AI 芯片:商業專案 GPU 怎么選?
- 通用芯片
- CPU
- 專用芯片
- GPU
- FPGA
- ASIC
- 商業專案的芯片怎么選?
通用芯片
CPU
CPU是由十幾億的晶體管以分層的思想,制造出來的,
TA的模型是由資訊論鼻祖 22歲的香農在碩士畢業時發表的一篇論文 , 名為《開關網路》,就倆種狀態,開 or 關,
在這篇論文里,TA解釋了一切的邏輯運算如何用開、關實作,
所以,晶體管您可以直觀理解為開關,而十幾億開關組成的 CPU,也可以直觀理解成 開關網路,
一個晶體管:
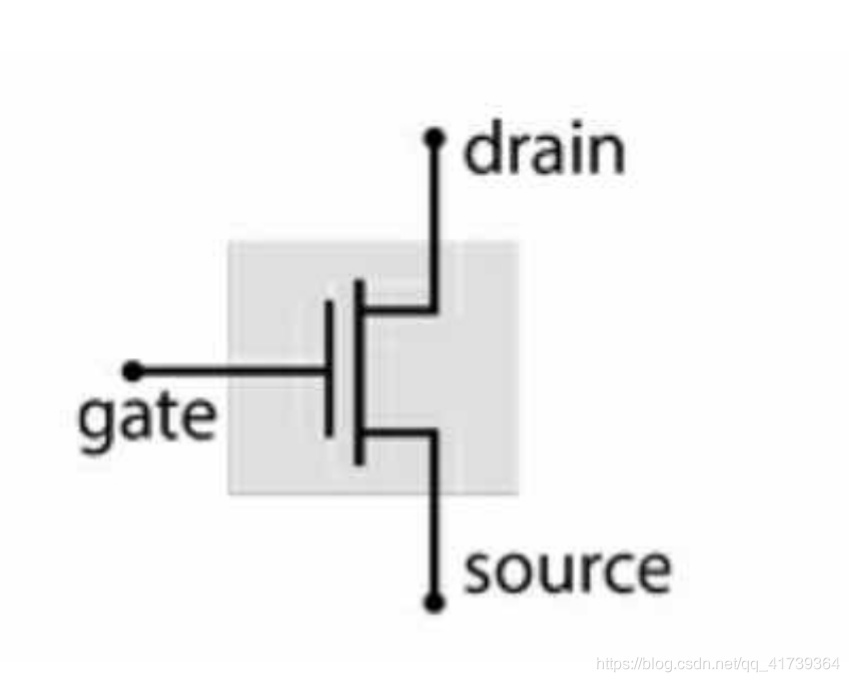
普通晶體管 有 3 極,gate : 柵極 source : 源極 drain : 漏極
- 柵極 電壓高時,源極和漏極會連通,等同 開關打開
- 柵極 電壓低時,源極和漏極會斷開,等同 開關關閉
一個互補晶體管:
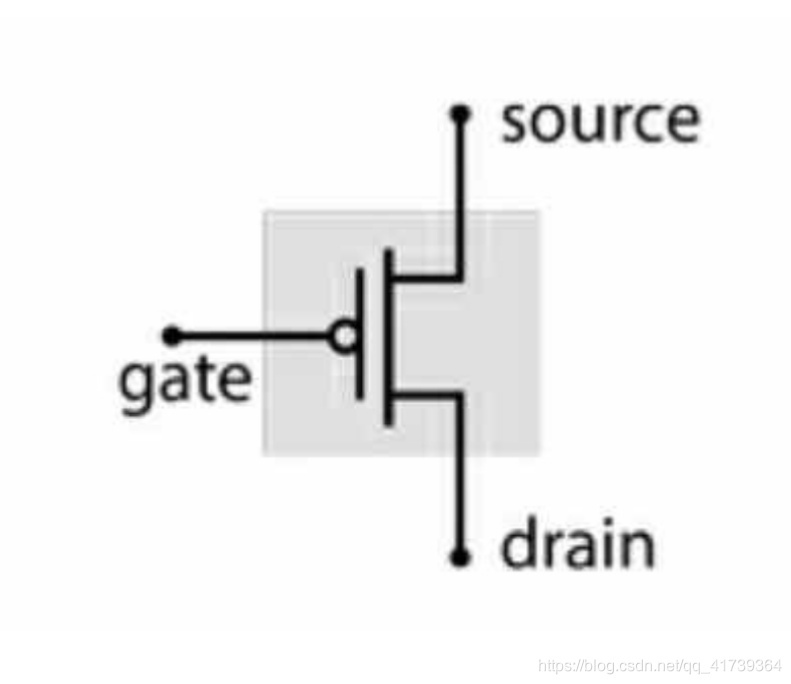
互補晶體管 ,結構和功能與晶體管幾乎一致,功能相反
- 柵極 電壓高時,源極和漏極會斷開,等同 開關關閉
- 柵極 電壓低時,源極和漏極會連通,等同 開關打開
一個晶體管和一個互補晶體管連接起來,就可以實作一個 “邏輯門”,
一個非門:
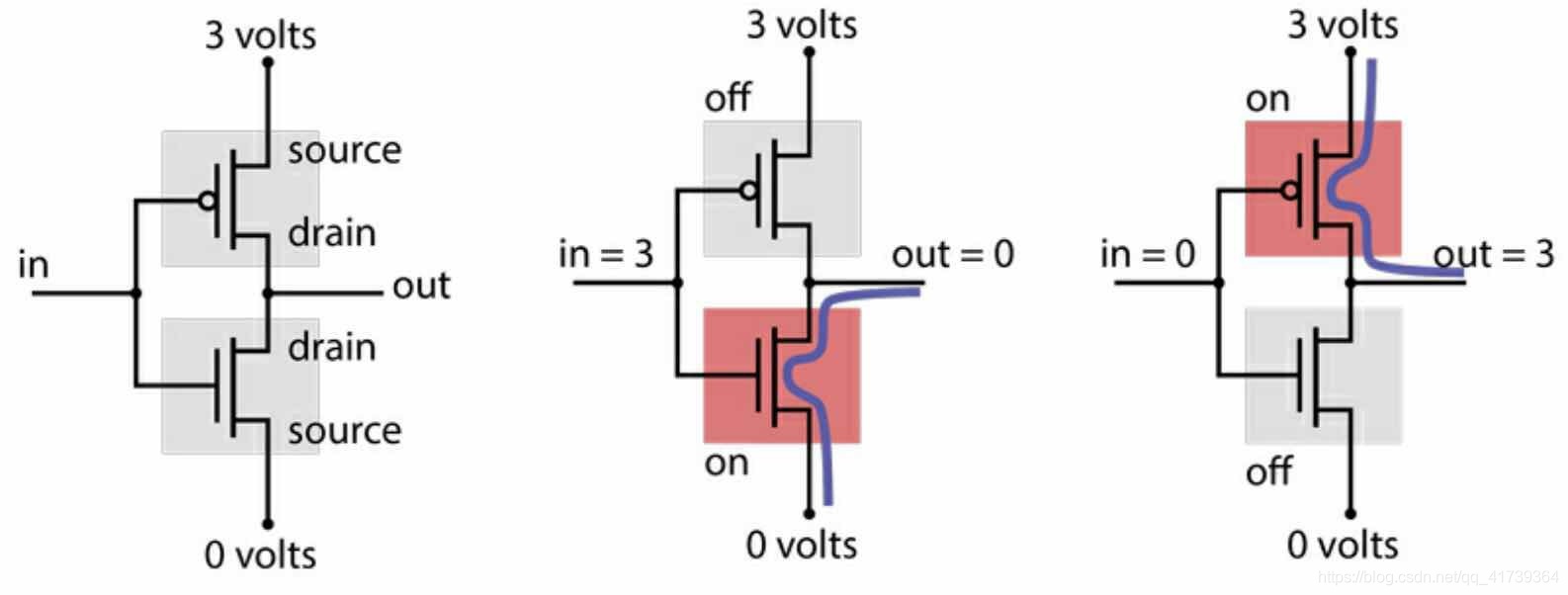
非門的功能:
- 輸入 0 ,輸出 1
- 輸入 1,輸出 0
用高電壓代表 1,低電壓代表 0,
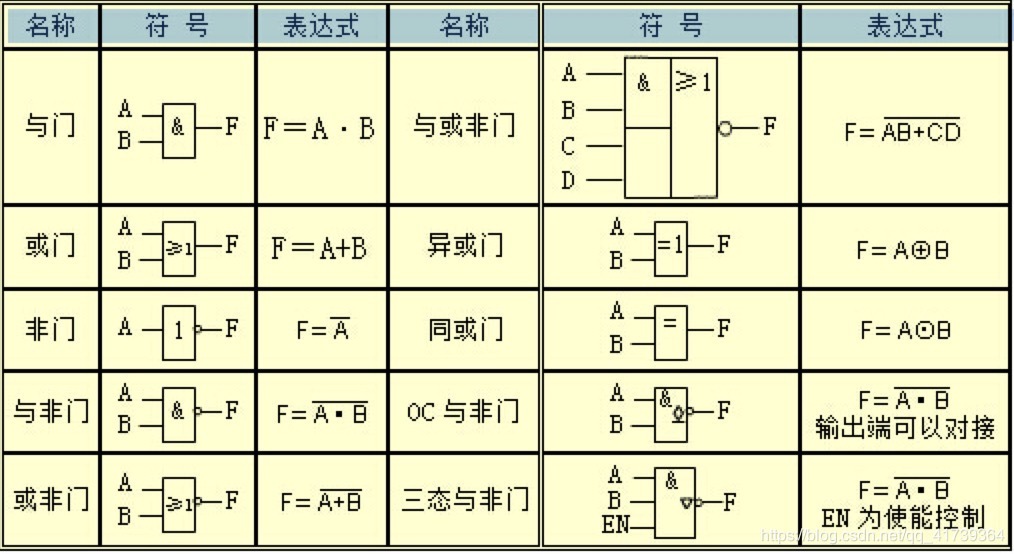
類似地,還有“或門”、“與非門”、“異或門”等等,
而后,我們再把晶體管、邏輯門組合成運算器:
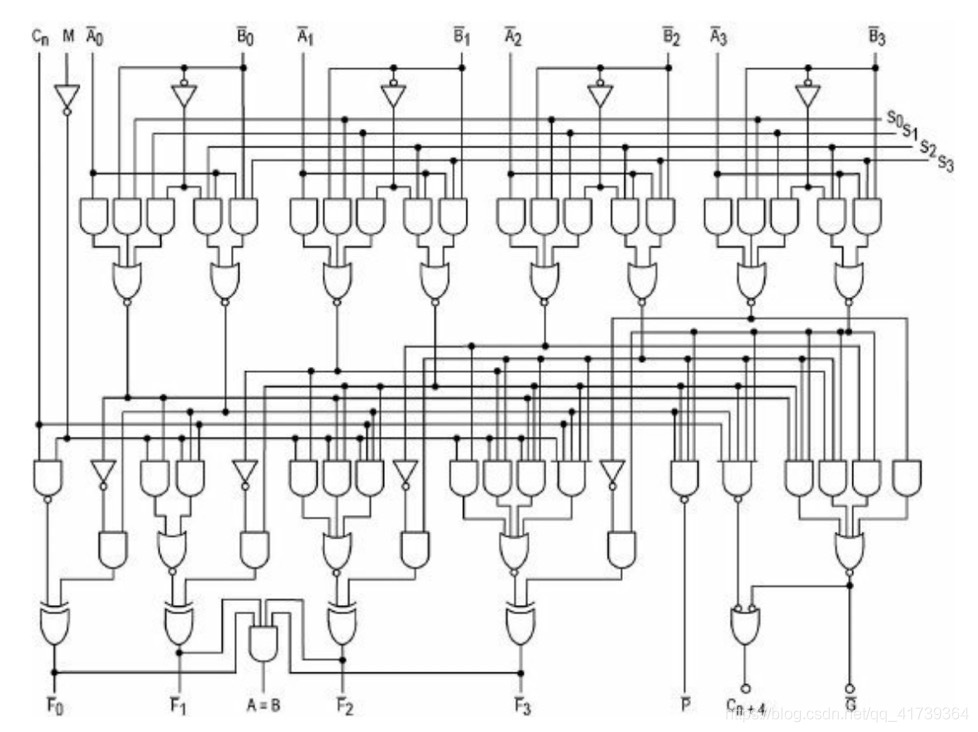
輸入 A 和 B 兩個二進制的 4位數,能判斷 A 和 B 是否相等,還能計算 A+B 和 A-B,
運算器是計算機 CPU 的一部分,CPU 中還有 “數字同步邏輯”之類的組件,但是不管 CPU 有多復雜多高級,也是用各種邏輯門組成的,而邏輯門是用開關做的,
所以整個 CPU 就是一個開關網路!
開關的功能是如此的簡單,
只能根據兩種命令完成兩個動作,雖然是純機械化地事,沒有任何智能;但是億萬個這樣的開關組成在一起,就是 CPU,就能運行軟體,就能實作人工智能,
CPU 的設計思想,是分層,分層使簡單的東西解決復雜的問題,只要系統足夠復雜,就值得這么做,
專用芯片
我們說的AI芯片,其實全稱叫“人工智能加速芯片”,它是一種專門芯片,作用就是來加速AI演算法的,
傳統的 CPU 芯片是一種通用芯片,要干的事情很多,除了用來計算,還要做很多功能,比如說要調取資料,要控制操作,要分析指令等等,
在一個CPU上,能用來計算的,就其實只有一小部分,
- 相當于說,河面上有一艘船,但是船上坐著的人不都是劃船的,還有一些其他人,有指揮的,有廚子,有負責看天氣的等等,一艘船上10個座位,劃槳的人可能只能坐下3-4個,剩下的位置都被“閑雜人等”占了,
但是GPU就不一樣了,
- GPU是“專用芯片”,它有專門的功能,處理影像資料,這就相當于,同樣是一艘船,GPU這艘船上大部分的位置都給了劃槳的人,閑雜人等不讓上船,10個座位上的人,可能八九個都在劃船,船當然劃得快,
GPU芯片性能的提升,主要還是通過優化硬體以及優化演算法做到的,
硬體優化是什么呢?
比如說你可以優化船體本身的設計,既然這個船只有一個任務,就是劃得快,那不如按照賽艇的模型去設計,還有船的里面,座位怎么排布,甚至用什么樣的槳來劃,也都可以優化,
對應到芯片設計領域,專業的術語就是,電路設計可以優化,
另一種方式,就是重新設計劃船的技術,提升船上每個人劃船的效率或者說提升整個團隊的效率,
比方說,在軟體的層面,你可以使用更好、更高效的演算法去發揮芯片的效率,
GPU
CPU 的計算速度之所以不夠快,是因為被設計成能夠適應所有的計算了,很大晶體管都用搭建控制電路,
而在計算機里,有一種計算相對單一 — 控制顯示幕的圖形計算,
于是,英偉達專門設計了影像型處理器 GPU,原來只有一些游戲發燒友才會追求高性能的 GPU,那是為了更好的游戲效果,
-
電路設計:控制電路單一了,更多晶體管用于計算,這樣就可以建立多核,核心越多性能更好,目前一個 GPU 可能有 3000 個內核,
-
演算法設計:單次計算變成了向量的批量化計算,很多重復一致的計算就可以并行,如影像識別領域常用的卷積神經網路演算法,主要的一個運算就是針對很大的矩陣進行大量的乘法操作,如果能針對這個特點來處理,自然就能提高計算速度,
現在人工智能加速芯片的實作方案,就是GPU、FPGA和ASIC這三種了,在不同的應用場景下,會選用不同的方案,
FPGA
FPGA,可編程邏輯陣列,
作為音響發燒友,經常在頂級音源、放大設備中見到FPGA形式的音頻芯片,處理音頻信號解碼、升頻、濾波、放大等運算,當時一直不理解FPGA的本質以及廠家為什么這么設計,
廠家是為實作專門的音頻處理定制了芯片,且根據自己的調音需求,特地燒錄出滿足自己調音偏好的FPGA,
FPGA 是一顆通用專一芯片,但做好以后,你可以根據需要,修改芯片里的連接形式,構成各種各樣不同功能的芯片,
你可以把FPGA當作是送外賣,雖然送外賣是一項通用的服務,誰都可以用,但是你一旦下了的訂單,這個送外賣小哥,他就只服務于你了,他會在你和你的目標之間建立一條最優的路徑,最快速度把東西送到,服務結束之后他才會接下一單,又針對新的用戶建立新的路線,
外賣下單就對應著FPGA的編程燒錄,燒錄好了之后,這塊FPGA就成了你的專用芯片,針對你的具體問題高效解決,完成任務之后,你還可以根據新的問題來改變電路結構,變成另一顆專用芯片,高效地完成新任務,
ASIC
現在芯片技術最熱門的叫,ASIC 定制化芯片,定制化就是專門設計一顆芯片,不做其他事·,
畢竟機器學習的向量計算,和通用的向量計算稍稍有點不同,能否讓計算的內核功能再專一點,只做特定的機器學習演算法,
于是,Google 提出了張量計算的概念,并設計了一種僅僅針對特定張量計算的處理器 TPU,
所謂張量,原本是一個數學概念,如倆張照片是倆個不同的向量,它們之間的相似性計算一個張量,
倆個最重要的張量計算:
- 矩陣乘法
- 卷積
TPU 設計的目的,就是快速計算矩陣乘法,
TPU、GPU 誰更好,完全要看做什么事情,不同的專案適合不同的處理器,
商業專案的芯片怎么選?
現在人工智能的商業專案,必定離不開 CPU,那應該買什么樣的 CPU 呢?
最簡單的方法,是辦一個 visa 的信用卡,就可以免費使用谷歌的云服務器,
具體來說,不同的深度學習架構,選擇 GPU 引數優先級也不同:
-
卷積網路和變換器 (Transformer):張量核心 > FLOPs (每秒浮點運算次數) > 顯存帶寬 > 16 位浮點計算能力
-
回圈神經網路:顯存帶寬 > 16 位浮點計算能力 > 張量核心 > FLOPs (每秒浮點運算次數)
針對不同的研究、預算看:
- 最佳 GPU:RTX 2070
- 高性價比:RTX 2070、RTX 2060、RTX 1060
- 學生黨:RTX 1060
- 最便宜:RTX 1050 Ti、CPU + AWS/TPU、Colab(visa支付一點點錢還可以用Google訓練好的模型)
- Kaggle:RTX 2070
- 計算機視覺、機器翻譯:采用鼓風設計的 GTX 2080 Ti,如果訓練網路非常大,用 RTX TItans
- 自然語言處理:RTX 2080 Ti
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/352091.html
標籤:AI
上一篇:pytorch學習筆記