這段時間閱讀研究了EAST演算法以及在EAST演算法上的改進并完成了復現運用到其他場景中去,
當今社會已進入影像大資料時代,影像數量龐大種類繁多,包含大量的有用知識,從影像中高效、精準、全面地提取文本和地理資訊坐標等有用知識這一課題,也成為影像處理的一個重要方向,
隨著近些年來深度學習技術不斷進步發展,對于一些特定場景的影像文本定位任務成為國內外計算機視覺、模式識別研究方向相關學者的研究方向之一,解決特定場景影像文本資訊提取問題依賴于各種神經網路模型演算法,需要考慮到各種因素,一般將場景文本提取拆分為兩個主要任務:文本定位和文本識別,特定場景影像文本檢測演算法的大體框架也基于文本定位和文本識別這兩大任務.
其中,文本定位演算法主要通過計算機自動框定出文本在柵格地質影像中的位置,作為后續文本識別程序的先行條件,在地質影像的知識提取中起著重要作用,目前基于深度學習的文本檢測演算法主要分為兩類,一類是基于預選框的文本檢測演算法,另一類是使用全卷積神經網路直接預測目標位置,文獻中提出的EAST(An Efficient and Accurate Scene Text Detector)演算法是直接預測文本字符位置的定位演算法,演算法運行速度快,在基準資料集上準確率高,核心思想是直接預測單詞或文本行的傾斜角度及多邊形形狀,消除多層神經網路中復雜的運算程序,在各種公開的資料集中取得了良好的成果,
同時,文本識別演算法主要是通過文本定位的結果定位到文本的位置,然后通過端到端的轉錄演算法將該位置的資訊轉換為中文文本,
EAST演算法是曠世科技在2017年CVPR上提出的一種十分簡潔高效的文本檢測模型,論文全稱是《 EAST: An Efficient and Accurate Scene Text Detector 》,作者在文中提出,過去的文本檢測方法雖然實作了不錯的效果,但這些方法基本上都是多階段、多組件的聯合作用,換句話說,就是作者認為以往的方法設計的步驟和組件過多,導致它們在一些具有挑戰性的場景中表現不夠好,速度也不夠快,
因此,作者設計了一種十分簡潔高效的方法,可以直接通過一個FCN網路來得到字符級或文本行的預測結果,且不論是精度還是速度,在各大基準資料集上都有杰出的表現(在ICDAR2015上得到了0.782的F值和13.2的fps),方法的整體思路是通過一個FCN直接得到文本框預測,之后將預測通過NMS得到最終結果(two stage),下面是這項作業的主要貢獻:
1. 提出了一個兩階段的場景文本檢測方法,FCN+NMS,不需要其他多余耗時的步驟,
2. 該方法可靈活生成字符級或文本行的預測,幾何形狀可以是旋轉框或者矩形框,
3. 在精度和速度都優于當時其他的方法,
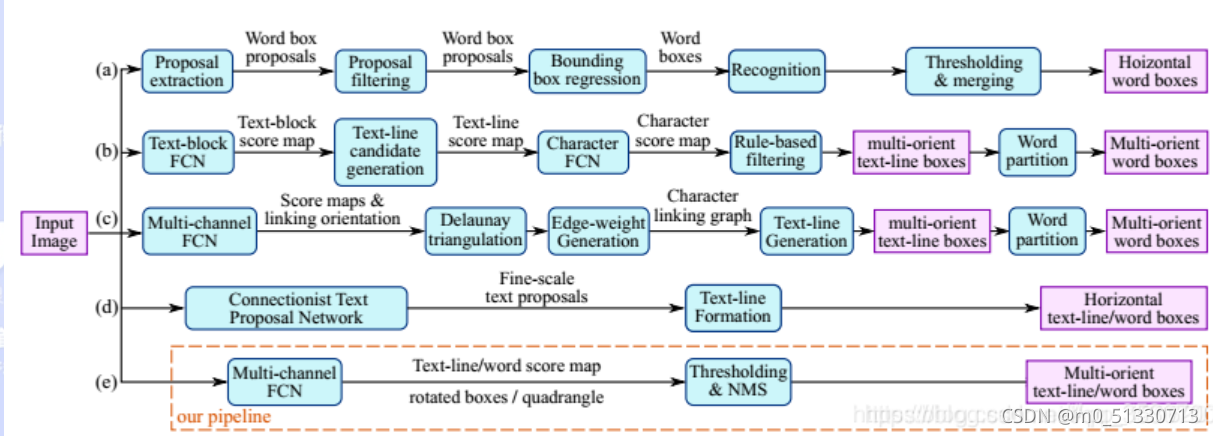
那么該演算法的優勢在于消除傳統演算法中間冗余而又慢速的步驟,只包含兩個主要流程: 一是使用全卷積網路( fully convolutional networks,FCN) 模型直接生成單詞或文本行級別預測; 二是將生成的文本預測( 可以是旋轉的矩形或四邊形) 輸入到非極大值抑制 NMS( non-maximum suppression) 中以產生最終結果,而傳統的文本檢測方法和一些基于深度神經 網路的文本定位方法由若干組件構成,包含多個步驟且在訓練時需要對其分別進行調優,耗費時間較多,
我打算先介紹一下EAST演算法,然后再詳細講述基于EAST演算法的改進,
https://github.com/argman/EAST
這是原作者參與的一份tensorflow版本代碼,網上還有其他的實作,
開源代碼一般都是在linux環境下撰寫、測驗、運行,
首先是下載原始碼:
git clone https://github.com/argman/EAST.git然后就是下載好模型檔案放到指定的位置測驗,
第一次運行肯定會報錯,windows和Linux畢竟不同,
參考博客:https://www.jianshu.com/p/c5a9e1ecf790
報錯:import lanms
File "D:\work\Chepai\License-Plate-Recognition-master1\EAST-master\lanms\__init__.py", line 10, in <module>解決問題的辦法是:
注釋掉__init__.py中的下面這兩行
# if subprocess.call(['make', '-C', BASE_DIR]) != 0: # return value
# raise RuntimeError('Cannot compile lanms: {}'.format(BASE_DIR))注釋掉這兩行還是會報錯:
File "eval.py", line 162, in main
boxes, timer = detect(score_map=score, geo_map=geometry, timer=timer)
File "eval.py", line 100, in detect
boxes = lanms.merge_quadrangle_n9(boxes.astype('float32'), nms_thres)
File "D:\Github\EAST\lanms\__init__.py", line 12, in merge_quadrangle_n9
from .adaptor import merge_quadrangle_n9 as nms_impl
ImportError: No module named 'lanms.adaptor'解決辦法是:
結果發現報eval.py中的100行錯誤,所以把這一行注釋掉,換成上一句,
boxes = nms_locality.nms_locality(boxes.astype(np.float64), nms_thres)
# boxes = lanms.merge_quadrangle_n9(boxes.astype('float32'), nms_thres)結果不再報錯了,
另外,我自己使用的是windows,所以原始碼中給出的test方法對我并不適用,會報錯找不到模型檔案路徑,
File "eval.py", line 147, in main
model_path = os.path.join(FLAGS.checkpoint_path, os.path.basename(ckpt_state.model_checkpoint_path))
AttributeError: 'NoneType' object has no attribute 'model_checkpoint_path'原因是這個代碼在windows下是用不了相對路徑,換成絕對路徑就可以了,
github 原始碼中給出的test腳本是:
python eval.py --test_data_path=/tmp/images/ --gpu_list=0 --checkpoint_path=/tmp/east_icdar2015_resnet_v1_50_rbox/ --output_dir=/tmp/我在windows下使用的腳本是:
(我把下面的腳本寫到一個test.bat檔案中,這樣每次執行就不用敲代碼了,雙擊一下就可以執行)
python eval.py --test_data_path=D:/Github/EAST/tmp/images/ --gpu_list=0 --checkpoint_path=D:/Github/EAST/tmp/east_icdar2015_resnet_v1_50_rbox/ --output_dir=D:/Github/EAST/tmp/
pause在windows下的訓練腳本train.bat:
python multigpu_train.py --gpu_list=0 --input_size=512 --batch_size_per_gpu=8 --checkpoint_path=D:/Github/EAST/tmp/east_icdar2015_resnet_v1_50_rbox/ --text_scale=512 --training_data_path=D:/Github/EAST/data/ocr/icdar2015/ --geometry=RBOX --learning_rate=0.0001 --num_readers=24 --pretrained_model_path=D:/Github/EAST/tmp/resnet_v1_50.ckpt
pause第一次跑也是跑不不通,報錯:
Generator use 10 batches for buffering, this may take a while, you can tune this yourself.
Traceback (most recent call last):
File "multigpu_train.py", line 180, in <module>
tf.app.run()
File "D:\Anaconda3\envs\py35\lib\site-packages\tensorflow\python\platform\app.py", line 126, in run
_sys.exit(main(argv))
File "multigpu_train.py", line 153, in main
data = next(data_generator)
File "D:\Github\EAST\icdar.py", line 726, in get_batch
enqueuer.start(max_queue_size=10, workers=num_workers)
File "D:\Github\EAST\data_util.py", line 81, in start
thread.start()
File "D:\Anaconda3\envs\py35\lib\multiprocessing\process.py", line 105, in start
self._popen = self._Popen(self)
File "D:\Anaconda3\envs\py35\lib\multiprocessing\context.py", line 212, in _Popen
return _default_context.get_context().Process._Popen(process_obj)
File "D:\Anaconda3\envs\py35\lib\multiprocessing\context.py", line 313, in _Popen
return Popen(process_obj)
File "D:\Anaconda3\envs\py35\lib\multiprocessing\popen_spawn_win32.py", line 66, in __init__
reduction.dump(process_obj, to_child)
File "D:\Anaconda3\envs\py35\lib\multiprocessing\reduction.py", line 59, in dump
ForkingPickler(file, protocol).dump(obj)
AttributeError: Can't pickle local object 'GeneratorEnqueuer.start.<locals>.data_generator_task'問題出現在上面的提示 enqueuer.start(max_queue_size=10, workers=num_workers)
參考:https://blog.csdn.net/weixin_41437855/article/details/90259922 的評論stoneboy1211
解決辦法:
將icdar.py 724行開始的部分改為(改動部分 True改為False,10改為1,numworks改為1):
enqueuer = GeneratorEnqueuer(generator(**kwargs), use_multiprocessing=False)
print('Generator use 10 batches for buffering, this may take a while, you can tune this yourself.')
enqueuer.start(max_queue_size=1, workers=1)接著還會報錯:
Traceback (most recent call last):
File "D:\Github\EAST\icdar.py", line 609, in generator
text_polys, text_tags = load_annoataion(txt_fn)
File "D:\Github\EAST\icdar.py", line 56, in load_annoataion
for line in reader:
UnicodeDecodeError: 'gbk' codec can't decode byte 0xbf in position 2: illegal multibyte sequence解決辦法:將icdar.py的54行由
with open(p, 'r') as f:
改為:
with open(p, 'r', encoding='utf-8') as f:
接下來訓練也可以跑通了,
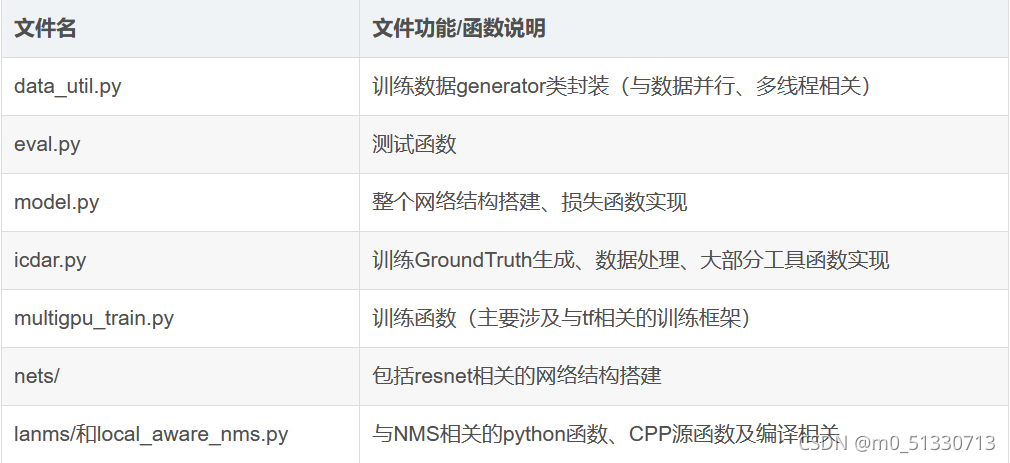
EAST原始碼主要包含3個功能模塊:
- icdar.py此部分主要是對資料進行預處理;
- model.model()函式,該函式在model.py中,主要是完成網路結構搭建,特征圖的生成;
- model.loss()函式,該函式在model.py中,主要是計算損失,
- 其他代碼說明:
下面介紹基于EAST演算法的改進,介紹的這篇文章大家感興趣的可以去搜索,
改進后的EAST演算法相比基于候選框的目標檢測演算法更加準確,對于大比例尺,文本尺度多樣的地質影像中的文本檢測更加準確,但仍然存在一些問題,如化學符號,地質符號特別密集的區域檢測準確率較低,存在改進方向如下:提高更加清晰的訓練樣本,優化網路結構,進一步提升檢測演算法的準確性,改進后的EAST演算法主要包含5個部分:演算法神經網路結構、基于focal-loss[29]優化的損失函式、傾斜的區域感知非極大值抑制網路(NMS)、基于可變尺度的影像分割優化、按比例尺切割訓練樣本,
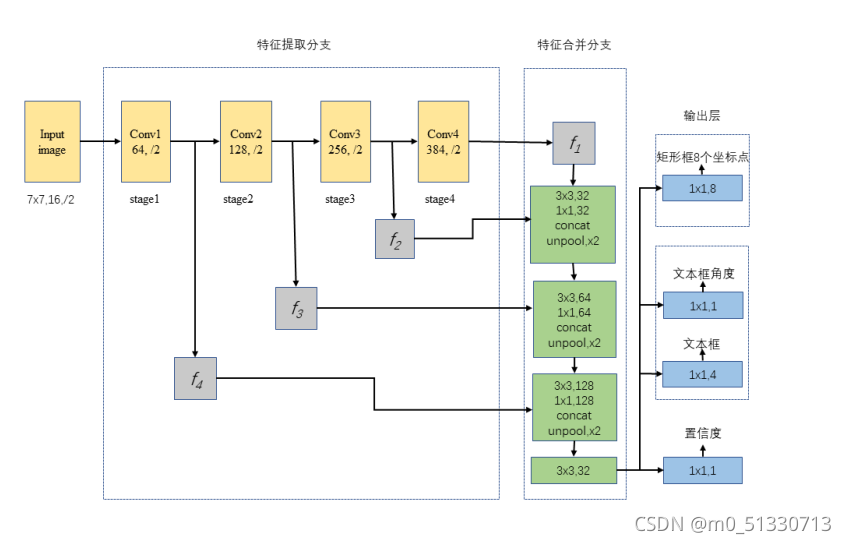
改進后的神經網路結構主要由特征提取分支、特征合并分支和輸出層三個部分構成,
特征提取分支包含Conv1、Conv2、Conv3、Conv4四組卷積層,使用EAST演算法在ImageNet資料集上進行訓練,摘取其中部分的卷積神經網路層,其中f1、f2、f3為卷積層中的特征圖,大小為原始輸入影像的1/32、1/16、1/8、1/4,
在特征合并分支在每個合并階段,將特征提取分支f1階段的特征圖輸入到反池化層(unpool)中,輸出影像為上一階段輸入影像的2倍 ;然后逐步合并,這一步操作會產生一部分計算代價,為提升演算法效率,本文通過減少Conv1的通道數,接著合并區域卷積特征,通過Conv3進行操作輸出到f3階段中,在經過所有的特征合并階段之后,將特征提取分支f4的輸入結果輸出到輸出層當中,
輸出層包含置信度、文本區域和文本區域旋轉角度、包含8個坐標的矩形文本區域三個部分,最終的輸出結果是1×1的卷積提取特征,
L為EAST演算法的損失函式:
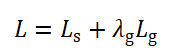
其中,表示分割影像背景和影像文本的分類損失,文本區域所在的部分表示1,非文本區域的背景部分表示0,即像素點的分類損失,![]() 表示對應文本區域的像素點所組成的矩形框和矩形框角度的回歸損失,
表示對應文本區域的像素點所組成的矩形框和矩形框角度的回歸損失,![]() 表示兩個損失之間的相關性,作者在原EAST演算法中將設定為1,
表示兩個損失之間的相關性,作者在原EAST演算法中將設定為1,
非極大值抑制簡稱NMS,簡單理解就是區域最大搜索,主要應用于目標識別、目標檢索、回歸分析等方向,在柵格地質影像文本定位程序中,分類器訓練結束后會輸出多個預測出來的文本矩形框,每個預測框都會有一個分數,但是絕大多數預測框會出現重疊的情況,所以NMS的主要作用就是在文本范圍內去輸出面積最大的矩形文本框,同時面積較小的文本預測框會收到抑制,得到最終結果,
標準NMS是直接取分數最高的預測框,而區域感知NMS則是基于鄰近幾個多邊形是高度相關的假設,在標準NMS的基礎上加了權重覆寫,就是將2個IoU(Intersection Over Union,交并比即重疊區域面積比例)[32]進行比較,首先設定一個面積為S的閾值,然后求兩個預測框的交集,如果大于S則合并,反之則洗掉,經過合并后的預測框,其坐標位置相對于文本區域更加準確,不會浪費每一個預測框的資訊,防止誤差過大,
由于兩個矩形文本框重疊的部分可以是任意多邊形,計算重疊區域面積的難度較大,所以區域感知NMS一般采取簡化的計算方式,將相交部分近似為一個矩形,每計算一次相當于計算矩形的頂點和坐標軸組成的梯形的面積,
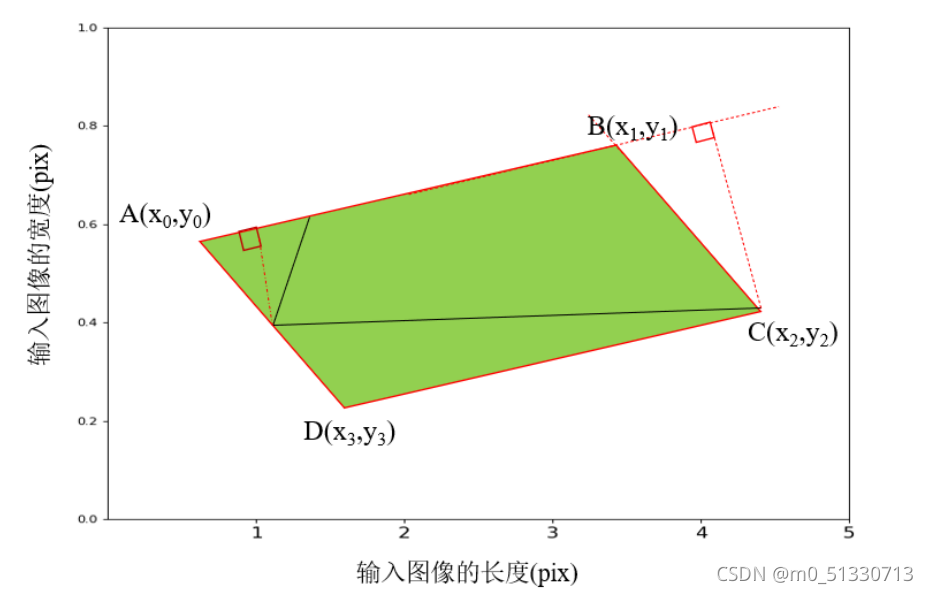
使用的影像資料集中包含有大量的傾斜文本(文本與水平形成夾角),所以本文在區域感知NMS的基礎上增加了傾斜的NMS來處理這些傾斜文本,其基本步驟如下:
(1)對網路輸出的旋轉矩形文本檢測框按照得分進行降序排列,并存盤到一個降序串列里,
(2)依次遍歷上述的降序串列,將當前的文本框和剩余的其它文本框進行交集計算的到相應的相交點集合,
(3)根據判斷相交點集合組成的凸多邊形的面積,計算每兩個文本檢測框的IOU(重疊區域面積比例);對于大于閾值的文本框進行過濾,保留小于閾值的文本框,并得到最終的文本矩形檢測框,

最近實在疲憊不堪了 對于這兩天發的博客 會進行完完全全認認真真地重新修改 復現代碼也會展示最后如何運用到火車證身份證等新的場景,
參考:https://blog.csdn.net/juluwangriyue/article/details/107295393
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/350760.html
標籤:其他