一. 資料集下載地址
SMSSpamCollection.txt
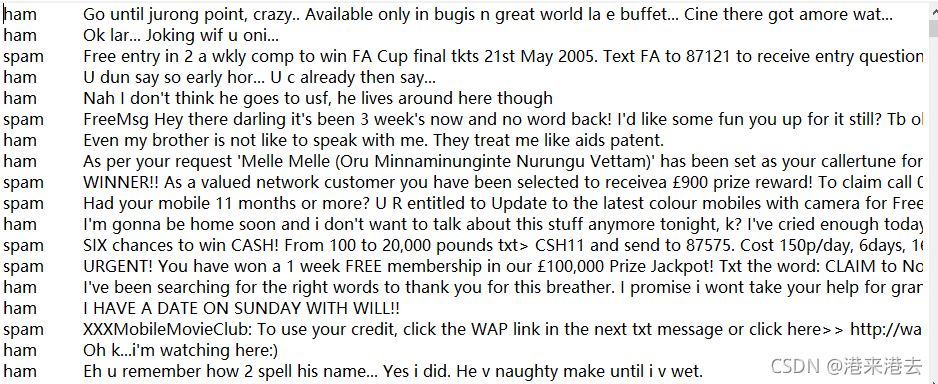
二. 打開下載的.txt檔案,可以看到資料集長這樣,標簽(ham和spam)與文本之間的分隔符是一個tab鍵,也就是‘\t’
三. 首先用pd.read_csv函式讀取該資料集時要注意設定分隔符sep=’\t’,然后用replace方法把“ham”標簽用0替代,“spam”用1替代,方便看預測結果,
data=pd.read_csv(path,sep='\t', header=None, names=Cnames)
data=data.replace({'ham':0,'spam':1}) #替換標簽值
接下來就是用詞袋方法處理文本資訊,也就是統計一大段話里的不同單詞的出現次數,最后得到一個頻率矩陣,矩陣的行就是資料集里的每一行短信,矩陣的列就是短信里每個單詞,元素值就是該單詞的出現頻率,可以用sklearn庫提供的CountVectorizer()方法實作詞袋處理,
from sklearn.feature_extraction.text import CountVectorizer
vector_nomial=CountVectorizer() #實作詞袋模型
train_matrix=vector_nomial.fit_transform(x_train)
test_matrix=vector_nomial.transform(x_test)
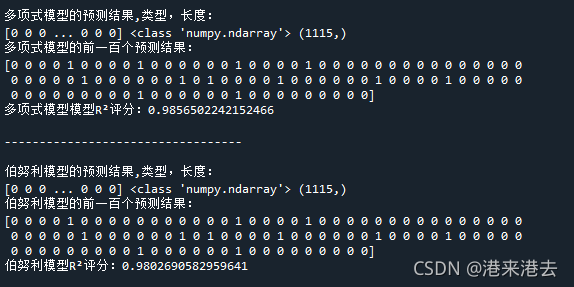
四. 將訓練資料和測驗資料輸入到詞袋模型里,就可以得到對應的頻率矩陣,最后分別運用sklearn提供的伯努利模型和多項式模型對垃圾短信進行分類,兩個模型回傳的預測結果都是長度為1115(我設定的訓練集占比為80%),型別為ndarray的串列,最終,多項式模型的R2分值為0.986,伯努利模型的R2分值為0.980,二者的預測結果幾乎是相同的,
五. 完整代碼
from sklearn.naive_bayes import BernoulliNB,MultinomialNB
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.model_selection import train_test_split
import pandas as pd
path = 'E:/Python_file/zuoye/SMSSpamCollection.txt'
Cnames=['labels','messages']
data = pd.read_csv(path,sep='\t', header=None, names=Cnames) #讀取資料集,分隔符是\t
data=data.replace({'ham':0,'spam':1}) #替換標簽值
print('資料集展示:')
print(data)
print('\n----------------------------------\n')
X=data['messages']
y=data['labels']
x_train,x_test,y_train,y_test=train_test_split(X,y,train_size=0.8,random_state=123)
vector_nomial=CountVectorizer() #實作詞袋模型
vector_bernou=CountVectorizer()
#多項式模型分類垃圾短信
train_matrix=vector_nomial.fit_transform(x_train)
test_matrix=vector_nomial.transform(x_test)
polynomial=MultinomialNB()
clm_nomial=polynomial.fit(train_matrix,y_train)
result_nomial=clm_nomial.predict(test_matrix)
#伯努利模型分類垃圾短信
train_matrix=vector_bernou.fit_transform(x_train)
test_matrix=vector_bernou.transform(x_test)
Bernoulli=BernoulliNB()
clm_bernoulli=Bernoulli.fit(train_matrix,y_train)
result_bernou=clm_bernoulli.predict(test_matrix)
print('多項式模型的預測結果,型別,長度:')
print(result_nomial,type(result_nomial),result_nomial.shape)
print('多項式模型的前一百個預測結果:')
print(result_nomial[0:100])
print('多項式模型模型R2評分:'+ str(clm_nomial.score(test_matrix,y_test)))
print('\n----------------------------------\n')
print('伯努利模型的預測結果,型別,長度:')
print(result_bernou,type(result_bernou),result_bernou.shape)
print('伯努利模型的前一百個預測結果:')
print(result_bernou[0:100])
print('伯努利模型R2評分:'+ str(clm_bernoulli.score(test_matrix,y_test)))
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/352097.html
標籤:AI
上一篇:李沐《動手學深度學習v2》學習筆記(三):Fashion-MNIST 資料集
下一篇:【知識圖譜】關系抽取