在前一篇文章中,我把Kaldi安裝并編譯了,相當于把利用Kaldi做語音識別的基本運行環境布置好了,這一篇文章記錄我用CVTE開源的kaldi模型來進行語音識別模型的建立和使用,
一、CVTE模型簡介及下載
CVTE Mandarin Model
Mandarin TDNN chain models trained on commercial data. The V1 model is deprecated; it is missing files needed to work with the current version of Kaldi. We recommended that you use the V2 model.
官方的介紹是說V1模型已經廢棄,建議使用V2模型,本文中使用的就是V2模型,
下載地址:http://kaldi-asr.org/models/m2
將下載后的模型解壓到kaldi目錄中的egs,即egs/cvte,要保證檔案kaldi/egs/cvte/s5的存在,
二、離線識別測驗
先準備需要測驗的語音檔案,格式要求16-bit位深,采樣率16000Hz,單聲道,wav格式(可以采用adobe audition軟體錄制),檔案詳細要求(可能是用sox工具來轉換的):
$ sox --info data/wav/chat001/001.wav
Input File : 'data/wav/chat001/001.wav'
Channels : 1
Sample Rate : 16000
Precision : 16-bit
Duration : 00:00:06.25 = 100000 samples ~ 468.75 CDDA sectors
File Size : 200k
Bit Rate : 256k
Sample Encoding: 16-bit Signed Integer PCM
上式參考:https://blog.csdn.net/samurais/article/details/107733688
也可以利用ffmpeg實作語音格式轉換的程序,可以參考我的另一篇文章:待補充,還在寫,
將測驗語音檔案.wav檔案放置在/egs/cvte/s5/data/wav/00030/下,這里由于還沒有語音格式轉換的工具,先用thchs30資料集中的wav檔案暫時代替一下,測驗用,
將egs/wsj/s5中的steps和utils拷貝到egs/cvte/s5目錄下
然后在Teminal中cd到egs/cvte/s5的目錄中
執行指令:
./run.sh
會出現錯誤:
Error!Both of the two phones-symbol tables are absent.
Please check your command
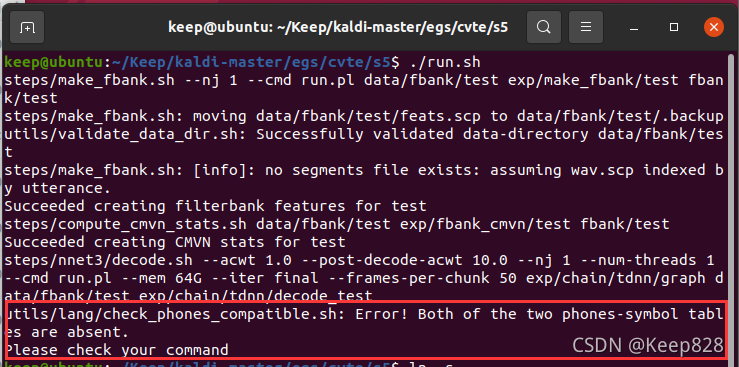
這個ERROR的出現,原因是CVTE作者沒有提供phones.txt, 不影響結果,忽略就好了,
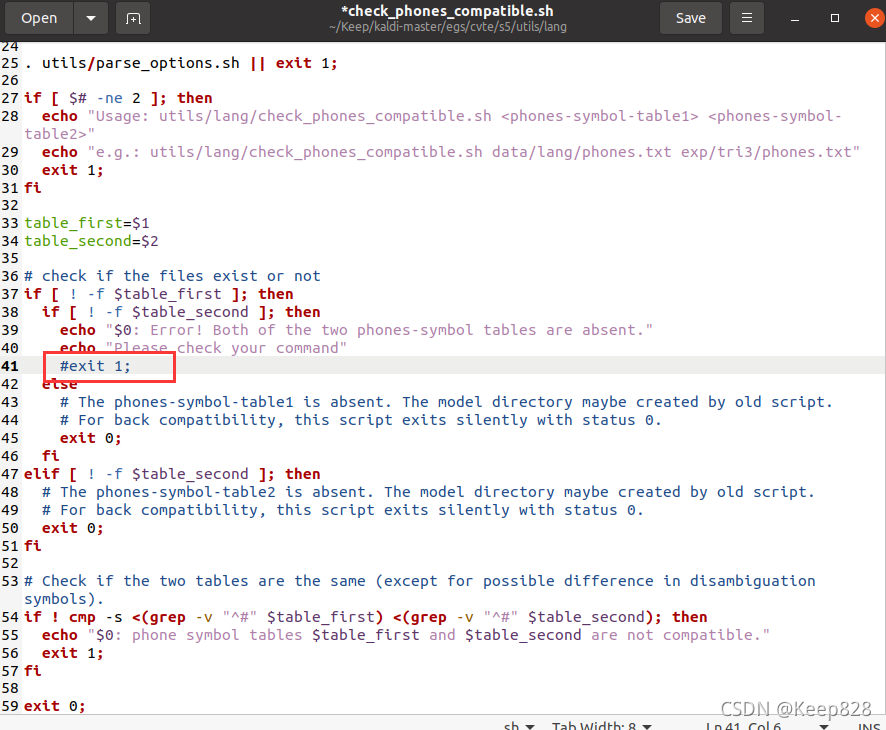
這里需要自行打開utils/lang/check_phones_compatible.sh,將其中if陳述句中的 exit 1注釋掉即可,
繼續運行不知道為什么等了很久沒有反應,,
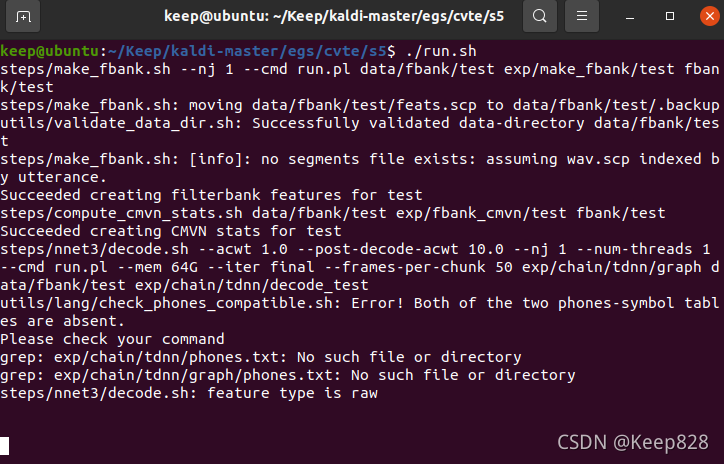
若出現找不到score.sh,建立軟連接即可
ln -s /home/keep/Keep/kaldi-master/egs/hkust/s5/local /home/keep/Keep/kaldi-master/egs/cvte/s5/local
回到egs/cvte/s5目錄下,./run.sh即可,
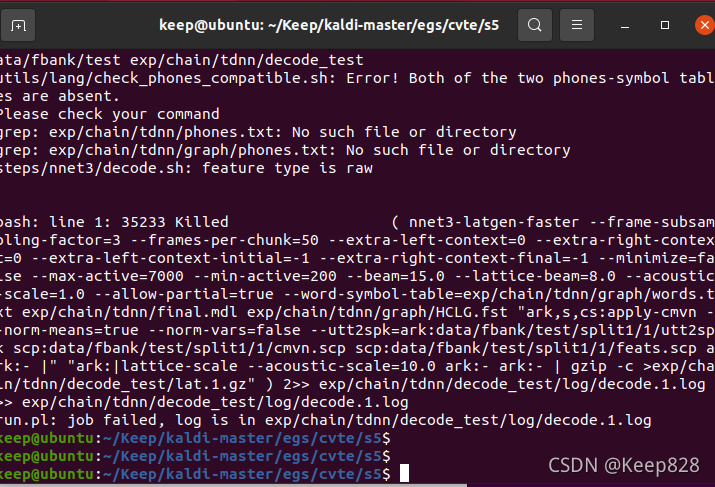
我運行了一次,結果行程被kill掉了,嘗試給虛擬機分配更多cpu和記憶體再試試,
若運行成功,結果在/../kaldi/egs/cvte/s5/exp/chain/tdnn/decode_test/scoring_kaldi檔案夾下可找到
還沒有完全成功,等我去搞下虛擬機再來補充,
感謝:
- kaldi使用cvte模型進行語音識別
- kaldi運行cvte開源chain模型
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/352043.html
標籤:其他
上一篇:C語言實作【N子棋】
下一篇:opencv-1.入門影像處理