基于STM32的有限詞條語音識別與對話模塊
- 一、模塊整體設計思路
- 二、器件選型與方案確定
- 1、器件選型
- (1)語音識別模塊
- (2)詞條存盤模塊
- (3)語音提示模塊
- (4)主控芯片
- 2、方案確定
- 三、IO資源分配與模塊介紹
- 1、模塊資源分配
- 2、模塊介紹
- 四、除錯步驟
- 第一步:初始程式
- 第二部:硬體SPI實作通信
- 第三步:單獨對W25Q128進行讀寫測驗
- 第四步:單獨對語音合成模塊SYN6288進行測驗
- 第五步:語音識別與語音合成程式合并測驗
- 第六步:單選單整體除錯
- 第七步:實作選單的切換與回傳操作
- 第八步:程式簡化
- 第九步:測驗發現問題并改進
- 五、總結
- 1、遺留問題
- 1、W25Q128詞條批量寫入問題
- 2、主程式對W25Q資料讀出后為什么沒有直接進行寫入,而是要在while(1)的回圈中不停寫入
- 2、新思路-CI1102(80詞條)/CI1103(300詞條)附說明檔案
- 特點:
- 說明:
- 芯片單價:
- 參考文獻與下載
一、模塊整體設計思路

二、器件選型與方案確定
1、器件選型
(1)語音識別模塊
語音識別采用LD3320A語音識別芯片, LD3320是一款非特定語音識別芯片,使用前不需要語音識別訓練就能夠識別不同的群體,能同時識別普通話和方言,LD3320能夠準確快速識別不同實驗物件發出的相同的語音命令,使其的適用范圍更加廣泛,
LD3320具有可動態編輯的關鍵詞語串列,只要在程式初始化時將需要識別的內容以拼音的形式寫入LD3320,即可進行語音的識別 ,舉一個簡單示例:在使用程序中,微處理器把諸如“wang zi”的拼音串按一定格式要求寫入LD3320芯片的關鍵詞串列中,當LD3320模塊識別的語音內容與該關鍵詞串列中的內容相同時便會輸出相應的詞條號,
LD3320的關鍵詞串列的容量為50,在某一時刻,LD3320識別的語音內容就與這50條關鍵詞進行對比,將最合適的結果所對應的詞條號通過SPI串口通信輸出給STM32F103處理器,此外,LD3320沒有預置外部存盤器的擴展介面,實作了真正的單芯片語音識別,因此大大消減了成本費用 ,
(2)詞條存盤模塊
因為LD3320A一次只能進行50條詞條的存盤,如果要進行大容量語音識別只能采取詞條的分級管理,這樣就涉及到詞條的存盤,考慮到詞條分級管理所需要的存盤空間大小,采用W25Q64作為詞條存盤設備最為合適,與U盤和SD卡存盤相比,W25Q只需要通過SPI口連接至主控芯片即可,不需要類似U盤或SD卡特定的處理芯片,這樣大大減少成本,
(3)語音提示模塊
語音提示模塊采用比較簡單的TTS芯片,與廉價的MP3播放芯片相比,TTS芯片不需要去考慮音頻檔案的存盤問題與環境干擾問題,從成本方面去分析,最主要的便是音頻檔案的存盤,經測驗1s的音頻檔案占用29kb大小,這樣考慮到詞條的三級管理是需要2403條語音提示,這樣所需存盤空間為66MB,這超過W25Q最大存盤容量,所以需要U盤與SD卡參與,這樣成本遠超普通的TTS語音合成芯片,
TTS語音合成芯片常用的型號有科大訊飛的XFS5152CE、SYN6288、SYN6658等,綜合考慮成本與實作該專案所需的功能,最終選型SYN6288,
(4)主控芯片
綜合上述模塊的選型與整體模塊架構,在本專案中MCU需要具備:2個SPI介面,2個USART介面,通過MCU選型軟體選擇價格低廉的48腳主控芯片STM32F103C8T6作為專案MCU,
2、方案確定
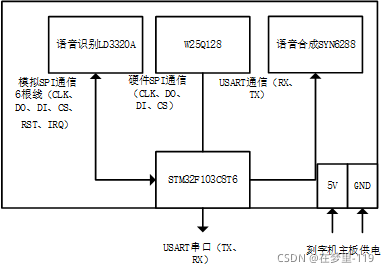
三、IO資源分配與模塊介紹
1、模塊資源分配
| 引腳號 | 引腳名稱 | 功能 | 連接模塊 | 連接模塊 |
|---|---|---|---|---|
| 3 | PC14 | 外部RTC晶振 | 32.768KHz晶振 | OSC32IN |
| 4 | PC15 | 外部RTC晶振 | 32.768KHz晶振 | OSC32OUT |
| 5 | OSC_IN | 外部晶振 | 8M晶振 | XLAT-IN |
| 6 | OSC_OUT | 外部晶振 | 8M晶振 | XLAT-OUT |
| 7 | NRST | 復位 | 復位電路 | NRST |
| 12 | PA2 | USART2_TX | 語音合成模塊 | SYN6288-RxD |
| 13 | PA3 | USART2_RX | 語音合成模塊 | SYN6288-TxD |
| 14 | PA4 | SPI1_NSS | W25Q64的介面座 | W25Q128-CS-B |
| 15 | PA5 | SPI1_SCK | W25Q64的介面座 | W25Q128-CLK-B |
| 16 | PA6 | SPI1_MISO | W25Q64的介面座 | W25Q128-DO-B |
| 17 | PA7 | SPI1_MOSI | W25Q64的介面座 | W25Q128-DI-B |
| 18 | PB0 | IO | 刻字機串口流控制(USART1) | IO |
| 20 | PB2 | BOOT1 | 接地 | |
| 25 | PB12 | SPI2_NSS | LD3320A模塊 | LD CS |
| 26 | PB13 | SPI2_SCK | LD3320A模塊 | LD SDCK |
| 27 | PB14 | SPI2_MISO | LD3320A模塊 | LD SDO |
| 28 | PB15 | SPI2_MOSI | LD3320A模塊 | LD SDI |
| 30 | PA9 | USART1_TX | 埠連接刻字機主板 | OUT-TxD |
| 31 | PA10 | USART1_RX | 埠連接刻字機主板 | OUT-RxD |
| 34 | PA13 | JTCK_SWDAT | SWD燒錄介面 | SWIO |
| 37 | PA14 | JTCK_SWCLK | SWD燒錄介面 | SWCLK |
| 44 | BOOT0 | BOOT0 | 接地 | |
| 45 | PB8 | IO | 接語音模塊復位 | LD IRQ |
| 46 | PB9 | IO | 接語音模塊中斷信號 | LD RST |
2、模塊介紹


四、除錯步驟
第一步:初始程式
初始程式基于語音模塊的畢業設計去考慮,完全從畢業設計的程式出發,初始程式具備了50個詞條的指令識別,以及識別之后的串口列印與OLED屏顯示識別結果,MCU與語音模塊采用了模擬SPI總線通信,
第二部:硬體SPI實作通信
在原始程式的基礎上,將模擬SPI通信更改為硬體SPI通信,使用了MCU的SPI2通信介面,在保留原有功能的基礎上進行了程式的移植,
第三步:單獨對W25Q128進行讀寫測驗
W25Q128與MCU連接采用了硬體SPI通信,使用的時SPI2介面,該程式實作了對W25Q128扇區擦除、資料寫入與讀出并進行兩次資料比對,注意:通過串口1列印顯示的時候會發現部分中文漢字資料亂碼,這是只要點擊十六進制顯示并取消按十六進制顯示,串口的中文漢字便會顯示正常,
第四步:單獨對語音合成模塊SYN6288進行測驗
SYN6288語音模塊使用起來比較簡單,直接通過串口2發送相關指令與待合成命令即可,SYN6288連接喇叭便會發出待合成語音命令,
第五步:語音識別與語音合成程式合并測驗
在硬體SPI完成語音識別的基礎上,在每一個識別結果下單獨加入語音合成命令取代原有的串口列印與OLED屏顯示,完成了一個簡單的語音互動功能,
第六步:單選單整體除錯
這一步就是對之前整體功能的除錯操作,事先通過單獨程式完成對W25Q128資料寫入,之后整體程式先讀出W25Q128的內容并進行資料處理分類,分成了待識別的拼音陣列、待合成的語音陣列、待發送的指令陣列以及待使用的扇區地址陣列,之后便按照W25Q128讀出內容進行語音識別與語音的合成操作,
第七步:實作選單的切換與回傳操作
這一步便是實作大量指令識別的基礎,由于LD3320A一次只能進行50個詞條的識別,要實作大量指令識別只能按選單分批次寫入,這就需要選單切換與回傳操作,
第八步:程式簡化
為了實作大量指令的識別以及選單的分級管理,必須對原有程式的用戶處理函式進行簡化操作,去掉switch選擇并進行資料統一操作(去掉了扇區地址的陣列),對這個操作的理解需要先理解用戶程式的撰寫思路,
第九步:測驗發現問題并改進
五、總結
1、遺留問題
1、W25Q128詞條批量寫入問題
前期W25Q128,后期因為用不到16M的容量,最終確定選用8M的W25Q64,程式更改只要更改FlashID即可,W25Q128的FlashID為0xEF4018,W25Q64的FlashID為0xEF4017,
前期W25Q128詞條寫入一次只寫入一個扇區的內容,當然寫入的內容要小于扇區容量,一般詞條測驗是否和要求的,
現在詞條寫入思路是:設定扇區地址并在相應扇區地址寫入相應的內容(必須一一對應,主程式依靠其一一對應實作程式簡化去掉了原有扇區地址陣列),如果想要對除錯選單的內容進行寫入,只需呀將紅框標出的FLASH_WriteAddress改為0x001000,并將下面紅框中的內容進行替換即可,這樣雖然簡單,但是總共50組詞條寫入,就要進行這樣操作50次,我們為什么不進行一次操作完成呢?
我的嘗試一:直接將50組資料定義在程式(如Order_Buffer[50][4096])中進行操作,這樣寫完一組只要進行相應標志位的更改便可以繼續進行下一組資料寫入,想法雖好,但是實際操作中發現程式無法對如此大的資料進行處理(芯片的空間不足),要么付訓主芯片,選取容量大一點,要么資料內容從外部分批讀入然后分批寫入,
我的嘗試二:將50組資料以txt檔案的形式保存在U盤中,這樣就可以通過U盤讀取資料進而寫入到W25Q64中,首先讀取U盤的.txt檔案并通過串口列印顯示查看讀取的結果是否正確,當然一組資料顯示是沒有問題,但是50組資料同時傳輸過來顯示亂碼比較嚴重(由于杜洋開發板U盤讀取電路與JTAG電路引腳沖突,無法運行在線除錯程式),于是我該用正點原子407開發板的USB HOST的相關程式進行除錯,發現資料完整性無法保持,之后我由于時間關系沒有進一步去進行程式改進以及原因查明,
2、主程式對W25Q資料讀出后為什么沒有直接進行寫入,而是要在while(1)的回圈中不停寫入
2、新思路-CI1102(80詞條)/CI1103(300詞條)附說明檔案
特點:
單芯片集成語音識別與CPU;
說明:
CI1102 是一顆專用于語音處理的人工智能芯片,可廣泛應用于家電、家居、照明、音箱、玩具、穿戴設備、汽車等產品領域,實作語音互動及控制,CI1102 內置自主研發的腦神經網路處理器 BNPU,支持本地語音識別,和內置的CPU 核結合可以做各類智能語音方案應用,
CI1102內置高性能低功耗Audio Codec 模塊和硬體音頻處理模塊,可以外接麥克風實作單芯片遠場降噪或者回聲消除等功能,同時該芯片還集成多路 UART、I2C、SPI、PWM、GPIO等外圍控制介面,可以開發低成本的單芯片智 能語音離線識別方案,
芯片單價:
15左右(1個);13左右(100個·)
參考文獻與下載
本文 原文 link.
芯片資料資料:
W25Q128 link.
SYN6288 link.
LD3320 link.
原理圖及PCB:link.
最終程式:link.
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/350747.html
標籤:其他
上一篇:影像處理(四):影像的幾何變換