上一篇:7.1、堆排序的邏輯分析(演算法基礎—排序演算法)
經過上一篇邏輯分析,我們已經知道了堆排序的核心就是解決2個問題:
1、堆的一次向下調整
2、構建堆
但是如果我們仔細看下圖,會發現,其實構建堆的程序,就是多次完成“堆的一次向下調整”,只不過這個程序中,要按什么順序去先后調整各個子樹,是個需要考慮的問題,
一、構造堆應該以什么順序去調整子樹
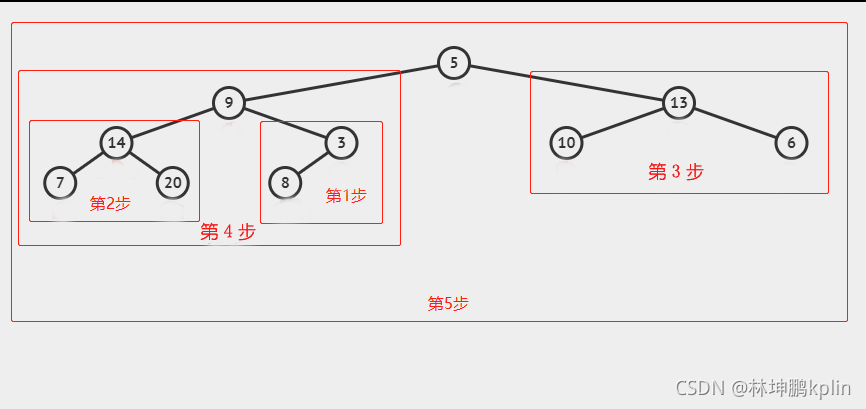
我們直接看每一步需要調整的子樹的根節點:
第一步的根節點:3
第二步的根節點:14
第三步的根節點:13
第四步的根節點:9
第五步的根節點:5
上面這個樹結構用串列來存盤其實就是:
li = [5, 9, 13, 14, 3, 10, 6, 7, 20, 8]
看看這些根節點在串列中的位置:
其實就是元素3前面的部分,從3的位置開始逆序掃描串列,步長為1,即可找出這些根節點的位置,
目前我們只知道最后一個葉子結點的位置是 len(li) - 1,也就是串列的長度減去1,
而根據前面我們總結的規律是:
1、當父節點的位置為 i 時,它的左孩子節點位置為:2*i+1,
它的右孩子節點的位置為:2*i+2;
2、當子節點的位置為 i 時,它的父節點的位置為: (i-1)//2
那最后一個葉子結點的父節點3的位置
其實就是 (len(li)-1-1)//2, 等同于 len(li)//2-1
所以我們可以找到最后一個非葉子節點的位置,再層層往上推,找到各個子樹的根節點位置,按這順序對每顆子樹都進行一次向下調整,就造堆成功了,
接著拿掉最大值,把最大值放進一個新串列,把最后一個葉子節點的拿到堆頂,又進行一次向下調整,重新得到一個堆,繼續把最大值拿掉,把最大值追加到串列…
重復這個程序,最后出來的串列就是一個排好序的串列了,
一個小優化:
上面我們是用一個新串列來存放最大值的,但為了節省空間,我們可以把最大值直接放在原來那串列的最后,并且標識下一次排序時,這個值不參與,最后出來的串列也同樣是排好序的,并且不需要另外開個串列占用存盤空間,
二、一次向下調整函式怎么寫?
我們先拿一個符合條件的圖來演示一下:
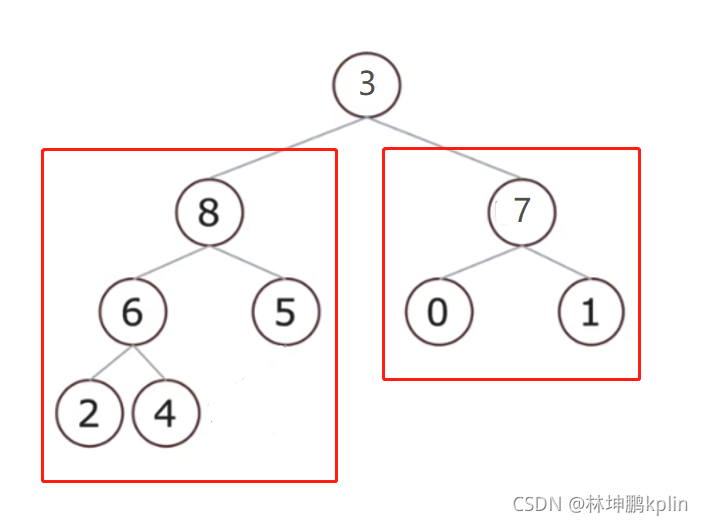
這個圖,堆頂不是最大值,但堆頂的左右兩個子樹,都符合堆的條件(父節點都比孩子節點大),所以我們可以通過一次調整,讓堆頂的3回到它應該待的位置去,并且把最大值推選上來,
這個二叉樹對應存放到串列應當是:
[3, 8, 7, 6, 5, 0, 1, 2, 4]
1、確認函式所需的引數
我們對這個二叉樹做一次向下調整其實就是在調整這個串列中元素的位置,
首先需要把串列傳進函式;
其次,我們要拿堆頂出來,把它放到合適的位置,所以也要知道堆頂的位置;
最后因為我們后面會不斷把最大值放到這個串列的最后,但這些值又不讓它們再次參與排序,所以我們需要有個引數來標識這個串列參與排序的最后一個元素的位置(其實就是用這個引數來邏輯標識等待排序的元素)
所以這個函式必須至少有三個引數:串列li,堆頂位置top,參與排序的最后一個元素的位置last
2、一次向下調整函式代碼+邏輯簡析
# 向下調整函式
def sift(li, top, last):
i = top # i 代表堆頂的位置
j = 2 * i + 1 # j 代表堆頂的左孩子
tmp = li[i]
while j <= last: # 只要j的位置有數,就一直回圈,確保不越界
if j < last and li[j] < li[j + 1]: # 如果右孩子比較大,就讓j指向右孩子
j += 1
if tmp < li[j]:
li[i] = li[j] # 上面已經是從左右2個孩子比較后,讓j指向更大的孩子了,這里就把更大的孩子放到原來tmp的位置
i = j # 把更大的值推選上去了,接下來讓i指向剛剛推選上去那個值的位置,也就是向下探一層,再次尋找比tmp更大的值
j = 2 * i + 1 # j同時也要開始往下一層走
else: # 通過上面的回圈對比之后,發現tmp已經是比較大的了,就把它放在i的位置
li[i] = tmp
break
li[i] = tmp # 上面跳出回圈的原因也有可能是j超出了位置,沒有j可以跟tmp對比了,此時跳出回圈,需要再次把tmp放到i位置
# 測驗一次向下調整
li = [3, 8, 7, 6, 5, 0, 1, 2, 4]
print('調整前:%s'%li)
sift(li, 0, len(li))
print('調整后:%s'%li)
測驗結果:
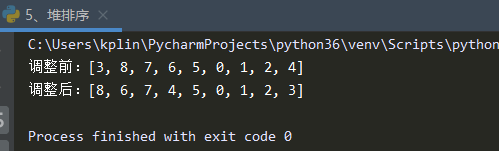
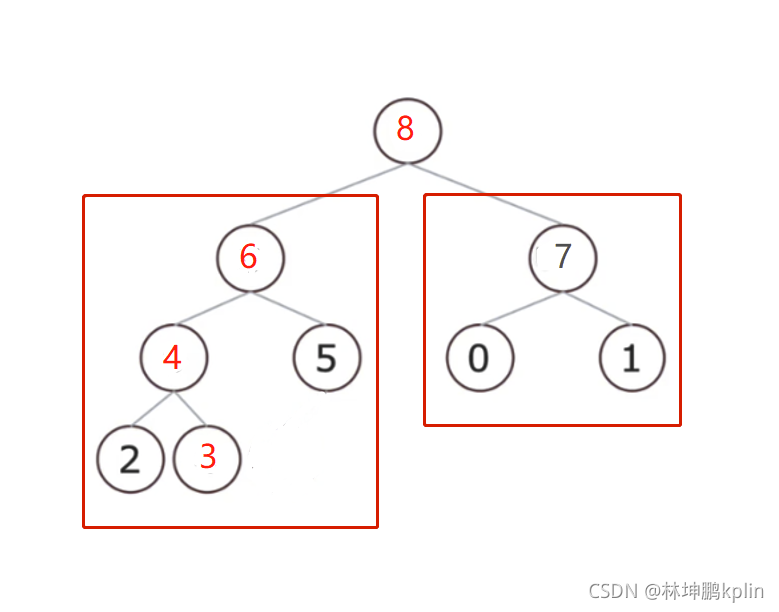
調整后的串列是符合預期的,如下圖所示,調整后的二叉樹能符合堆的性質
三、堆排序主函式代碼+邏輯簡析
完成最關鍵的一次向下調整函式后,我們就可以利用它來構造堆,并且多次調整,完成堆排序了,
針對以下代碼解釋一下:
1、i 代表堆頂的位置;
2、range(n//2-1, -1, -1)的第一個引數 n//2-1 是最后一個非葉子節點的位置,第二個引數-1是讓這個序列倒著遍歷,最后一個引數-1是指定步長,也就是向前移動1位,
這樣我們就能實作從最后一個非葉子節點的位置開始遍歷,每遍歷一次可以獲取到一個子樹的堆頂位置,
def heap_sort(li):
n = len(li)
# 開始建堆,i代表堆頂的位置
for i in range(n//2-1, -1, -1):
sift(li, i, n- 1) # 建堆完成
# 開始向下調整并逐一獲取最大值,放到串列最后
for i in range(n-1, -1, -1):
li[0], li[i] = li[i], li[0] # 先把堆頂的最大值和最后一個葉子結點調換位置,接著進行向下調整
sift(li, 0, i - 1) # 由于我們把最后一個結點的位置不斷往前移,代表這個二叉樹是一直在縮小的,
# 這個程序是為了排除掉那些由堆頂拎出來的最大值,不讓它們再繼續參與堆的向下調整程序
# 測驗堆排序
import random
li = list(range(100))
random.shuffle(li)
print('排序前:%s'%li)
heap_sort(li)
print('排序后:%s'%li)
測驗堆排序需要一個打亂的序列,可以使用random.shuffle(li)來打亂
li的順序,
四、完整代碼
# 向下調整函式
def sift(li, top, last):
i = top # i 代表堆頂的位置
j = 2 * i + 1 # j 代表堆頂的左孩子
tmp = li[i]
while j <= last:
if j < last and li[j] < li[j + 1]:
j += 1
if tmp < li[j]:
li[i] = li[j]
i = j
j = 2 * i + 1
else:
li[i] = tmp
break
li[i] = tmp
def heap_sort(li):
n = len(li)
# 開始建堆
for i in range(n // 2 - 1, -1, -1):
sift(li, i, n- 1) # 建堆完成
# 開始向下調整并逐一出數
for i in range(n - 1, -1, -1):
li[0], li[i] = li[i], li[0]
sift(li, 0, i - 1)
import random
li = list(range(100))
random.shuffle(li)
print('排序前:%s'%li)
heap_sort(li)
print('排序后:%s'%li)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/350946.html
標籤:其他
上一篇:IP協議資料報格式詳解