前言
生活在一個資訊大爆炸的時代,每天都會接收到大量繽紛繁雜的資訊,包括各種影像、視頻、語音等等的訊息種類,那么如何能夠快速的篩選資訊從中獲得自己有用或者感興趣的知識呢?針對最復雜的視頻這一種類,我們可以通過使用Azure的認知服務,通過視頻提取音頻、語音轉文本、文本翻譯、文本摘要生成等多項技術,實作視頻理解,
輸入視頻:
“元宇宙”場景會是怎樣?扎克伯格演示“元宇宙”的社交場景
輸出視頻摘要:
想象一下,你戴上眼鏡或耳機,立刻就進入了你的家庭空間,作為虛擬重建的物體家庭的一部分,它有著只有虛擬才能實作的東西,它有著令人難以置信的令人振奮的視角,讓你看到最美的東西,馬克,怎么了?有一位藝術家在四處走動,所以幫助人們找到隱藏AR作品,和3D街頭藝術,
一、Azure服務開通
最近CSDN開展了《0元試用微軟 Azure人工智能認知服務,精美禮品大放送》,通過添加客服小姐姐申請企業試用的賬號,可以白嫖Azure 認知服務,個人的話還得需要visa卡,
申請成功后,可以免費體驗Azure人工智能認知服務,包括語音轉文本、文本轉語音、語音翻譯、文本分析、文本翻譯、語言理解等功能,
下面我們以語音轉文本功能為例子,看看如何試用Azure認知服務吧,首先我們進入:https://portal.azure.cn/并登錄,
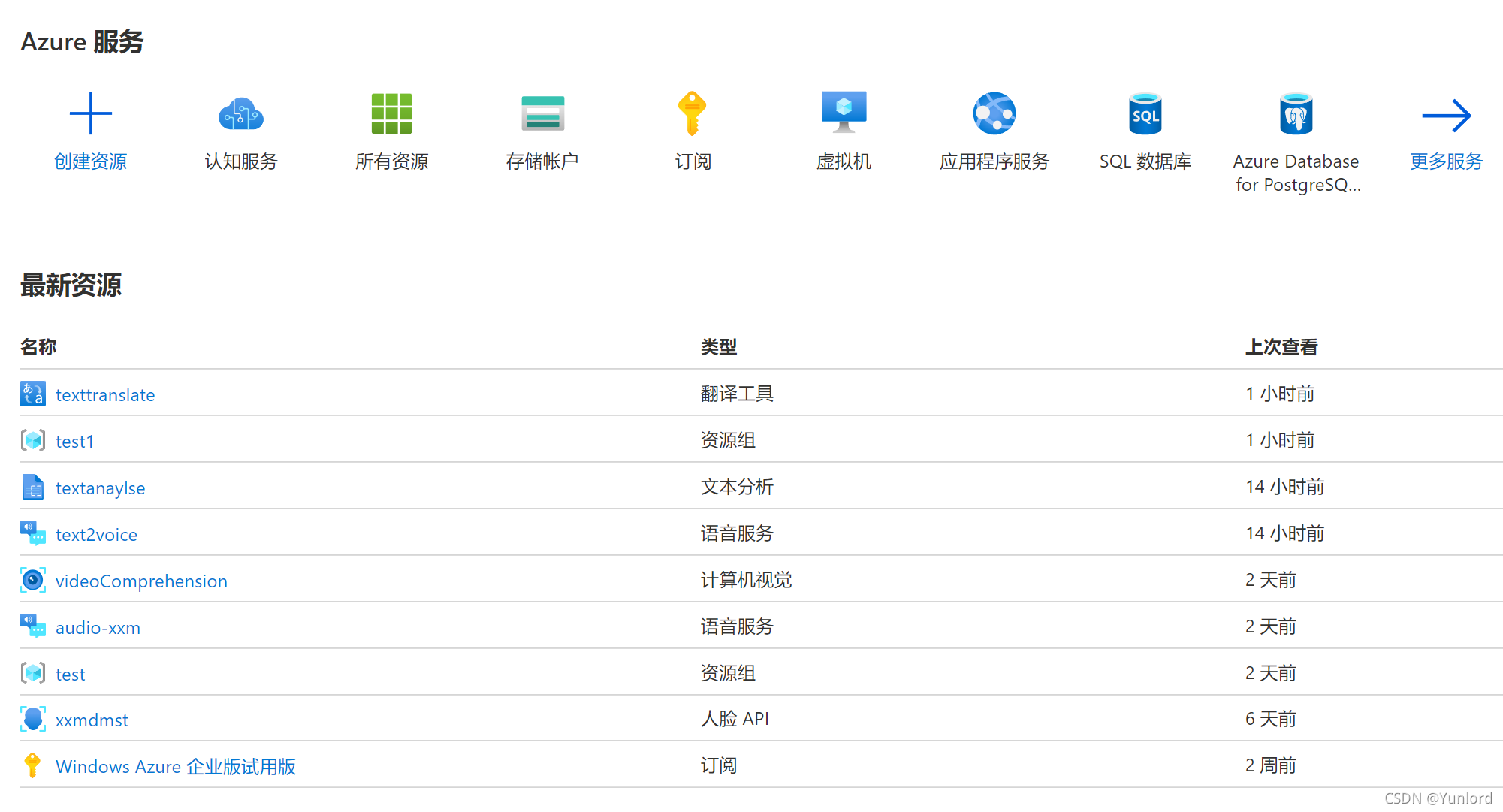
選擇認知服務
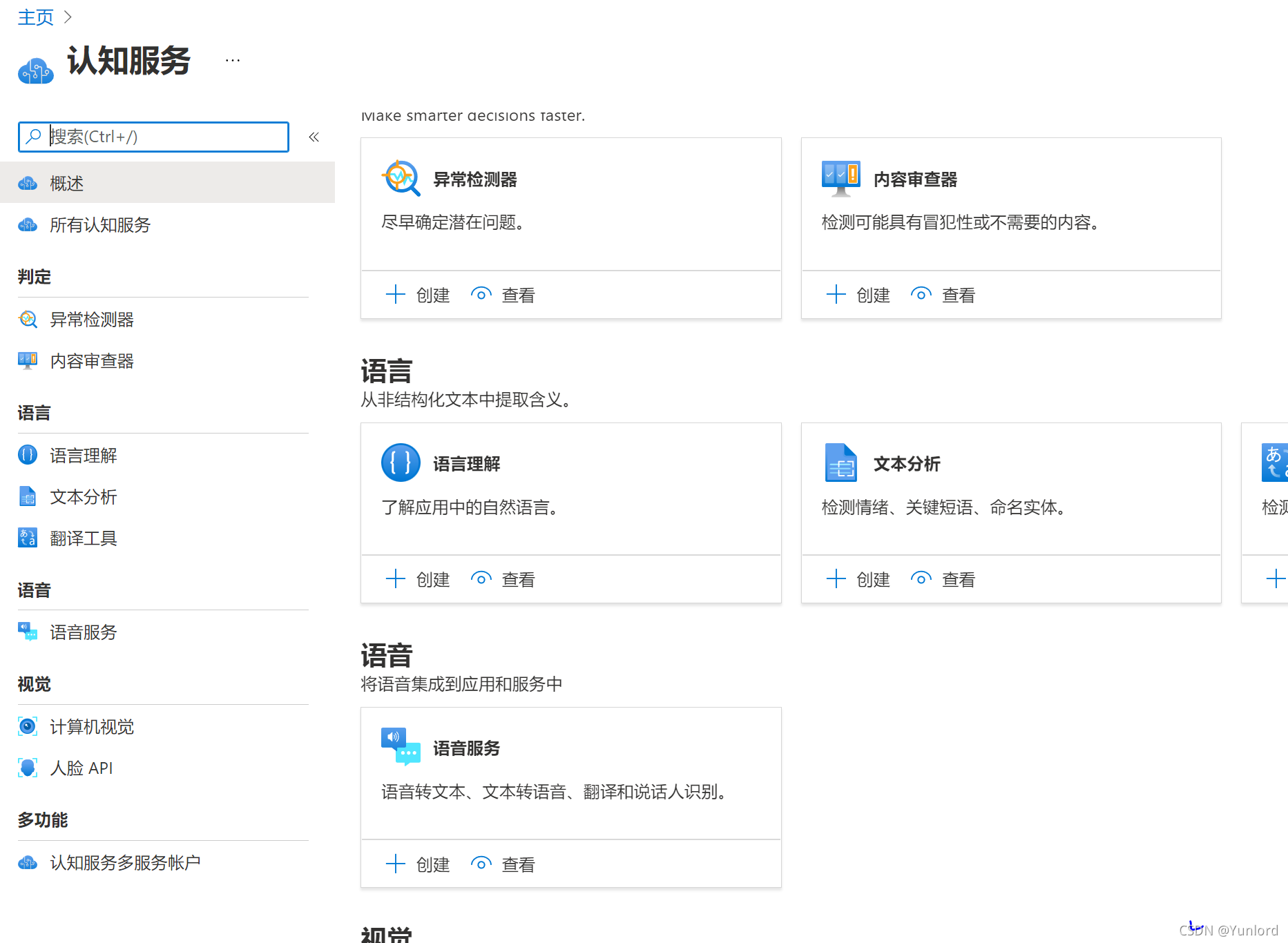
選擇對應的服務進行創建,比如語音轉文本,則點擊語音服務創建,
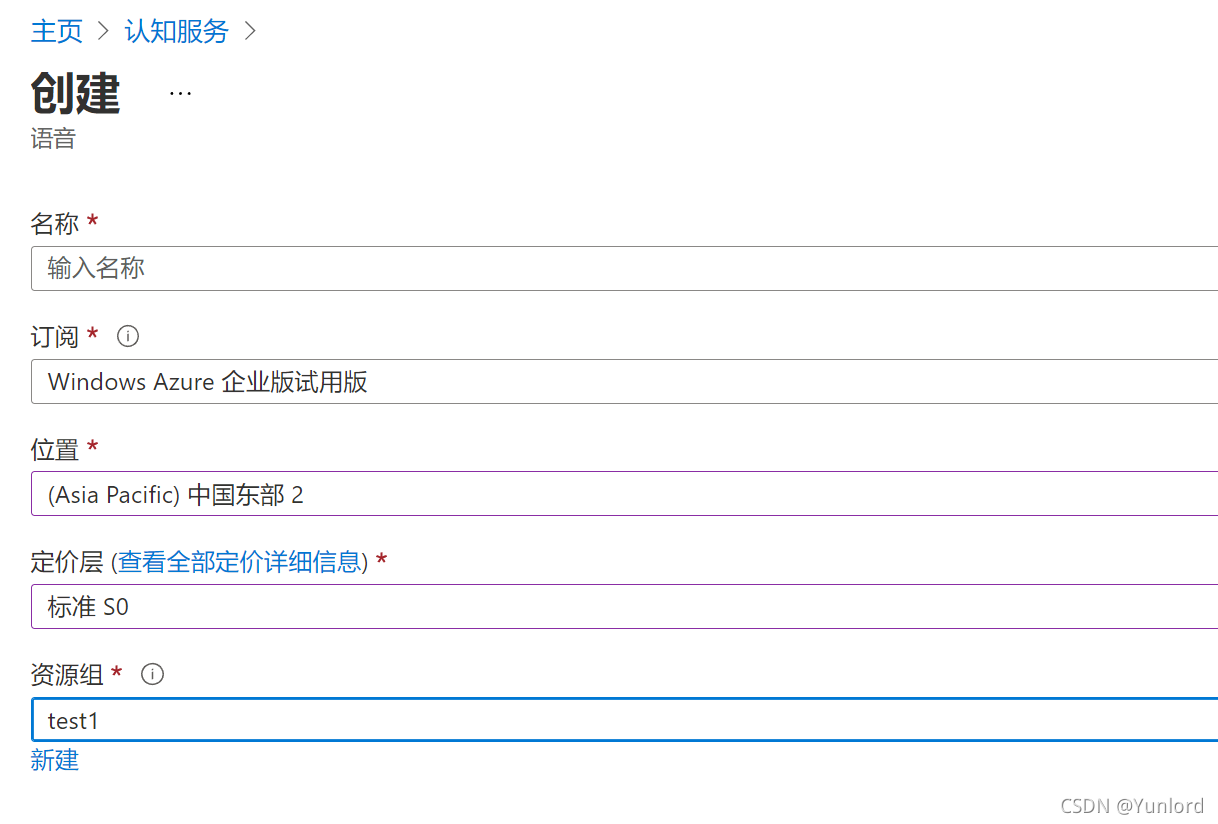
點擊頁面最下方的創建按鈕,就等待資源配置好,
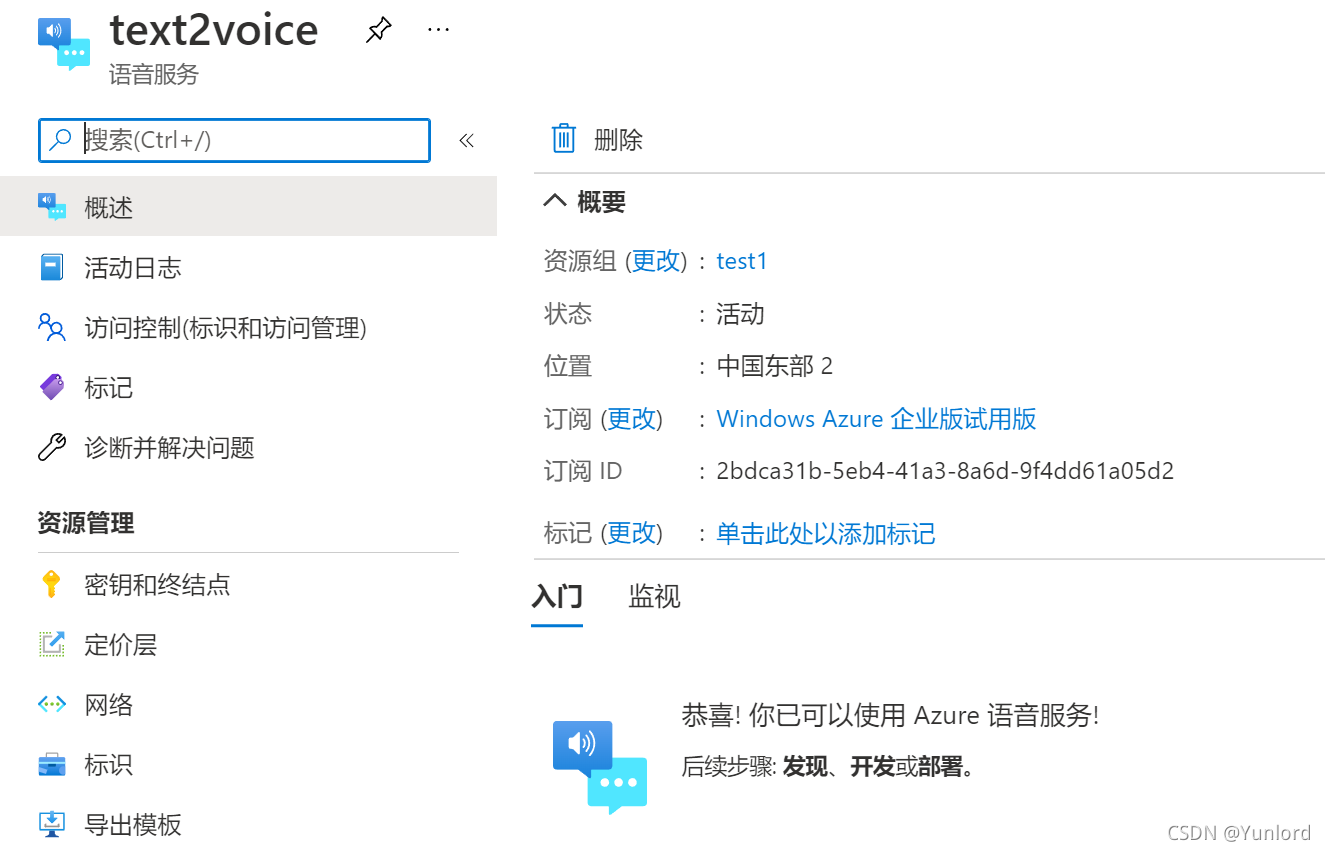 查看密鑰和終結點,
查看密鑰和終結點,
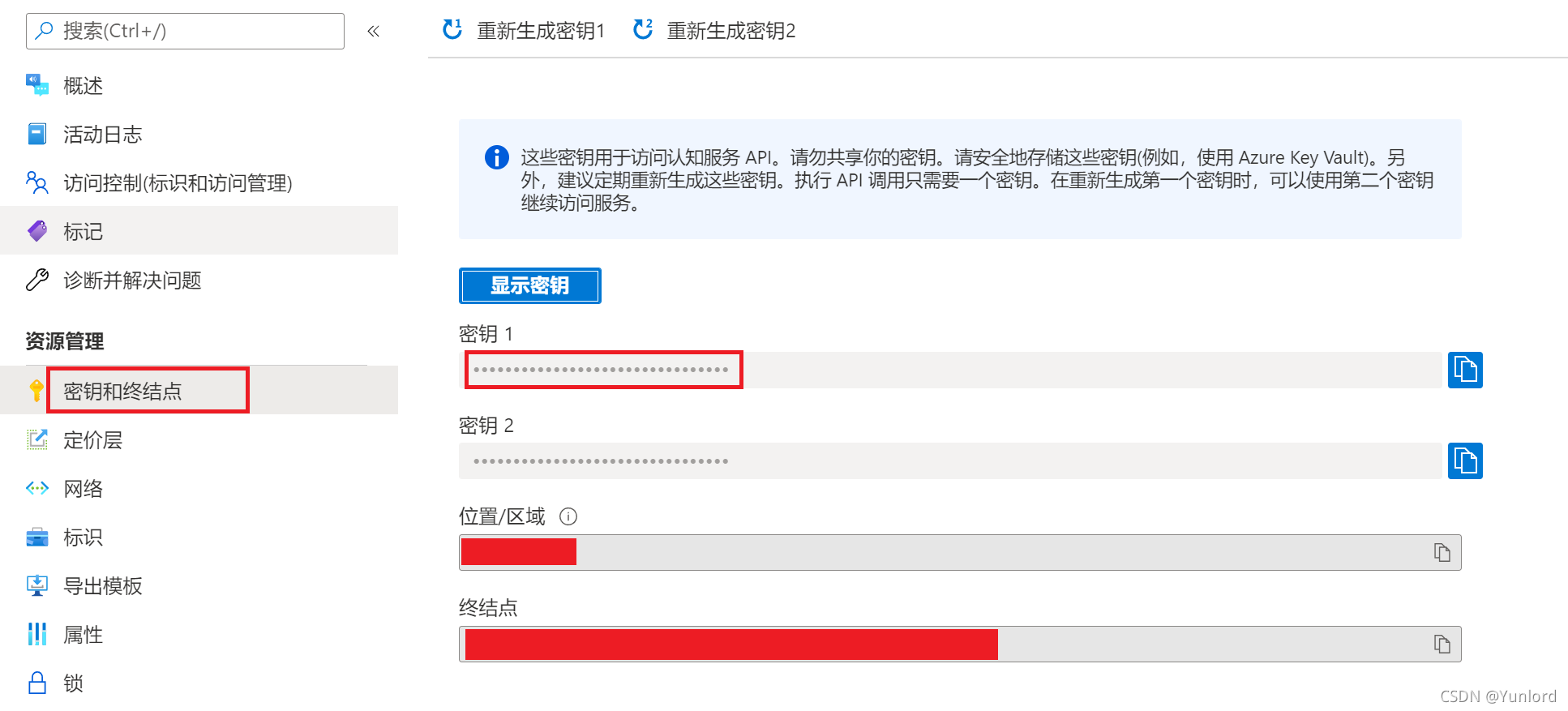
有兩個密鑰任選一個即可,位置/區域也需要記錄下來,后面我們的程式就需要通過密鑰和位置來呼叫,
之后下文涉及到的文本翻譯、文本摘要生成等服務開通也按以上步驟進行獲得密鑰以及位置就可以了,
二、核心功能實作
1.視頻轉音頻
安裝moviepy庫:
pip install moviepy提取音頻:
from moviepy.editor import AudioFileClip
my_audio_clip = AudioFileClip("data_dst.mp4")
my_audio_clip.write_audiofile("data_dst.wav")生成wav格式音頻:


2.語音轉文本
參考Azure 認知服務檔案:語音轉文本入門
首先安裝和匯入語音 SDK:
pip install azure-cognitiveservices-speech
首先從檔案識別語音轉文本:
import azure.cognitiveservices.speech as speechsdk
def from_file():
speech_config = speechsdk.SpeechConfig(subscription="<paste-your-speech-key-here>", region="<paste-your-speech-location/region-here>")
audio_input = speechsdk.AudioConfig(filename="your_file_name.wav")
speech_recognizer = speechsdk.SpeechRecognizer(speech_config=speech_config, audio_config=audio_input)
result = speech_recognizer.recognize_once_async().get()
print(result.text)
from_file()

3.文本摘要生成
參考Azure 認知服務檔案:文本分析快速入門
安裝 Python 后,可使用以下命令安裝客戶端庫:
pip install azure-ai-textanalytics==5.2.0b1
可以使用文本分析來匯總大型文本區塊, 創建一個名為 summarization_example() 的新函式,該函式采用客戶端作為引數,然后呼叫 begin_analyze_actions() 函式, 結果將是一個回圈操作,將輪詢該操作以獲得結果,
from azure.ai.textanalytics import TextAnalyticsClient
from azure.core.credentials import AzureKeyCredential
key = ""
endpoint = ""
def authenticate_client():
ta_credential = AzureKeyCredential(key)
text_analytics_client = TextAnalyticsClient(
endpoint=endpoint,
credential=ta_credential)
return text_analytics_client
client = authenticate_client()
def sample_extractive_summarization(client):
from azure.core.credentials import AzureKeyCredential
from azure.ai.textanalytics import (
TextAnalyticsClient,
ExtractSummaryAction
)
document = [
"The extractive summarization feature in Text Analytics uses natural language processing techniques to locate key sentences in an unstructured text document. "
"These sentences collectively convey the main idea of the document. This feature is provided as an API for developers. "
"They can use it to build intelligent solutions based on the relevant information extracted to support various use cases. "
"In the public preview, extractive summarization supports several languages. It is based on pretrained multilingual transformer models, part of our quest for holistic representations. "
"It draws its strength from transfer learning across monolingual and harness the shared nature of languages to produce models of improved quality and efficiency. "
]
poller = client.begin_analyze_actions(
document,
actions=[
ExtractSummaryAction(MaxSentenceCount=4)
],
)
document_results = poller.result()
for result in document_results:
extract_summary_result = result[0] # first document, first result
if extract_summary_result.is_error:
print("...Is an error with code '{}' and message '{}'".format(
extract_summary_result.code, extract_summary_result.message
))
else:
print("Summary extracted: \n{}".format(
" ".join([sentence.text for sentence in extract_summary_result.sentences]))
)
sample_extractive_summarization(client)其中檔案內容為:
"The extractive summarization feature in Text Analytics uses natural language processing techniques to locate key sentences in an unstructured text document. "
"These sentences collectively convey the main idea of the document. This feature is provided as an API for developers. "
"They can use it to build intelligent solutions based on the relevant information extracted to support various use cases. "
"In the public preview, extractive summarization supports several languages. It is based on pretrained multilingual transformer models, part of our quest for holistic representations. "
"It draws its strength from transfer learning across monolingual and harness the shared nature of languages to produce models of improved quality and efficiency. "
“文本分析中的提取摘要功能使用自然語言處理技術定位非結構化文本檔案中的關鍵句子,”
“這些句子共同傳達了檔案的主要思想,此功能作為API提供給開發人員,”
“他們可以使用它根據提取的相關資訊構建智能解決方案,以支持各種用例,”
“在公開預覽中,摘錄摘要支持多種語言,它基于預訓練的多語言轉換器模型,這是我們尋求整體表示的一部分,”
“它從跨單語的遷移學習中汲取力量,并利用語言的共享性來制作質量和效率更高的模型,”
摘要結果為:
The extractive summarization feature in Text Analytics uses natural language processing techniques to locate key sentences in an unstructured text document. This feature is provided as an API for developers. They can use it to build intelligent solutions based on the relevant information extracted to support various use cases.
文本分析中的提取摘要功能使用自然語言處理技術定位非結構化文本檔案中的關鍵句子,此功能作為API提供給開發人員,他們可以使用它根據提取的相關資訊構建智能解決方案,以支持各種用例,
4.文本翻譯
參考Azure 認知服務檔案:文本翻譯快速入門
import requests, uuid, json
# Add your subscription key and endpoint
subscription_key = "YOUR_SUBSCRIPTION_KEY"
endpoint = "https://api.translator.azure.cn"
# Add your location, also known as region. The default is global.
# This is required if using a Cognitive Services resource.
location = "YOUR_RESOURCE_LOCATION"
path = '/translate'
constructed_url = endpoint + path
params = {
'api-version': '3.0',
'from': 'en',
'to': ['zh']
}
constructed_url = endpoint + path
headers = {
'Ocp-Apim-Subscription-Key': subscription_key,
'Ocp-Apim-Subscription-Region': location,
'Content-type': 'application/json',
'X-ClientTraceId': str(uuid.uuid4())
}
# You can pass more than one object in body.
body = [{
'text': ''The extractive summarization feature in Text Analytics uses natural language processing techniques to locate key sentences in an unstructured text document. This feature is provided as an API for developers. They can use it to build intelligent solutions based on the relevant information extracted to support various use cases.'
}]
request = requests.post(constructed_url, params=params, headers=headers, json=body)
response = request.json()
print(json.dumps(response, sort_keys=True, ensure_ascii=False, indent=4, separators=(',', ': ')))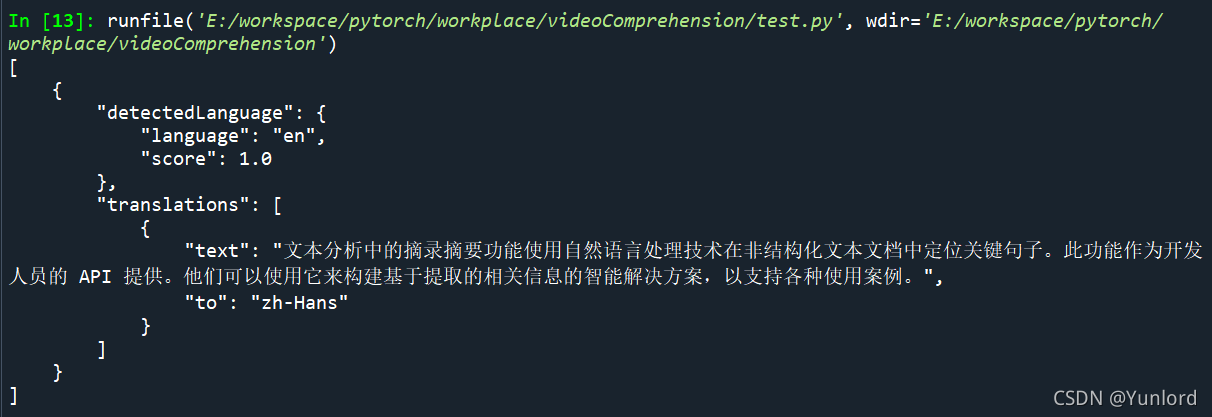
原文:
The extractive summarization feature in Text Analytics uses natural language processing techniques to locate key sentences in an unstructured text document. This feature is provided as an API for developers. They can use it to build intelligent solutions based on the relevant information extracted to support various use cases.
翻譯結果:
文本分析中的摘錄摘要功能使用自然語言處理技術在非結構化文本檔案中定位關鍵句子,此功能作為開發人員的 API 提供,他們可以使用它來構建基于提取的相關資訊的智能解決方案,以支持各種使用案例,
三、搭建框架
開發流程示意圖:
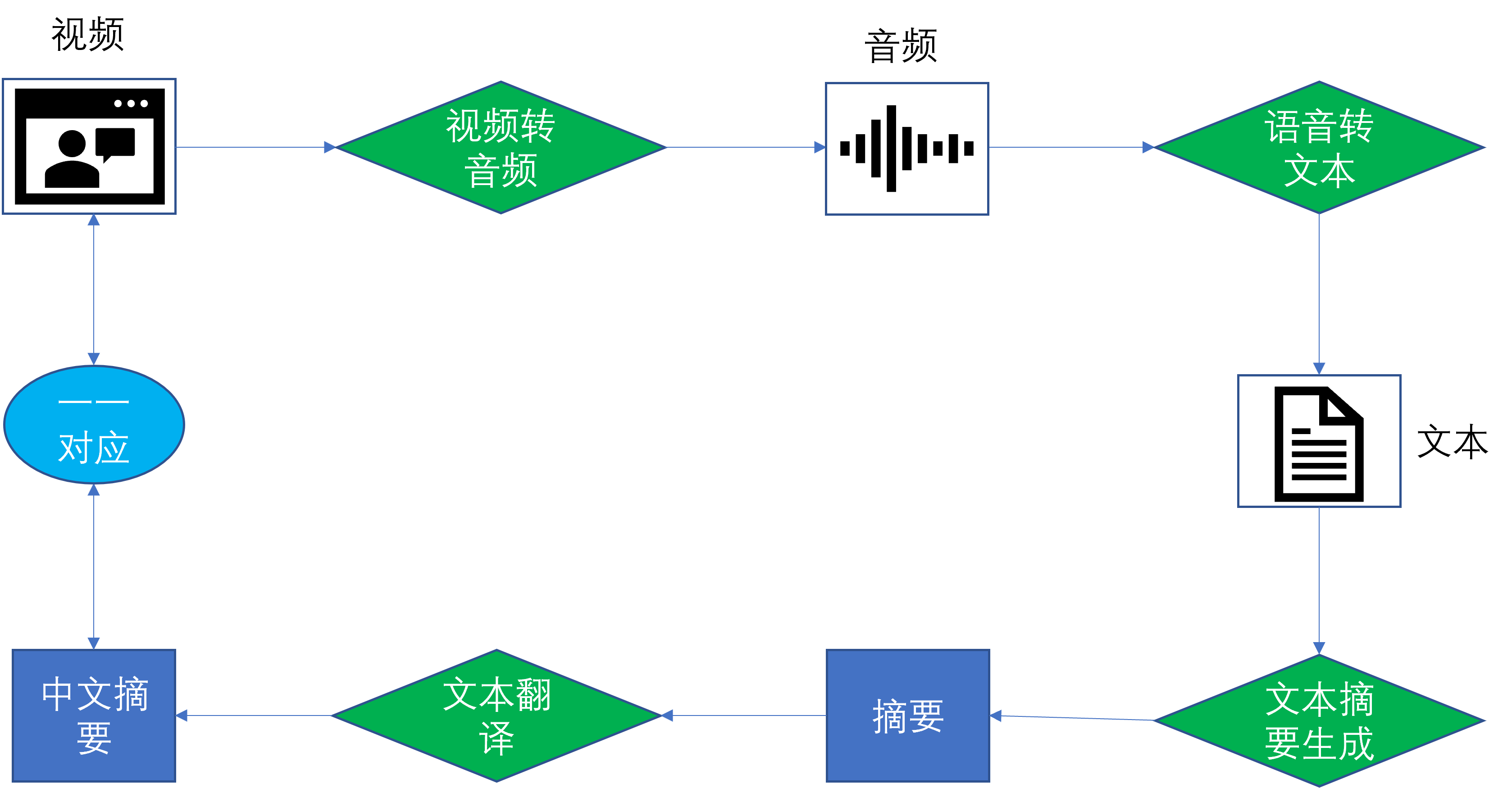
整體的流程如上圖所示:
將視頻轉成音頻后輸入到語音轉文本服務中,輸出的文本資訊,輸入到文本摘要生成服務中,輸入摘要資訊,再輸入到文本翻譯服務中,翻譯成中文,最后就得到對應視頻的中文摘要,幫助快速理解視頻資訊,
代碼實作:
同樣分成了四個模塊:
視頻轉音頻 video2audio() :
def video2audio(path):
my_audio_clip = AudioFileClip(path)
output_path=path[:-3]+"wav"
my_audio_clip.write_audiofile(output_path)
print("第一步:視頻轉語音完成")
return output_path連續語音轉文本 continuous_recognition() :
def continuous_recognition(path):
audio_config = speechsdk.audio.AudioConfig(filename=path)
speech_config = speechsdk.SpeechConfig()
speech_recognizer = speechsdk.SpeechRecognizer(speech_config=speech_config, audio_config=audio_config)
done = False
def stop_cb(evt):
print('CLOSING on {}'.format(evt))
speech_recognizer.stop_continuous_recognition()
nonlocal done
done = True
text=[]
speech_recognizer.recognized.connect(lambda evt: text.append(evt.result.text))
speech_recognizer.session_started.connect(lambda evt: print('SESSION STARTED: {}'.format(evt['text'])))
speech_recognizer.session_stopped.connect(lambda evt: print('SESSION STOPPED {}'.format(evt)))
speech_recognizer.canceled.connect(lambda evt: print(summary))
speech_recognizer.session_stopped.connect(stop_cb)
speech_recognizer.canceled.connect(stop_cb)
speech_recognizer.start_continuous_recognition()
while not done:
time.sleep(.5)
print("第二步:語音轉文本完成")
print(text)
return text文本摘要生成 sample_extractive_summarization() :
def sample_extractive_summarization(client,text):
from azure.core.credentials import AzureKeyCredential
from azure.ai.textanalytics import (
TextAnalyticsClient,
ExtractSummaryAction
)
text="".join(text)
document = [text]
poller = client.begin_analyze_actions(
document,
actions=[
ExtractSummaryAction(MaxSentenceCount=4)
],
)
document_results = poller.result()
for result in document_results:
extract_summary_result = result[0] # first document, first result
if extract_summary_result.is_error:
summary=("...Is an error with code '{}' and message '{}'".format(
extract_summary_result.code, extract_summary_result.message
))
else:
print("第三步:文本摘要生成完成")
summary=("Summary extracted: \n{}".format(
" ".join([sentence.text for sentence in extract_summary_result.sentences]))
)
print(summary)
return summary文本翻譯 translate() :
def translate(text):
import requests, uuid, json
subscription_key =
endpoint =
location =
path = '/translate'
constructed_url = endpoint + path
params = {
'api-version': '3.0',
'to': ['zh']
}
constructed_url = endpoint + path
headers = {
'Ocp-Apim-Subscription-Key': subscription_key,
'Ocp-Apim-Subscription-Region': location,
'Content-type': 'application/json',
'X-ClientTraceId': str(uuid.uuid4())
}
# You can pass more than one object in body.
body = [{
'text':text
}]
request = requests.post(constructed_url, params=params, headers=headers, json=body)
response = request.json()
translate_text=response[0]['translations'][0]['text']
# translate_text=(json.dumps(response, sort_keys=True, ensure_ascii=False, indent=4, separators=(',', ': ')))
print('第四步:文本翻譯完成')
print(translate_text)
return translate_text最終輸出結果:
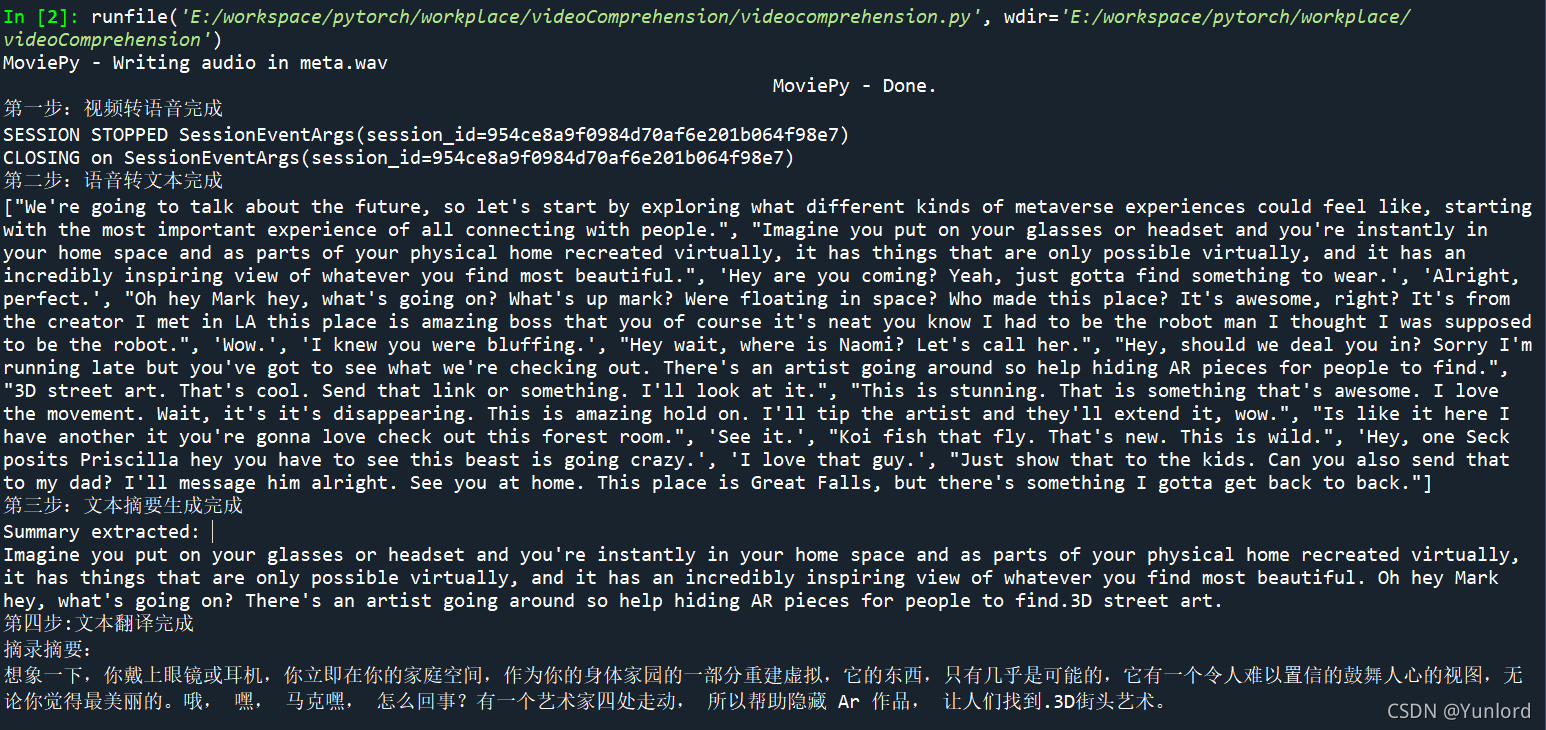 英文摘要結果:
英文摘要結果:
Imagine you put on your glasses or headset and you're instantly in your home space and as parts of your physical home recreated virtually, it has things that are only possible virtually, and it has an incredibly inspiring view of whatever you find most beautiful. Oh hey Mark hey, what's going on? There's an artist going around so help hiding AR pieces for people to find and 3D street art.
中文摘要結果:
想象一下,你戴上眼鏡或耳機,立刻就進入了你的家庭空間,作為虛擬重建的物體家庭的一部分,它有著只有虛擬才能實作的東西,它有著令人難以置信的令人振奮的視角,讓你看到最美的東西,馬克,怎么了?有一位藝術家在四處走動,所以幫助人們找到隱藏AR作品,和3D街頭藝術,
四、總結
在試用程序中,單項服務效果還行,但是其中的摘要生成和文本翻譯的準確度還是可以再次提高的,而且一開始使用語音轉文本功能只能翻譯十五秒,所以之后選擇了連續語音識別轉文本,才算是基本獲取了該視頻的所有語音,
總而來說,通過這次Azure認知服務免費試用活動,基本實作了預期設想的視頻語意理解功能,
尤其是近兩年隨著短視頻領域的火爆發展,圍繞短視頻的業務場景應用也在增長,工業界應用場景都對視頻內容理解提出了迫切的落地需求,本篇實作的視頻語意理解功能基本可以滿足以上需求,能夠實作個性化推薦以及用戶選擇建議,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/349755.html
標籤:其他