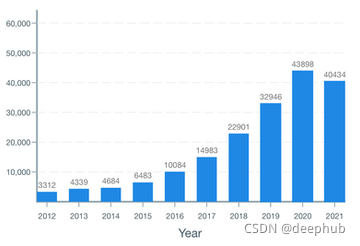
隨著我們接近 2021 年底,arXiv 上的論文首次發表量增長似乎正在放緩:經過幾年持續呈指數增長(每年 30-40%)后,看起來 2021 年的發表量 2020 年的排名僅略高于 2020 年(高出約 10%), 我們會看到 NeurIPS 和 ICLR 的強勁增長嗎? 或者人工智能研究已經成熟?
讓我們先從過去幾周的一些熱門新聞開始:
EMNLP將于 11 月 7 日至 11 日以線上線下混合形式舉行:同時在線和在多米尼加共和國蓬塔卡納舉行(這個地方你都沒聽說過吧,它可是海灘度假的最佳選擇之一,所以你懂的),官方公開會議將很快在 ACL 選集中出版,
Deepmind 收購了 MuJoCo 并將其開源,MuJoCo 是機器人和 RL 中使用最廣泛的物理模擬軟體之一,而且它非常的貴,大型學校和科研機構肯定有實力為他們的學生和教職員工購買許可證,但這下好了我們窮人也可以進入邁過過這個門檻了,
微軟發布530B引數模型,但是它仍然只是一篇博客文章!他們聲稱這是迄今為止最大的monolithic transformer;你可能會問monolithic 是啥意思?這是一種使用所有引數的方式,與專家混合 (MoE) 型別的模型不同,例如 Wu Dao 的 1.75 萬億或 Switch Transformer 的萬億(在每個推理/訓練步驟中只激活較小的子集),雖然龐大的規模看起來非常令人難以置信,但我們必須等到他們更深入地分享才能夠了解細節,說到引數,我們現在還是關心他們的大小,
人工智能投資者 Nathan Benaich 和 Ian Hogarth 最近發布了《2021 年人工智能狀況報告》(www.stateof.ai),它提供了有用的 AI 年度執行摘要:研究、行業、人才、政治和預測,絕對值得一讀!
如果你想嘗試用于計算機視覺的基于注意力的大型架構, Scenic [4] 最近發布一個代碼庫(包含大量樣板代碼和示例)來運行用于計算機視覺的 JAX 模型,包括幾個 Vision Transformer [6]、ViViT [7] 等等,
如果你正在使用影像的生成模型,可以關注下VQGAN-CLIP,這是一個可以將自然語言句子轉換為影像,
下面來看看論文:
Recursively Summarizing Books with Human Feedback
By OpenAI et al.
非常長的檔案摘要(例如書籍規模)對于機器來說是一項艱巨的任務,主要是因為注釋資料非常耗時:要注釋一個示例,一個人需要閱讀一本書并得出它的摘要, 這需要幾個小時甚至幾天,
長摘要可以(在某種程度上)成功地分解為分批式摘要任務,這些任務的注釋成本更低:將一本書分成幾塊,然后將每個塊總結成摘要, 連接這些摘要并總結它們, 遞回地應用此程序,直到達到所需的全書摘要長度,
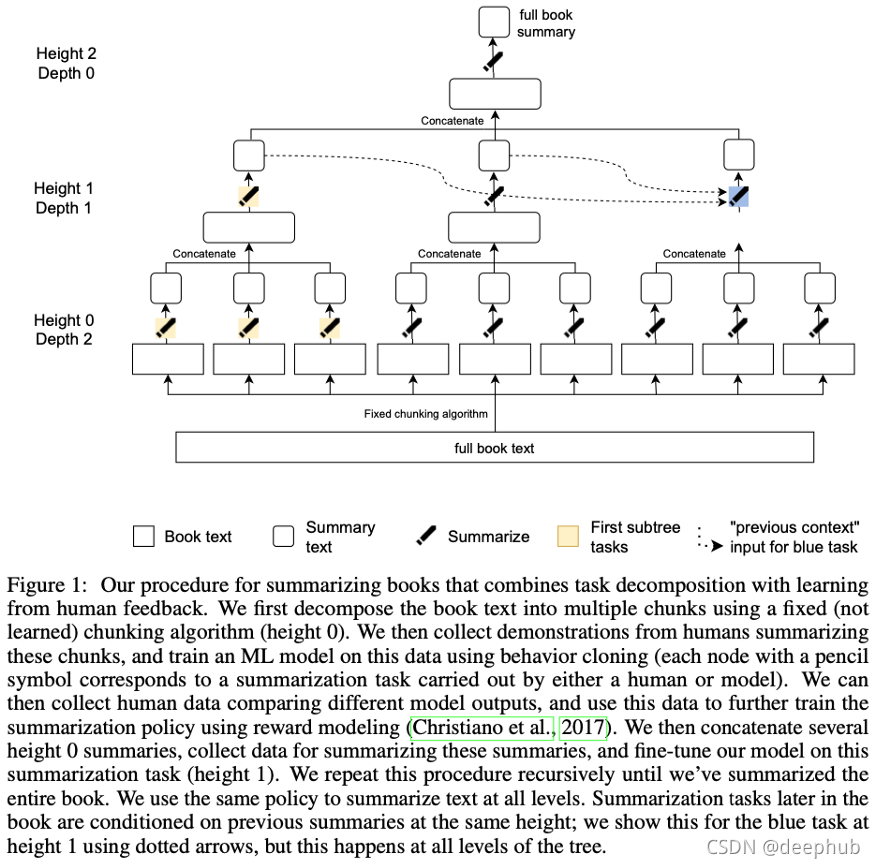
我們來大致了解一下所涉及的資料的規模:使用了40本書,平均10萬字,大部分是小說,每個摘要子任務壓縮的比例約為5-10比1,
這一程序的結果仍然與人類的質量相去甚遠,只有5%的摘要達到了可比的質量,有趣的是,模型大小似乎起著重要作用,因為他們從最大的模型中總結出來的結論明顯優于遵循同樣訓練程序的較小模型,
這又是一次令人印象深刻的人工回圈訓練復雜大型模型的作業, 距離產生“哇,這真是太棒了”的感徑訓差得很遠,但這是一個開始, 接下來可能的研究方向是如何將其轉化為只需要很少或非常稀疏的人類注釋的場景?
Multitask Prompted Training Enables Zero-Shot Task Generalization
By Victor Sanh, Albert Webson, Colin Raffel, Stephen H. Bach. et al.
驚人的大型模型研究主要限于擁有大量預算的公司, 這是 Hugging Face BigScience Workshop 的第一篇論文,該論文提出合作方式使大規模 ML 對大學等小型機構可行, 這不是第一個開源的大型 GPT-3 樣模型(例如查看 GPT-J),但這肯定會產生影響,
他們談論的是一個 110 億引數模型,完全開源并可通過 🤗Hugging Face 訪問,
model = AutoModelForSeq2SeqLM.from_pretrained("bigscience/T0pp")
你可以在GitHub repo上查看專案的所有細節,其中包括每個模型變體的訓練的詳細描述,
該模型是一個t5風格的1encoder-decoder Transformer(與GPT-3的僅限解碼器架構不同),它通過自回歸語言建模來預測下一個令牌,然而,現在訓練集的管理更加細化:除了使用通用語言的大型網路爬蟲,作者還建議使用帶有標簽的自然語言提示的NLP任務,例如,對于帶有注釋的電影評論的句子分類任務,例如
The film had a superb plot, enhanced by the excellent work from the main actor. | Positive
將會被模板轉換為:
The film had a superb plot, enhanced by the excellent work from the main actor. It was <great/amazing/fantastic...>.
為了避免對一組模板進行過度優化,這些模板來自多個來源 (36) 以最大限度地提高多樣性,并為 NLP 任務提供數十個可多交替使用的模板,
即使比 GPT-3 小 16 倍,并且在訓練期間沒有看到這些任務的訓練集,T0 在大多數任務中也優于 GPT-3 ,
以下是主要結果的摘要,
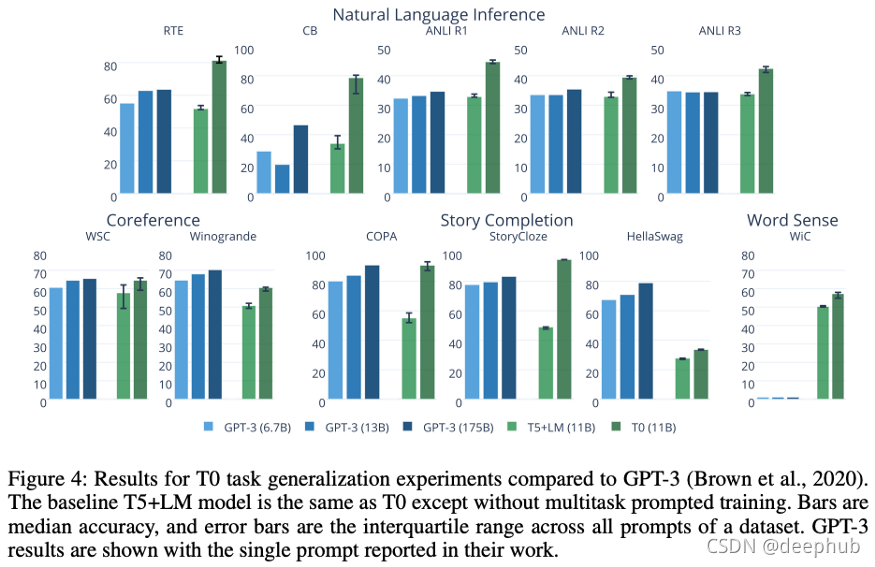
你可能已經注意到這種方法與 Google 幾周前發布的 FLAN [1] 非常相似, 作者徹底解決了這項作業,T0 仍然有很多作業要做:T0 和 +/++ 變體具有相當或更好的性能,同時小 10 倍(137B 與 11B 引數!!!),
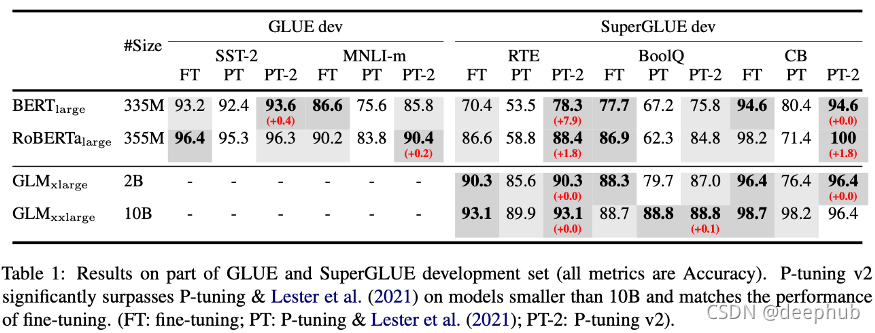
P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks
By Xiao Liu, Kaixuan Ji, Yicheng Fu et al.
continuous p-tuning/prompt-tuning/prefix-tuning 被提出還不到一年時間 [3],它已經成為許多任務中微調的可行替代方案和 ML 研究的一個蓬勃發展的方向,這是它最新的修訂版,顯示了 p-tuning 的優勢,
p-tuning(也稱為prefix-tuning、soft 或continuous prompt-tuning)是一種在不改變預訓練引數模型的情況下為特定任務微調預訓練模型的技術,它包括通過幾個連續嵌入的梯度下降來學習Prompt ,這些嵌入是任何輸入的固定前綴,這已經證明在使用自回歸語言建模訓練的 Transformer 上表現非常好,并且引數效率更高(即,與完全微調相比,特定任務只需要學習非常少的引數),
作者在這項作業中采取的進一步措施是為Prompt 添加“深度”,也就是在一個 Transformer 的不同層添加各種Prompt ,雖然這增加了可訓練引數的數量,但它提高了性能,同時將總模型引數與可訓練Prompt 的比率保持在 0.1-3% 的范圍內,它們在層間相互獨立(它們在每一層獨立訓練,而不是來自Transformer 的前向傳遞),
希望在不久的將來看到 p-tuning 應用于其他任務!
Exploring the Limits of Large Scale Pre-training
By Samira Abnar, Mostafa Dehghani, Behnam Neyshabur and Hanie Sedghi.
規模一直是機器學習圈子內一個持續討論的話題,這絕對是該領域必須解決的重要問題之一:引數和資料將在多大的規模才夠用?
本文的主旨很簡單,“隨著我們提高上游(US)準確性,下游(DS)任務的性能會飽和”,
他們研究了上游任務(例如大規模影像標簽)的預訓練性能如何轉移到下游性能(例如鯨魚檢測),然后對架構和規模進行很多的實驗:“在Vision Transformers、MLP-Mixers 和 ResNet 上進行 4800 次實驗,引數數量從一千萬到一百億不等,資料使用的是最大規模的可用的影像資料”🤑💸
以下的圖比較了上游性能,這意味著在預訓練任務上的性能,以及在評估任務上的下游性能,它最終幾乎全面飽和,盡管如此,計算機視覺架構之間的差異仍然非常有趣!
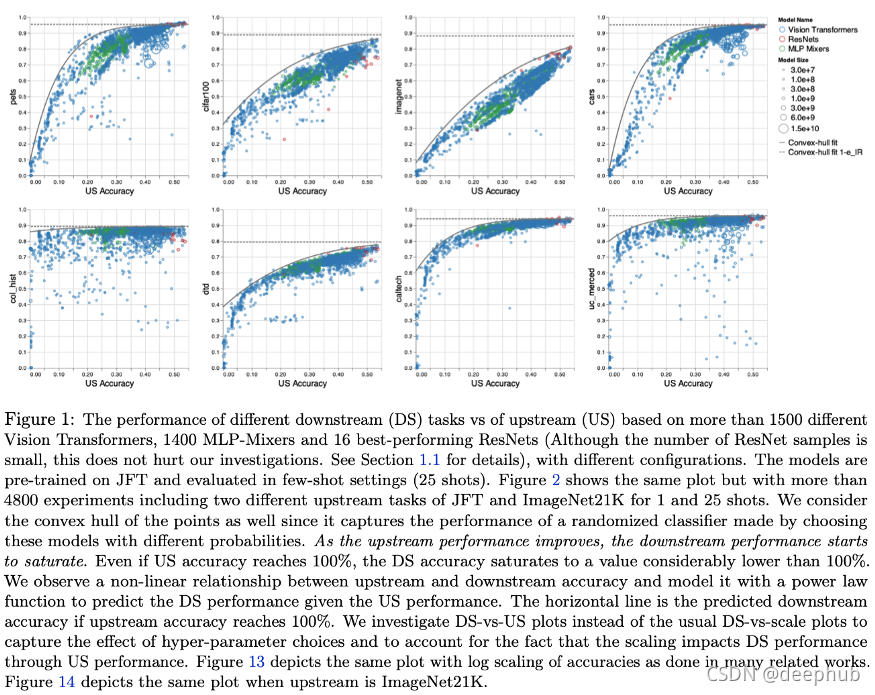
他們還探討了超引數選擇的影響:是否一些超引數對上游非常有益,但不能很好地轉化為下游? 是的! 他們在第 4 節深入探討了這種現象,并發現例如權重衰減是一個特別顯著的超引數,它對上游和下游的性能產生不同的影響,
在沒有人真正從頭開始訓練模型而是選擇預先訓練的模型來引導他們的應用程式的情況下,這項研究是關鍵, 這篇論文的內容比幾段總結的要多得多,如果想深入了解,絕對值得一讀!
A Few More Examples May Be Worth Billions of Parameters
By Yuval Kirstain, Patrick Lewis, Sebastian Riedel and Omer Levy.
增加新標注還是設計更大的模型?對于ML實踐者來說,在決定如何分配資源時,這可能是一個常見的困境:更大的預訓練模型還是標注更多的資料,視情況而定!
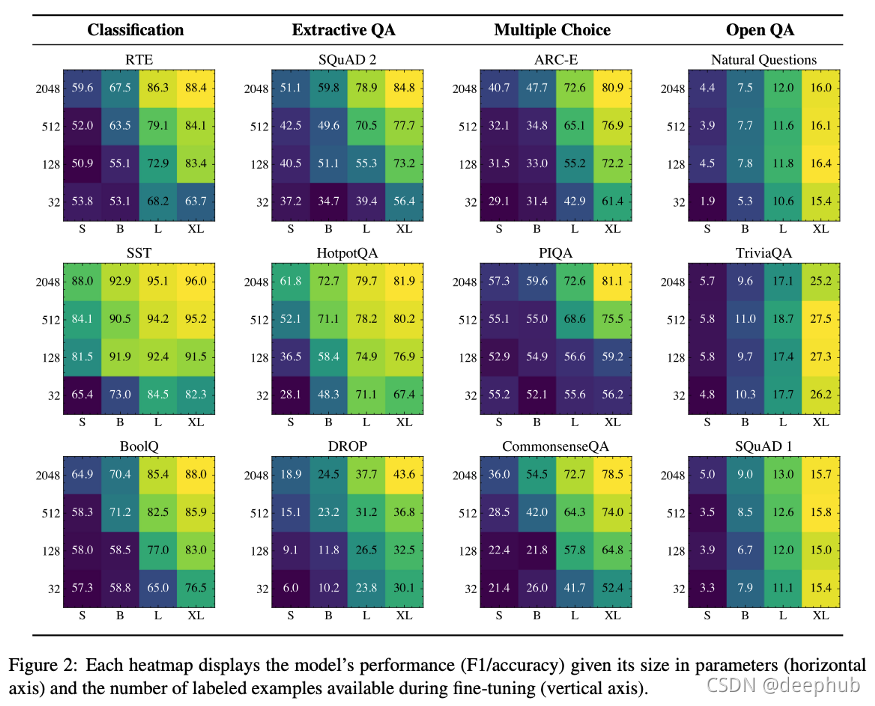
本文主要結論是,在NLP任務的背景關系中,可伸縮引數始終能帶來性能改進,然而,附加標注的貢獻在很大程度上取決于任務,例如,在開放式問題回答資料集中,添加標注并不能顯著提高性能,而在句子分類或抽取式問題回答中卻可以,下面是本文研究結果的最佳總結圖,人們可能會期望熱圖沿著對角線有一個梯度:大小和標注都能提高性能,但事實并非如此,
SpeechT5: Unified-Modal Encoder-Decoder Pre-training for Spoken Language Processing
By Junyi Ao, Rui Wang, Long Zhou et al.
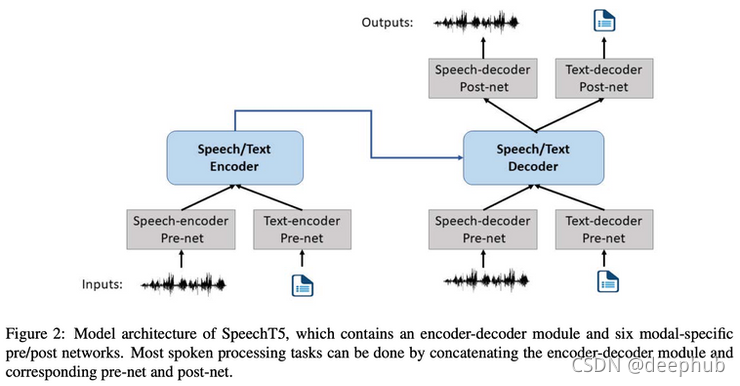
NLP幾乎經常被用作文本處理的同義詞,但自然語言比文本要多得多!口語使用了比文字更多的表達方式,這里有一種方法,通過利用過去幾年在NLP中非常成功的現有技術來對所有這些進行建模,
通過向模型提供音頻和文本來共同學習文本和語音表征,并在一個自監督設定中訓練,其任務類似于應用于聲音的雙向掩碼語言建模, 但是將 MLM 應用于音頻并不像文本那么簡單,它涉及將音頻預處理為合適的表示,稱為 log-Mel 濾波器,并在可以執行分類任務的這種表示狀態中應用量化目標, 重要的是,音頻和文本表征被組合并聯合輸入到模型,允許跨模態建模,
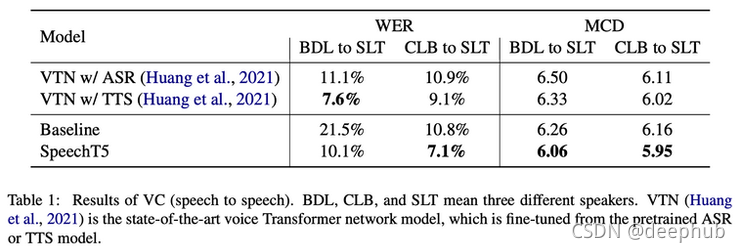
結果對于語音轉換 (VC)、自動語音識別 (ASR) 等某些任務來說是最先進的,并且在應用于文本到語音和語音到類 (SID) 時具有競爭力,
ADOP: Approximate Differentiable One-Pixel Point Rendering
By Darius Rückert, Linus Franke and Marc Stamminger.
與傳統技術相比,使用神經網路以更低的計算成本改進渲染是非常令人興奮的,特別是在 VR 和 AR 領域緩慢但穩定起飛的時候(你好 Meta),畢竟深度學習可能在渲染元宇宙方面發揮關鍵作用……
渲染場景視圖(例如在視頻游戲或模擬中)是一個令人印象深刻的復雜程序:3D 物件可以通過多種方式定義,照明、遮擋、紋理、透明度、反射以復雜的方式互動,將內容光柵化為像素網格等,對于低延遲應用程式來說,強制執行這些任務是不可能的;相反,程式必須聰明地不計算不需要計算的東西,例如被其他不透明物件遮擋的物件,
事實證明,渲染中涉及的大多數程序都可以由可微模塊執行,這意味著在給定適當的損失函式的情況下,可以使用梯度下降來優化它們,渲染場景的新視圖所涉及的主要模塊是光柵化器、渲染器和色調映射器,如下圖所示,
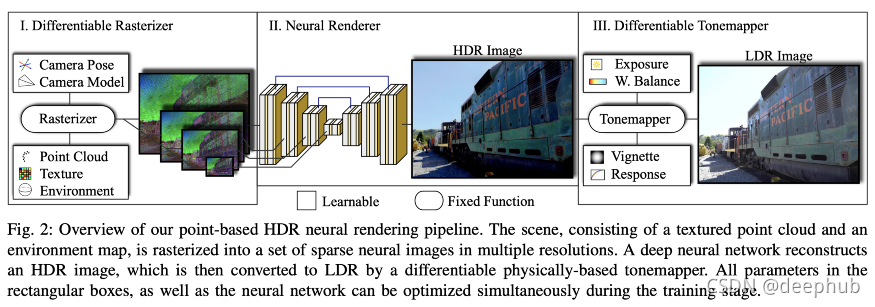
我不能說得太詳細,因為老實說這個話題有點超出我的能力, 他們提供的視頻演示還是相當令人印象深刻,我迫不及待地期待這種技術被主流渲染技術廣泛采用,
其他
在人工智能的倫理方面,上個月還看到了幾篇有趣的論文
《Delphi: Towards Machine Ethics and Norms》 讓機器了解是非的錯綜復雜, 雖然這項任務的復雜性在數千年來一直未能達成哲學共識,但這項作業是朝著將倫理判斷引入演算法邁出的切實一步,
《Systematic Inequalities in Language Technology Performance across the World’s Languages 》介紹了一個評估語言技術“全球效用”的框架,以及它如何涵蓋世界各地的語言多樣性,
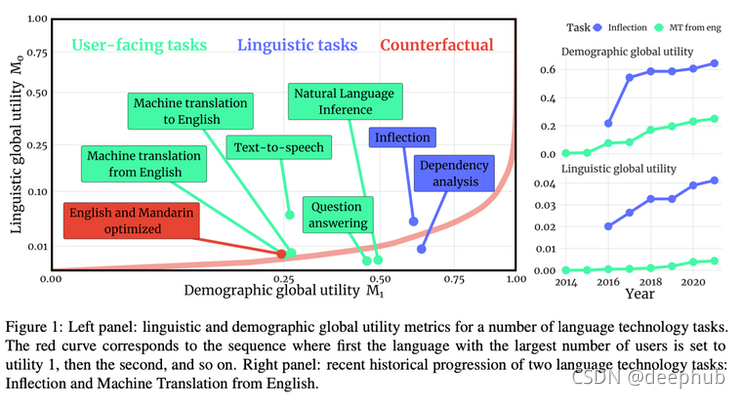
在資訊檢索的主題上,用于密集文本檢索的 《Adversarial Retriever-Ranker》 是一種令人興奮的新方法,可以為 2 階段檢索設定的檢索器和排名器之間的互動建模,檢索器試圖用“似乎相關”但實際上并不相關的檔案愚弄排名者,而排名者試圖顯示最重要的相關性標簽檔案,
論文參考:
[1] Finetuned Language Models Are Zero-Shot Learners. By Jason Wei, Maarten Bosma, Vincent Y. Zhao, Kelvin Guu et al. 2021
[2] SuperGLUE: A Stickier Benchmark for General-Purpose Language Understanding Systems. By Alex Wang, Yada Pruksachatkun, Nikita Nangia, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, Samuel R. Bowman, 2019.
[3] Prefix-Tuning: Optimizing Continuous Prompts for Generation. By Xiang Lisa Li, Percy Liang, 2021.
[4] SCENIC: A JAX Library for Computer Vision Research and Beyond. By Mostafa Dehghani, Alexey Gritsenko, Anurag Arnab, Matthias Minderer, Yi Tay, 2021.
[6] An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. By Alexey Dosovitskiy et al. 2020.
[7] ViViT: A Video Vision Transformer. By Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lu?i?, Cordelia Schmid, 2021.
作者:Sergi Castella i Sapé
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/350799.html
標籤:AI
上一篇:機器學習中的距離計算方法