作者:RayChiu_Labloy
著作權宣告:著作權歸作者所有,商業轉載請聯系作者獲得授權,非商業轉載請注明出處
目錄
概念
KNN相關的三個事情
1.K值的確定
2.距離的度量
計算距離注意一定要做資料縮放:歸一化和標準化
3.分類判別的方式方案
演算法基本步驟:
演算法python實作
優缺點
優點
缺點
概念
KNN,K-NearestNeighbor——K最近鄰
K最近鄰,就是k個最近的鄰居的意思,說的是每個樣本都可以用它最接近的k個鄰居來代表核心思想是如果一個樣本在特征空間中的k個最相鄰的樣本中的大多數屬于某一個類別,則該樣本也屬于這個類別,并具有這個類別上樣本的特性,
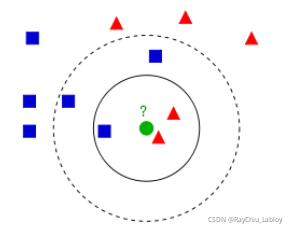
該方法的思路是:如果一個樣本在特征空間中的 k 個最相似(即特征空間中最鄰近)的樣本中的大多數屬于某一個類別,則該樣本也屬于這個類別.它不具有顯示的學習程序,
在 KNN中,通過計算物件間的距離來作為各個物件之間的非相似性指標,避免了物件之間的匹配問題,在這里距離一般使用歐氏距離或曼哈頓距離,對于文本分類來說,使用余弦來計算相似度就比歐式距離更合適:同時,KNN 通過依據 k 個物件中占優的類別進行決策,而不是單一的物件類別決策,這兩點就是 KNN 演算法的優勢,
KNN相關的三個事情
1.K值的確定
吳恩達的機器學習課程中,有一個方法,就是嘗試不同的k直,然后把誤差對應k值的圖畫出來,一般k值越大,平均誤差約小,如果圖有明顯的拐點,那么這個點對應的k就是一個比較合適的k值,很多情況下靠經(xia)驗(meng)來確定,沒有固定的經驗,一般根據樣本的分布,選擇一個較小的值,可以通過交叉驗證選擇一個合適的k值,一般采用5折(10折)交叉驗證選擇一個最優的準確率最高的k值,
選擇較小的k值,就相當于用較小的領域中的訓練實體進行預測,訓練誤差會減小,容易發生過擬合,選擇較大的k值,就相當于用較大領域中的訓練實體進行預測,其優點是可以減少泛化誤差,但缺點是訓練誤差會增大,
2.距離的度量
歐氏距離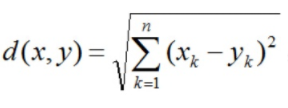
曼哈頓距離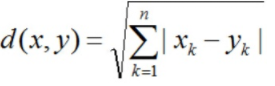
計算距離注意一定要做資料縮放:歸一化和標準化
3.分類判別的方式方案
多數表決法和平均值兩種方案,
演算法基本步驟:
1)計算待分類點與已知類別的點之間的距離
2)按照距離遞增次序排序
3)選取與待分類點距離最小的k個點
4)確定前k個點所在類別的出現次數
5)回傳前k個點出現次數最高的類別作為待分類點的預測分類
演算法python實作
"""
knn
樣本集
X = [[1,1],[1,2.5],[3,2],[4.5,3],[4,5]]
Y =['A','A','B','B','B']
測驗樣本:
t=[3,2.5] 屬于哪個型別
設k=3
knn的實作:
將待測驗樣本和所有的訓練進行計算,找出最短的k個元素
然后投票
"""
import numpy as np
import operator
X = np.array([[1,1],[1,2.5],[3,2],[4.5,3],[4,5]])
Y = np.array(['A','A','B','B','B'])
def knn_clasification(X,Y,k,testSample):
"""
:param X: 輸入資料
:param Y: 真實資料
:param k: 鄰居的個數
:param testSample: 待測驗樣本
:return: 回傳待測驗樣本類別
"""
# 1.求待測驗樣本和所有訓練樣本之間的距離
dist = np.sum((X-testSample)**2, axis=1)**0.5
# 2.距離排序
sort_dist = np.argsort(dist)
# 3.統計距離最近得k個樣本的類別的個數
class_count = {}
for dist_index in sort_dist[:k]:
label = Y[dist_index]
class_count[label] = class_count.get(label,0)+1
return sorted(class_count.items(), key=operator.itemgetter(1), reverse=True)[0][0]
if __name__ == "__main__":
predict = knn_clasification(X, Y, 3, np.array([3, 2]))
print(predict)
優缺點
優點
1.簡單好用,容易理解,精度高,理論成熟,既可以用來做分類也可以用來做回歸;
2.可用于數值型資料和離散型資料;
3.訓練時間復雜度比支持向量機之類的演算法低,僅為O(n);
4.和樸素貝葉斯之類的演算法比,對資料沒有假設,準確度高, 對例外點不敏感;
缺點
1.計算復雜性高;空間復雜性高,KD樹,球樹之類的模型建立需要大量的記憶體;
2.樣本不平衡問題(即有些類別的樣本數量很多,而其它樣本的數量很少);
3.一般數值很大的時候不用這個,計算量太大,但是單個樣本又不能太少 否則容易發生誤分,
4.最大的缺點是無法給出資料的內在含義,可解釋性不強,
5.使用懶散學習方法,基本上不學習,導致預測時 速度比起邏輯回歸之類的演算法慢
【如果對您有幫助,交個朋友給個一鍵三連吧,您的肯定是我博客高質量維護的動力!!!】
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/350808.html
標籤:AI