python 機器學習 一元和二元多項式回歸
一元多項式
一元多項式運算式為:
Y
=
W
T
X
=
[
w
0
+
w
1
+
?
+
w
n
]
?
[
1
+
x
+
?
+
x
n
?
1
]
T
Y=W^TX=\left[ w_0+w_1+\cdots +w_n \right] \cdot \left[ 1+x+\cdots +x^{n-1} \right] ^T
Y=WTX=[w0?+w1?+?+wn?]?[1+x+?+xn?1]T
其中高次項為一次項的高次冪,將該式寫為多元運算式:
Y
=
W
T
X
=
[
w
0
+
w
1
+
?
+
w
n
]
?
[
x
1
+
x
2
+
?
+
x
n
]
T
Y=W^TX=\left[ w_0+w_1+\cdots +w_n \right] \cdot \left[ x_1+x_2+\cdots +x_n \right] ^T
Y=WTX=[w0?+w1?+?+wn?]?[x1?+x2?+?+xn?]T
其中,xn=x^(n+1),n=0,1,2…,n-1
這里使用梯度下降演算法擬合一元二次多項式方程:
假設其函式(X,Y)的函式映射關系為:
h
θ
(
x
)
=
θ
0
+
θ
0
×
x
+
θ
0
×
x
2
h_{\theta}\left( x \right) =\theta _0+\theta _0\times x+\theta _0\times x^2
hθ?(x)=θ0?+θ0?×x+θ0?×x2
損失函式選擇均平方誤差MSE:
J
(
θ
)
=
1
2
m
∑
i
=
1
m
(
h
θ
(
x
(
i
)
)
?
y
(
i
)
)
2
J\left( \theta \right) =\frac{1}{2m}\sum_{i=1}^m{\left( h_{\theta}\left( x^{\left( i \right)} \right) -y^{\left( i \right)} \right)}^2
J(θ)=2m1?i=1∑m?(hθ?(x(i))?y(i))2
引數θ關于J(θ)的梯度為:
?
J
?
θ
j
=
1
m
∑
i
=
1
m
(
h
θ
(
x
(
i
)
)
?
y
(
i
)
)
x
j
(
i
)
\frac{\partial J}{\partial \theta _j}=\frac{1}{m}\sum_{i=1}^m{\left( h_{\theta}\left( x^{\left( i \right)} \right) -y^{\left( i \right)} \right)}{x_j}^{\left( i \right)}
?θj??J?=m1?i=1∑m?(hθ?(x(i))?y(i))xj?(i)
所以其引數更新公式為:
θ
j
=
θ
j
?
α
?
J
?
θ
j
=
θ
j
?
α
m
∑
i
=
1
m
(
h
θ
(
x
(
i
)
)
?
y
(
i
)
)
x
j
(
i
)
\theta _j=\theta _j-\alpha \frac{\partial J}{\partial \theta _j}=\theta _j-\frac{\alpha}{m}\sum_{i=1}^m{\left( h_{\theta}\left( x^{\left( i \right)} \right) -y^{\left( i \right)} \right)}{x_j}^{\left( i \right)}
θj?=θj??α?θj??J?=θj??mα?i=1∑m?(hθ?(x(i))?y(i))xj?(i)
α為學習率
生成資料
待擬合函式為:
y
=
2
+
3
×
x
+
2
×
x
2
y=2+3\times x+2\times x^2
y=2+3×x+2×x2
使用numpy.random.normal()函式為資料添加噪聲,(高斯噪音):
y_noise=np.random.normal(loc=0,scale=1,size=len(x))
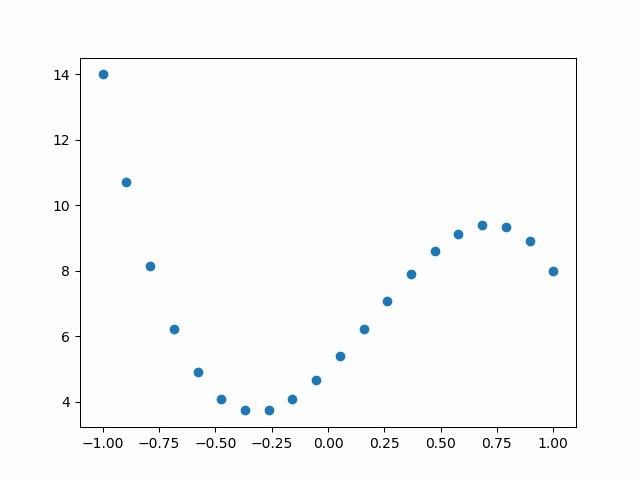
下圖為生成資料散點圖:
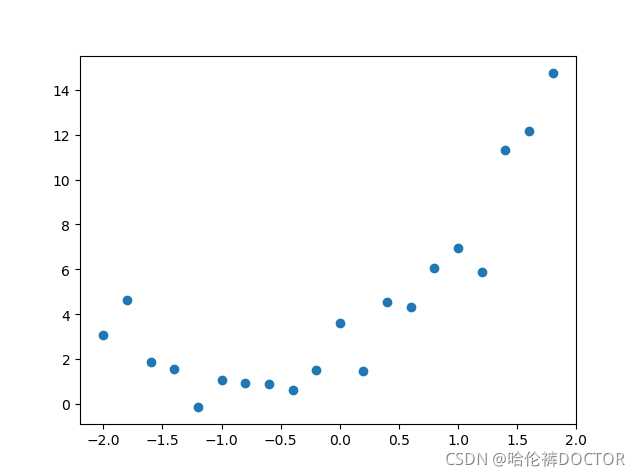
具體代碼為:
import matplotlib.pyplot as plt
import numpy as np
x=np.arange(-2,2,0.2)
def Y():
return 2+3*x+2*x**2 #待擬合函式
y=Y()
##噪音
# x_noise=np.random.normal(loc=0,scale=0,size=len(x)) #可為x添加隨機擾動
y_noise=np.random.normal(loc=0,scale=1,size=len(x))
#x=x+x_noise
y=y+y_noise
x_train=np.stack((np.linspace(1,1,len(x)),x,x**2),axis=1) #使用np.stack(將X0,X1,X2)合成待訓練資料
y_train=y
plt.scatter(x,y_train)
plt.show()
x_train的生成原理:
x
_
t
r
a
i
n
=
[
x
0
x
1
x
2
]
=
[
1
x
x
2
]
x\_train=[x_0\ x_1\ x_2]=[1\ x\ x^2]
x_train=[x0? x1? x2?]=[1 x x2]
最后使用梯度下降方式實作PYTHON引數更新代碼為:
import matplotlib.pyplot as plt
import numpy as np
x=np.arange(-2,2,0.2)
def Y():
return 2+3*x+2*x**2
y=Y()
x_noise=np.random.normal(loc=0,scale=0,size=len(x))
y_noise=np.random.normal(loc=0,scale=1,size=len(x))
x=x+x_noise
y=y+y_noise
x_train=np.stack((np.linspace(1,1,len(x)),x,x**2),axis=1)
y_train=y
plt.scatter(x,y_train)
m=len(x_train)
theat=np.array([0,0,0])
lr=0.009
def Y_pred(x,a):
return a[0]*x[0]+a[1]*x[1]+a[2]*x[2]
def partial_theat(x,y,a):
cost_all=np.array([0,0,0])
for i in range(m):
cost_all=cost_all+(Y_pred(x[i],a)-y[i])*x[i]
return 1.0/m*cost_all
def J(x,y,a):
cost=0
for i in range(m):
cost=cost+(Y_pred(x[i],a)-y[i])**2
return (1/2*m)*cost
iterations=0
theat_list=np.array([0,0,0])
while(True):
# plt.scatter(x_train,y_train)
# plt.plot(np.arange(-3,3,0.1),theat[0]*np.arange(-3,3,0.1)+theat[1])
theat=theat-lr*partial_theat(x_train,y_train,theat)
theat_list=np.vstack((theat_list,theat))
iterations=iterations+1
if(np.abs(J(x_train,y_train,theat_list[-1])-J(x_train,y_train,theat_list[-2]))<0.001):
break
print(theat_list[-1],theat_list.shape)
x_t=np.linspace(-2,2,20)
x_test=np.stack((np.linspace(1,1,20),x_t,x_t**2),axis=1)
##plt.plot(x,theat[0]+x_t*theat[1]+x_t**2*theat[2])
from matplotlib.animation import FuncAnimation
fig,ax=plt.subplots()
atext_anti=plt.text(0.2,2,'',fontsize=15)
btext_anti=plt.text(1.5,2,'',fontsize=15)
ctext_anti=plt.text(3,2,'',fontsize=15)
ln,=plt.plot([],[],'red')
def init():
ax.set_xlim(np.min(x_train),np.max(x_train))
ax.set_ylim(np.min(y_train),np.max(y_train))
return ln,
def upgrad(frame):
x=x_t
y=frame[0]+frame[1]*x+frame[2]*x**2
ln.set_data(x,y)
atext_anti.set_text('a=%.3f'%frame[0])
btext_anti.set_text('b=%.3f'%frame[1])
ctext_anti.set_text('c=%.3f'%frame[2])
return ln,
ax.scatter(x,y_train)
ani=FuncAnimation(fig,upgrad,frames=theat_list,init_func=init)
plt.show()
梯度下降演算法擬合程序動圖如下:
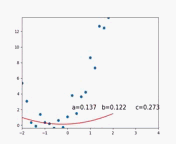
最后擬合結果為:
y
=
1.86
+
3.07
×
x
+
1.92
×
x
2
y=1.86+3.07\times x+1.92\times x^2
y=1.86+3.07×x+1.92×x2
迭代次數為622次,擬合精度為0.001,擬合效果較好,與原始函式引數產生差距是因為噪聲關系,
這里不對代碼進行解釋,感興趣的可點擊這里,里面有代碼的具體解釋,
二元多項式
設函式中的二元變數分別為x1和x2,其與y之間的多項式運算式關系為:
y
=
5
?
2
x
1
+
3
x
2
+
3
x
1
2
?
x
2
2
+
4
x
1
x
2
?
10
x
1
3
y=5-2x_1+3x_2+3{x_1}^2-{x_2}^2+4x_1x_2-10{x_1}^3
y=5?2x1?+3x2?+3x1?2?x2?2+4x1?x2??10x1?3
設該二元函式多項式運算式為:
h
θ
(
x
)
=
??
[
θ
0
?
θ
11
]
T
?
[
x
0
??
x
1
??
x
2
??
x
1
x
2
??
x
1
2
??
x
2
2
??
x
1
x
2
2
??
x
2
x
1
2
??
x
1
2
x
2
2
??
x
1
3
??
x
2
3
]
??
h_{\theta}\left( x \right) =\,\,\left[ \begin{array}{c} \theta _0\\ \vdots\\ \theta _{11}\\ \end{array} \right] ^T\cdot \left[ \begin{array}{c} x_0\,\,x_1\,\,x_2\,\,x_1x_2\,\,{x_1}^2\\ \,\,{x_2}^2\,\,x_1{x_2}^2\,\,x_2{x_1}^2\,\,\\ {x_1}^2{x_2}^2\,\,{x_1}^3\,\,{x_2}^3\\ \end{array} \right] \,\,
hθ?(x)=????θ0??θ11??????T????x0?x1?x2?x1?x2?x1?2x2?2x1?x2?2x2?x1?2x1?2x2?2x1?3x2?3????
將上式中變數用z替換,則原式為:
h
θ
(
z
)
=
??
[
θ
0
?
θ
11
]
T
?
[
z
0
??
z
1
??
z
2
??
z
3
??
z
4
??
z
5
??
z
6
??
z
7
??
z
8
??
z
9
??
z
10
]
h_{\theta}\left( z \right) =\,\,\left[ \begin{array}{c} \theta _0\\ \vdots\\ \theta _{11}\\ \end{array} \right] ^T\cdot \left[ \begin{array}{c} z_0\,\,z_1\,\,z_2\,\,z_3\,\,z_4\,\,z_5\\ \,\,z_6\,\,z_7\,\,z_8\,\,z_9\,\,z_{10}\\ \end{array} \right]
hθ?(z)=????θ0??θ11??????T?[z0?z1?z2?z3?z4?z5?z6?z7?z8?z9?z10??]
引數更新公式和損失函式與一元多項式相同,直接上代碼:
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
import numpy as np
x1=np.linspace(-1,1,20)
x2=np.linspace(2,4,20)
np.random.seed=7
def Y():
return 5-2*x1+3*x2+3*x1**2-x2**2+4*x1*x2-10*x1**3
y=Y()
y_noise=np.random.normal(loc=0,scale=1,size=len(x1))
x_train=np.stack((np.linspace(1,1,len(x1)),x1,x2,x1*x2,x1**2,x2**2,x1*x2**2,x2*x1**2,x1**2*x2**2,x1**3,x2**3),axis=1)#,x1**3,x2**3,x1*x2**3,x1**2*x2**3,x2*x1**3,x2**2*x1**3,x1**3*x2**3
y_train=y+y_noise
features=x_train.shape[1]
m=len(x_train)
theat=np.linspace(1,1,features)*0
lr=0.001
def Y_pred(x,a):
return np.dot(x,a)
def partial_theat(x,y,a):
cost_all=np.linspace(1,1,features)*0
for i in range(m):
cost_all=cost_all+(Y_pred(x[i],a)-y[i])*x[i]
return 1.0/m*cost_all
def J(x,y,a):
cost=0
for i in range(m):
cost=cost+(Y_pred(x[i],a)-y[i])**2
return (1/2*m)*cost
theat_list=np.linspace(1,1,features)*0
while(True):
theat=theat-lr*partial_theat(x_train,y_train,theat)
theat_list=np.vstack((theat_list,theat))
if(np.abs(J(x_train,y_train,theat_list[-1])-J(x_train,y_train,theat_list[-2]))<0.001):
break
print(theat_list[-1],theat_list.shape)
theat_list=theat_list[0:theat_list.shape[0]:500,:]
from matplotlib.animation import FuncAnimation
fig,ax=plt.subplots()
ln,=plt.plot([],[],'red')
def upgrad(frame):
y=np.dot(x_train,frame)
ln.set_data(x1,y)
return ln,
plt.scatter(x1,y_train)
ani=FuncAnimation(fig,upgrad,frames=theat_list,interval=100)
ani.save('二元多項式.gif',writer='pillow')
plt.show()
迭代次數3萬多次,計算相對復雜一些,而且與原函式各引數有所不同,
原函式關系:
y
=
5
?
2
x
1
+
3
x
2
+
3
x
1
2
?
x
2
2
+
4
x
1
x
2
?
10
x
1
3
y=5-2x_1+3x_2+3{x_1}^2-{x_2}^2+4x_1x_2-10{x_1}^3
y=5?2x1?+3x2?+3x1?2?x2?2+4x1?x2??10x1?3
當有噪音時的擬合函式結果為:
h
θ
(
x
)
=
?
?
[
0.57550069
?
1.43501733
0.29148473
?
1.05994284
3.24510915
?
0.18548867
0.73316333
3.91299186
?
1.30377424
?
5.8223356
0.17669733
]
T
?
[
x
0
??
x
1
??
x
2
??
x
1
x
2
??
x
1
2
??
x
2
2
??
x
1
x
2
2
??
x
2
x
1
2
??
x
1
2
x
2
2
??
x
1
3
??
x
2
3
]
T
??
h_{\theta}\left( x \right) =\,\,^{\left[ \begin{array}{c} 0.57550069\\ -1.43501733\\ 0.29148473\\ -1.05994284\\ 3.24510915\\ -0.18548867\\ 0.73316333\\ 3.91299186\\ -1.30377424\\ -5.8223356\\ 0.17669733\\ \end{array} \right] ^T\cdot \left[ \begin{array}{c} x_0\,\,x_1\,\,x_2\,\,x_1x_2\,\,{x_1}^2\\ \,\,{x_2}^2\,\,x_1{x_2}^2\,\,x_2{x_1}^2\,\,\\ {x_1}^2{x_2}^2\,\,{x_1}^3\,\,{x_2}^3\\ \end{array} \right] ^T\,\,}
hθ?(x)=?????????????0.57550069?1.435017330.29148473?1.059942843.24510915?0.185488670.733163333.91299186?1.30377424?5.82233560.17669733??????????????T?[x0?x1?x2?x1?x2?x1?2x2?2x1?x2?2x2?x1?2x1?2x2?2x1?3x2?3?]T
跟原函式引數有較大差距
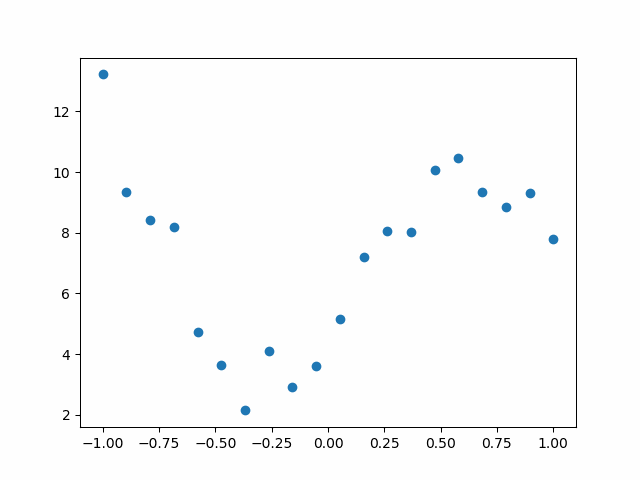
當無噪聲時,擬合結果為下圖,擬合結果與加入噪聲時的大致相同,所以,擬合函式結果與假設函式有關,雖然引數有所不同,但是函式誤差很小,基本與原函式重合,
為準確擬合原函式,可在損失函式中引入正則項以降低函式復雜度,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/350801.html
標籤:AI