸出(因為 2 個分支中的每一個都輸出一個 4-dim FC 層,然后我們將它們連接起來以創建一個 8 維向量),
我們將具有四個神經元的全連接層添加到組合輸入, 然后我們添加我們的“線性”激活回歸頭,其輸出是預測價格, 我們的模型使用兩個分支的輸入作為我們的多輸入和最終的一組層 x 作為輸出定義, 讓我們繼續編譯、訓練和評估我們新形成的模型:
# compile the model using mean absolute percentage error as our loss,
# implying that we seek to minimize the absolute percentage difference
# between our price *predictions* and the *actual prices*
opt = Adam(lr=1e-3, decay=1e-3 / 200)
model.compile(loss="mean_absolute_percentage_error", optimizer=opt)
# train the model
print("[INFO] training model...")
model.fit(
x=[trainAttrX, trainImagesX], y=trainY,
validation_data=([testAttrX, testImagesX], testY),
epochs=200, batch_size=8)
# make predictions on the testing data
print("[INFO] predicting house prices...")
preds = model.predict([testAttrX, testImagesX])
我們的模型是使用“mean_absolute_percentage_error”損失和具有學習率衰減的 Adam 優化器,
訓練,然后呼叫 model.predict 允許我們獲取用于評估模型的預測, 現在讓我們進行評估:
# compute the difference between the *predicted* house prices and the
# *actual* house prices, then compute the percentage difference and
# the absolute percentage difference
diff = preds.flatten() - testY
percentDiff = (diff / testY) * 100
absPercentDiff = np.abs(percentDiff)
# compute the mean and standard deviation of the absolute percentage
# difference
mean = np.mean(absPercentDiff)
std = np.std(absPercentDiff)
# finally, show some statistics on our model
locale.setlocale(locale.LC_ALL, "en_US.UTF-8")
print("[INFO] avg. house price: {}, std house price: {}".format(
locale.currency(df["price"].mean(), grouping=True),
locale.currency(df["price"].std(), grouping=True)))
print("[INFO] mean: {:.2f}%, std: {:.2f}%".format(mean, std))
為了評估我們的模型,我們計算了絕對百分比差異并使用它來推匯出我們的最終指標, 這些指標(價格平均值、價格標準偏差和絕對百分比差異的平均值 + 標準偏差)以正確的貨幣區域設定格式列印到終端,
多輸入和混合資料結果

最后,我們準備好在我們的混合資料上訓練我們的多輸入網路!
打開一個終端并執行以下命令以開始訓練網路:
$ python mixed_training.py --dataset HousesDataset/HousesDataset/
[INFO] loading house attributes...
[INFO] loading house images...
[INFO] processing data...
[INFO] training model...
Epoch 1/200
34/34 [==============================] - 0s 10ms/step - loss: 972.0082 - val_loss: 137.5819
Epoch 2/200
34/34 [==============================] - 0s 4ms/step - loss: 708.1639 - val_loss: 873.5765
Epoch 3/200
34/34 [==============================] - 0s 5ms/step - loss: 551.8876 - val_loss: 1078.9347
Epoch 4/200
34/34 [==============================] - 0s 3ms/step - loss: 347.1892 - val_loss: 888.7679
Epoch 5/200
34/34 [==============================] - 0s 4ms/step - loss: 258.7427 - val_loss: 986.9370
Epoch 6/200
34/34 [==============================] - 0s 3ms/step - loss: 217.5041 - val_loss: 665.0192
Epoch 7/200
34/34 [==============================] - 0s 3ms/step - loss: 175.1175 - val_loss: 435.5834
Epoch 8/200
34/34 [==============================] - 0s 5ms/step - loss: 156.7351 - val_loss: 465.2547
Epoch 9/200
34/34 [==============================] - 0s 4ms/step - loss: 133.5550 - val_loss: 718.9653
Epoch 10/200
34/34 [==============================] - 0s 3ms/step - loss: 115.4481 - val_loss: 880.0882
...
Epoch 191/200
34/34 [==============================] - 0s 4ms/step - loss: 23.4761 - val_loss: 23.4792
Epoch 192/200
34/34 [==============================] - 0s 5ms/step - loss: 21.5748 - val_loss: 22.8284
Epoch 193/200
34/34 [==============================] - 0s 3ms/step - loss: 21.7873 - val_loss: 23.2362
Epoch 194/200
34/34 [==============================] - 0s 6ms/step - loss: 22.2006 - val_loss: 24.4601
Epoch 195/200
34/34 [==============================] - 0s 3ms/step - loss: 22.1863 - val_loss: 23.8873
Epoch 196/200
34/34 [==============================] - 0s 4ms/step - loss: 23.6857 - val_loss: 1149.7415
Epoch 197/200
34/34 [==============================] - 0s 4ms/step - loss: 23.0267 - val_loss: 86.4044
Epoch 198/200
34/34 [==============================] - 0s 4ms/step - loss: 22.7724 - val_loss: 29.4979
Epoch 199/200
34/34 [==============================] - 0s 3ms/step - loss: 23.1597 - val_loss: 23.2382
Epoch 200/200
34/34 [==============================] - 0s 3ms/step - loss: 21.9746 - val_loss: 27.5241
[INFO] predicting house prices...
[INFO] avg. house price: $533,388.27, std house price: $493,403.08
[INFO] mean: 27.52%, std: 22.19%
我們的平均絕對百分比誤差開始時非常高,但在整個訓練程序中繼續下降, 在訓練結束時,我們在測驗集上獲得了 27.52% 的平均絕對百分比誤差,這意味著,平均而言,我們的網路在其房價預測中將降低約 26-27%,
總結
在本教程中,您學習了如何定義能夠接受多個輸入的 Keras 網路,
您還學習了如何使用 Keras 處理混合資料,
為了實作這些目標,我們定義了一個能夠接受的多輸入神經網路:
- 數值資料
- 分類資料
- 影像資料
在訓練之前,數值資料被最小-最大縮放到范圍 [0, 1],我們的分類資料是單熱編碼的(同時確保生成的整數向量在 [0, 1] 范圍內),
然后將數值和分類資料連接成一個單一的特征向量,以形成 Keras 網路的第一個輸入, 我們的影像資料也被縮放到 [0, 1] 范圍內——這些資料作為 Keras 網路的第二個輸入,
該模型的一個分支包括嚴格完全連接的層(用于連接數值和分類資料),而多輸入模型的第二個分支本質上是一個小型卷積神經網路,
兩個分支的輸出被組合在一起,并定義了一個單一的輸出(回歸預測),
通過這種方式,我們能夠端到端地訓練我們的多輸入網路,從而導致準確性幾乎與單獨的一個輸入一樣好,
代碼復現
KerasMultipleInputsandMixedData.zip-深度學習檔案類資源-CSDN文庫
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/348548.html
標籤:AI
上一篇:【slowfast 損失函式改進】深度學習網路通用改進方案:slowfast的損失函式(使用focal loss解決不平衡資料)改進