學習目標:學會如何應用pytorch;理解深度學習/神經網路的基礎
人工智能:1、推理,根據外界資訊做出決策,2、預測,例如根據貓的圖片和抽象的概念(cat)聯系起來,
機器學習:把推理、預測的程序通過演算法實作;演算法:窮舉法,貪心法,分治法,動態規劃,從資料集中把想要的演算法提取出來(監督學習)
開發學習系統:基于規則的學習,經典的機器學習方法(進行手工特征提取得到特征向量,和輸出之間找到映射關系)、表示學習(把高維特征轉換為低維特征)
因為使用電腦不方便,略過了很多內容,有機會重拾一下,
本文內容是根據up主劉二大人視頻整理,
用CNN網路實作MINIST手寫數字識別代碼實作:
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.optim as optim
#資料處理
batch_size = 64
transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,),(0.3081,))])
train_dataset = datasets.MNIST('./data',train=True,download=False,transform=transform)
test_dataset = datasets.MNIST('./data',train=False,transform=transform)
train_loader = DataLoader(train_dataset,shuffle=True,batch_size=batch_size,drop_last=True)
test_loader = DataLoader(test_dataset,shuffle=False,batch_size=batch_size,drop_last=True)
#構建模型
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(in_channels=1,out_channels=10,padding=1,kernel_size=3)
self.conv2 = nn.Conv2d(in_channels=10,out_channels=20,kernel_size=3)
self.conv3 = nn.Conv2d(in_channels=20,out_channels=16,kernel_size=3)
self.pooling = nn.MaxPool2d(kernel_size=2)
self.layer1 = nn.Linear(64,128)
self.layer2 = nn.Linear(128,32)
self.layer3 = nn.Linear(32,10)
def forward(self,x):
x = self.pooling(F.relu(self.conv1(x)))
x = self.pooling(F.relu(self.conv2(x)))
x = self.pooling(F.relu(self.conv3(x)))
x = x.view(batch_size,-1)
x = F.relu(self.layer1(x))
x = F.relu(self.layer2(x))
x = self.layer3(x)
return x
#實體化模型
model = Net()
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
model = model.to(device)
#選擇損失函式和優化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(),lr=0.01,momentum=0.5)
#定義訓練函式
def train(epoch):
train_loss = 0.0
for idx,data in enumerate(train_loader):
inputs,target = data
inputs,target = inputs.to(device),target.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs,target)
loss.backward()
optimizer.step()
train_loss += loss.item()
if idx % 300==299:
print("[%d,%5d] loss : %.3f"%(epoch+1,idx+1,train_loss/300))
train_loss = 0.0
def test():
correct = 0
total = 0
with torch.no_grad():#不計算梯度
for data in test_loader:
images,labels = data
images,labels = images.to(device),labels.to(device)
output = model(images)
_,predicted = torch.max(output.data,dim=1)
total += labels.size(0)
correct += (predicted==labels).sum().item()
print('Accuracy on test set:%d %%'%(100*correct/total))
if __name__=='__main__':
for epoch in range(10):
train(epoch)
if epoch % 1 ==0:
test()
注意的問題:卷積層輸入通道和輸出通道數要對應起來,卷積層的輸出連接全連接層時要做flatten,在資料加載時,Datalodaer中的引數drop_last=True
google_net網路中的inception模塊代碼實作
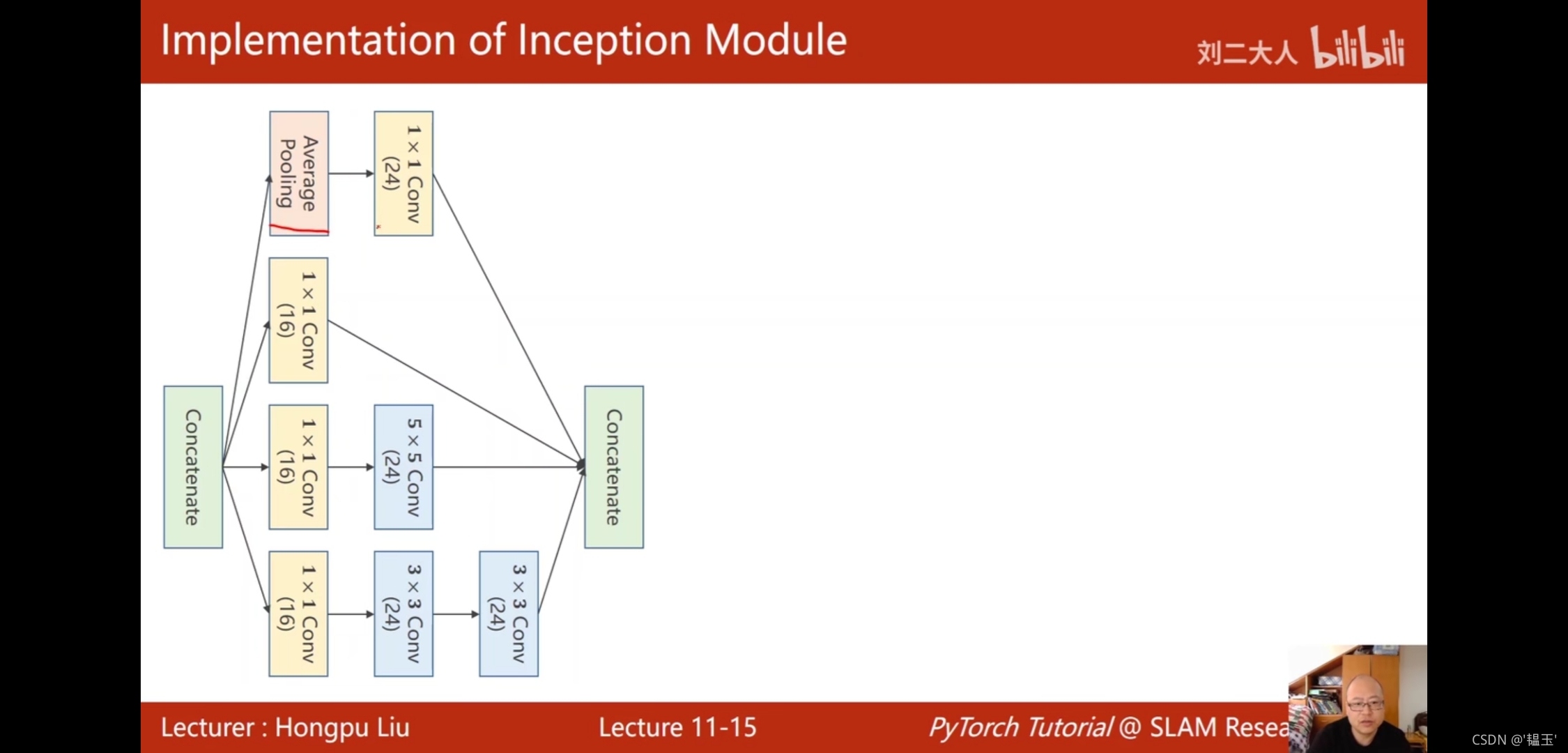
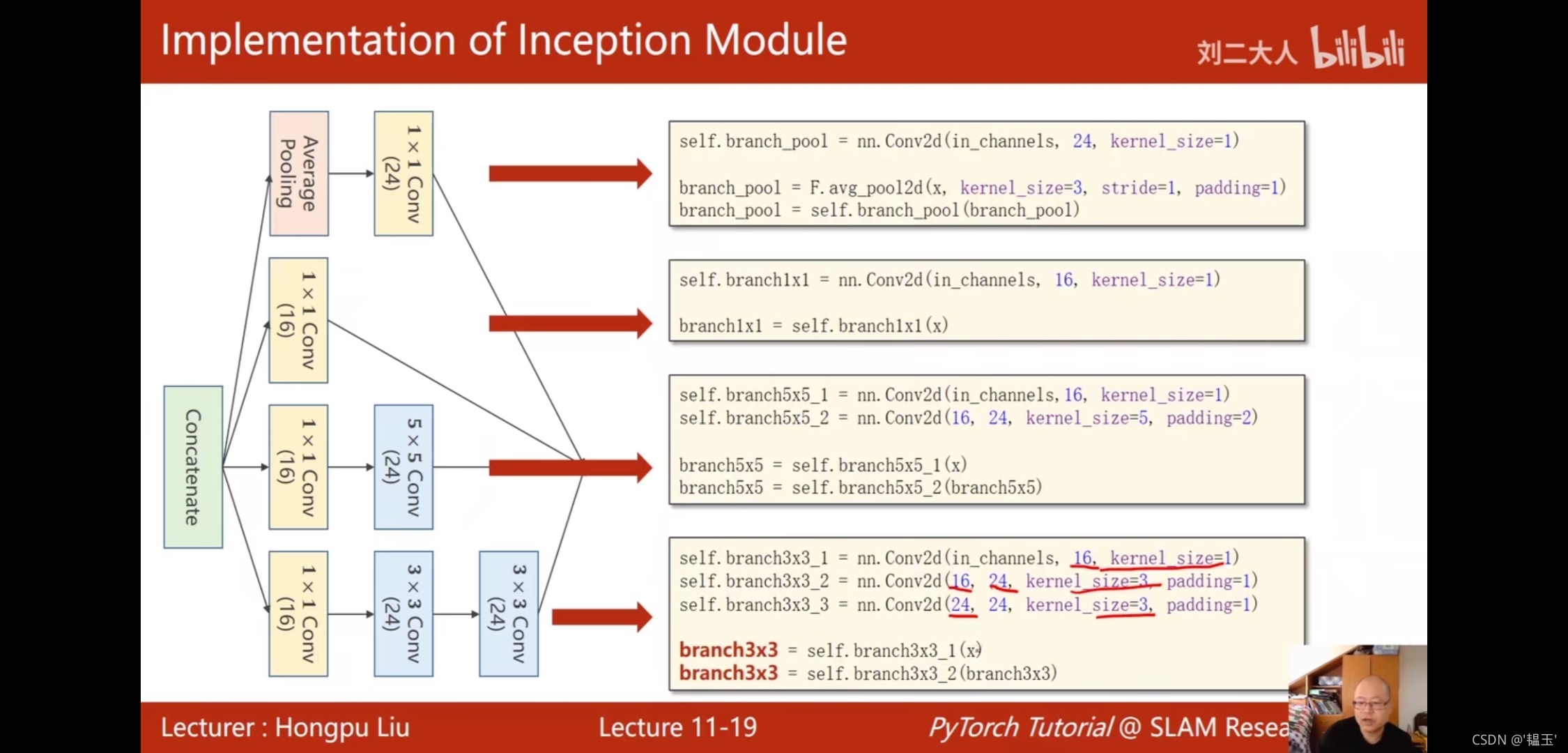
使用Google_Net網路實作手寫數字識別:
#使用google_net實作手寫數字識別
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.optim as optim
#資料準備
batch_size = 64
transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,),(0.3081,))])
train_dataset = datasets.MNIST('./data',train=True,download=False,transform=transform)
test_dataset = datasets.MNIST('./data',train=False,transform=transform)
train_loader = DataLoader(train_dataset,shuffle=True,batch_size=batch_size,drop_last=True)
test_loader = DataLoader(test_dataset,shuffle=False,batch_size=batch_size,drop_last=True)
#多了InceptionA類
class InceptionA(nn.Module):
def __init__(self,in_channels):
super(InceptionA, self).__init__()
self.branch1x1 = nn.Conv2d(in_channels=in_channels,out_channels=16,kernel_size=1)
self.branch5x5_1 = nn.Conv2d(in_channels,16,kernel_size=1)
self.branch5x5_2 = nn.Conv2d(16,24,kernel_size=5,padding=2)
self.branch3x3_1 = nn.Conv2d(in_channels,16,kernel_size=1)
self.branch3x3_2 = nn.Conv2d(16,24,kernel_size=3,padding=1)
self.branch3x3_3 = nn.Conv2d(24,24,kernel_size=3,padding=1)
self.branch_pool = nn.Conv2d(in_channels,24,kernel_size=1)
def forward(self,x):
branch1x1 = self.branch1x1(x)
branch5x5 = self.branch5x5_1(x)
branch5x5 = self.branch5x5_2(branch5x5)
branch3x3 = self.branch3x3_1(x)
branch3x3 = self.branch3x3_2(branch3x3)
branch3x3 = self.branch3x3_3(branch3x3)
branch_pool = F.avg_pool2d(x,kernel_size=3,stride=1,padding=1)#呼叫平均池化函式,沒用現成的類
branch_pool = self.branch_pool(branch_pool)
outputs = [branch1x1,branch5x5,branch3x3,branch_pool]
#沿著通道方向拼接起來,輸出張量為[batch,channel,weight,height]所以dim=1,
return torch.cat(outputs,dim=1)
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1,10,kernel_size=5)
self.conv2 = nn.Conv2d(88,20,kernel_size=5)
#為什么是88,在forward里inception的輸出為(24*3+16)
self.incep1 = InceptionA(in_channels=10)
self.incep2 = InceptionA(in_channels=20)
self.mp = nn.MaxPool2d(kernel_size=2)
#全連接層
self.fc = nn.Linear(1408,10)
#這里的1408,可以讓模根據全連接層之前的輸出得到,forward中使用x.size()
def forward(self,x):
in_size = x.size(0)#in_size=batch_size
x = F.relu(self.mp(self.conv1(x)))
x = self.incep1(x)
x = F.relu(self.mp(self.conv2(x)))
x = self.incep2(x)
x = x.view(in_size,-1)
x = self.fc(x)
#全連接層不用做激活,因為使用nn.CrossEntropyLoss中包含了softmax激活
#未來可以增加全連接層來提高正確率
return x
#實體化模型
model = Net()
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
model = model.to(device)
# 選擇損失函式和優化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
#使用下面這段代碼可以得到卷積層的輸出張量,使用時去掉注釋符,并把下面的訓練代碼和測驗代碼加上注釋
# for idx, data in enumerate(train_loader):
# inputs, target = data
# inputs, target = inputs.to(device), target.to(device)
# optimizer.zero_grad()
# outputs = model(inputs)
# print(outputs.size())
# break
#torch.Size([64, 88, 4, 4])88*4*4=1408
#定義訓練函式
def train(epoch):
train_loss = 0.0
for idx, data in enumerate(train_loader):
inputs, target = data
inputs, target = inputs.to(device), target.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
train_loss += loss.item()
if idx % 300 == 299:
print("[%d,%5d] loss : %.3f" % (epoch + 1, idx + 1, train_loss / 300))
train_loss = 0.0
def test():
correct = 0
total = 0
with torch.no_grad(): # 不計算梯度
for data in test_loader:
images, labels = data
images, labels = images.to(device), labels.to(device)
output = model(images)
_, predicted = torch.max(output.data, dim=1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy on test set:%d %%' % (100 * correct / total))
if __name__ == '__main__':
for epoch in range(10):
train(epoch)
if epoch % 1 == 0:
test()
Residual net 殘差網路
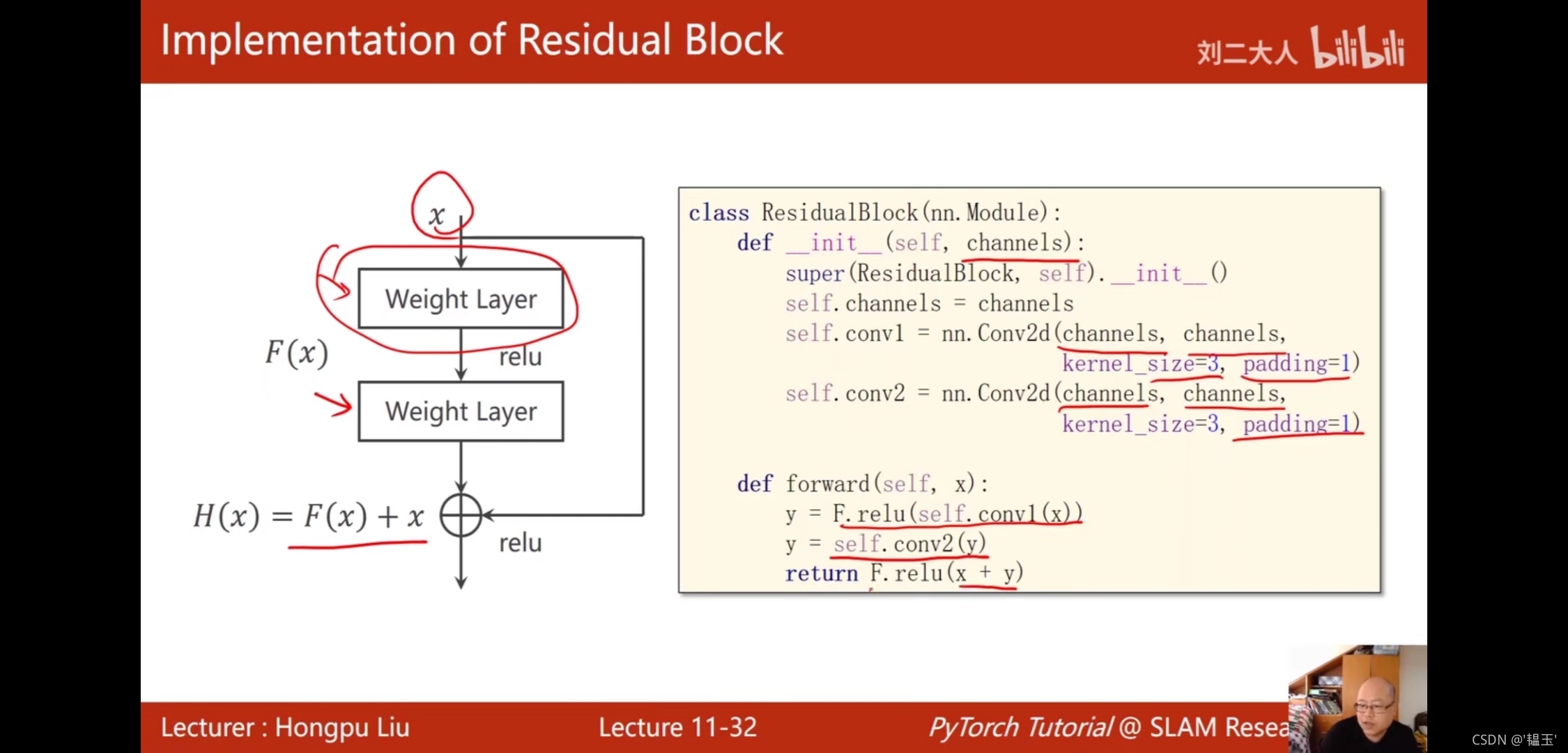
class ResidualBlock(nn.Module):
def __init__(self,channels):
super(ResidualBlock, self).__init__()
self.channels = channels
self.conv1 = nn.Conv2d(channels,channels,kernel_size=3,padding=1)
self.conv2 = nn.Conv2d(channels,channels,kernel_size=3,padding=1)
def forward(self,x):
y = F.relu(self.conv1(x))
y = self.conv2(y)
return F.relu(x+y)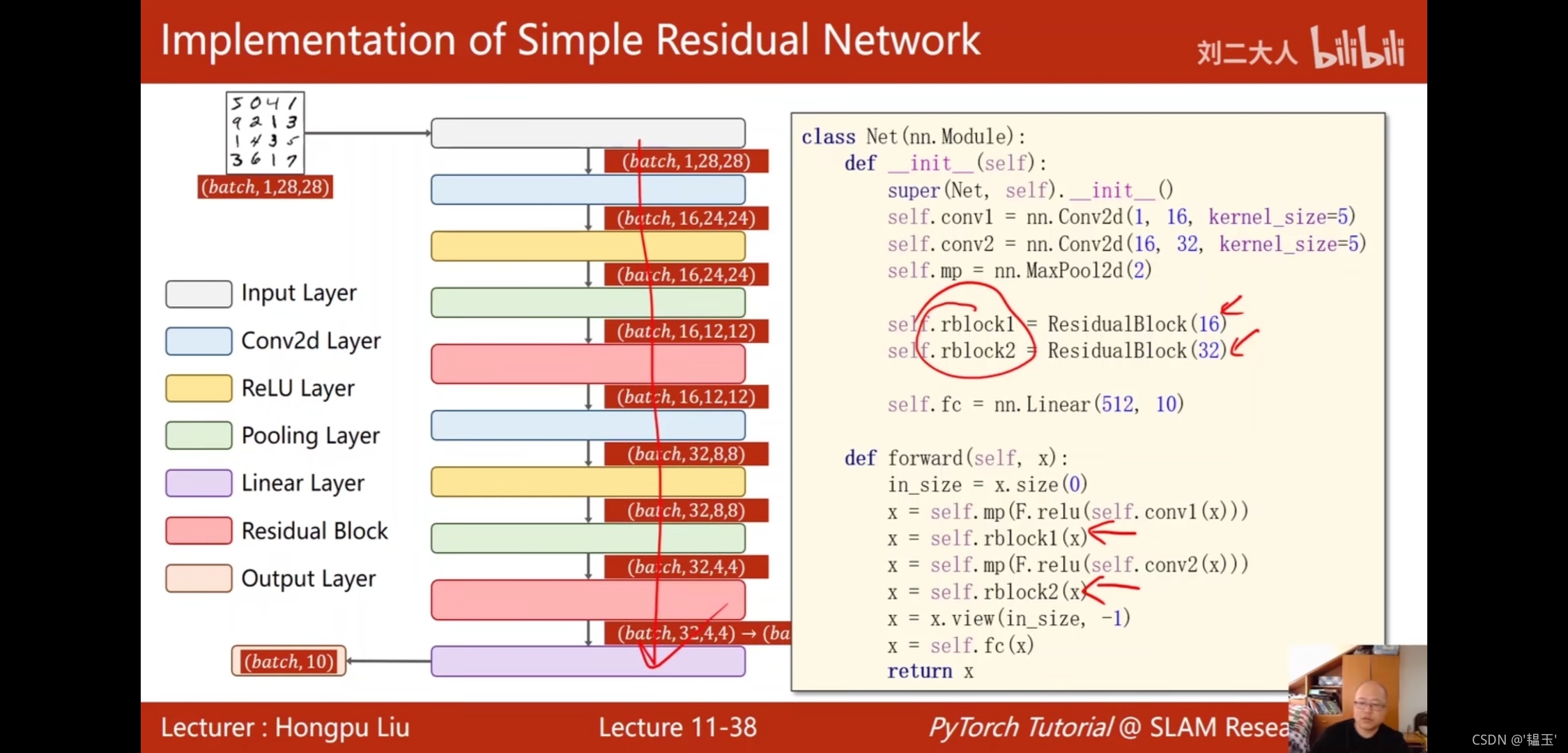
使用殘差網路實作手寫數字識別:
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.optim as optim
#資料處理
batch_size = 64
transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,),(0.3081,))])
train_dataset = datasets.MNIST('./data',train=True,download=False,transform=transform)
test_dataset = datasets.MNIST('./data',train=False,transform=transform)
train_loader = DataLoader(train_dataset,shuffle=True,batch_size=batch_size,drop_last=True)
test_loader = DataLoader(test_dataset,shuffle=False,batch_size=batch_size,drop_last=True)
#做殘差連接時輸入輸出的大小和通道數要相同
class ResidualBlock(nn.Module):
def __init__(self,channels):
super(ResidualBlock, self).__init__()
self.channels = channels
self.conv1 = nn.Conv2d(channels,channels,kernel_size=3,padding=1)
self.conv2 = nn.Conv2d(channels,channels,kernel_size=3,padding=1)
def forward(self,x):
y = F.relu(self.conv1(x))
y = self.conv2(y)
return F.relu(x+y)
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1,16,kernel_size=5)
self.conv2 = nn.Conv2d(16,32,kernel_size=5)
self.mp = nn.MaxPool2d(kernel_size=2)
self.rblock1 = ResidualBlock(16)
self.rblock2 = ResidualBlock(32)
self.fc = nn.Linear(512,10)
def forward(self,x):
in_size = x.size(0)
x = self.mp(F.relu(self.conv1(x)))
x = self.rblock1(x)
x = self.mp(F.relu(self.conv2(x)))
x = self.rblock2(x)
x = x.view(in_size,-1)
x = self.fc(x)
return x
#實體化模型
model = Net()
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
model = model.to(device)
#選擇損失函式和優化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(),lr=0.01,momentum=0.5)
#定義訓練函式
def train(epoch):
train_loss = 0.0
for idx, data in enumerate(train_loader):
inputs, target = data
inputs, target = inputs.to(device), target.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
train_loss += loss.item()
if idx % 300 == 299:
print("[%d,%5d] loss : %.3f" % (epoch + 1, idx + 1, train_loss / 300))
train_loss = 0.0
def test():
correct = 0
total = 0
with torch.no_grad(): # 不計算梯度
for data in test_loader:
images, labels = data
images, labels = images.to(device), labels.to(device)
output = model(images)
_, predicted = torch.max(output.data, dim=1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy on test set:%d %%' % (100 * correct / total))
if __name__ == '__main__':
for epoch in range(10):
train(epoch)
if epoch % 1 == 0:
test()
深度學習計劃
1、理論學習《深度學習》
2、閱讀pytorch檔案(通讀一遍)
3、復現經典作業(讀代碼+寫代碼)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/352090.html
標籤:AI
上一篇:機器學習之貝葉斯分類器