🐱?🏍寫博客的主要原因是為了鞏固所學知識 🐱?🏍
IP資料報格式
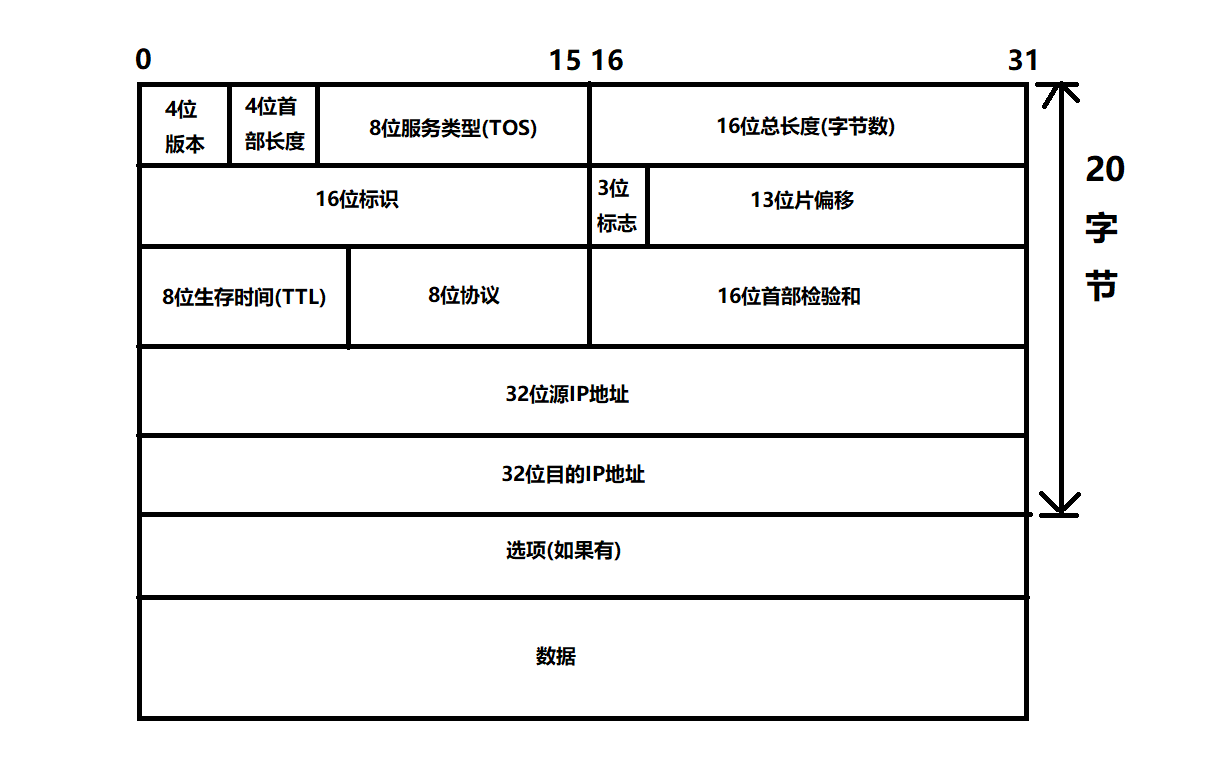
4位版本號(Version)
由4位元組成,用來指定IP協議的版本,IPv4的版本號為4,即0100,
4位首部長度(Header Length)
由4位元組成,表示IP協議的頭部長度,用來作為header和payload之間的區分,單位為4位元組,4位元位組成的最大的數為15,即1111,則header的最大長度則為60位元組,其中固定長度(去掉選項)為20位元組,
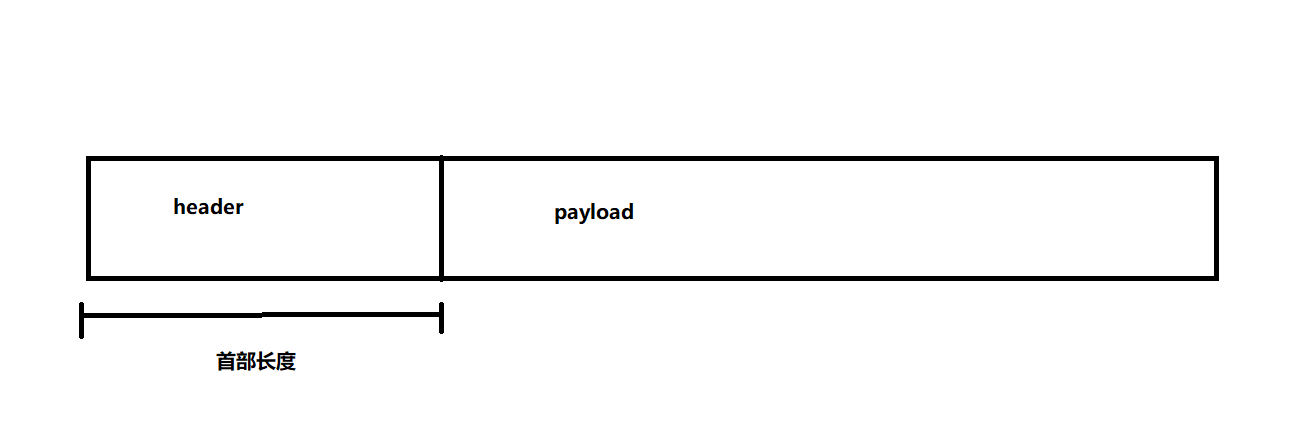
在資料報中,位元組都是連續的,那么怎么區分header和payload呢?就是依靠4位首部長度,
8位服務型別(TOS:Type Of Service)
0~2位優先權欄位(已經棄用),3~6位TOS欄位,第7位保留欄位(必須為0),
TOS欄位:
第3位: 最低延遲
第4位: 最大吞吐量
第5位: 最高可靠性
第6位: 最小成本
這四者互相沖突,只能選中的一個為1,其他的必須為0,不過現在幾乎所有的網路都無視這些欄位,是因為在符合質量要求的情況下按其要求發送本身的功能實作起來十分困難,還因為若不符合質量要求就可能會產生不公平的現象,
16位總位元組長度(Total Length)
由16位元位組成,表示header和payload合起來的位元組數,由于16位元組成最大的數為65536,所以IP資料報的最大長度為65535位元組(64K),和UDP一樣的大小,
那么IP資料報是如何傳輸大檔案的呢?
雖然IP協議看起來也是有個最大64k的限制,但是實際上IP協議內置了分包組包的功能 如果一個資料太長了,協議就會自動的拆成多個資料包,進行傳輸,然后接受方就會重新進行組包,
16位標識(ID:Identification)
由16位元位組成,由于IP協議會對大的資料進行分片,同一個分片的標志位相同,接受發可用根據16位標識進行組包,但是若標識位相同,但協議、源IP地址或者目的IP地址不同,也會被認為是不同的分片,
3位標志段(Flags)
由3位元位組成,表示包被分片的相關資訊,
第1位:保留欄位(保留的意思是現在不用,以后可能會用到),
第2位:指示是否進行分片(don't fragment)
如果該位為1,表示禁止分片,如果報文長度超過MTU(最大傳輸單元)后,
IP協議則丟棄該報文,
如果該位為0,表示可以分片,如果報文長度超過MTU(最大傳輸單元)后,
IP協議則會對其進行分片,
第3位:包被分片的情況下,表示是否為最后一個包,
0表示為最后一個分片的包,
1表示為分片中段的包,
13位分片偏移(framegament offset)
由13位元位組成,用來標識被分片的每一個分段相對于原始資料的位置,其實就是在表示當前分片在原始資料中處在哪個位置,
第一個分片的值為0,由于FO域占13位,因此最多可以表示 8192( = )個相對位置,單位為8位元組,因此最大可表示原始資料 8×8192=65536位元組的位置,
除了最后一個包之外,其他包的長度必須是8的整數倍(否則報文就不連續了),
8位生存時間(TTL:Time To Live)
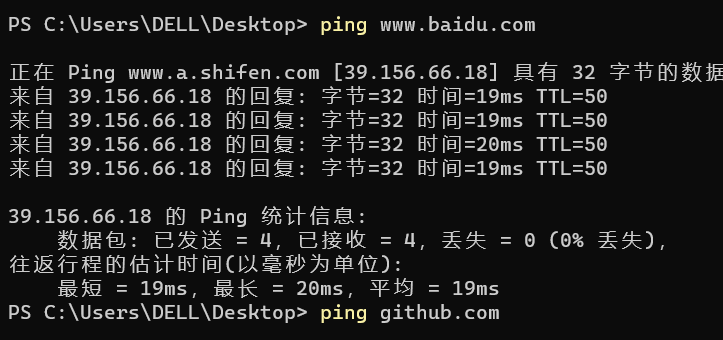
由8位元位組成,表示資料包到達目的地的最大報文跳數,它最初的意思是以秒為單位記錄當前包的生存期限,在實際中它是指可以中轉多少個路由器的意思, 每經過一個路由器,TTL會減少1,直到變成0則丟棄該包(TTL一般初始為64),
可以在控制臺輸入 ping + 網址 獲取到從本地到達目的地剩余的TTL
8位協議(Protocol)
由8位元位組成,表示上層協議型別,
TCP: 6
UDP: 17
16位首部校驗和(Header Checksum)
由16位元位構成,用來校驗資料報的首部,不校驗資料部分,
為什么不對資料部分進行效驗?
因為載荷部分就是一個完整的TCP/UDP資料報,由TCP和UDP本身進行效驗即可,
計算方式:
首先要將該校驗和的所有位置設定為0,然后以16位元為單位劃分IP首部,并用1補數(1補數 通常計算機中對整數運算采用2補數的方式,但在校驗和的計算中采用1補數運算方法,這樣做的優點在于即使產生進位也可以回到第1位,可以防止資訊缺失并且可以用2個0區分使用,) 計算所有16位字的和,最后將所得到這個和的1補數 賦給首部校驗和欄位,
源地址(Source Address)
由32位元位構成,表示發送端IP地址,
目標地址(Destination Address)
由32位元位構成,表示接收端IP地址,
選項
長度可變,通常只在進行實驗或診斷時使用,
資料
一個完整的上層資料報,

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/350945.html
標籤:其他
上一篇:演算法給小碼農二叉樹魂鎧戰衣