語音識別-Kaldi的安裝編譯實錄(Ubuntu環境)
本篇博客用于記錄一次用開源語音識別(ASR)工具Kaldi來實作中文語音識別功能的經歷,記錄一路遇到的一些問題,希望本篇文章可以給廣大有需要的人提供一些幫助,也以防之后若再做此方向的東西會重蹈覆轍,
注意:本文是在Ubuntu64位的虛擬機環境下運行的,通過閱讀Kaldi官方的INSTALL檔案中指出的,似乎不能在Windows下正常編譯使用,
Kaldi簡介:Kaldi是當前最流行的開源語音識別工具(Toolkit),它使用WFST來實作解碼演算法,它自帶了很多特征提取模塊,能提取MFCC/ivector/xvector等語音特征;也自帶了很多語音模型代碼,可以直接使用或重新訓練GMM-HMM等模型;它還支持GPU進行訓練,可以說是功能很強大了,更厲害的是,你只需要簡單的SHELL編程,就能使用kaldi,kaldi作為一個工具,不需要像庫一樣進行大量編程,所以使用門檻其實不高,
對應大部分Kaldi的用戶來說,我們只需要使用腳本和組態檔就可以完成語音識別系統的訓練和預測了,所以我也選擇了用Kaldi來完成導師安排的語音識別任務,
一、配置Kaldi環境
安裝VMWare虛擬機并安裝了Ubuntu,我的版本是Ubuntu20.04.3,安裝程序參考:Ubuntu18.04安裝教程
Kaldi官方教程:https://kaldi-asr.org/doc/install.html
安裝下載,我是從github上直接下載zip然后解壓的,官方github鏈接:https://github.com/kaldi-asr/kaldi
注意,如果下載zip到win上,一定要將zip傳輸到虛擬機再解壓,不要解壓后再復制到虛擬機!會出錯的!
或者!
也可以使用git命令將其下載到本地,在終端鍵入:
git clone https://github.com/kaldi-asr/kaldi.git kaldi --origin upstream
======== 下面這部分是我準備thchs30資料集的部分,和本文編譯kaldi內容無關 ========
在Ubuntu中安裝清華大學開源的thchs30資料集:http://www.openslr.org/18/
這里面的三個檔案都要下,一共約8G,下載好后解壓放到Kaldi的目錄中對應的thchs30目錄下新建的thchs30-openslr目錄(該目錄由自己創建)下:
例如,我的目錄如下:
/home/keep/Keep/kaldi-master/egs/thchs30
這個thchs30-openslr是自己創建的,進去將下載來的3個資料集檔案壓縮到這個檔案夾內即可,
在傳輸資料集的程序中我遇到了Ubuntu磁盤空間滿的問題,但是我剛分配了40G,理應不會滿,后來我猜測是因為從Win上復制檔案到VMWare中可能會有快取,然后去查了相關檔案,發現問題確實如此,解決辦法參考了:linux硬碟滿了如何處理–ck3208
我的目錄里是一個VMWare的dictionary中的./.cache占用了20G的記憶體,隨后我按照上面的博客步驟去釋放,問題也就得到了解決,
======== 上面這部分是我準備thchs30資料集的部分,和本文編譯kaldi內容無關 ========
二、安裝Kaldi依賴包、準備編譯
進入kaldi-master專案檔案夾,查看./INSTALL,提示需要分別編譯tools和src下的檔案
在終端鍵入 cd kaldi-master/tools/extras
鍵入./check_dependencies.sh執行該腳本檢查包依賴情況
根據提示安裝所需要的包
這里遇到了一個問題,是我按提示安裝了所有包之后,一直提示我sudo apt-get install zlib1g-dev,我按提示鍵入命令安裝這個zlib提示已安裝且是最新版,一直重復得不到解決,
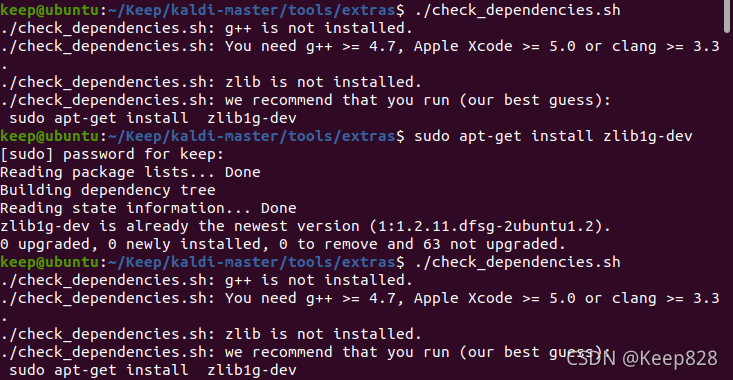
后來嘗試先安裝它提示的別的包試試,于是嘗試安裝g++,
先是鍵入了:
sudo add-apt-repository ppa:ubuntu-toolchain-r/test
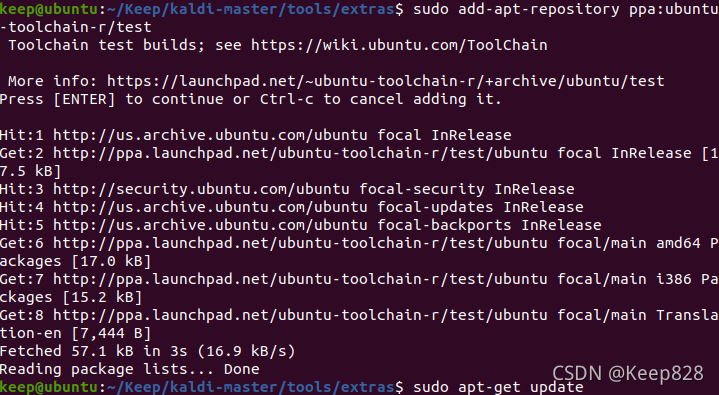
鍵入命令:
sudo apt-get update

接著才可以鍵入安裝g++的命令:
sudo apt install g++
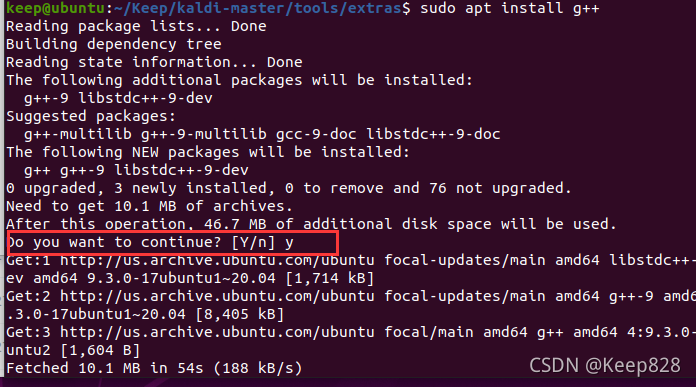
中間會提示問是否繼續,鍵入y后回車即可
終于,再次使用./check_dependencise.sh命令查看依賴包提示時已經all OK了,

三、編譯
依賴包安裝完了,先來編譯tools
先cd到tools目錄下,鍵入:
make -j 4 //這個數字4因人而異
#注意:這里的數字4是根據你的虛擬機cpu核心數來的,我這里虛擬機分配了4個核心就輸入了4,當然也可以輸入<=4的正整數,但是數字越大編譯的效率也就越高了,所以看自己來確定這個數字,
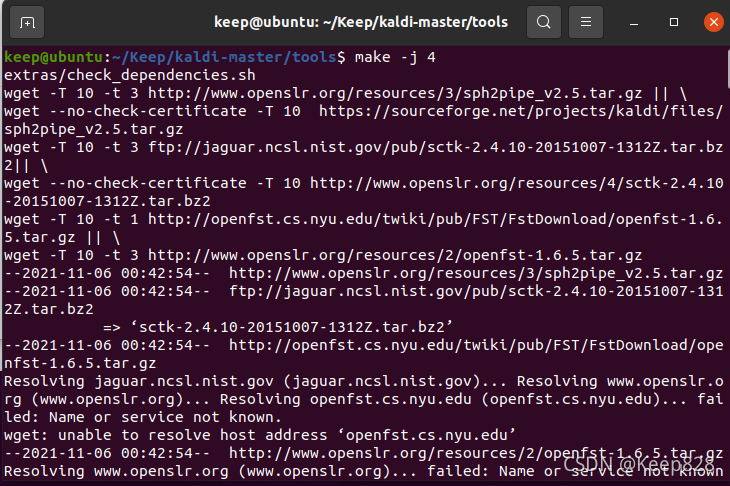
編譯完提示All done OK.:
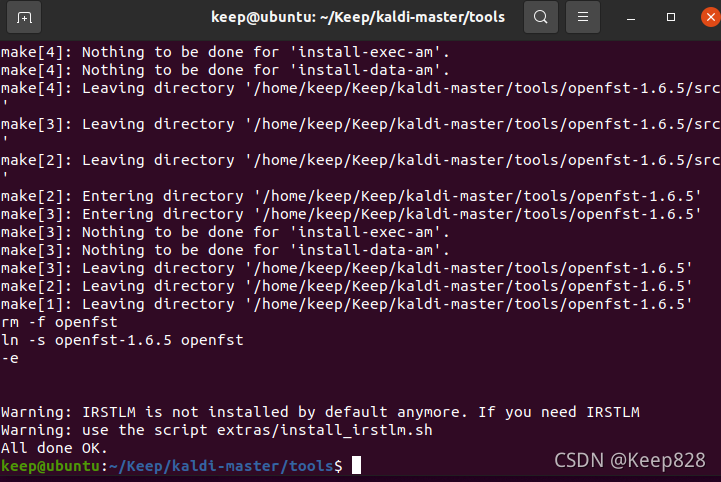
編譯完tools就可以來編譯src了,先cd到src目錄下,
鍵入命令:
./configure
這里出現了如下錯誤,當我按提示鍵入了如下圖的命令后無果,查閱相關問題,發現了解決辦法,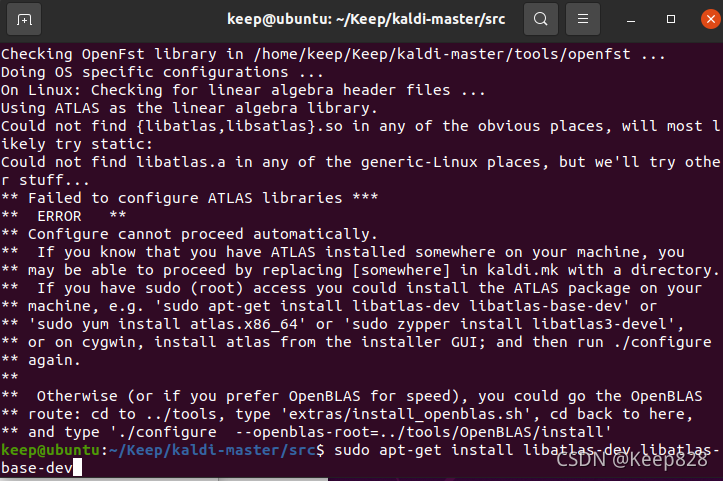
這里需要鍵入:
sudo apt-get install libatlas-base-dev
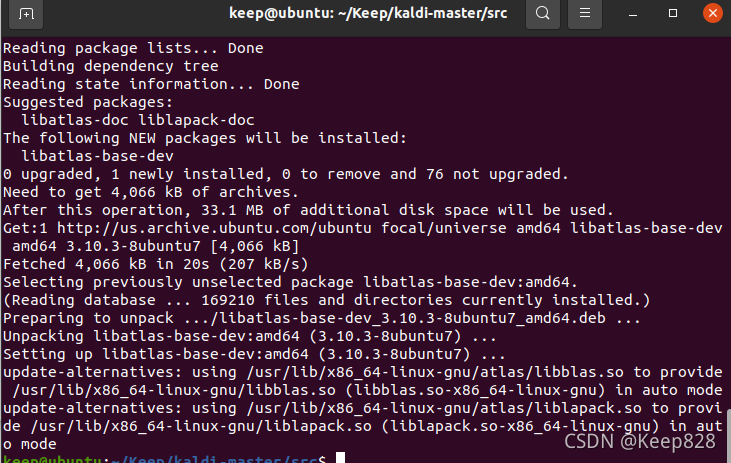
此時,再執行:
./configure --shared
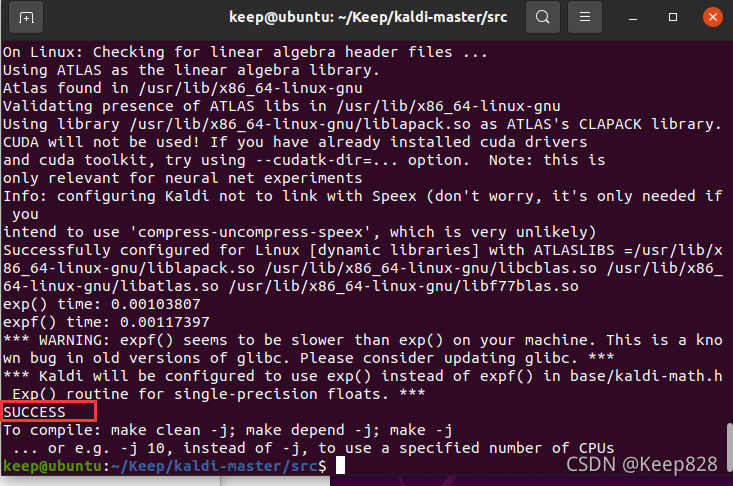
看到了SUCCESS表示成功了,
繼續依次鍵入命令:
make depend -j 4
make -j 4
注意:此處的4仍然按照自己分配的CPU核數來修改
鍵入make 進行編譯,make耗時較長請耐心等待
出現:Done表示成功
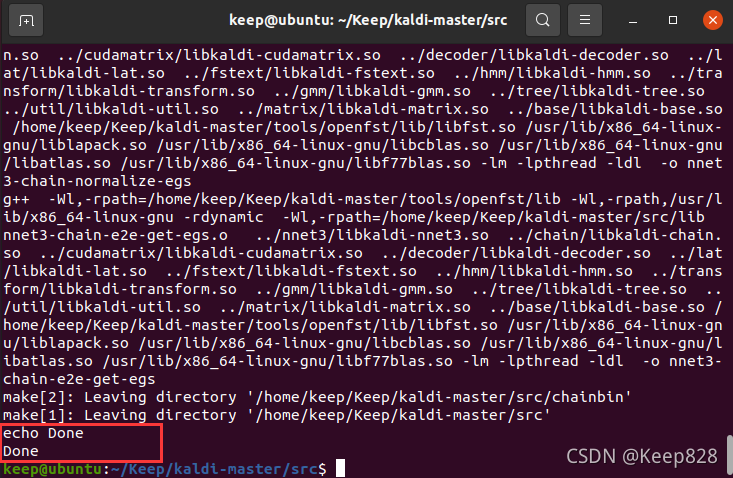
現在需要驗證一下是否安裝成功
進入egs目錄,用命令 cat README.txt 查看用例,egs下面包含如voxforge,vystadial_{cz,en},yesno和LDC用例
這里用yesno為例
進入egs/yesno目錄,用命令cat README.txt 查看yesno資料集介紹,是一個關于Yes/no識別的簡單的資料集
進入egs/yesno/s5目錄,執行
./run.sh
這里我出現了這個
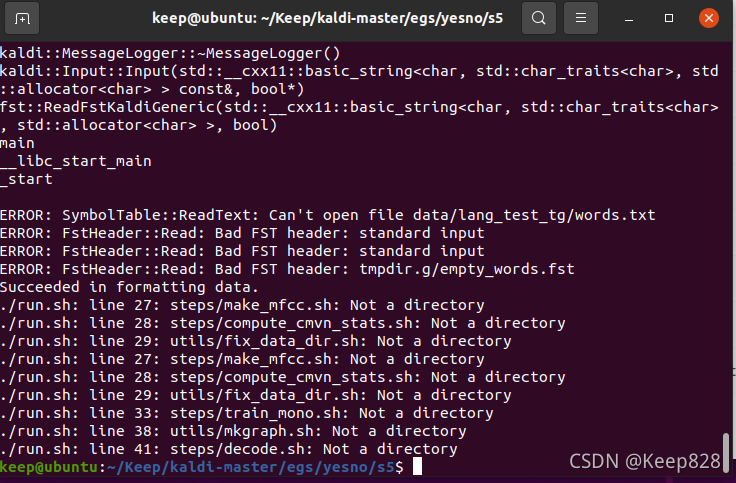
考慮到剛剛make編譯的程序中重啟了一下虛擬機,遂回到scr目錄下 重新鍵入3個命令./configure --shared , make depend -j 4 , make -j 4 后重新編譯再進行此步驟,發現還是解決不了,看到一個同樣遇到這個問題的說:
究其原因是在于呼叫steps/ 和 utils/ 檔案夾下的sh檔案是報錯,找不到檔案,發現steps/ 和 utils/ 此時為兩個檔案,
實際上這兩個檔案為兩個外鏈檔案,類似于windows下的快捷方式,此處本應為外鏈的形式,但是卻變成了兩個檔案,
錯誤在于,本人在windows下下載了kaldi的zip包, 解壓完之后移動到了ubuntu下安裝編譯,此時會生成檔案而非外鏈,
解決方法如下:
-
直接在ubuntu下 git clone 專案并解壓安裝
-
下載zip包在windows, 不解壓縮直接傳至ubuntu下解壓縮并安裝,
崩潰了,要重新來一遍了,,艸,,也沒辦法不是,我去重新來一遍,
最后我用方法2,把zip放到Ubuntu后再解壓,然后重新走了一遍步驟二、編譯,然后就成功了!
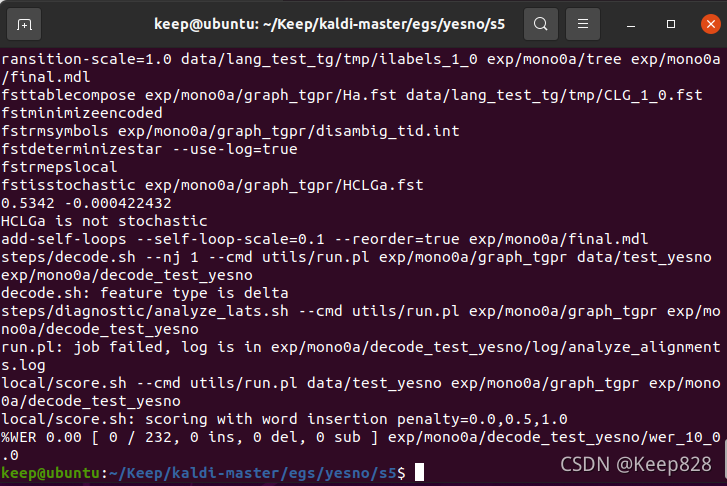
出現%WER 0.00 [ 0 / 232, 0 ins, 0 del, 0 sub ] exp/mono0a/decode_test_yesno/wer_10_0.0時,恭喜你,Kaldi安裝成功!
感謝:
- 基于kaldi和CVTE開源模型的中文識別
- [2019.6.21]Ubuntu下Kaldi完整安裝步驟以及初步跑通程序
- Kaldi安裝(ubuntu)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/350758.html
標籤:其他
下一篇:基于改進EAST演算法的文本檢測