一、基礎搭建
1.1 使用連接工具連接比賽節點,更改本地源
??1.使用本地Windows操作機提供的Xshell或MobaXterm連接比賽平臺所提供的master,slave1,slave2三臺機器,并按照比賽平臺提供的linux用戶和密碼進行登錄,登錄成功后開始進行接下來的比賽,
??注意連接工具沒有在桌面上,點擊(或者鍵入)左下角“windows”,即可看到連接工具,
??同時可以使用以下命令進行修改主機名:
??hostnamectl set-hostname master(在master執行)
??立即生效:bash
??同理修改slave1和slave2的主機名:
??hostnamectl set-hostname slave1(在slave1執行)
??hostnamectl set-hostname slave2(在slave2執行)
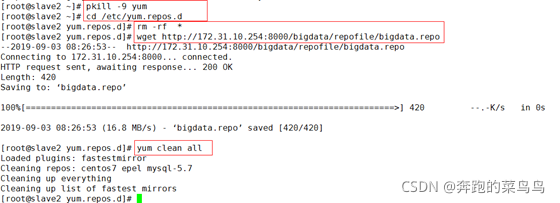
??2.配置本地源,通過比賽平臺提供源檔案下載路徑,將本地源檔案下載到/etc/yum.repos.d/目錄下(三臺機器都執行),
??●發信號給yum行程: pkill -9 yum
??●進入yum源組態檔: cd /etc/yum.repos.d
??●洗掉所有檔案:rm -rf *
??●下載yum源:
??wget http://172.16.47.240/bigdata/repofile/bigdata.repo
??wget http://172.31.10.254:8000/bigdata/repofile/bigdata.repo
??●清除YUM快取: yum clean all yum makecache
1.2 配置hosts檔案(三臺機器都執行)
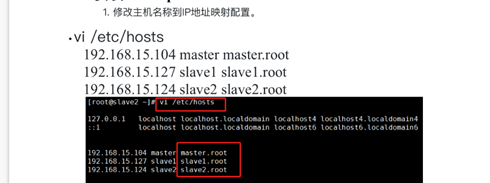
??可以通過ifconfig命令進行查看機器的ip地址或者直接輸入比賽平臺提供的ip地址,
查看節點地址之后將三個節點的ip地址以及其對應的名稱寫進hosts檔案,這里我們設定為master、slave1、slave2,注意保存退出,
??vim /etc/hosts(三臺機器都執行,然后內容見下圖)
1.3 關閉防火墻(三臺機器都執行)
??●關閉防火墻:systemctl stop firewalld
??●查看狀態:systemctl status firewalld
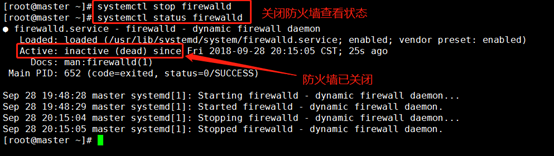
注意:當環境重置之后,防火墻會自動開啟,可以使用如下命令禁止開機自啟:
systemctl stop firewalld
systemctl status firewalld
systemctl disable firewalld
1.4 時間同步
●選擇時區(三臺執行):
tzselect
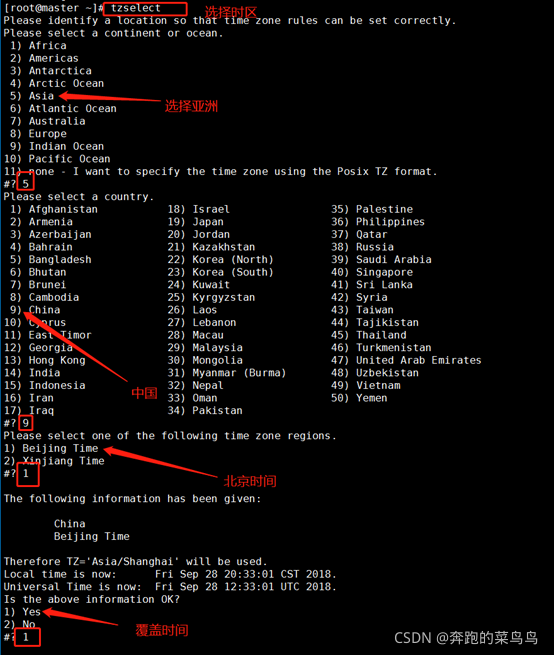
echo "TZ='Asia/Shanghai'; export TZ" >> /etc/profile && source /etc/profile
(三臺都執行)
●下載ntp(三臺機器都執行):
yum install -y ntp
master作為ntp服務器,修改ntp組態檔,(master上執行,注意空格問題)
vim /etc/ntp.conf
●注釋圖中的server0~3
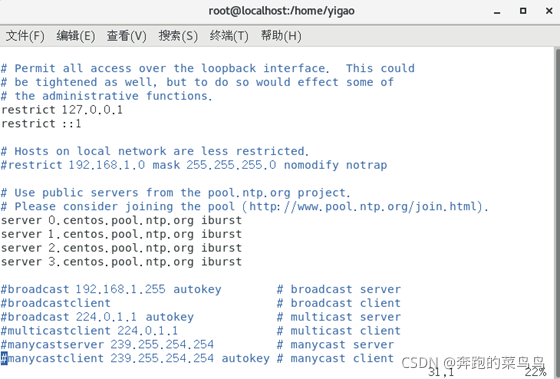
server 127.127.1.0 # local clock
fudge 127.127.1.0 stratum 10 #stratum設定為其它值也是可以的,其范圍為0~15
留下下圖中的內容就可以了:

??修改后注意保存退出,
??●重啟ntp服務,(master上執行)
/bin/systemctl restart ntpd.service
??●定時任務,早八晚五每半個小時同步一次,(slave1和2上使用此方法):
crontab -e
*/30 8-17 * * * /usr/sbin/ntpdate master
crontab -l
??●其他機器進行同步(在slave1,slave2中執行)
ntpdate master

1.5 配置ssh免密
1.配置ssh免密時得配置ssh自己,否則啟動Hadoop會輸入自己的密碼,3個節點要完成兩兩之間的免密,所以要執行3*3=9次的免密配置,在master上執行如下命令生成公私密鑰:(注意master上執行)
??ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
2.然后將master公鑰id_dsa復制到slave1進行公鑰認證,
??ssh-copy-id -i /root/.ssh/id_dsa.pub slave1
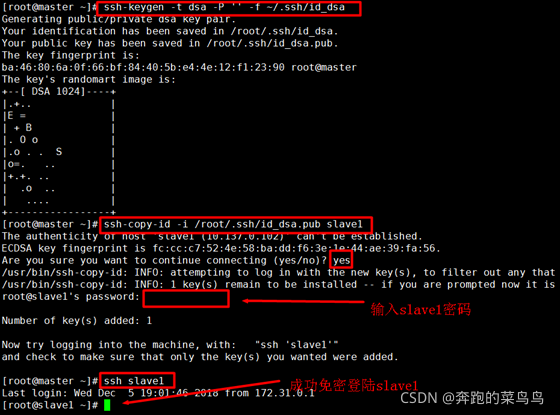
3.退出連接:exit
??同理可以將master公鑰復制到master、slave2進行公鑰認證,
??ssh-copy-id -i /root/.ssh/id_dsa.pub master
??ssh-copy-id -i /root/.ssh/id_dsa.pub slave2
??注意:以上只是master到slave1、slave2的免密,如果想配置其他(比如slave1到master、slave2)的免密,其命令類似,
二、安裝JDK
1.以下操作為先在master上操作,然后遠程復制到slave1和slave2,參賽選手僅供參考,首先在根目錄下建立作業路徑/usr/java,進入創建的java作業路徑
??mkdir -p /usr/java
??cd /usr/java
2.下載java安裝包(master上執行)
??wget http://172.16.47.240/bigdata/bigdata_tar/jdk-8u171-linux-x64.tar.gz
3.解壓(在master執行)
??tar -zxvf jdk-8u171-linux-x64.tar.gz -C /usr/java/
4.洗掉軟體包:
??rm -rf /usr/java/jdk-8u171-linux-x64.tar.gz
5.修改環境變數:vim /etc/profile(在master執行)
??注意:此時需要去slave1和slave2上配置java的環境變數,并使環境變數生效,
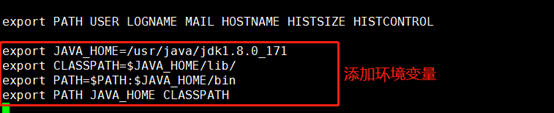
??添加內容如下:
export JAVA_HOME=/usr/java/jdk1.8.0_171
export CLASSPATH=$JAVA_HOME/lib/
export PATH=$PATH:$JAVA_HOME/bin
export PATH JAVA_HOME CLASSPATH
??生效環境變數:(在master執行)查看java版本:(在master執行)
??source /etc/profile
??java -version

6.在master中將JDK復制到slave1和slave2中,(在master執行)
??scp -r /usr/java root@slave1:/usr/
??scp -r /usr/java root@slave2:/usr/

三、安裝zookeeper
1.首先創建zookeeper的作業路徑:(在master上執行,然后遠程復制到其他節點)
??mkdir -p /usr/zookeeper
??cd /usr/zookeeper
??下載zookeeper
wget http://172.16.47.240/bigdata/bigdata_tar/zookeeper-3.4.10.tar.gz
??解壓到/usr/zookeeper
??tar -zxvf zookeeper-3.4.10.tar.gz -C /usr/zookeeper/
??洗掉軟體包
??rm -rf /usr/zookeeper/zookeeper-3.4.10.tar.gz
??在zookeeper的目錄中,創建配置中所需的zkdata和zkdatalog兩個檔案夾,(在master執行)
??cd /usr/zookeeper/zookeeper-3.4.10
??mkdir zkdata
??mkdir zkdatalog

2.組態檔zoo.cfg
??進入zookeeper組態檔夾conf,將zoo_sample.cfg檔案拷貝一份命名為zoo.cfg,Zookeeper 在啟動時會找這個檔案作為默認組態檔,
??cd /usr/zookeeper/zookeeper-3.4.10/conf/
??mv zoo_sample.cfg zoo.cfg
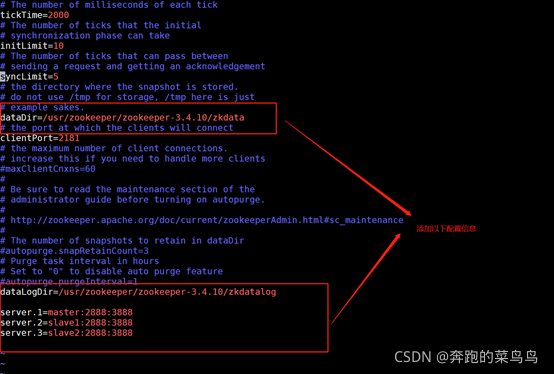
??對zoo.cfg檔案配置如下:(在master執行)
??vim zoo.cfg
??修改如下:全刪然后放入框內內容
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/usr/zookeeper/zookeeper-3.4.10/zkdata
clientPort=2181
dataLogDir=/usr/zookeeper/zookeeper-3.4.10/zkdatalog
server.1=master:2888:3888
server.2=slave1:2888:3888
server.3=slave2:2888:3888
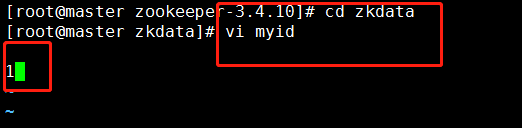
3.進入zkdata檔案夾,創建檔案myid,用于表示是幾號服務器,master主機中,設定服務器id為1,(集群中設定master為1號服務器,slave1為2號服務器,slave2為3號服務器)
??cd /usr/zookeeper/zookeeper-3.4.10/zkdata
??echo 1 > myid
??cat myid
(myid不加空行)
4.遠程復制分發安裝檔案,
??以上已經在主節點master上配置完成ZooKeeper,現在可以將該配置好的安裝檔案遠程拷貝到集群中的各個結點對應的目錄下:(在master執行)
??scp -r /usr/zookeeper root@slave1:/usr/
??scp -r /usr/zookeeper root@slave2:/usr/

5.設定myid,
??在我們配置的dataDir指定的目錄下面,創建一個myid檔案,里面內容為一個數字,用來標識當前主機,conf/zoo.cfg檔案中配置的server.X中X為什么數字,則myid檔案中就輸入這個數字,(在slave1和slave2中執行)
??cd /usr/zookeeper/zookeeper-3.4.10/zkdata
??echo 2 > myid
??cat myid
??echo 3 > myid
??cat myid
(myid不加空行)
實驗中設定slave1中為2;
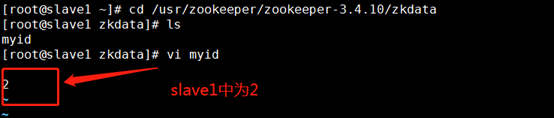
slave2中為3:

6.修改/etc/profile檔案,配置zookeeper環境變數,(三臺機器都執行),確保粘貼復制沒有后空格,否則source出錯,
vi /etc/profile
#set zookeeper environment
export ZOOKEEPER_HOME=/usr/zookeeper/zookeeper-3.4.10
PATH=$PATH:$ZOOKEEPER_HOME/bin
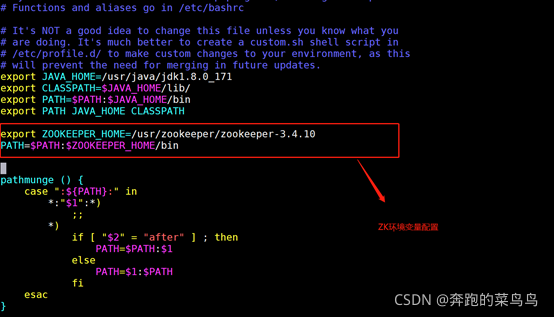
生效環境變數:source /etc/profile
7.啟動ZooKeeper集群,在ZooKeeper集群的每個結點上,執行啟動ZooKeeper服務的腳本,注意在zookeeper目錄下:(三臺機器都執行)
??回到上一層:cd ..
??開啟服務:bin/zkServer.sh start
??查看狀態:bin/zkServer.sh status
master節點狀態👇:

slave1節點狀態👇: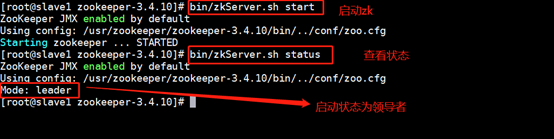
slave2節點狀態👇:
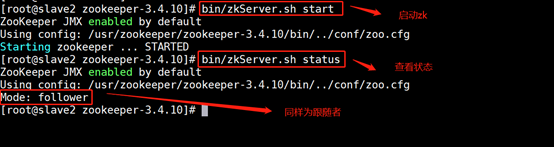
??通過上面狀態查詢結果可見,一個節點是Leader,其余的結點是Follower,至此,zookeeper安裝成功,
四、安裝hadoop
??以下步驟邏輯僅供選手參考:即hadoop安裝同樣在主節點master上進行配置操作,然后將檔案復制到到子節點slave1和slave2,
4.1解壓安裝包,配置環境變數
1.下載hadoop壓縮包,創建對應作業目錄/usr/hadoop,解壓hadoop到相應目錄,洗掉相應軟體包,
mkdir -p /usr/hadoop
cd /usr/hadoop
wget http://10.10.88.2:8000/bigdata/bigdata_tar/hadoop-2.7.3.tar.gz
tar -zxvf hadoop-2.7.3.tar.gz -C /usr/hadoop/
rm -rf /usr/hadoop/hadoop-2.7.3.tar.gz
2.添加hadoop環境變數(三臺機器執行)
vim /etc/profile
添加如下內容:
# HADOOP
export HADOOP_HOME=/usr/hadoop/hadoop-2.7.3
export CLASSPATH=$CLASSPATH:$HADOOP_HOME/lib
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
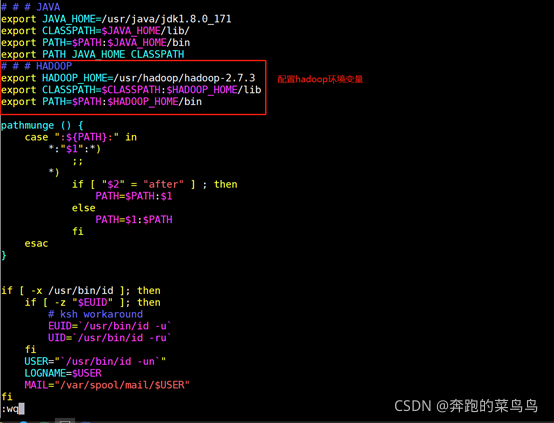
使用以下命令使profile生效:
source /etc/profile
4.2配置hadoop各組件
??hadoop的各個組件的都是使用XML進行配置,這些檔案存放在hadoop的etc/hadoop目錄下,

1.進入hadoop配置目錄,編輯hadoop-env.sh環境組態檔,
cd $HADOOP_HOME/etc/hadoop
vim hadoop-env.sh
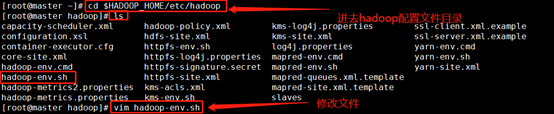
輸入以下內容,修改java環境變數:
記得洗掉:
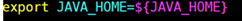
添加這個:↓
export JAVA_HOME=/usr/java/jdk1.8.0_171
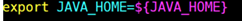
鍵入“Esc”,退出編輯模式,使用命令“:wq”進行保存退出,
2.編輯core-site.xml檔案,
vim core-site.xml
添加以下:
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/hadoop/hadoop-2.7.3/hdfs/tmp</value>
<description>A base for other temporary directories.</description>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>fs.checkpoint.period</name>
<value>60</value>
</property>
<property>
<name>fs.checkpoint.size</name>
<value>67108864</value>
</property>
master:在主節點的ip或者映射名,
9000:主節點和從節點配置的埠都是9000,
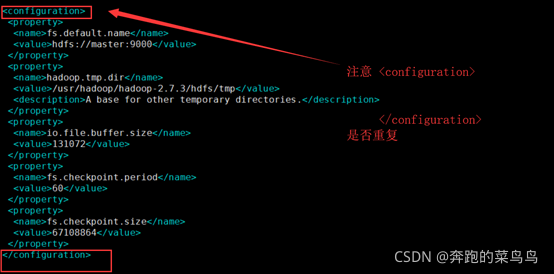
同樣注意保存退出,
3. 編輯mapred-site.xml,hadoop是沒有這個檔案的,需要將mapred-site.xml.template樣本檔案復制為mapred-site.xml,對其進行編輯:
cp mapred-site.xml.template mapred-site.xml
vim mapred-site.xml

在<configuration></configuration>中加入以下代碼:
<property>
<!--指定Mapreduce運行在yarn上-->
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
注意保存退出,
4.修改yarn-site.xml,
vim yarn-site.xml
在<configuration></configuration>中加入以下代碼:
<!-- 指定ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.address</name>
<value>master:18040</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:18030</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:18088</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:18025</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:18141</value>
</property>
<!-- 指定reducer獲取資料的方式-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<!-- Site specific YARN configuration properties -->
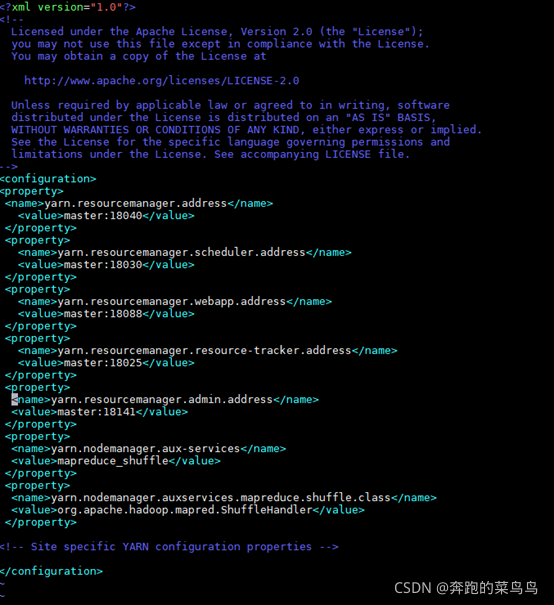
注意保存退出,
5. 編輯hdfs-site.xml組態檔,
vim hdfs-site.xml
echo “export JAVA_HOME=/usr/java/jdk1.8.0_171” >> yarn-env.sh
在<configuration></configuration>中加入以下代碼:
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/hadoop/hadoop-2.7.3/hdfs/name</value>
<final>true</final>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/hadoop/hadoop-2.7.3/hdfs/data</value>
<final>true</final>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9001</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
dfs.replication:因為hadoop是具有可靠性的,它會備份多個文本,這里value就是指備份的數量(小于等于從節點的數量),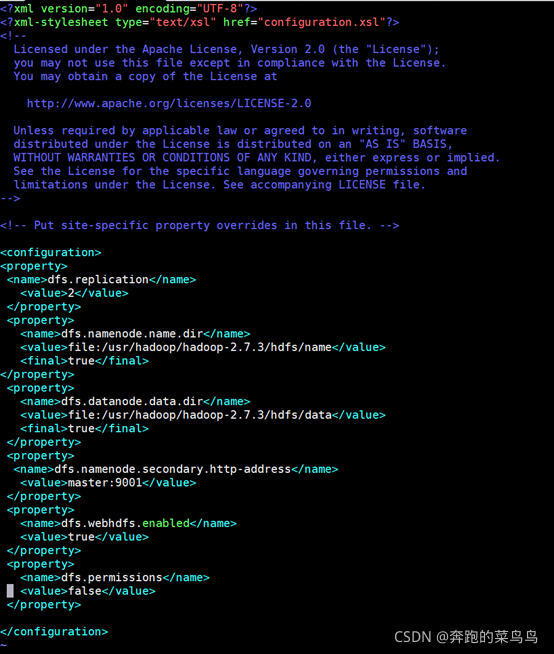
注意保存退出,
6.撰寫slaves檔案,添加子節點slave1和slave2,
vi slaves
記得刪localhost


撰寫master檔案,這里添加主節點master,如果沒有此檔案,可以直接添加,
vi master

7.分發hadoop檔案到slave1、slave2兩個子節點:
scp -r /usr/hadoop root@slave1:/usr/
scp -r /usr/hadoop root@slave2:/usr/

注意:slave各節點上還需要配置環境變數,參考hadoop中第一個步驟,
8.在master中格式化hadoop,開啟hadoop,(僅在master中進行操作)
namenode:hadoop namenode -format
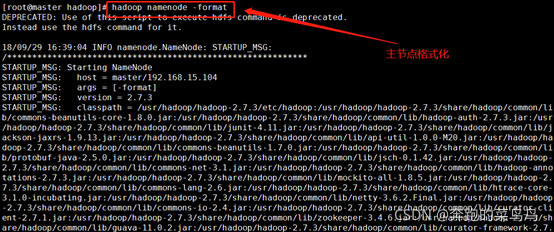
當出現“Exiting with status 0”的時候,表明格式化成功,

9.主節點格式化成功之后,就可以在主節點中開啟hadoop集群,僅在master主機上開啟操作命令,它會帶起從節點的啟動,(僅在master中進行操作)
??●回到hadoop目錄:cd /usr/hadoop/hadoop-2.7.3
??●主節點開啟服務:sbin/start-all.sh
??●Jps
master主節點狀態如下:
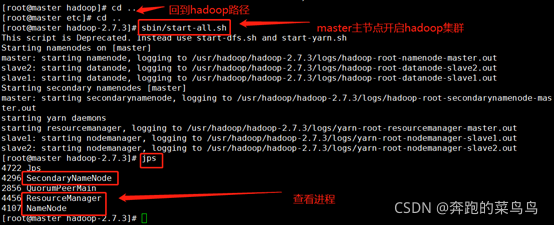
slave1節點狀態如下:

slave2節點狀態如下:

11.使用hadoop命令“hadoop fs”進行相關操作,
五、安裝hbase
1.同樣先在主節點master下進行操作,然后在復制到子節點slave1和slave2.先建立作業路徑/usr/hbase,將/opt/soft下的hbase解壓到作業路徑中,
mkdir -p /usr/hbase
cd /usr/hbase
wget http://10.10.88.2:8000/bigdata/bigdata_tar/hbase-1.2.4-bin.tar.gz
#解壓縮并洗掉
tar -zxvf hbase-1.2.4-bin.tar.gz -C /usr/hbase
rm -rf /usr/hbase/hbase-1.2.4-bin.tar.gz
2.進入hbase配置目錄conf,修改組態檔hbase-env.sh,添加配置變數:
cd /usr/hbase/hbase-1.2.4/conf
vim hbase-env.sh
添加以下內容:
export HBASE_MANAGES_ZK=false
export JAVA_HOME=/usr/java/jdk1.8.0_171
export HBASE_CLASSPATH=/usr/hadoop/hadoop-2.7.3/etc/hadoop
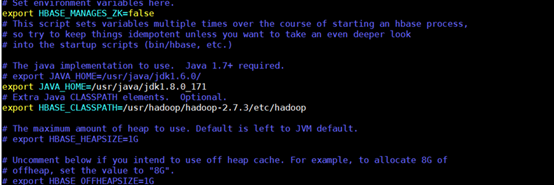
解釋:一個分布式運行的Hbase依賴一個zookeeper集群,所有的節點和客戶端都必須能夠訪問zookeeper,默認的情況下Hbase會管理一個zookeep集群,即Hbase默認自帶一個zookeep集群,這個集群會隨著Hbase的啟動而啟動,而在實際的商業專案中通常自己管理一個zookeeper集群更便于優化配置提高集群作業效率,但需要配置Hbase,需要修改conf/hbase-env.sh里面的HBASE_MANAGES_ZK 來切換,這個值默認是true的,作用是讓Hbase啟動的時候同時也啟動zookeeper.在本實驗中,我們采用獨立運行zookeeper集群的方式,故將其屬性值改為false,
3.配置conf目錄下的hbase-site.xml,
vim hbase-site.xml
添加或修改為以下內容:
<property>
<name>hbase.rootdir</name>
<value>hdfs://master:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.master</name>
<value>hdfs://master:6000</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>master,slave1,slave2</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/usr/zookeeper/zookeeper-3.4.10</value>
</property>
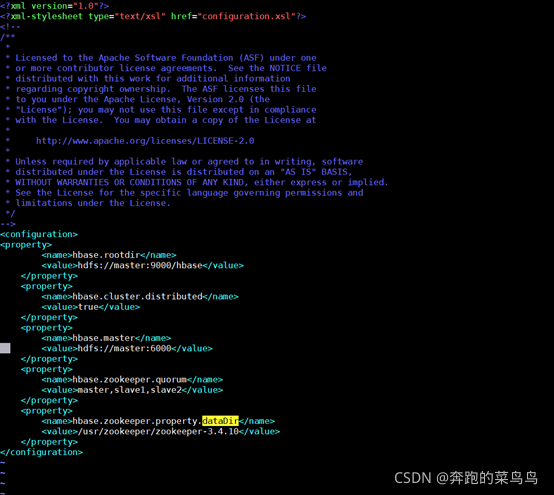
解釋:要想運行完全分布式模式,加一個屬性 hbase.cluster.distributed 設定為 true 然后把 hbase.rootdir 設定為HDFS的NameNode的位置;
hbase.rootdir:這個目錄是region server的共享目錄,用來持久化Hbase,URL需要是’完全正確’的,還要包含檔案系統的scheme;
hbase.cluster.distributed :Hbase的運行模式,false是單機模式,true是分布式模式,若為false,Hbase和Zookeeper會運行在同一個JVM里面,在hbase-site.xml配置zookeeper,當Hbase管理zookeeper的時候,你可以通過修改zoo.cfg來配置zookeeper,對于zookeepr的配置,你至少要在 hbase-site.xml中列出zookeepr的ensemble servers,具體的欄位是 hbase.zookeeper.quorum.在這里列出Zookeeper集群的地址串列,用逗號分割,
hbase.zookeeper.property.clientPort:ZooKeeper的zoo.conf中的配置,客戶端連接的埠,
hbase.zookeeper.property.dataDir:ZooKeeper的zoo.conf中的配置,對于獨立的Zookeeper,要指明Zookeeper的host和埠,需要在 hbase-site.xml中設定,
4. 配置conf/regionservers
vim regionservers

在這里列出了希望運行的全部 HRegionServer,一行寫一個host (就Hadoop里面的slaver 一樣),列在這里的server會隨著集群的啟動而啟動,集群的停止而停止,
5.hadoop組態檔拷入hbase的目錄下(當前目錄為/usr/hbase/hbase-1.2.4/conf)
#注意最后面有 .
cp /usr/hadoop/hadoop-2.7.3/etc/hadoop/hdfs-site.xml .
cp /usr/hadoop/hadoop-2.7.3/etc/hadoop/core-site.xml .
6.分發hbase到子節點,
scp -r /usr/hbase root@slave1:/usr/
scp -r /usr/hbase root@slave2:/usr/
7.配置環境變數(三臺機器)
vim /etc/profile
添加以下內容:
# set hbase environment
export HBASE_HOME=/usr/hbase/hbase-1.2.4
export PATH=$PATH:$HBASE_HOME/bin
生效環境變數:
source /etc/profile
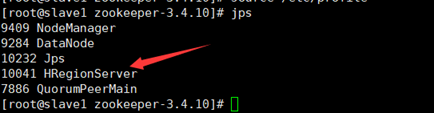
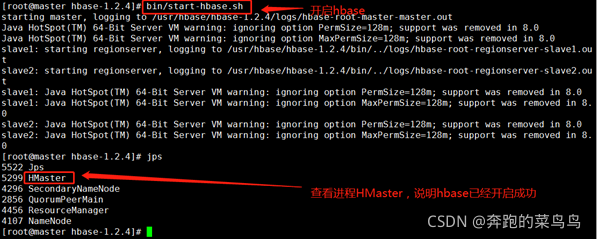
9.運行和測驗,在master上執行(保證hadoop和zookeeper已開啟):
start-hbase.sh
jps
slave1中行程👇:
master中行程👇:
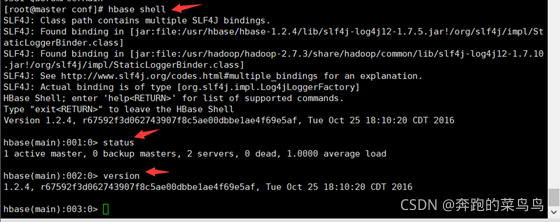
10. hbase shell 查看狀態與版本exit
hbase shell
六、安裝hive
??實驗中我們選用hive的遠程模式,slave2安裝mysql server用于存放元資料,slave1作為hive server作為thrift 服務器,master作為client客戶端進行操作,
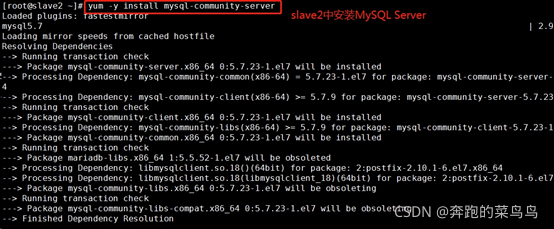
6.1slave2上安裝MySQL server
1.配置過本地源了,安裝MySQL Server
安裝MySQL:
wget http://dev.mysql.com/get/mysql57-community-release-el7-8.noarch.rpm
yum -y localinstall mysql57-community-release-el7-8.noarch.rpm
(比賽時候只用下面這一句就行,平時應該需要加上面的)
yum -y install mysql-community-server
2.啟動服務
●多載所有修改過的組態檔:systemctl daemon-reload
查看狀態:systemctl status mysqld
●開啟服務:systemctl start mysqld
●開機自啟:systemctl enable mysqld

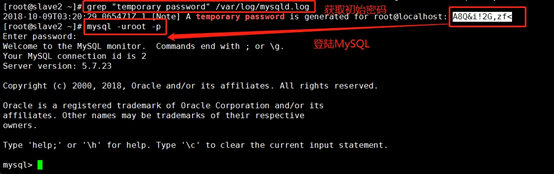
3.安裝完畢后,MySQL會在/var/log/mysqld.log這個檔案中會自動生成一個隨機的密碼,獲取得這個隨機密碼,以用于登錄MySQL資料庫:
●獲取初密碼:
grep "temporary password" /var/log/mysqld.log
●登陸MySQL:(注意中英文)
mysql -uroot -p
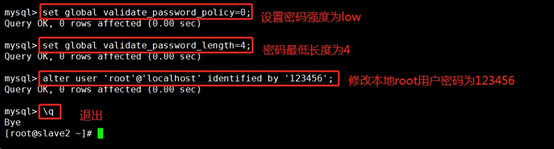
4.MySQL密碼安全策略設定:
●設定密碼強度為低級:set global validate_password_policy=0;
●設定密碼長度:set global validate_password_length=4;
●修改本地密碼:alter user 'root'@'localhost' identified by '123456';
●退出:\q
密碼強度分級如下:
●0為low級別,只檢查長度;
●1為medium級別(默認),符合長度為8,且必須含有數字,大小寫,特殊字符;
●2為strong級別,密碼難度更大一些,需要包括字典檔案,
●密碼長度最低長為4,當設定長度為1、2、3時,其長度依然為4,
5.設定遠程登錄
●以新密碼登陸MySQL:mysql -uroot -p123456
●創建用戶:create user 'root'@'%' identified by '123456';
●允許遠程連接:grant all privileges on *.* to 'root'@'%' with grant option;
●重繪權限:flush privileges;
6.創建資料庫test:create database test;
6.2創建作業路徑,解壓安裝包
??首先創建作業路徑,并將hive解壓,環境中master作為客戶端,slave1作為服務器端,因此都需要使用到hive,因為hive相關安裝包存放在master中,因此我們先在master中對hive進行解壓,然后將其復制到slave1中,
master中操作如下:
mkdir -p /usr/hive
wget http://10.10.88.2:8000/bigdata/bigdata_tar/apache-hive-2.1.1-bin.tar.gz
tar -zxvf apache-hive-2.1.1-bin.tar.gz -C /usr/hive/
6.3slave1中建立檔案
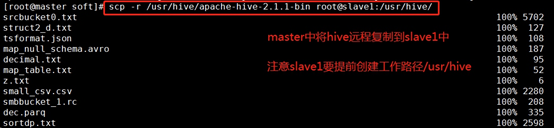
同樣slave1上建立檔案夾/usr/hive,然后master中將安裝包遠程復制到slave1,
mkdir -p /usr/hive
master中將hive檔案復制到slave1:
scp -r /usr/hive/apache-hive-2.1.1-bin root@slave1:/usr/hive/
修改/etc/profile檔案設定hive環境變數,(master和slave1都執行)
vim /etc/profile
添加以下內容:
#set hive
export HIVE_HOME=/usr/hive/apache-hive-2.1.1-bin
export PATH=$PATH:$HIVE_HOME/bin
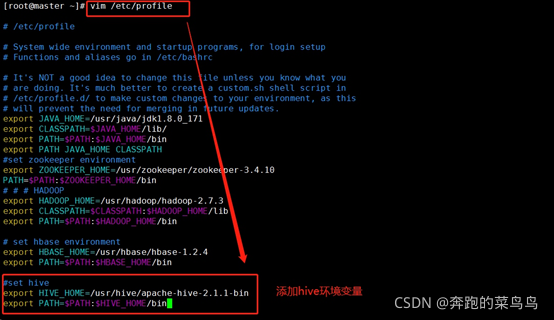 生效環境變數:
生效環境變數:source /etc/profile

6.4解決版本沖突和jar包依賴問題
??由于客戶端需要和hadoop通信,所以需要更改Hadoop中jline的版本,即保留一個高版本的jline jar包,從hive的lib包中拷貝到Hadoop中lib位置為/usr/hadoop/hadoop-2.7.3/share/hadoop/yarn/lib,(master,salve1中執行)
cp /usr/hive/apache-hive-2.1.1-bin/lib/jline-2.12.jar /usr/hadoop/hadoop-2.7.3/share/hadoop/yarn/lib/

??因為服務端需要和Mysql通信,所以服務端需要將Mysql的依賴包放在Hive的lib目錄下,(slave1中進行)
cd /usr/hive/apache-hive-2.1.1-bin/lib
wget http://10.10.88.2:8000/bigdata/bigdata_tar/mysql-connector-java-5.1.47-bin.jar

6.5Slave1作為服務器端配置hive(slave1,master都得執行)
??回到slave1,修改hive-env.sh檔案中HADOOP_HOME環境變數,進入hive配置目錄,因為hive中已經給出組態檔的范本hive-env.sh.template,直接將其復制一個進行修改即可:
cd $HIVE_HOME/conf
ls
#cp hive-env.sh.template hive-env.sh
vim hive-env.sh

hive-env.sh檔案中修改HADOOP_HOME環境變數,
export HADOOP_HOME=/usr/hadoop/hadoop-2.7.3
export HIVE_CONF_DIR=/usr/hive/apache-hive-2.1.1-bin/conf
export HIVE_AUX_JARS_PATH=/usr/hive/apache-hive-2.1.1-bin/lib

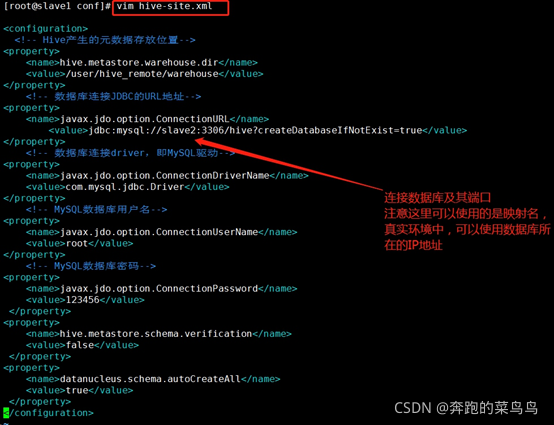
3.修改hive-site.xml檔案
??如果配置一臺機器的話,需要將下面slave2改成master,并且將3.6.6第一步hive-site.xml中的組態檔復制到這個里頭,將重復的存放位置洗掉,將3.6.6第一步里的slave1改為master,
<configuration>
<!-- Hive產生的元資料存放位置-->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive_remote/warehouse</value>
</property>
<!-- 資料庫連接JDBC的URL地址-->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://slave2:3306/hive?createDatabaseIfNotExist=true&useSSL=false</value>
</property>
<!-- 資料庫連接driver,即MySQL驅動-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!-- MySQL資料庫用戶名-->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!-- MySQL資料庫密碼-->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>datanucleus.schema.autoCreateAll</name>
<value>true</value>
</property>
</configuration>
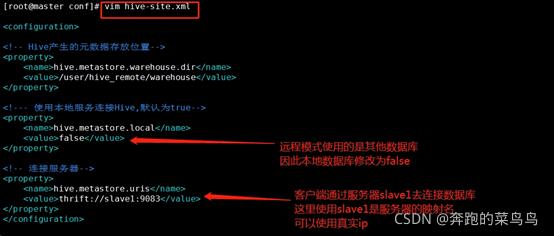
6.6Master作為客戶端配置hive
和slave1中配置方式類似,直接進入
1.修改hive-site.xml 如果是一臺機器需要將slave1改為master
<configuration>
<!-- Hive產生的元資料存放位置-->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive_remote/warehouse</value>
</property>
<!--- 使用本地服務連接Hive,默認為true-->
<property>
<name>hive.metastore.local</name>
<value>false</value>
</property>
<!-- 連接服務器-->
<property>
<name>hive.metastore.uris</name>
<value>thrift://slave1:9083</value>
</property>
</configuration>
Slave1格式化資料庫:
schematool -dbType mysql -initSchema
由于在3.6.5Slave1作為服務器端配置hive(slave1,master都得執行)這一步配置了master的hive-env.sh的三行配置,所以此處省略
2.修改hive-env.sh中HADOOP_HOME環境變數:(配置單臺機器,此步驟可以省略)
ls
cp hive-env.sh.template hive-env.sh
vim hive-env.sh
添加以下內容:
HADOOP_HOME=/usr/hadoop/hadoop-2.7.3
export HIVE_CONF_DIR=/usr/hive/apache-hive-2.1.1-bin/conf
6.7成功啟動Hive
1.啟動hive server服務(slave1上)注意在hive目錄下進行
cd /usr/hive/apache-hive-2.1.1-bin
bin/hive --service metastore(注意空格)

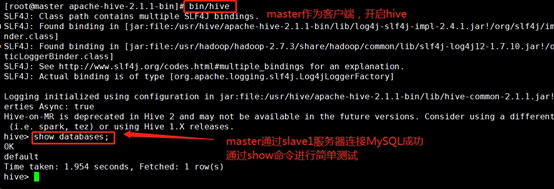
2.啟動hive client(master上) 注意在hive目錄下進行

cd /usr/hive/apache-hive-2.1.1-bin
bin/hive
測驗hive是否啟動成功:
hive>show databases;
創建資料庫hive_db,
hive>create database hive_db;
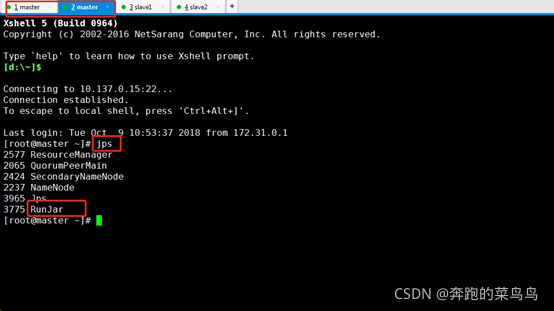
3.復制master會話,最后master的行程如下:
jps
七、安裝Spark
7.1安裝scala環境
1.下載相應安裝包,創建對應作業目錄/usr/scala,解壓scala到相應目錄,
mkdir -p /usr/scala
cd /usr/scala
wget http://10.10.88.2:8000/bigdata/bigdata_tar/scala-2.11.12.tgz
tar -zxvf scala-2.11.12.tgz -C /usr/scala
2.配置scala的環境變數并生效:(三臺都添加)
vim /etc/profile
寫入以下內容:
##scala
export SCALA_HOME=/usr/scala/scala-2.11.12
export PATH=$SCALA_HOME/bin:$PATH
查看scala是否安裝成功:
source /etc/profile
scala -version
復制到其他節點:
scp -r /usr/scala root@slave1:/usr/
scp -r /usr/scala root@slave2:/usr/
7.2安裝spark
1.下載相應安裝包,創建對應作業目錄/usr/scala,解壓scala到相應目錄,
mkdir -p /usr/spark
cd /usr/spark
wget http://10.10.88.2:8000/bigdata/bigdata_tar/spark-2.4.0-bin-hadoop2.7.tgz
tar -zxvf spark-2.4.0-bin-hadoop2.7.tgz -C /usr/spark
rm -rf /usr/spark/spark-2.4.0-bin-hadoop2.7.tgz
2.復制conf下spark-env.sh檔案
cd /usr/spark/spark-2.4.0-bin-hadoop2.7/conf
ls
cp spark-env.sh.template spark-env.sh
vim spark-env.sh
并添加以下內容,具體操作如下圖所示:
export SPARK_MASTER_IP=master
export SCALA_HOME=/usr/scala/scala-2.11.12
export SPARK_WORKER_MEMORY=8g
export JAVA_HOME=/usr/java/jdk1.8.0_171
export HADOOP_HOME=/usr/hadoop/hadoop-2.7.3
export HADOOP_CONF_DIR=/usr/hadoop/hadoop-2.7.3/etc/hadoop
3.配置spark從節點,修改slaves檔案,(注意slaves節點中只包含節點資訊,其他注釋不需要)
cp slaves.template slaves
vim slaves
寫入以下內容:
slave1
slave2
接下來向所有子節點發送spark配置好的安裝包,具體操作如下圖所示:
scp -r /usr/spark root@slave1:/usr/
scp -r /usr/spark root@slave2:/usr/
4.配置spark環境變數
命令:vim /etc/profile(三臺都添加)
在其中添加如下內容:
#spark
export SPARK_HOME=/usr/spark/spark-2.4.0-bin-hadoop2.7
export PATH=$SPARK_HOME/bin:$PATH
生效:source /etc/profile
(3)開啟spark環境(master節點)
命令:/usr/spark/spark-2.4.0-bin-hadoop2.7/sbin/start-all.sh
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/350037.html
標籤:其他