知識圖譜-關系抽取
- 關系抽取任務定義
- 物體間關系抽取的定義
- 網路文本資訊結構
- 傳統關系抽取
- 傳統關系抽取方法
- 自然語言處理程序
- 詞表示
- NNLM: Neural Network Language Model
- CBOW & Skip-gram
- 自然語言的表示學習
- 基礎:多層前饋神經網路
- 卷積神經網路
- 全連接 vs 卷積
- 一維卷積
- 卷積的引數
- 卷積步長
- 窄卷積、寬卷積、等長卷積
- 二維卷積
- 卷積層作用
- 子采樣層
- 引數訓練
- 基于卷積神經網路的關系抽取
- 詞匯級特征
- 句子級特征
- 前饋神經網路的缺點
- 回圈神經網路
- 回圈神經網路:應用場景
- 引數學習
- 長短時記憶神經網路:LSTM
- 雙向回圈神經網路
- 遞回神經網路
- 利用LSTM做關系抽取
- 物體和關系聯合抽取
- 傳統關系抽取方法
- 開放域關系抽取特點
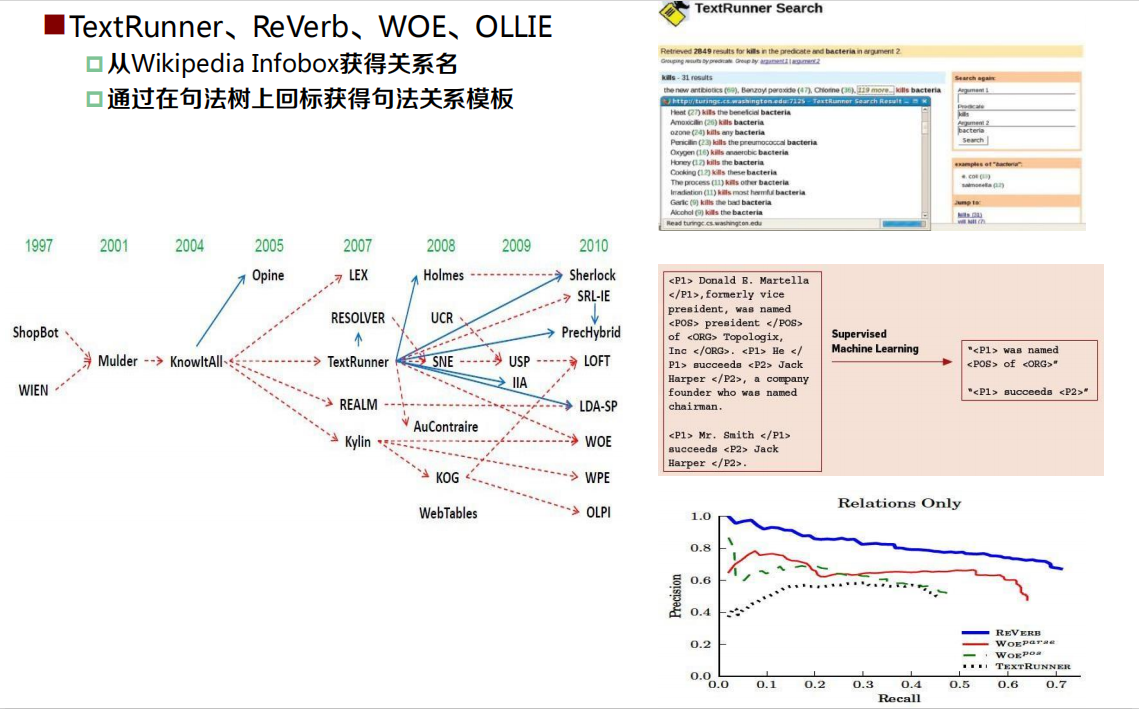
- 開放抽取
- 開放域關系抽取: Web Page
- 開放域關系抽取: Wikipedia
關系抽取任務定義

物體間關系抽取的定義
Alexander Schutz等人認為關系抽取是自動識別由一對概念和聯系這對概念的關系構成的相關三元組,
- Example1: 比爾蓋茨是微軟的CEO
- CEO(比爾蓋茨, 微軟)
- Example2: CMU坐落于匹茲堡
- Located-in(CMU, 匹茲堡)
- 高階關系:Michael Jordan獲得1997/98賽季的MVP
- Award(Michael Jordan, 1997/98賽季, MVP)
網路文本資訊結構
結構化資料(Infobox)
- 置信度高
- 規模小
- 缺乏個性化的屬性資訊
半結構化資料
- 置信度較高
- 規模較大
- 個性化的資訊
- 形式多樣
- 含有噪聲
純文本
- 置信度低
- 復雜多樣
- 規模大

結構化 vs. 半結構化 vs. 非結構化
隨機抽取100篇百科檔案(共5類)
- 對于其中三部分都包含的網頁進行了統計
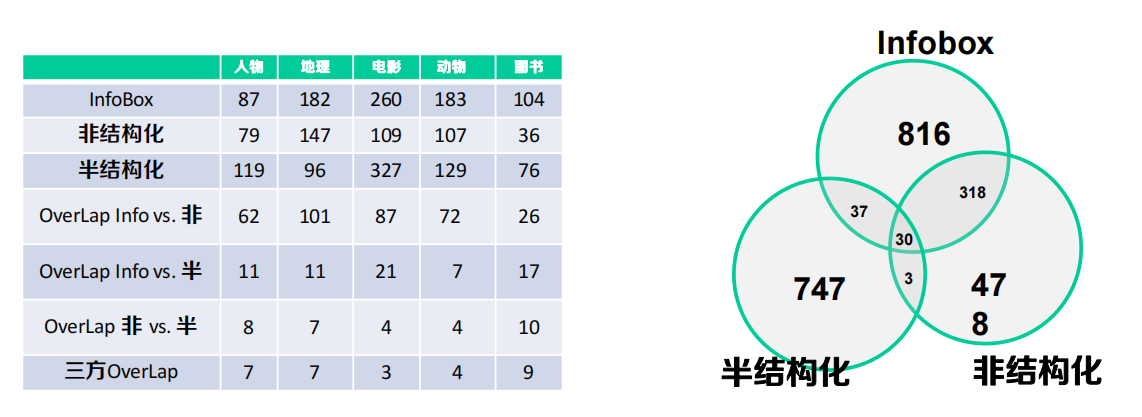
結構化與半結構化的關系抽取方法
- 結構化與半結構化文本資訊(利用網頁結構)
? 資訊塊的識別
? 模板的學習
? 屬性值的抽取
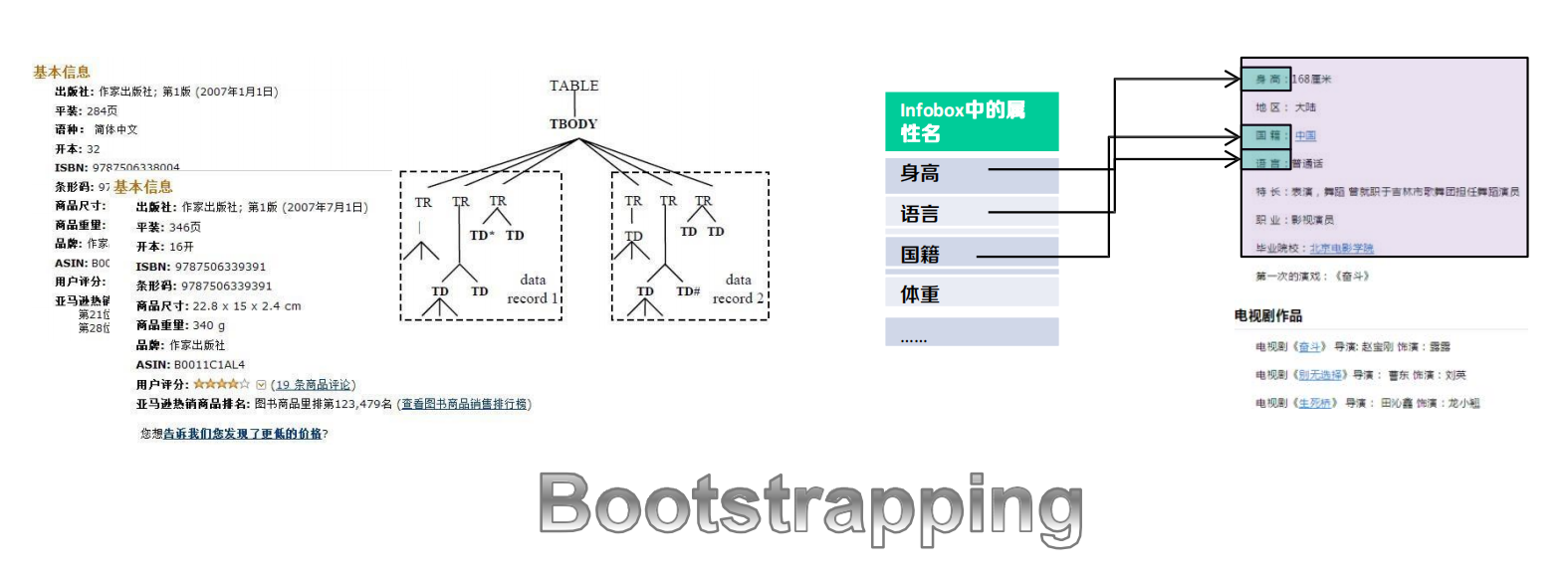
非結構化文本的關系抽取分類
傳統關系抽取
- 評測語料(MUC, ACE, …)
- 專家制訂類別,人工標注語料
開放域關系抽取
- 類別自動獲取
- 語料自動生成
- 語言證據清晰表達的關系
傳統關系抽取
任務
- 給定物體關系類別,給定語料,抽取目標關系對
評測語料(MUC, ACE, KBP, SemEval)
- 專家標注語料,語料質量高
- 抽取的目標類別已經定義好
- 有公認的評價方式
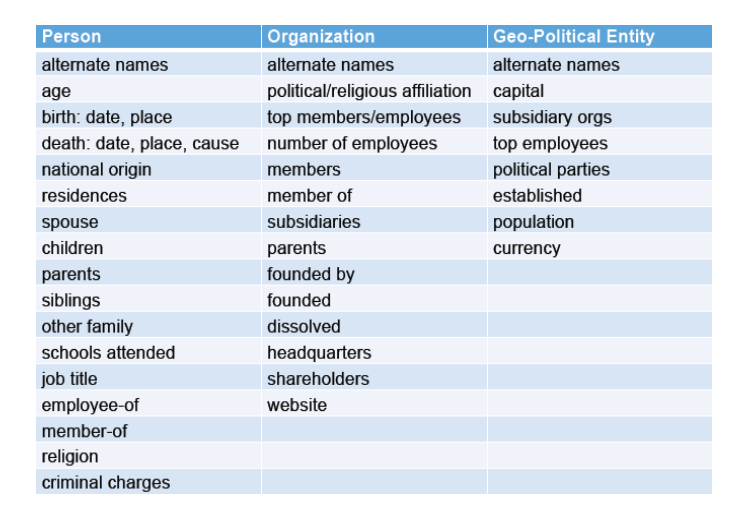
ACE抽取的目標關系串列
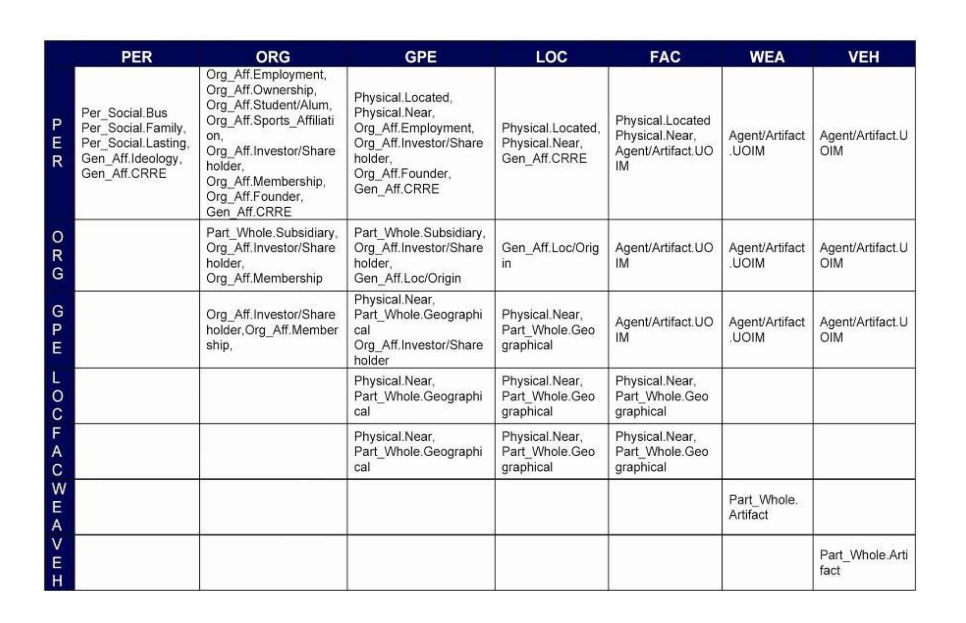
TAC-KBP抽取的目標關系串列
SemEval-2010 Task 8
目標關系串列:19種
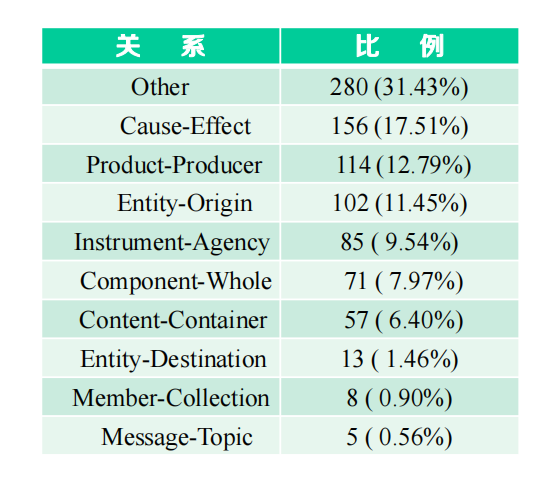
ACE(2005-2007)評測結果
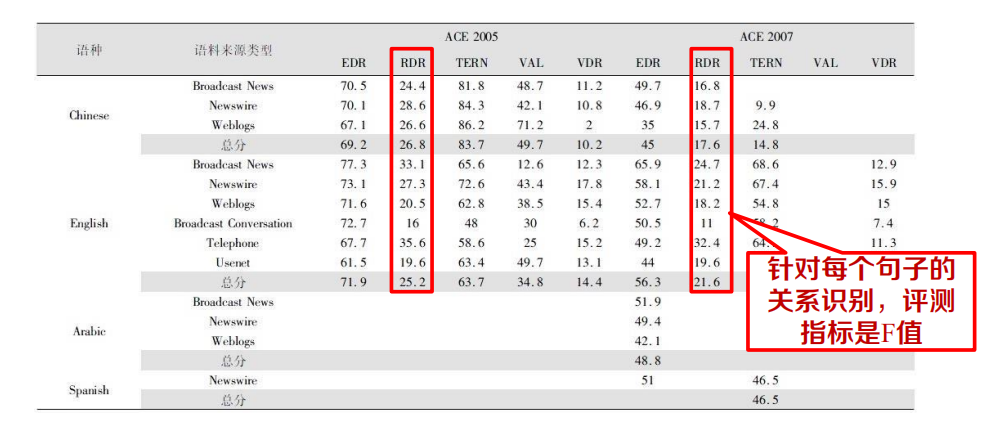
(http://www.nist.gov/speech/tests/ace/ace05/doc/acee05eval_official_results_20060110.htm
http://www.nist.gov/speech/tests/ace/ace05/doc/acee05eval_official_results_20070402.htm)
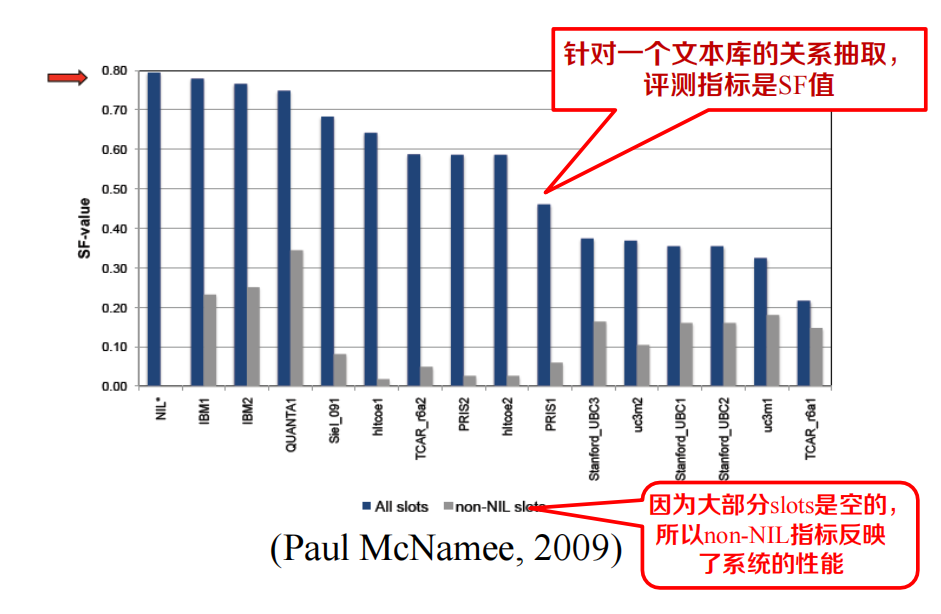
TAC-KBP 2009 Slot Filling Track評測結果
傳統關系抽取方法
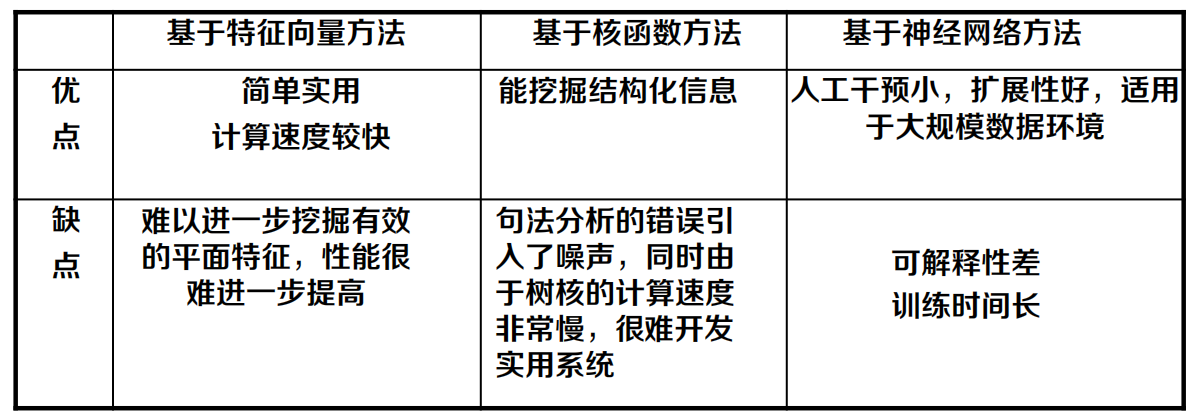
目前主要采用統計機器學習的方法,將關系實體轉換成高維空間中的特征向量或直接用離散結構來表示,在標注語料庫上訓練生成分類模型,然后再識別物體間關系,
- 基于特征向量方法:最大熵模型(Kambhatla 2004)和支持向量機 (Zhao et al., 2005;Zhouet al., 2005; Jiang et al., 2007)等
- 基于核函式的方法:淺層樹核(Zelenko et al., 2003)、依存樹核( Culotta et al., 2004)、最短依存樹核(Bunescu et al., 2005)、卷積樹 核(Zhang et al., 2006;Zhou et al., 2007)
- 基于神經網路的方法:遞回神經網路( Socher et al., 2012)、基于矩陣空間的遞回神經網路( Socher et al., 2012)、卷積神經網路(Zeng et al., 2014)
基于特征向量方法:
- 主要問題:如何獲取各種有效的詞法、句法、語意等特征,并把它們有效地集成起來,從而產生描述物體語意關系的各種區域特征和簡單的全域特征
- 特征選取:從自由文本及其句法結構中抽取出各種詞匯特征以及結構化特征
- 物體詞匯及其背景關系特征
- 物體型別及其組合特征(PER,LOC等)
- 交疊特征(兩個物體或詞組塊是否在同一個名詞短語、動詞短 語或者介詞短語之中、兩個物體或者詞組塊之間單詞的個數等)
- 句法樹特征(連接兩個物體的語法路徑)
基于核函式方法:
- 主要問題:如何有效挖掘反映語意關系的結構化資訊及如何有效計算結構化資訊之間的相似度
- 卷積樹核:用兩個句法樹之間的公共子樹的數目來衡量它們之間的相似度
- 標準的卷積樹核(CTK)
- 在計算兩棵子樹的相似度時,只考慮子樹本身,不考慮子樹的背景關系資訊
- 背景關系相關卷積樹核函式(CS-CTK)
- 在計算子樹相似度時,同時考慮子樹的祖先資訊,如子樹根結點的父結點、祖父結點資訊,并對不同祖先的子樹相似度加權平均
- 標準的卷積樹核(CTK)
基于神經網路的方法:
- 主要問題:如何設計合理的網路結構,從而捕捉更多的資訊,進而更準確地完成關系的抽取
- 網路結構:不同的網路結構捕捉文本中不同的資訊
- 遞回神經網路(RNN)
- 網路的構建程序更多的考慮到句子的句法結構,但是需要依賴復雜的句法 分析工具
- 卷積神經網路(CNN)
- 通過卷積操作完成句子級資訊的捕獲,不需要復雜的NLP工具
- 回圈神經網路(RNN)
- 通過回圈神經網路建模詞語之間的依賴關系,自動捕獲句子級資訊
- 遞回神經網路(RNN)
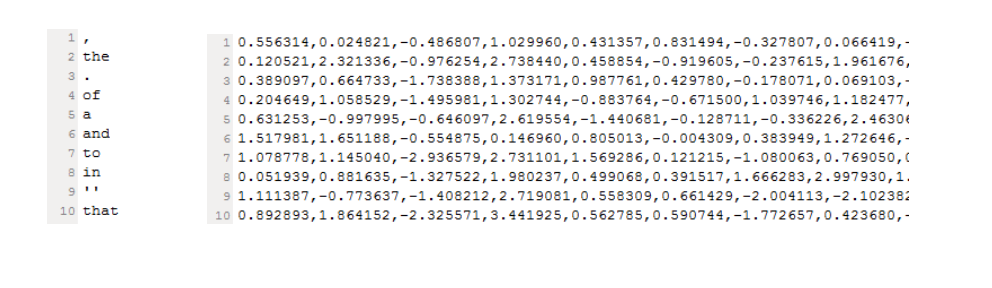
自然語言處理程序
自然語言的表示學習
基本語言單元的語意表示
- 詞的表示
- 分布式原則
更大語言單元的語意表示
- 句子的表示
- 語意組合原則
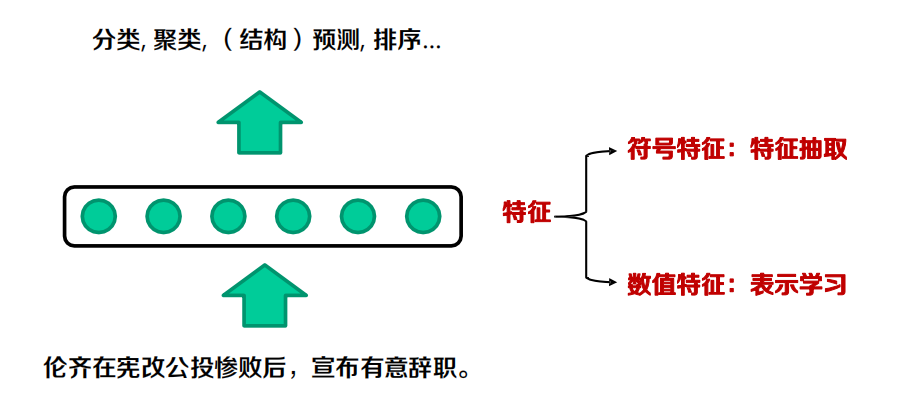
深度學習的本質:用數值(向量,矩陣等)表示各個語言單元的語意(特征)
詞表示
詞是語言處理中最基本的語言單元
詞以及詞間關系的表示和建模是NLP任務中重要基礎作業
人工方法:刻畫詞之間多維度關系,例如:聚合關系,組合關系
深度學習:用數值化的方法表示詞的語意資訊
詞的分布表示
深度學習框架下,詞的語意表示為向量的形式,也就是分布表示,
The first thing you do with a word symbol is you convert it to a word vector. And you learn to do that,
you learn for each word how to turn a symbol into a vector, say, 300 components, and after you’ve done
learning, you’ll discover the vector for Tuesday is very similar to the vector for Wednesday.
[Geoffrey E. Hinton. 2015]
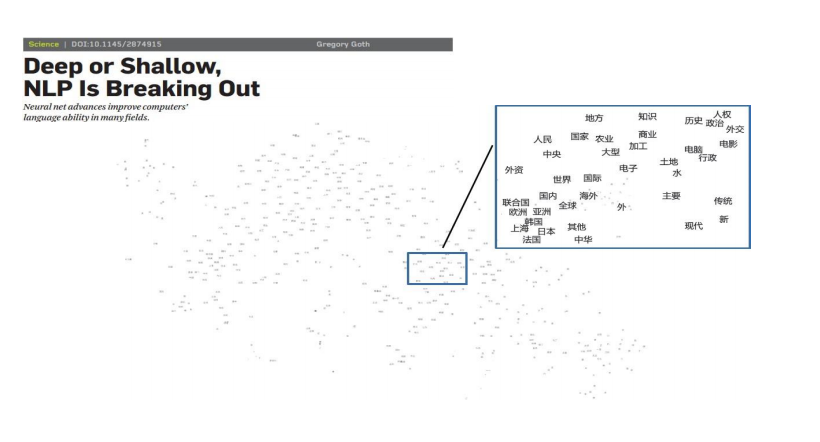
Harris和firth的分布假說:背景關系相似的詞 → 詞義相似
- 詞的語意可以通過大規模語料庫統計獲得 [Harris 1954]
- 詞語的語意相似度可以度量
江西省地處中國東南部
攜程帶你玩轉江西省
四川省地處中國西南腹地
攜程帶你玩轉四川省
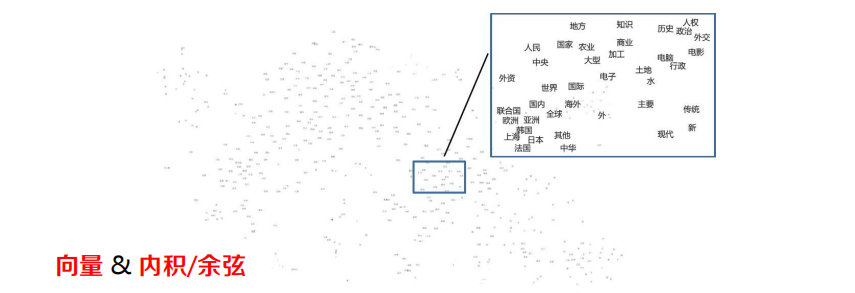
詞的分布表示:歷史的角度
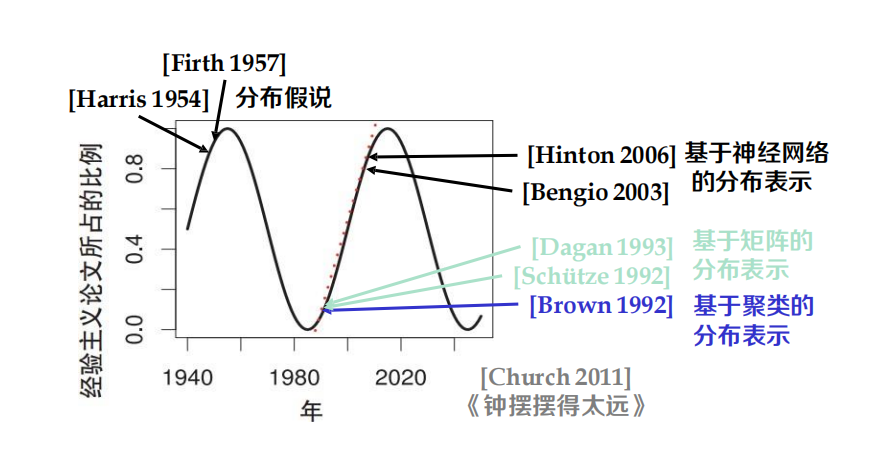
詞表示學習
- 背景關系的表示:檔案、詞、n元詞組
- 相似度的衡量:向量的內積(余弦)
- 詞間關系一般分為聚合關系和組合關系,分布式表示學習常常從聚合 關系的角度去建模
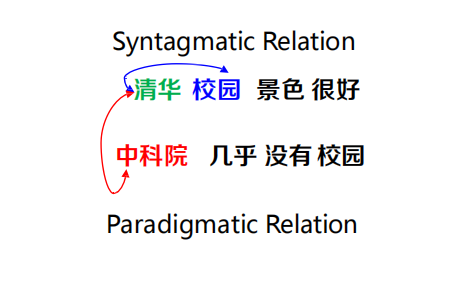
傳統方法:也是從分布的角度建模,但是沒有用到神經網路的方法
- LSA:矩陣分解
- Brown Clustering:聚類
神經網路:NNLM, Skip-gram, CBOW, GloVe,LBL,C&W
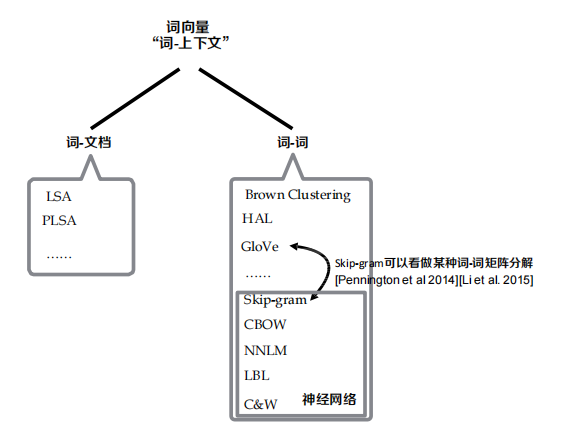
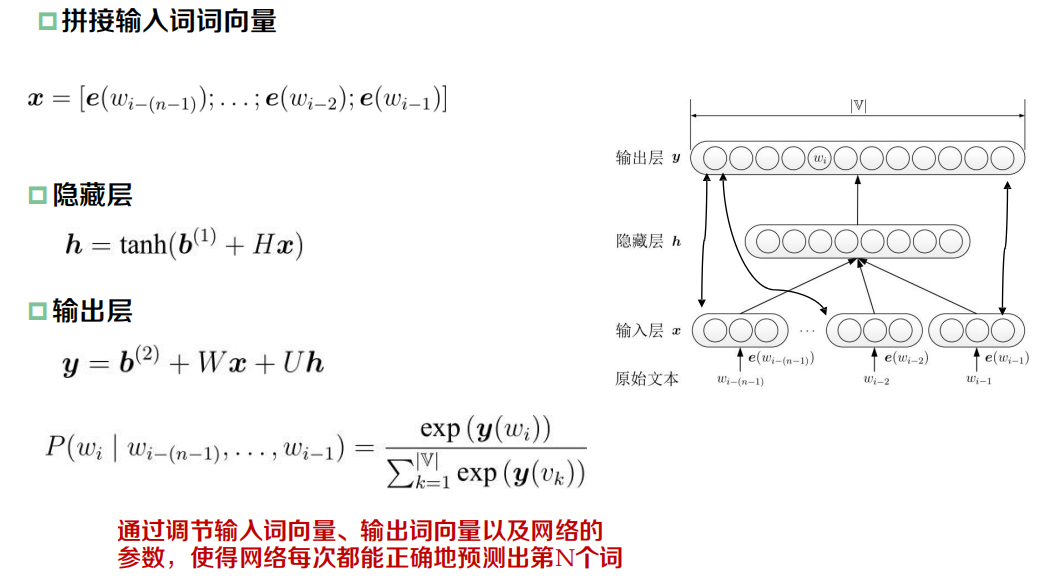
NNLM: Neural Network Language Model
三層前饋神經網路,以前n-1個詞作為輸入,第n個詞作為輸出,進而完成網路引數的優化,實作詞向量的表示學習
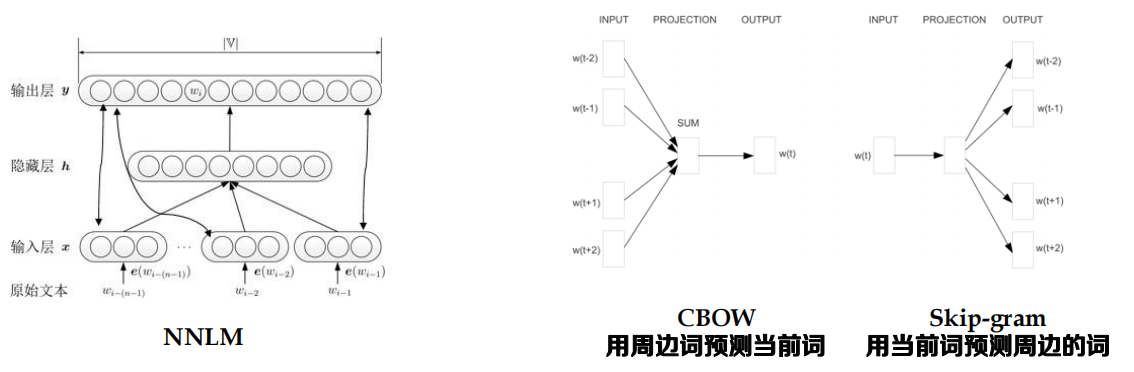
CBOW & Skip-gram
- Continuous Bag of Word
- 特點:
?去除隱藏層
?去除詞序
研表究明,漢字序順并不定一影閱 響讀!事證實明了
也許當你看這完 句話之后才發字現都亂是的,
工具示例
Word2vec:Google在2013年年中開源的一款將詞表征為實數值向量的高效工具,采用的模型有CBOW和Skip-Gram兩種,
代碼鏈接:https://code.google.com/p/word2vec/
輸入文本:英文(token后的文本)中文(分詞后的文本)
輸出:指定維度的詞向量
自然語言的表示學習
基本語言單元的語意表示
- 詞的表示
- 分布式原則
更大語言單元的語意表示
- 句子的表示
- 語意組合原則
組合語意
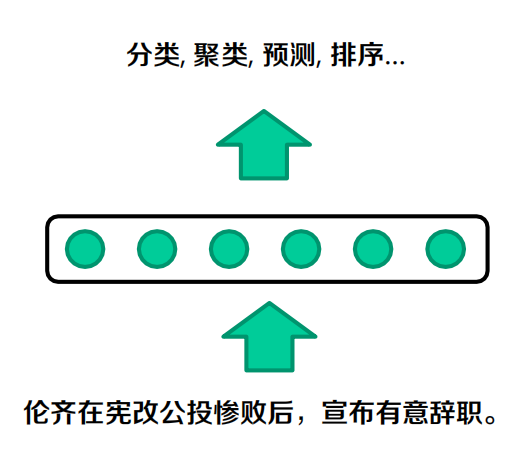
- 一個復雜物件的意義是由其各組成部分的意義以及它們的組合規則來決定
- The meaning of a complex expression is determined by the meanings of its constituent expressions and the rules used to combine them
意義的組合和具體任務相關
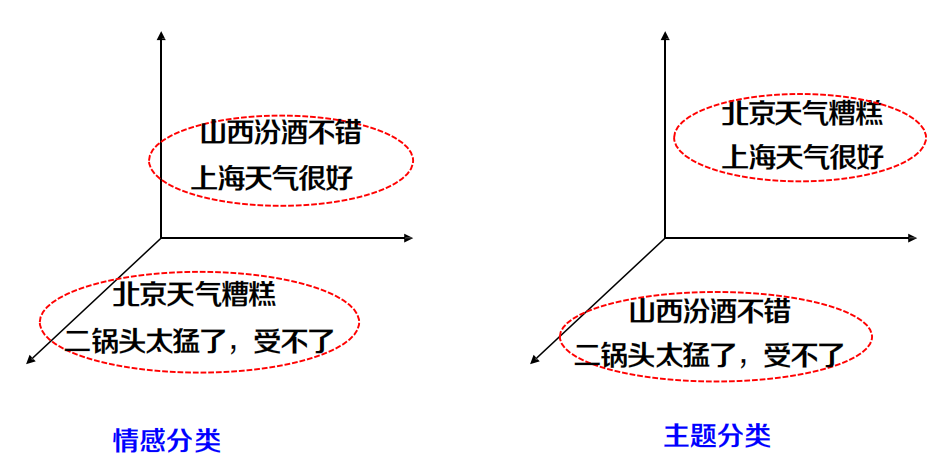
- 基于詞語等基本語意單元表示句子等更大語意單元的程序
- 語意組合模型就是要建模句子的句法/語意結構
兩類最基本語意組合模型

基礎:多層前饋神經網路
在前饋神經網路中,各神經元分別屬于不同的層,整個網路中無反饋,信號從輸入層向輸出層單向傳播,可用一個有向無環圖表示,
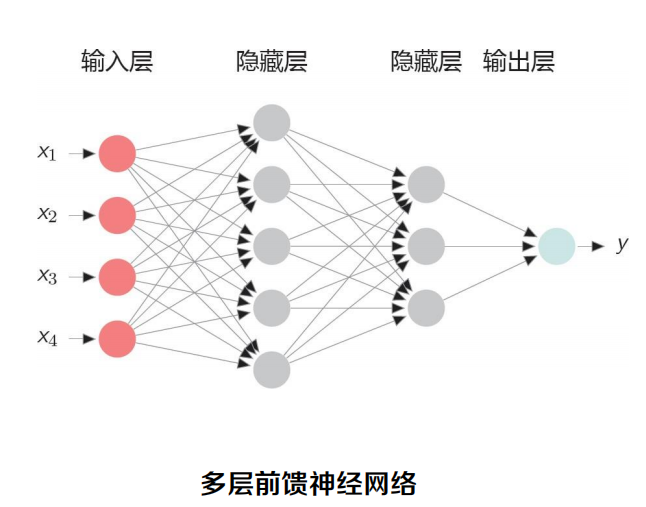
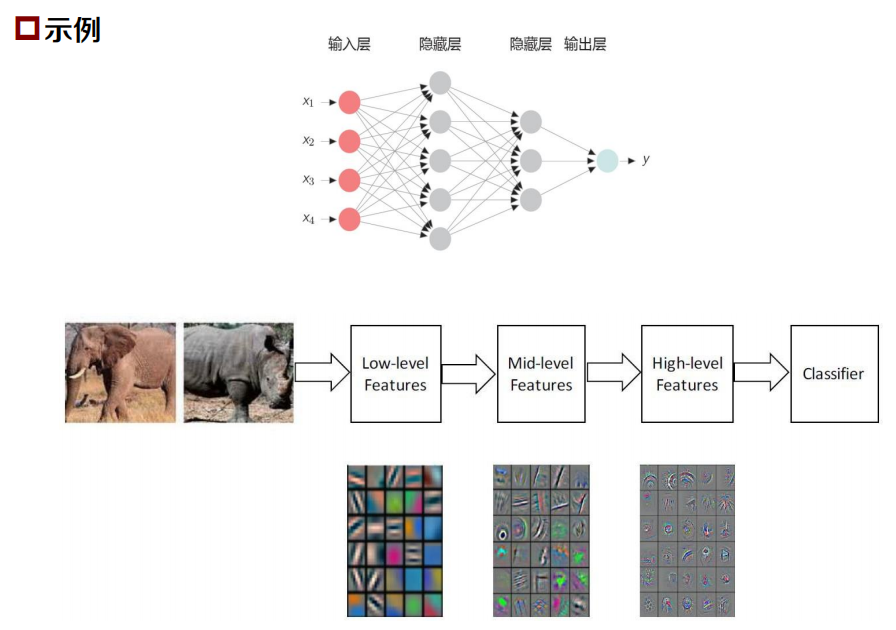
- 全連接層:相鄰兩層的任何兩個不同層神經元之間都存在連接,在全連接前饋神經網路中
- 如果第l 層有nl個神經元,L表示神經網路的層數
- 則引數個數: 𝐿 𝑛𝑙
- 權重矩陣引數非常多,訓練效率低下
- 資料不足時,欠學習
卷積神經網路
Convolutional Neural Networks,CNN
-
一種前饋神經網路
-
是受生物學上感受野(Receptive Field)的機制而提出的,
- 感受野主要是指聽覺系統、感覺系統和視覺系統中神經元 的一些性質,
- 例如:在視覺神經系統中,一個神經元的感受野是指視網膜上的特定區域,只有這個區域內的刺激才能夠激活該神經元,
-
特性:卷積神經網路有三個結構上的特性
- 區域連接
- 權重共享
- 采樣
這些特性使得卷積神經網路具有一定程度上的平移、縮放和扭曲不變性
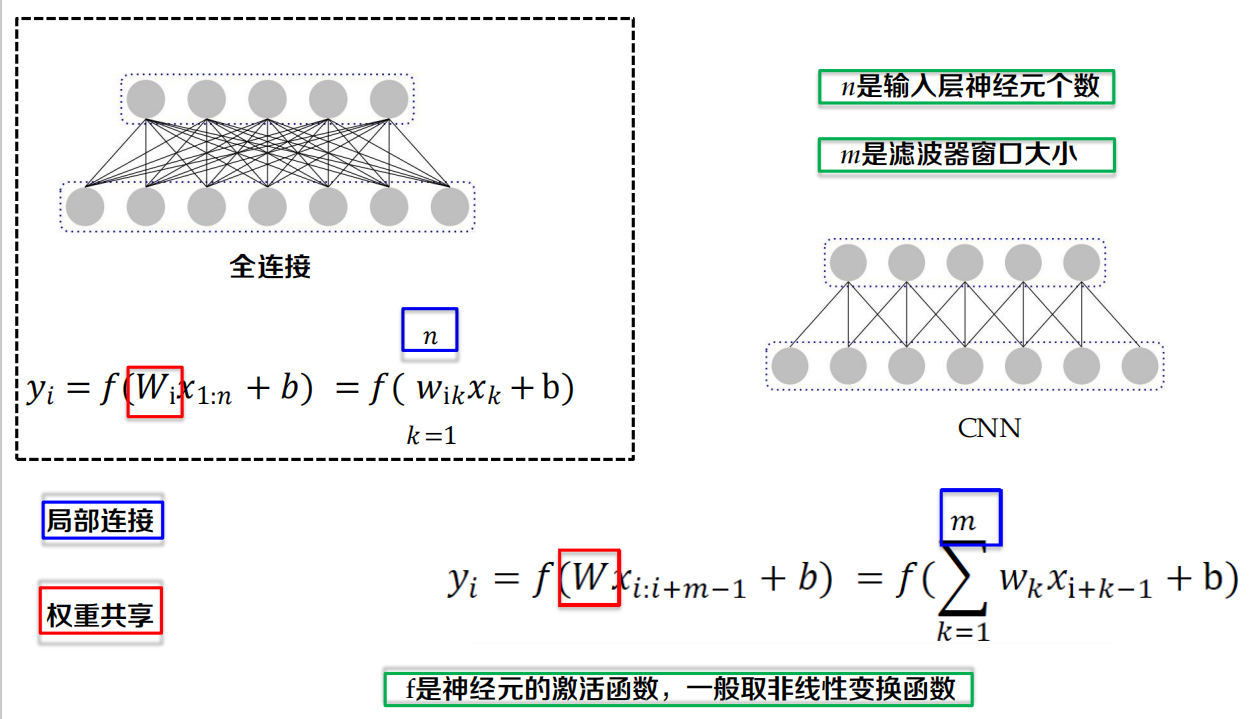
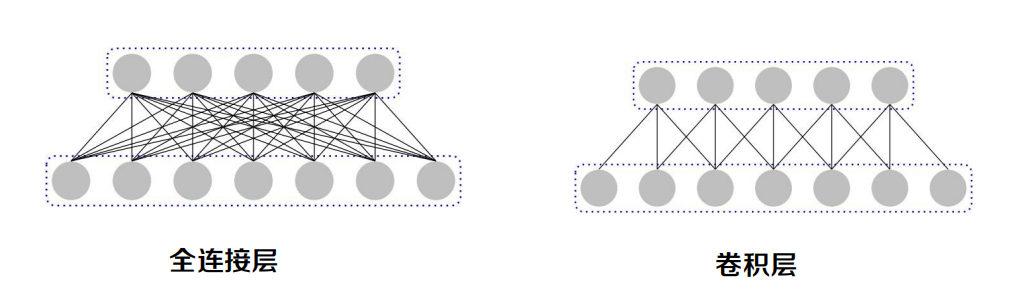
全連接 vs 卷積
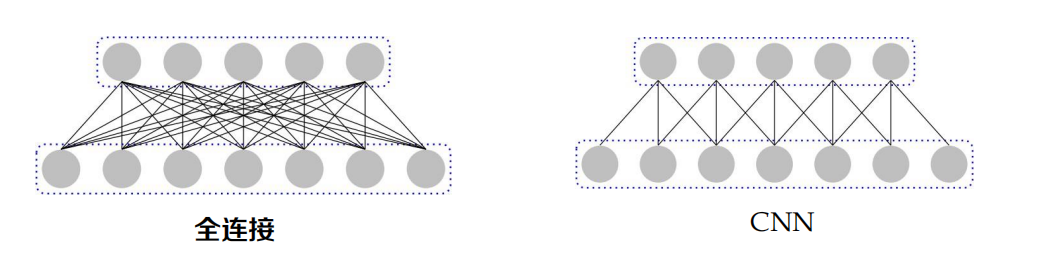
不同:
- 全連接 vs 區域連接
- 權重獨立 vs 權重共享
- 一般不采樣 vs 一般采樣
例子:引數規模(全連接 vs 卷積)
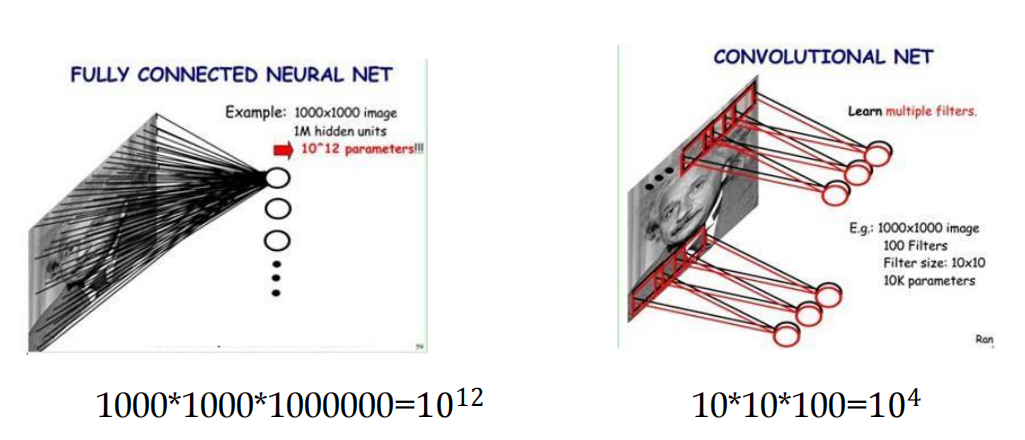
左邊的圖表示全連接,輸入為1000*1000,假設下一層神經元的數目為1M,引數規模為1012,
右邊的圖是卷積網路示意,當一個濾波器的大小為10*10時,一個濾波器處理圖片不同區域時權重共享,所以卷積結果規模為991*991,已經接近1M;即使使用100個濾波器,引數規模也為10*10*100=104,引數個數遠小于全連接的情況,
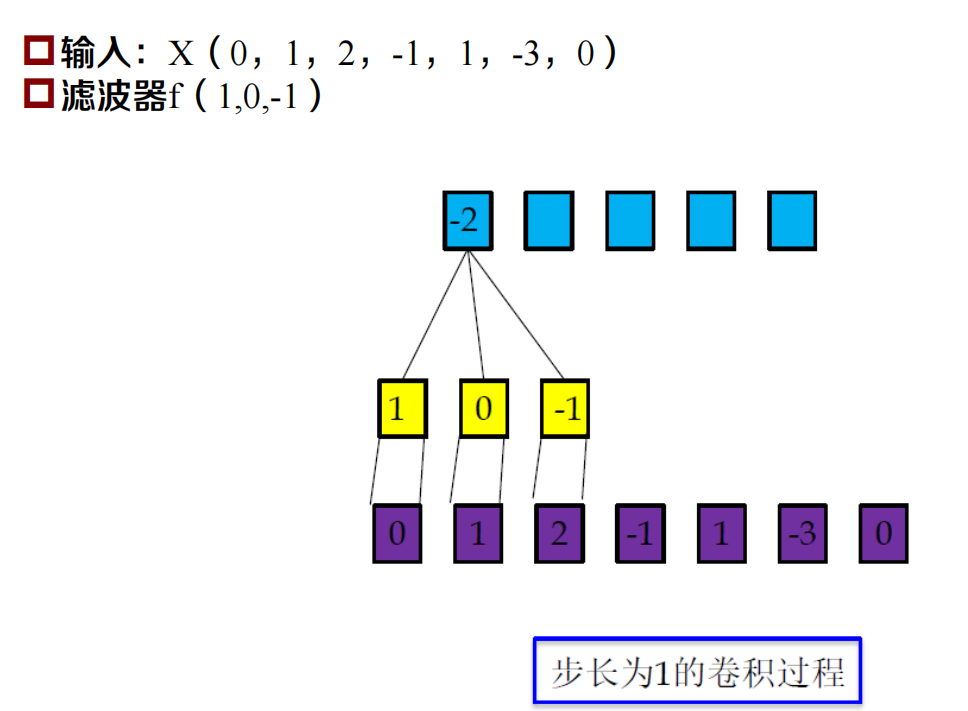
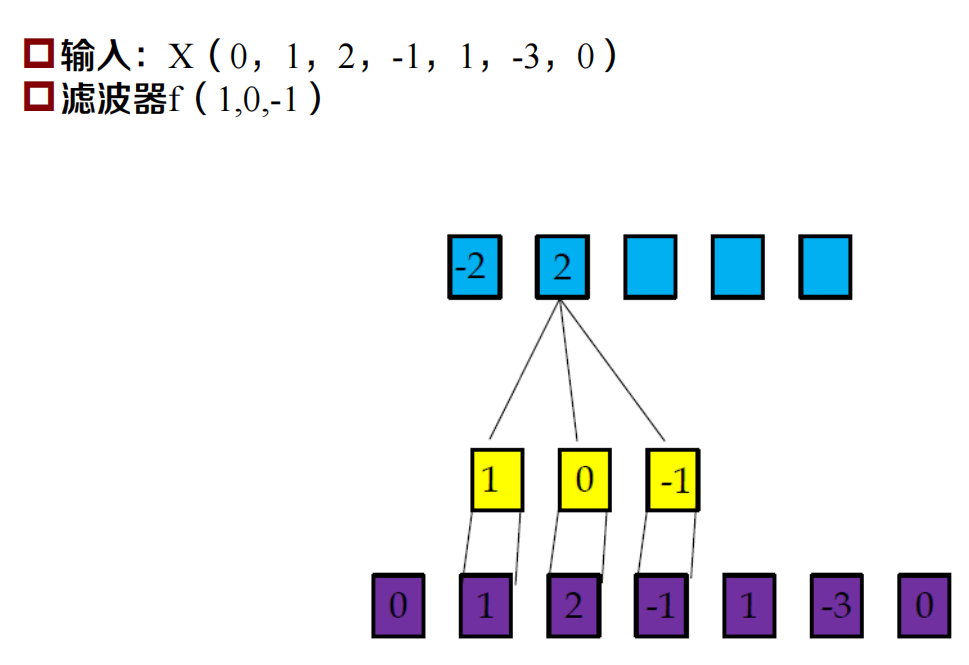
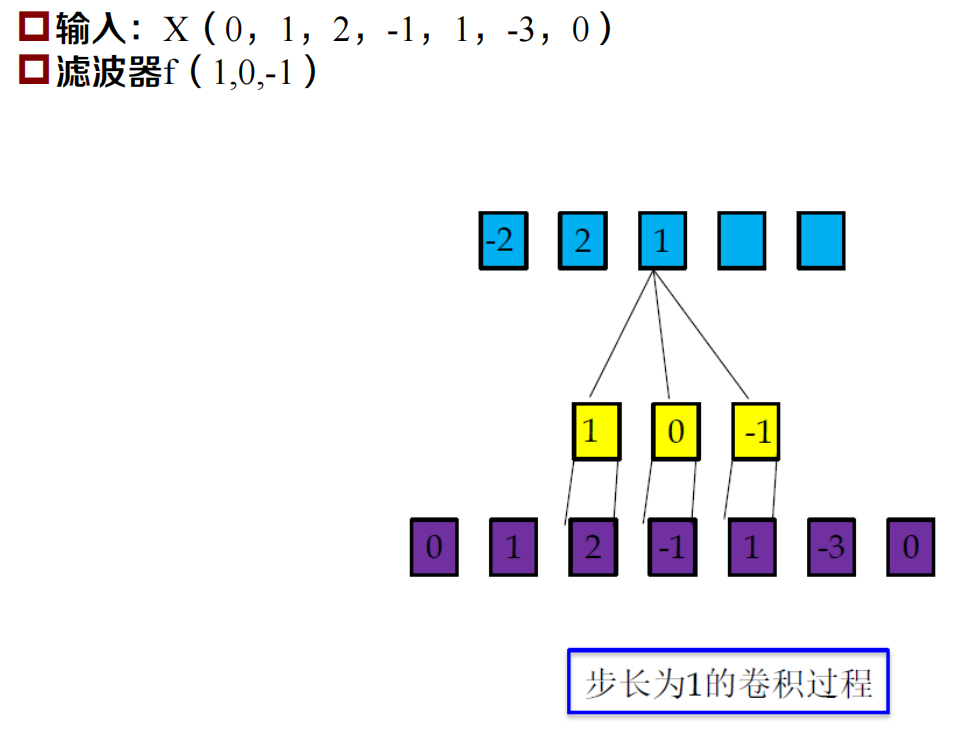
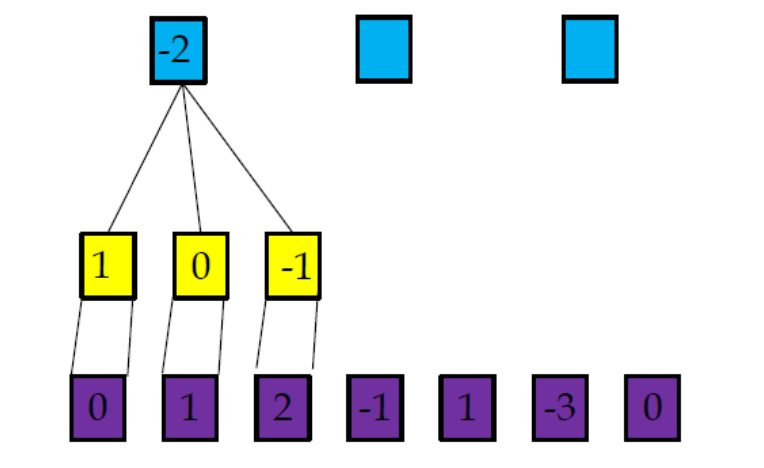
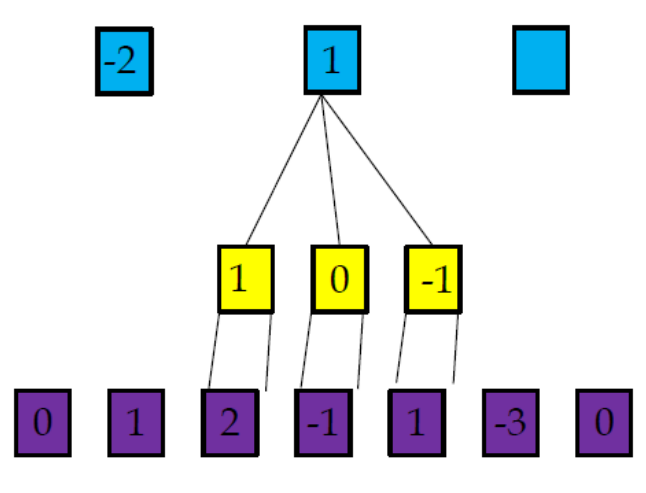
一維卷積

一維卷積示例
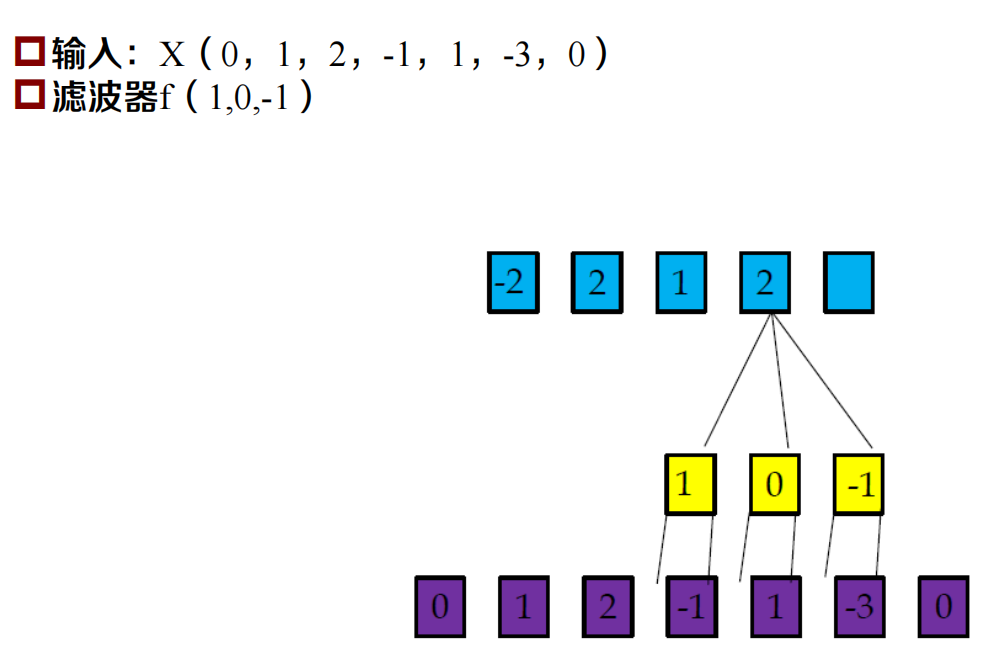
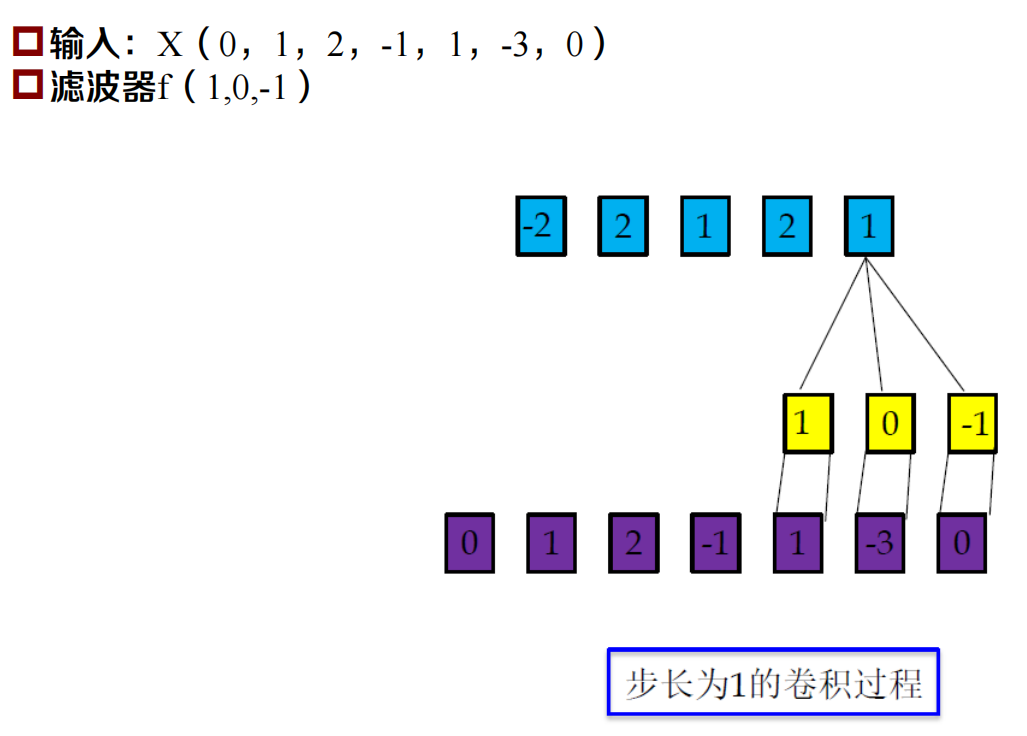
卷積的引數
卷積視窗:濾波器的引數數目,表征了每次編碼的資訊單元的大小
卷積步長:濾波器編碼資訊時每次移動的距離
例子:視窗為3,步長為2
卷積步長
卷積視窗:濾波器的引數數目,表征了每次編碼的資訊單元的大小
卷積步長:濾波器編碼資訊時每次移動的距離
例子:視窗為3,步長為2
卷積視窗:濾波器的引數數目,表征了每次編碼的資訊單元的大小
卷積步長:濾波器編碼資訊時每次移動的距離
例子:視窗為3,步長為2
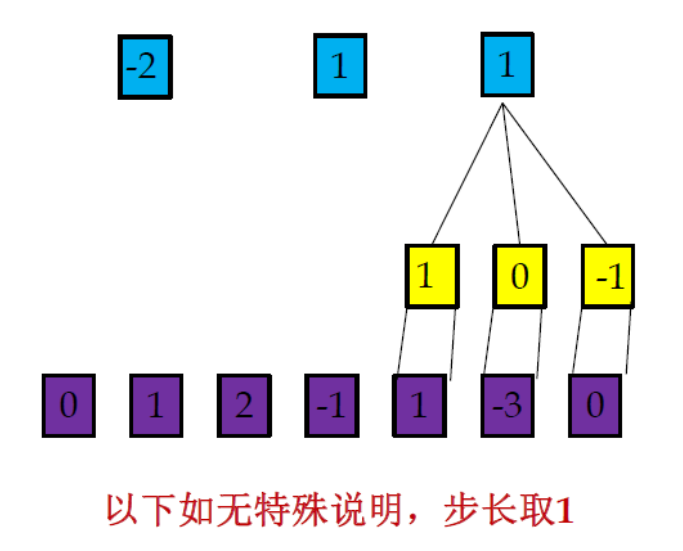
窄卷積、寬卷積、等長卷積
- 窄卷積:輸出長度n-m+1,不補零,
- 寬卷積:輸出長度n + m -1,對于不在[1,n] 范圍之外的xt 用零補齊(zero-padding),(Padding=m-1)
- 等長卷積:輸出長度n,對于不在[1,n]范圍之外的xt用零補齊(zero-padding),(Padding=(m-1)/2)
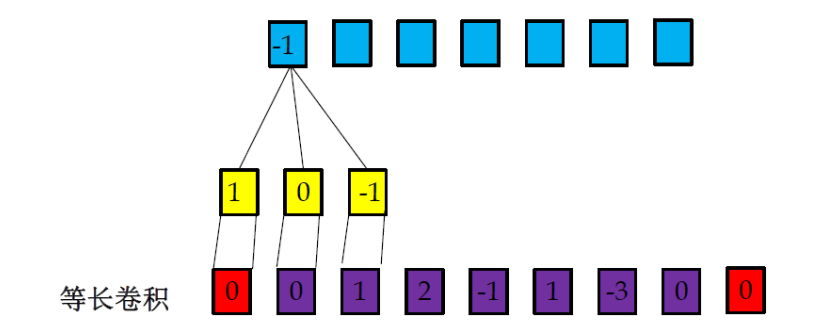
在這里除了特別宣告,我們一般說的卷積默認為窄卷積,
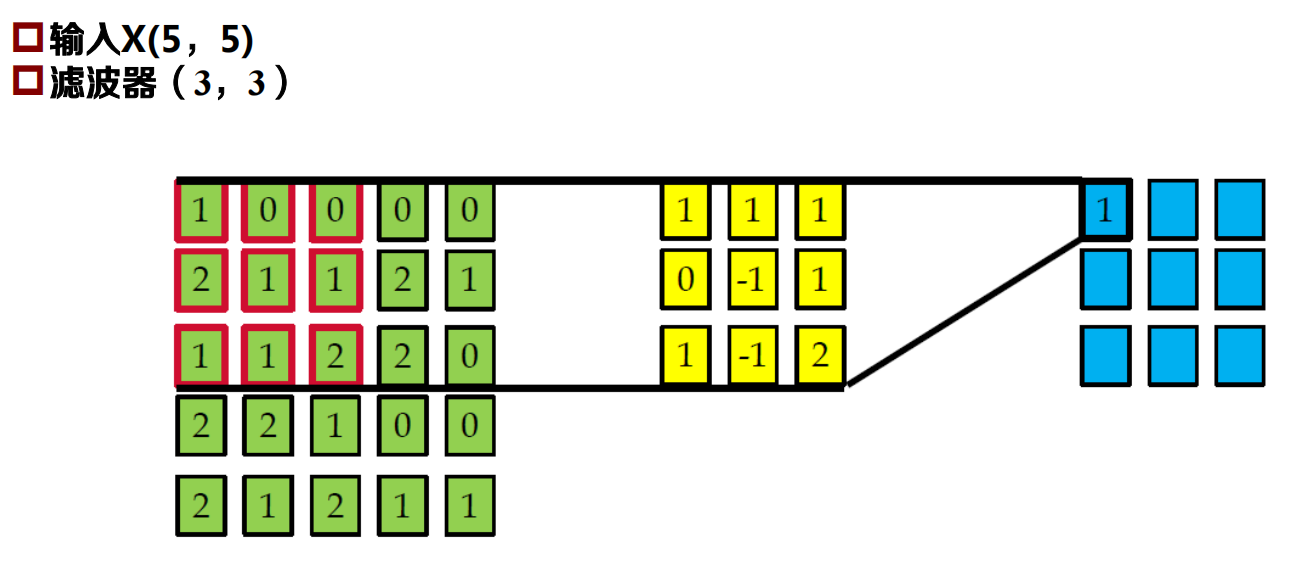
二維卷積
兩維卷積經常用在影像和自然語言處理中
給定一個影像或句子X=[xij], i∈ 1, M , j ∈ 1,𝑁]
濾波器W=[wij], i∈ 1, m , j ∈ 1,n 一般m << M; n << N
卷積后的輸出值Y中的每個位置如下表示
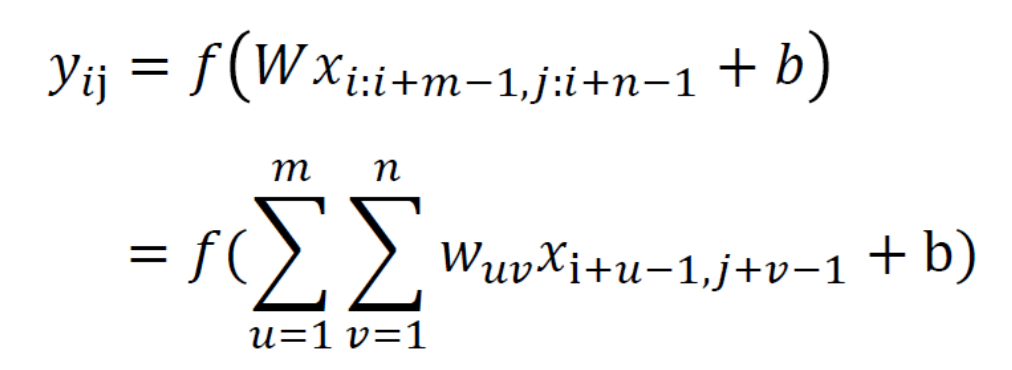
二維卷積示例
濾波器:特征提取器
如果把濾波器看成一個特征提取器,每一組輸出都可以看成是輸入經過一個特征抽取后得到的特征,因此,在卷積神經網路中每一組輸出也叫作一個特征映射(Feature Map),
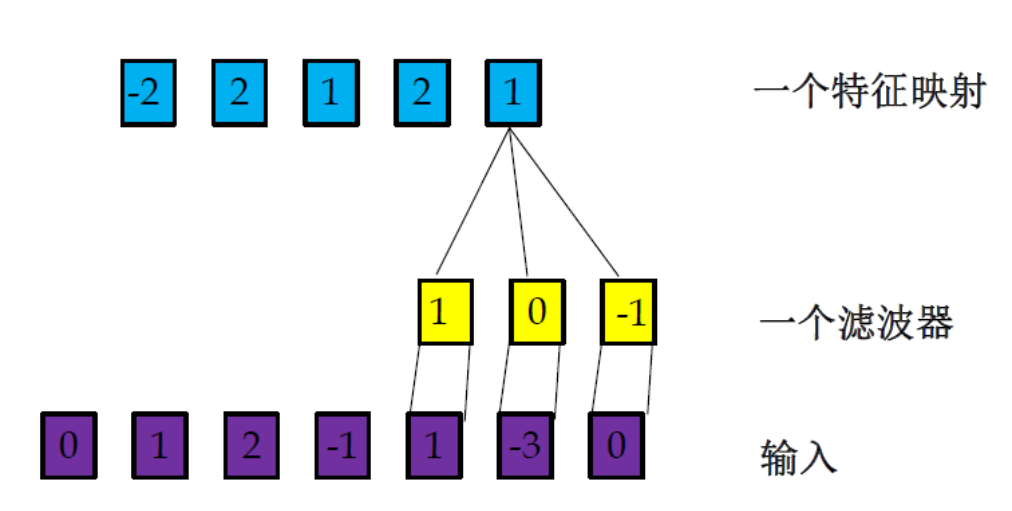
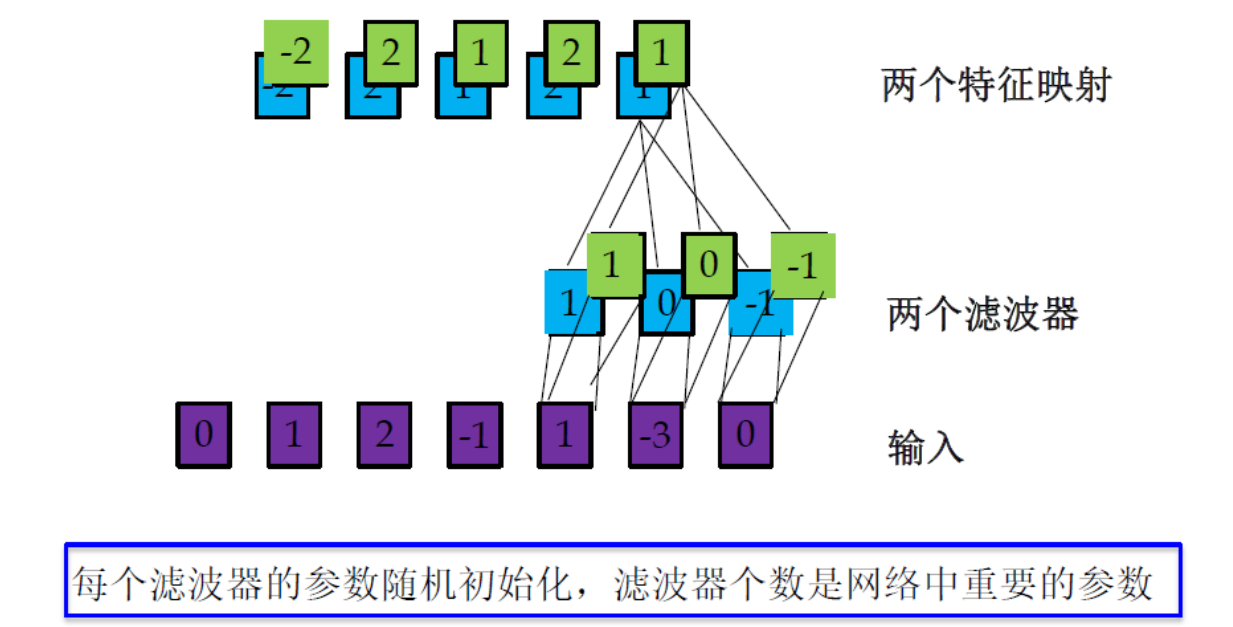
多個濾波器
為了增強卷積層的表示能力,可以使用K 個不同的濾波器來 得到K 組輸出,即K個特征映射,
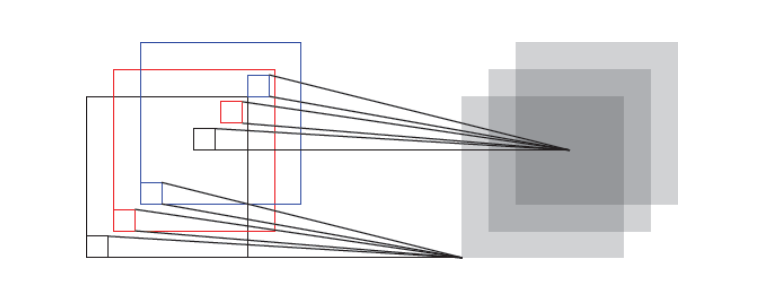
卷積層作用
提取一個區域區域的特征,每一個濾波器相當于一個特征提取器,
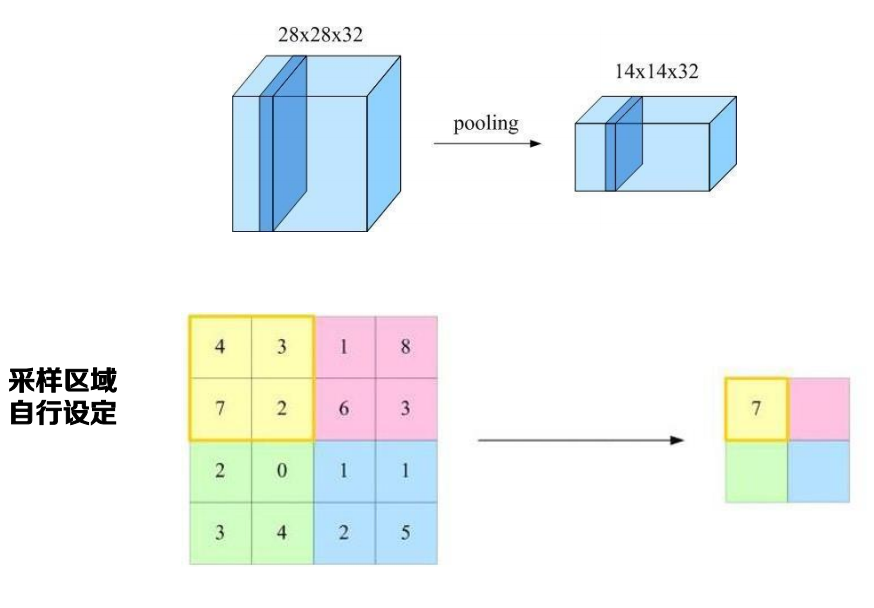
子采樣層
子采樣層:池化操作
雖然卷積層通過區域連接和權重共享顯著減少了連接的個數,但是每一個特征映射的維度并沒有顯著減少,
如果后面接一個分類器,分類器的輸入維數依然很高,容易出現過擬合,
為了解決這個問題,卷積神經網路一般會在卷積層之后再加 一個池化(Pooling)操作,即子采樣(Subsampling), 構成一個子采樣層,通過子采樣顯著降低特征維數,避免過擬合,
- 對于卷積層得到的一個特征映射𝑋(𝑙),則采樣層輸
出有:
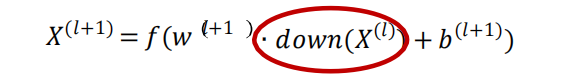
其中,𝑤 𝑙+1 和 𝑏(𝑙+1)分別是可訓練的權重和偏置引數
𝑑𝑜𝑤𝑛(𝑋(𝑙))是指子采樣后的特征映射

子采樣層示例
引數訓練
任務:一個濾波器,就是訓練W和b
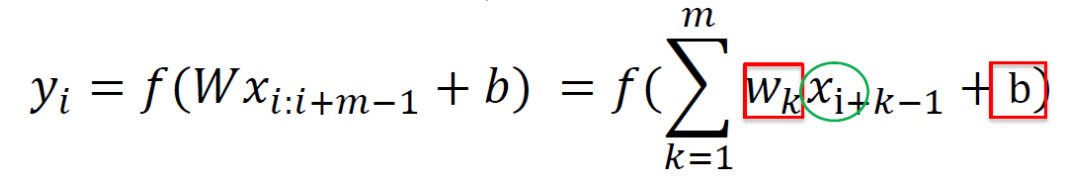
采用反向傳播演算法
- 選擇一個樣本 x,資訊從輸入層經過逐級的變換,傳送到輸出層
- 計算該樣本的實際輸出 o 與相應的理想輸出 t 的差
- 按極小化誤差反向傳播方法調整權矩陣,也可以調整輸入詞向量
示例
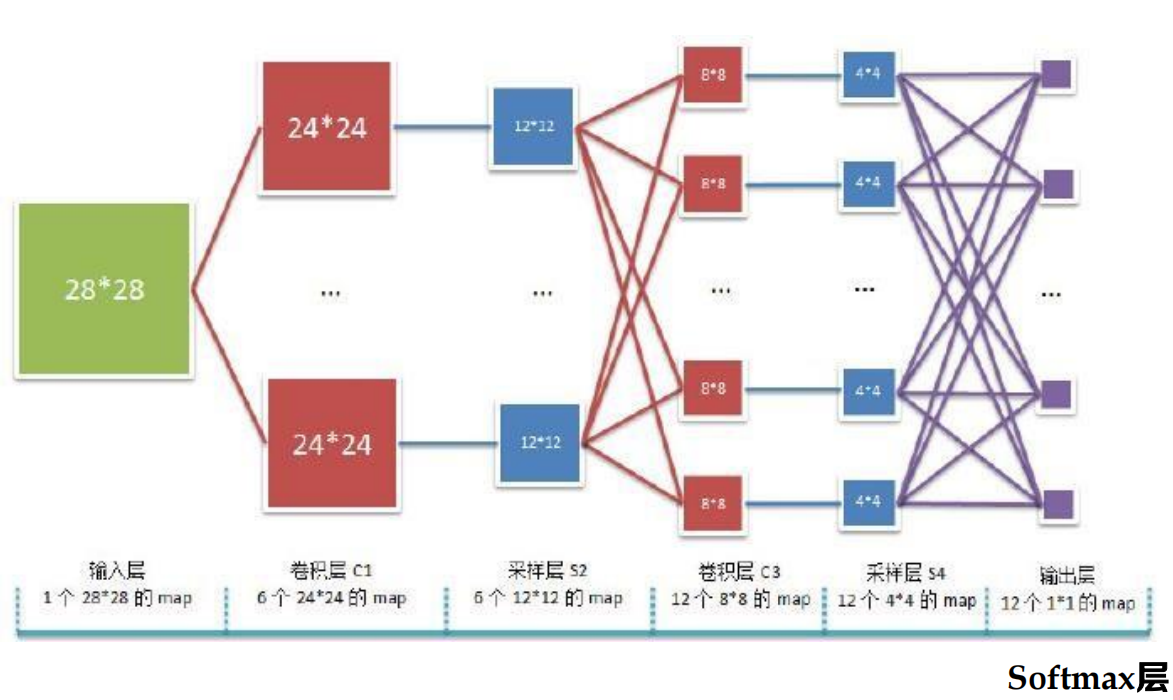
基于卷積神經網路的關系抽取
任務:判別句子中物體之間的語意關系
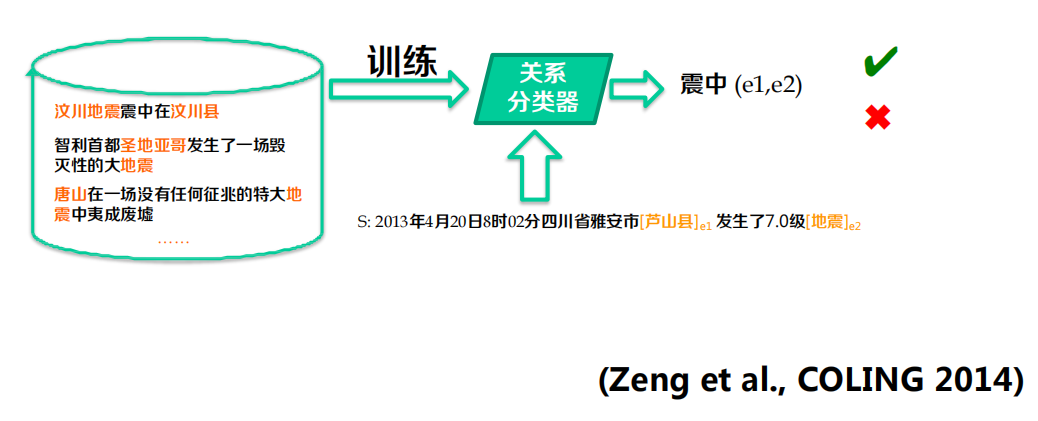
S: 2013年4月20日8時02分四川省雅安市[蘆山縣]e1 發生了7.0級[地震]e2
語意關系分類
傳統特征提取需要NLP預處理+人工設計的特征
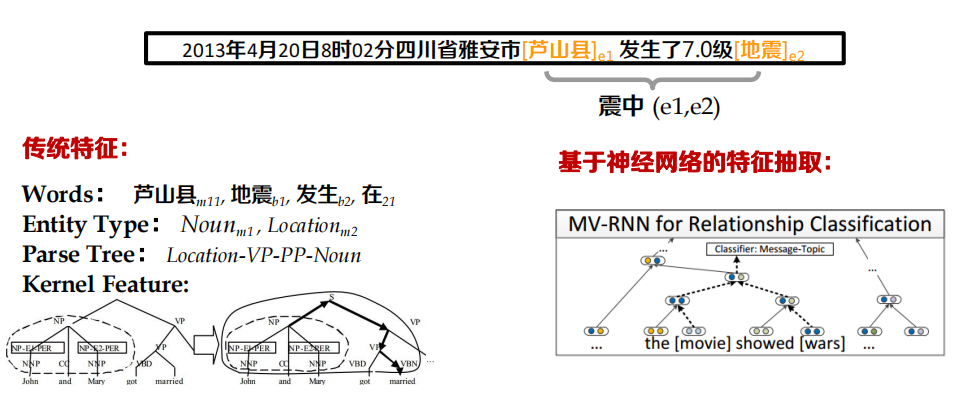
? 問題1:對于缺少NLP處理工具和資源的語言,無法提取文本特征
? 問題2:NLP處理工具引入的“錯誤累積”
? 問題3:人工設計的特征不一定適合當前任務
解決方法
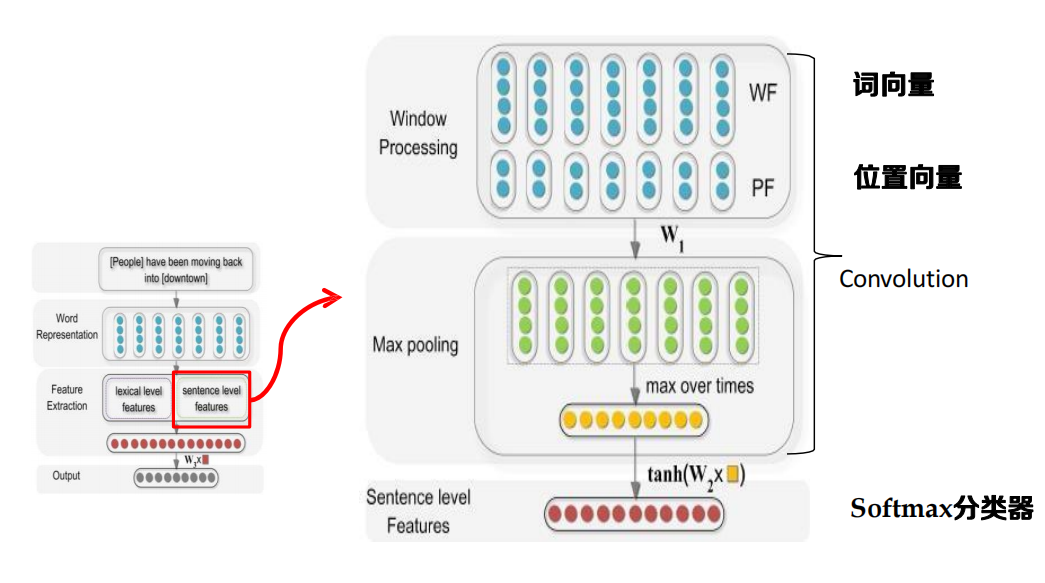
基于卷積神經網路的物體關系分類方法
- 通過CNN學習文本語意特征
- 不需要人工設計特征

詞匯級特征
利用詞向量(Word Embedding)資訊作為詞匯級特征

句子級特征
利用CNN捕獲句子級特征
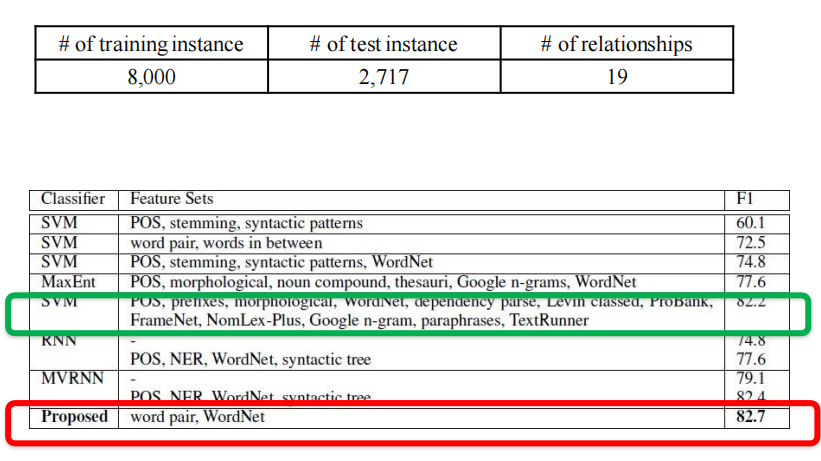
實驗結果
前饋神經網路的缺點
輸入和輸出的維數都是固定的,不能任意改變,無法處理 變長的序列資料
句子是有長有短,影像大小也不固定
連接存在于層與層之間,每層的節點之間是無連接的,假設每次輸入都是獨立的,無法建模時序或者位置資訊
回圈神經網路
反饋神經網路
- 全部或者部分神經元可以接受來自其它神經元或自身的神經元信號(cf. 前饋神經網路只接受前一層的神經元信號)
- 可以建立同層神經元的關聯,從而每層節點之間有連接,因此可以建模時序或者位置資訊,處理變長的序列資料
回圈神經網路:至少包含一個反饋連接的神經網路結構, 網路的激勵可以沿著一個loop 進行流動,這種網路結構特別適合于處理時序資料,
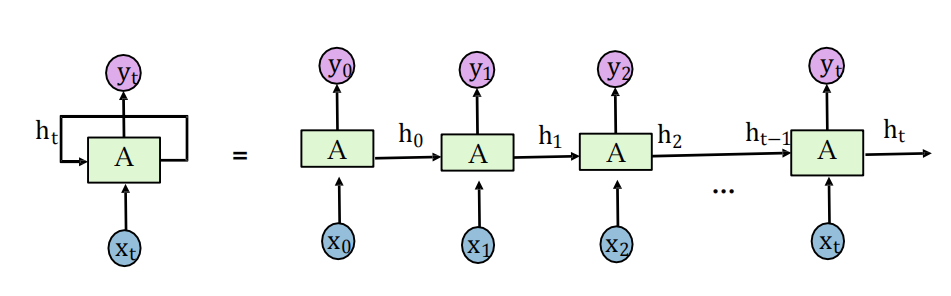
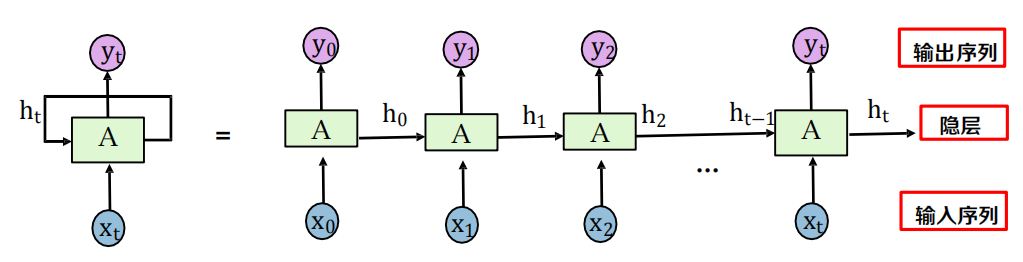
假設時刻𝑡時,輸入為𝑥𝑡,隱層狀態為?𝑡, ?𝑡不僅和當前 時刻的輸入相關,也和上一個時刻的隱層狀態
h
𝑡
?
1
?_𝑡?1
ht??1相關,
-
A代表一個RNN單元,由一套引陣列成
-
一般使用如下函式:

ht的目的是編碼從0到t時刻的所有資訊
回圈神經網路:應用場景
- 輸入:任意長度的序列
- 輸出:同樣長度的序列
- 適合:序列標注任務
- 例如:命名物體識別
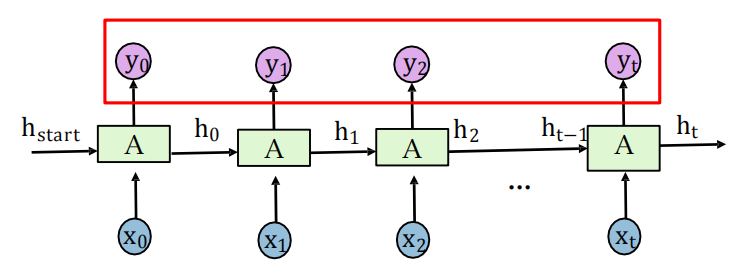
?輸入:任意長度的序列
?輸出:關于該序列的一個向量表示
?適合:輸入序列的統一表示
?應用:文本分類(ht是文本的表示,再加一個分類層)
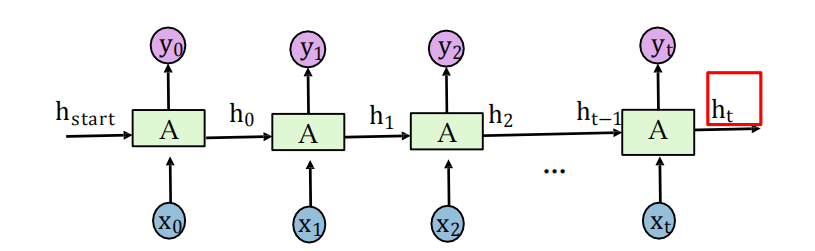
?輸入:任意長度的序列
?輸出:關于該序列的多個向量表示
?適合:輸入序列中每個時刻的表示
?應用:關系分類
- xt是句子中的一個詞,ht是這個詞在當前背景關系的表示
- hk和hj是待分類的兩個物體的表示
- 再加一個分類器完成關系分類
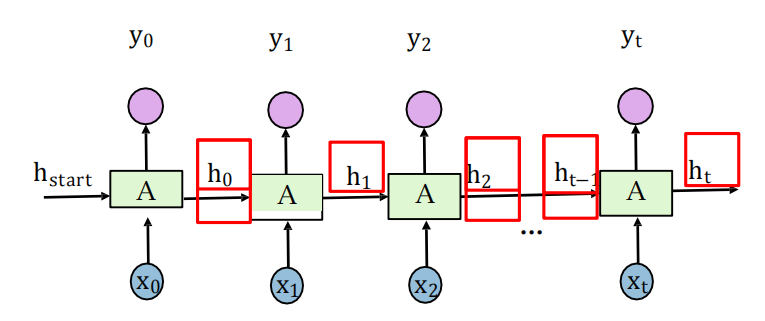
引數學習
回圈神經網路(4個引數),其中U,W,V是矩陣,b是向量
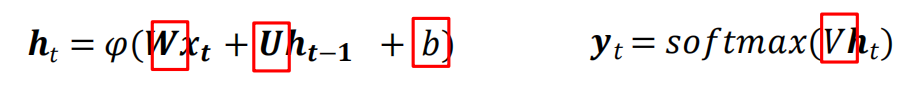
引數訓練可以利用反向傳播演算法(Backpropagation
Through Time,BPTT)
- P. J. Werbos. “Backpropagation through time: what it does and how to do it”. In: Proceedings of the IEEE 10 (1990).
問題:序列長度過長時會導致梯度爆炸或者梯度消失問題
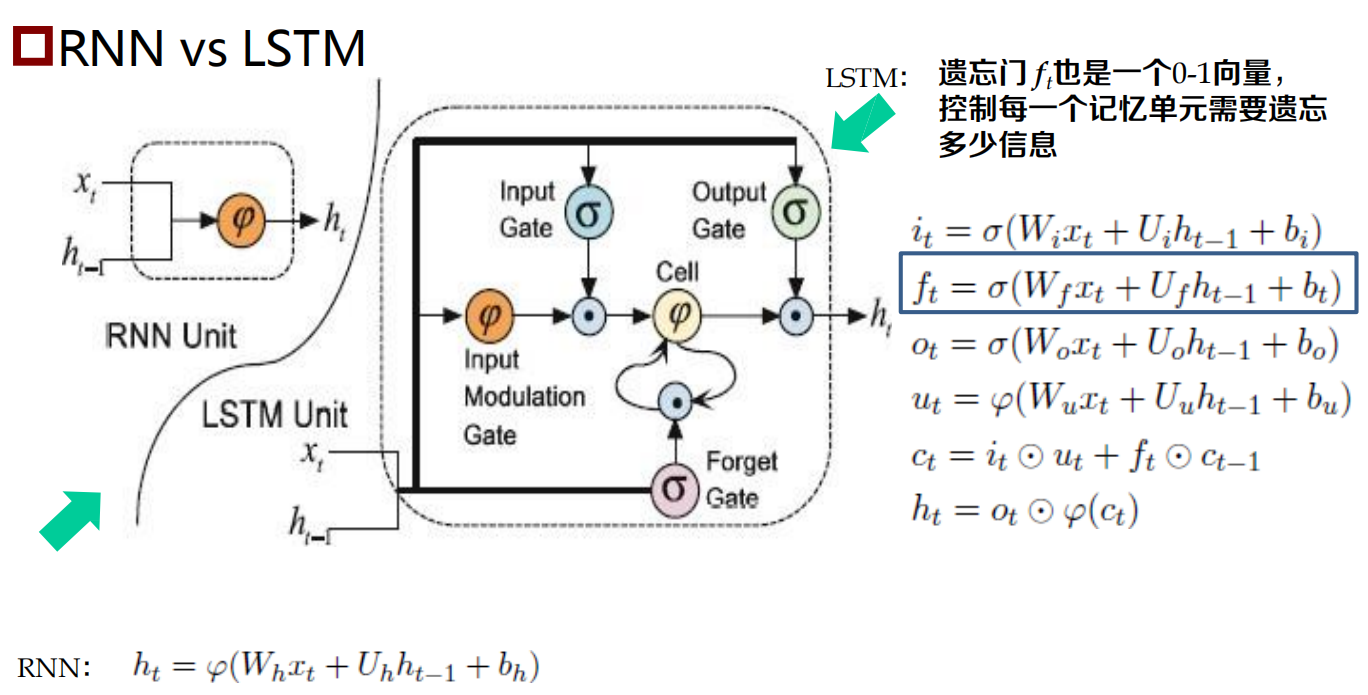
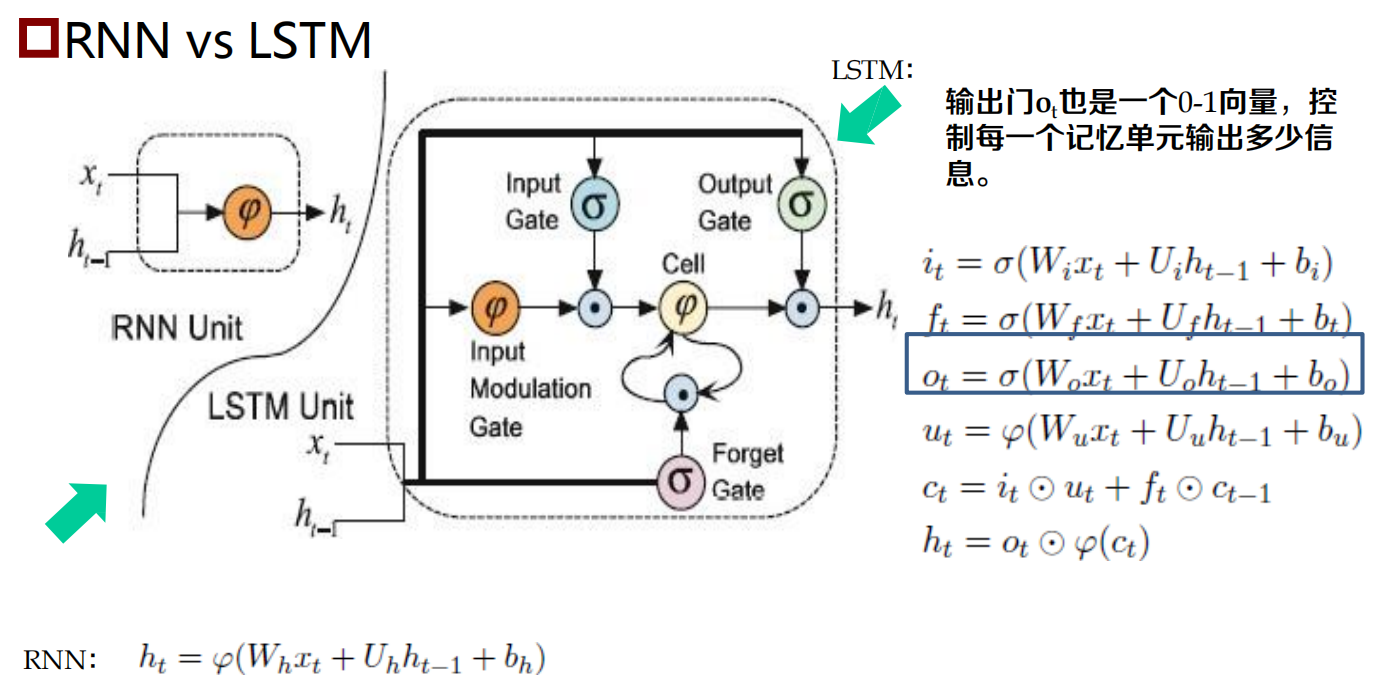
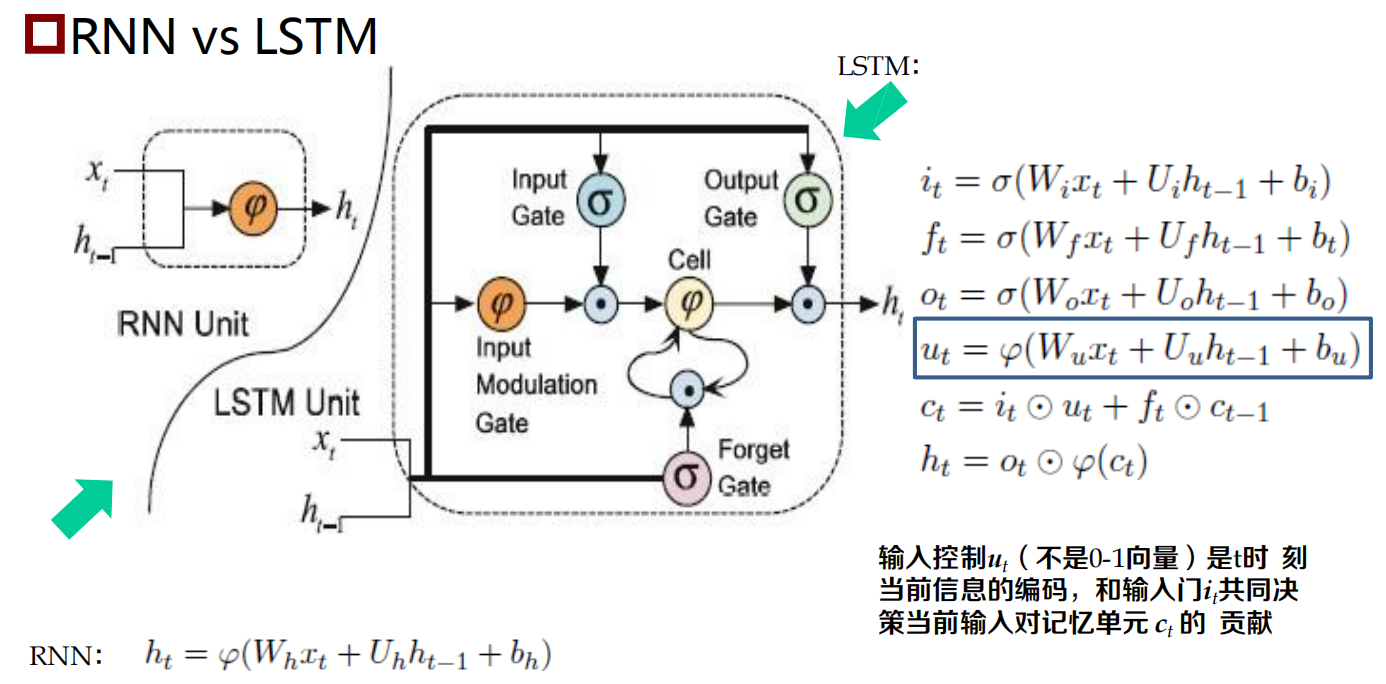
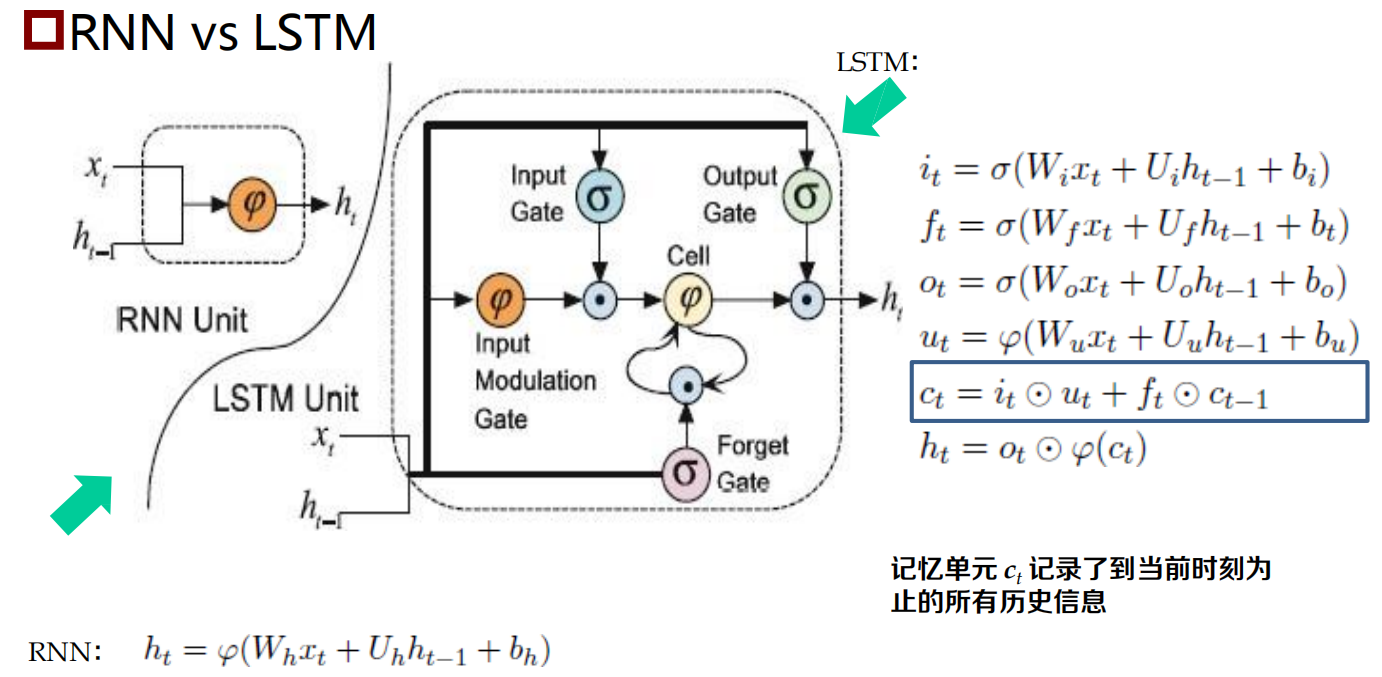
長短時記憶神經網路:LSTM
長短時記憶神經網路:Long Short-Term Memory Neural Network,LSTM)
RNN的一個變體,可以有效地解決簡單回圈神經網路的梯度爆炸或消失問題
關鍵:引入了一組記憶單元(Memory Units),允許網路可以學習何時遺忘歷史資訊,何時用新資訊更新記憶單元,
- 在時刻 t ,記憶單元 ct 記錄了到當前時刻為止的所有歷史資訊,并受三個“門”控制:輸入門 it , 遺忘門ft 和輸出門ot ,三個門的元素的值在[0, 1] 之間,
RNN: LSTM:
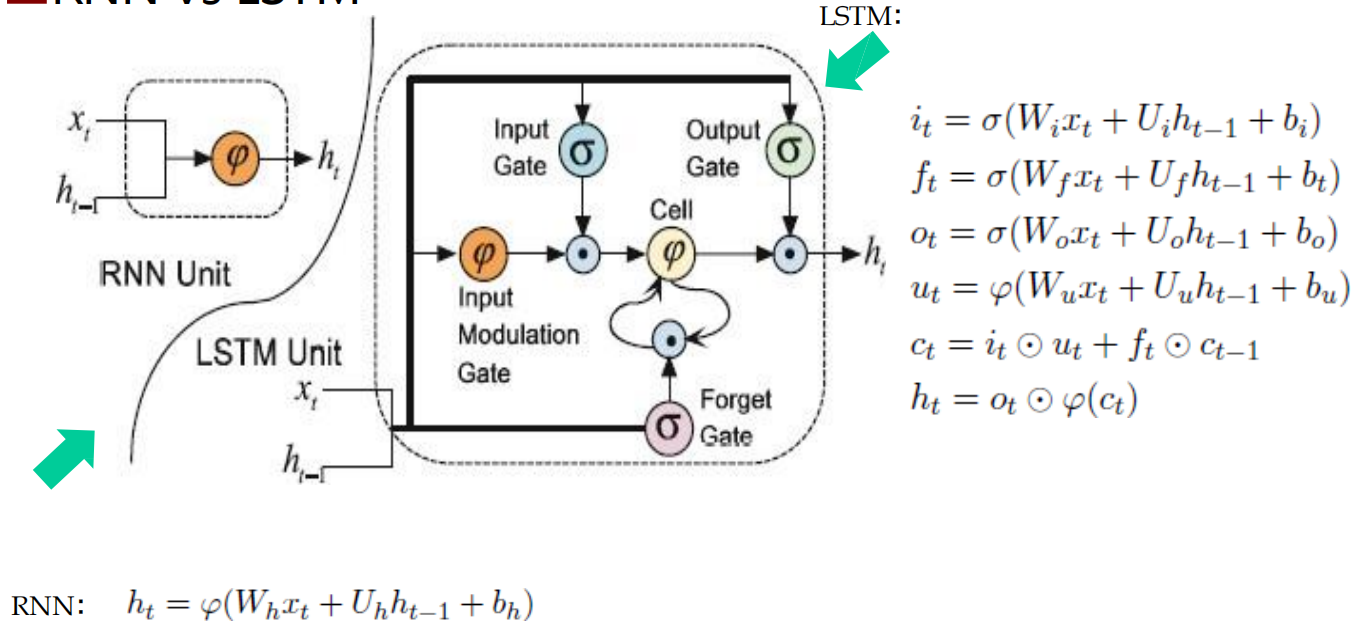
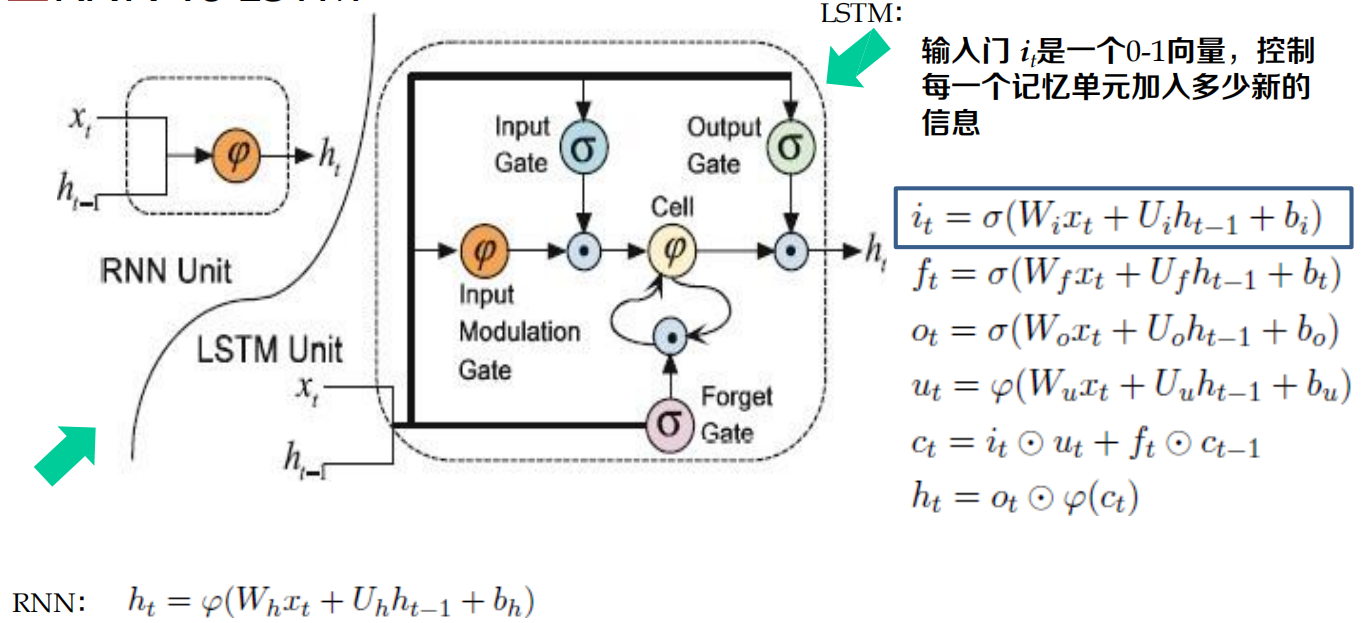
雙向回圈神經網路
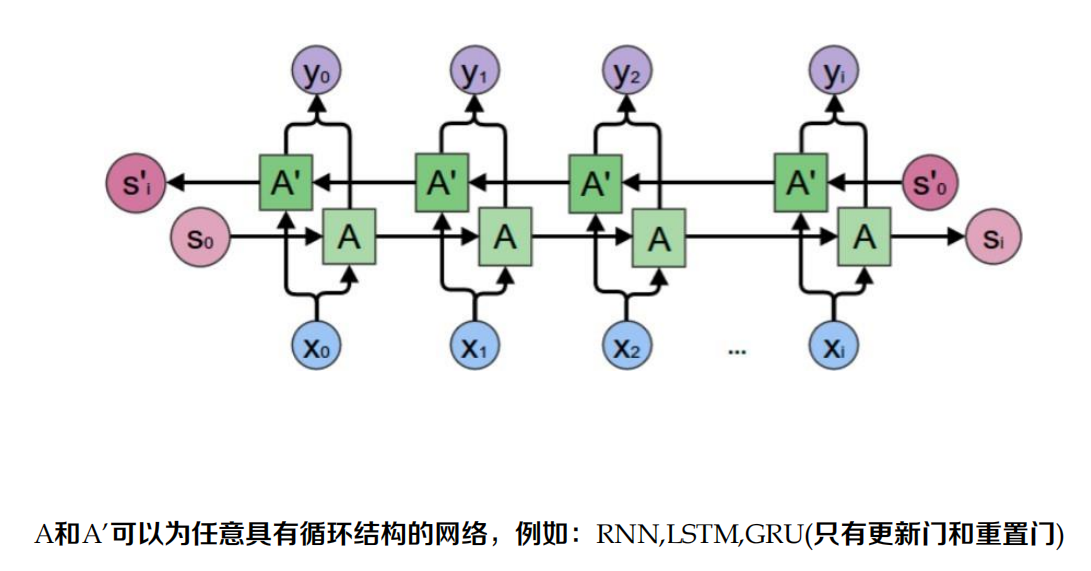
層疊(Stack)回圈神經網路
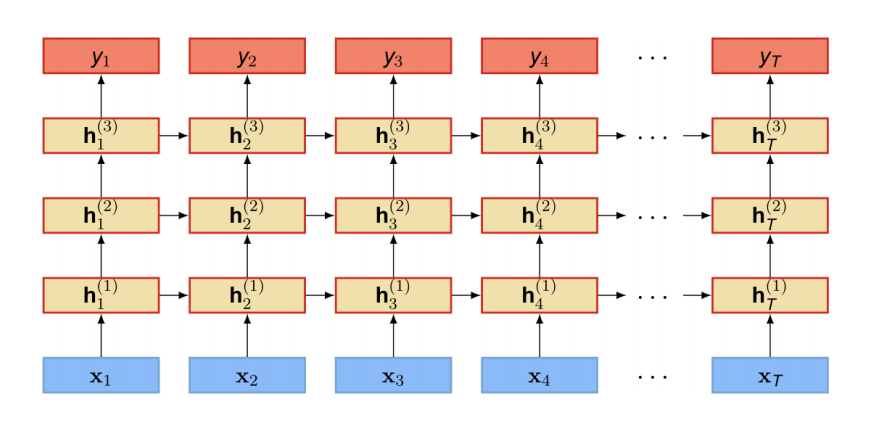
本質就是多個回圈網路逐層使用
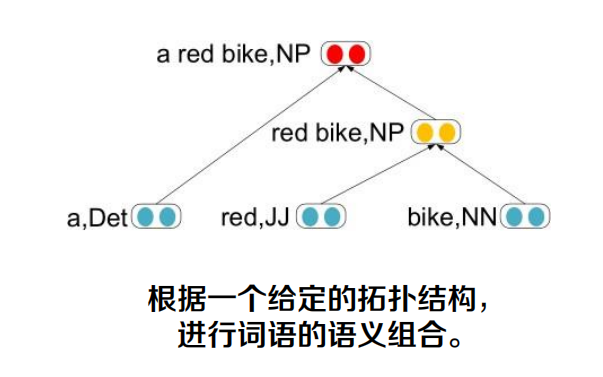
遞回神經網路
遞回神經網路:Recursive Neural Network (RecNN)
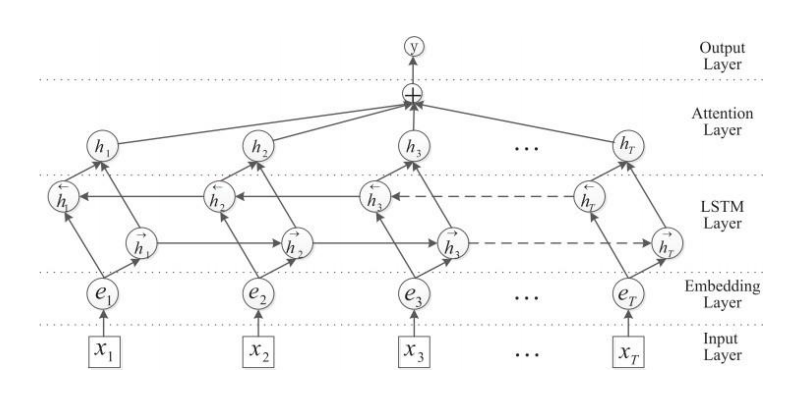
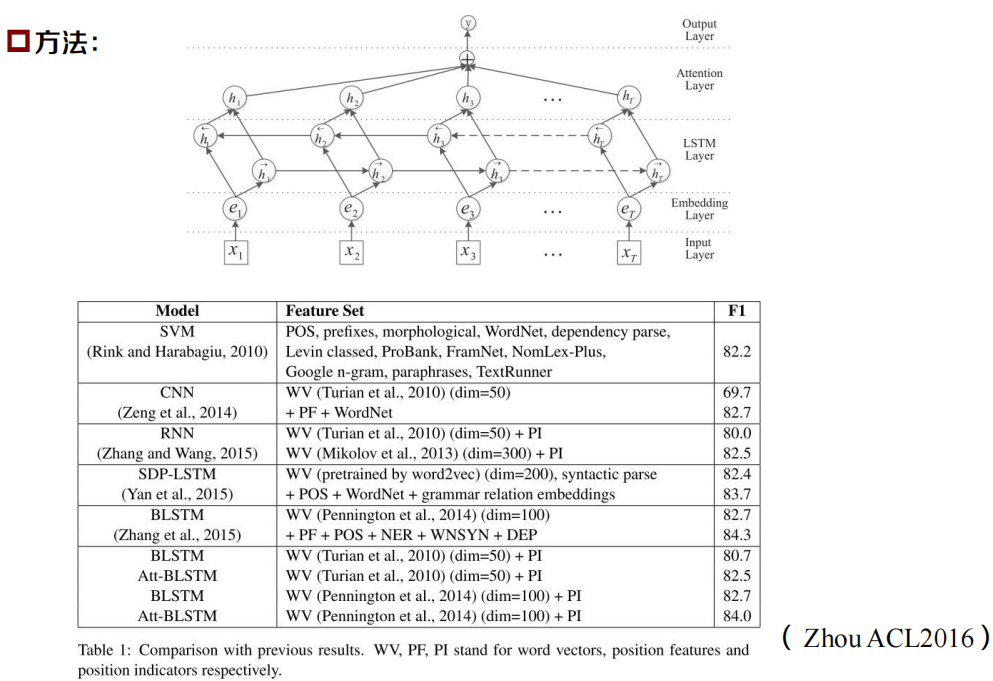
利用LSTM做關系抽取
動機:
- 句子級語意資訊對關系抽取任務至關重要
- 句子中的不同位置的詞有不同程度的重要性
- 傳統方法依賴NLP工具,人工提取特征,造成錯誤傳遞
- CNN的方法難以建模句子中長距離的依賴關系

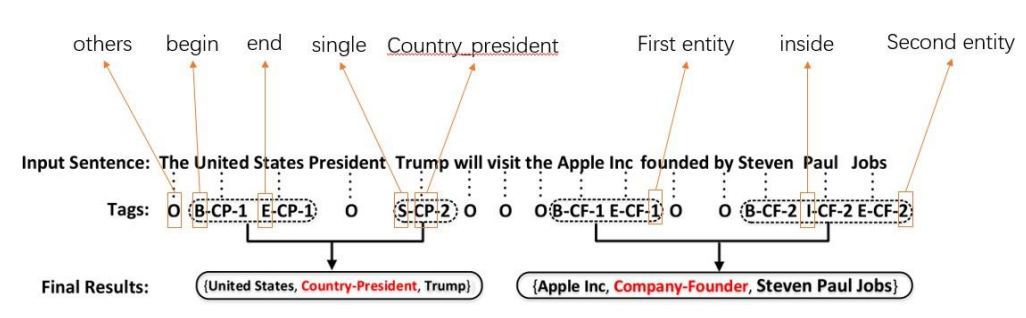
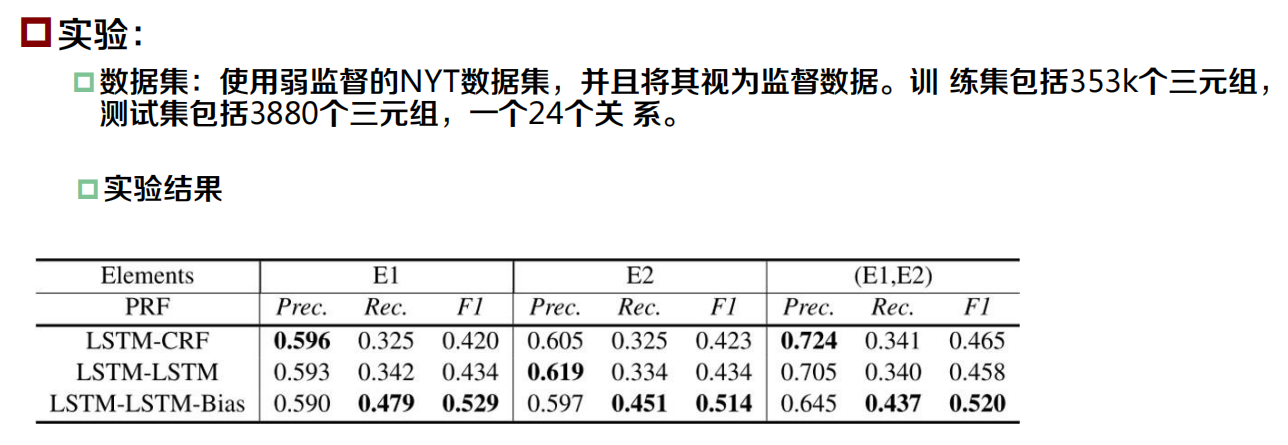
物體和關系聯合抽取
動機:
- 真實世界中很多情況下要物體和關系聯合抽取
- 傳統的方法大多數都假定給出了待抽取的兩個物體

傳統關系抽取方法
基于特征向量方法 vs. 基于核函式方法 vs.基于神經網路方法
傳統的人工標注語料+機器學習演算法模式無法滿足開放域 開放語料下的資訊抽取
- 語料構建成本過高
- 跨領域跨文本類別時抽取性能嚴重下降
- 需要抽取的資訊類別通常未預先指定
需要開放域關系抽取
- 關系型別更多
- 語料規模不受限
- 抽取物體型別也更豐富
開放域關系抽取特點
不限定關系類別
不限定目標文本
? Web Page
? Wikipedia
? Query Log
難點問題
? 如何獲取訓練語料
? 如何獲取物體關系類別
? 如何針對不同型別目標文本抽取關系
需要研究新的抽取方法
? 按需抽取—Bootstrapping,模板
? 開放抽取—Open IE
? 知識監督抽取—Distant Supervision
按需抽取:Bootstrapping
Bootstrapping:模板生成->實體抽取->迭代直至收斂
語意漂移問題:迭代會引入噪音實體和噪音模板
- 首都:Rome ? 城市模板 “* is a city of ”
Paris is a city of France.
Paris is a city of Romance.
COLING 14:引入負實體來限制語意漂移
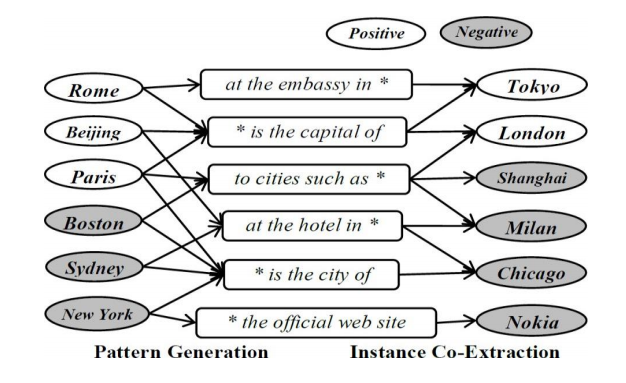

開放抽取
通過識別表達語意關系的短語來抽取物體之間的關系
- (華為,總部位于, 深圳),(華為,總部設定于,深圳),(華為, 將其總部建于,深圳)
同時使用句法和統計資料來過濾抽取出來的三元組
- 關系短語應當是一個以動詞為核心的短語
- 關系短語應當匹配多個不同物體對
優點:無需預先定義關系類別
缺點:語意沒有歸一化,同一關系有不同表示、

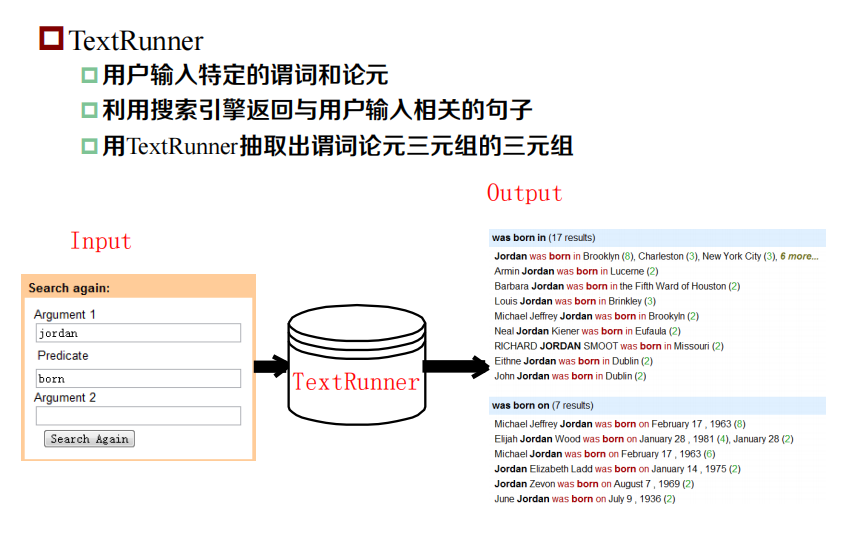
開放域關系抽取: Web Page
步驟:
? 離線的訓練集產生:利用簡單的啟發式規則,在賓州樹庫上產生訓練語料
? 離線的分類器訓練:提取一些淺層句法特征,訓練分類器,用來判斷一個元組是否構成關系
? 在線關系抽取:在網路語料上,找到候選句子,提取淺層句法特征,利用分類器,判斷抽取的關系對是否“可信”
? 在線的關系可信度評估:利用網路海量語料的冗余資訊,對可信的關系對,進行評估
出發點:
? 關系類別的產生:動詞作為關系類別
? 訓練語料的產生:通過句法關系引出語意關系
Machine Reading
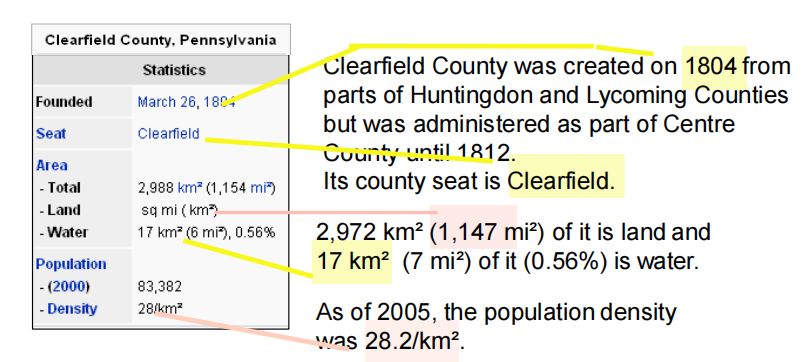
開放域關系抽取: Wikipedia
?任務:在Wikipedia文本中抽取關系(屬性)資訊
?難點
- 無法確定關系類別
- 無法獲取訓練語料
方法
- 在Infobox抽取關系資訊
- 在Wikipedia條目文本中進行回標,產生訓練語料

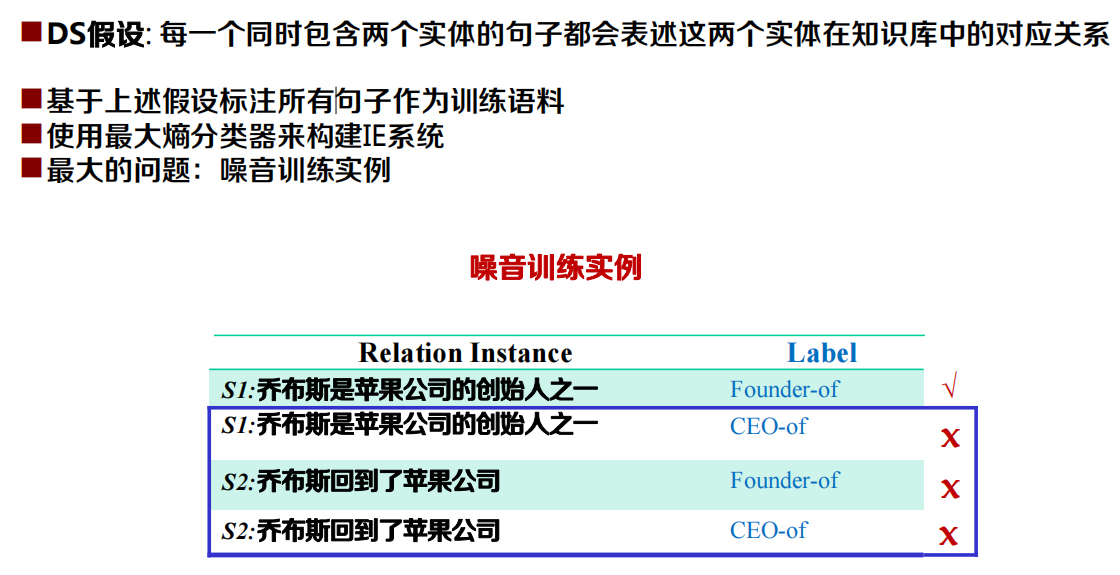
知識監督開放抽取:Distant Supervision
- 開放域資訊抽取的一個主要問題是缺乏標注語料
- Distant Supervision: 使用知識庫中的關系啟發式的標注訓練語料
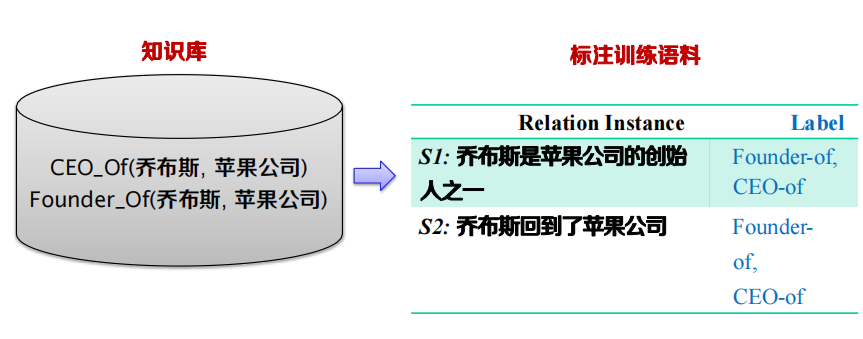
簡單遠距離監督方法

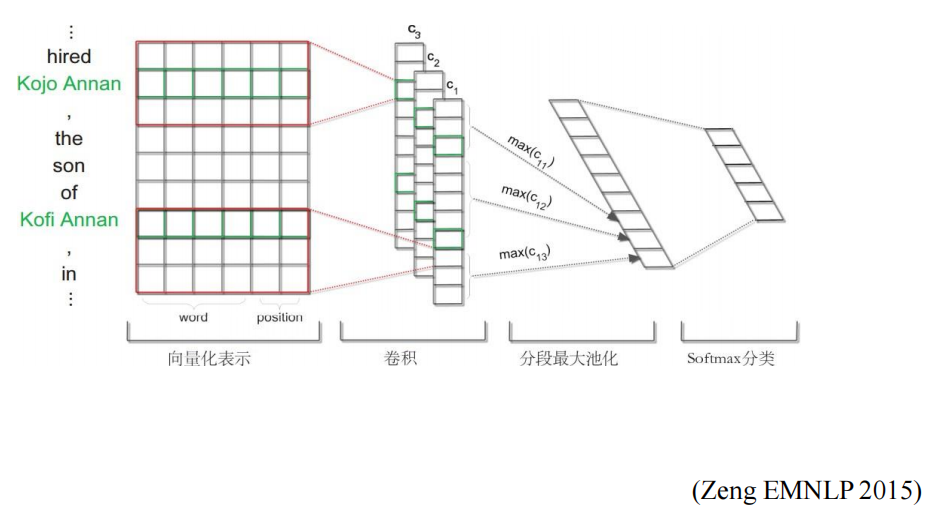
利用分段卷積網路自動學習特征
- 設計分段最大池化層,根據兩個物體把句子分成三段,在每段里利用最大池化技術,更好地保留句子的結構化資訊
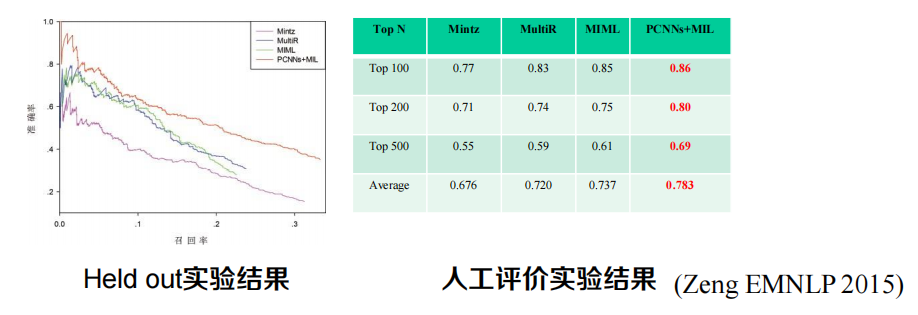
資料集:Riedel等開發
?設計分段最大池化層,保留句子中結構化資訊
?知識庫:Freebase
?文本:紐約時報(NYT)
?評價方法
?Held-out 評價:以Freebase 中存在關系的三元組作為標準
?人工評價:去掉已經在Freebase 中存在的物體對,人工標注top N結果
開放域關系抽取: 從NYT中抽取Freebase的關系類別
?實驗結果


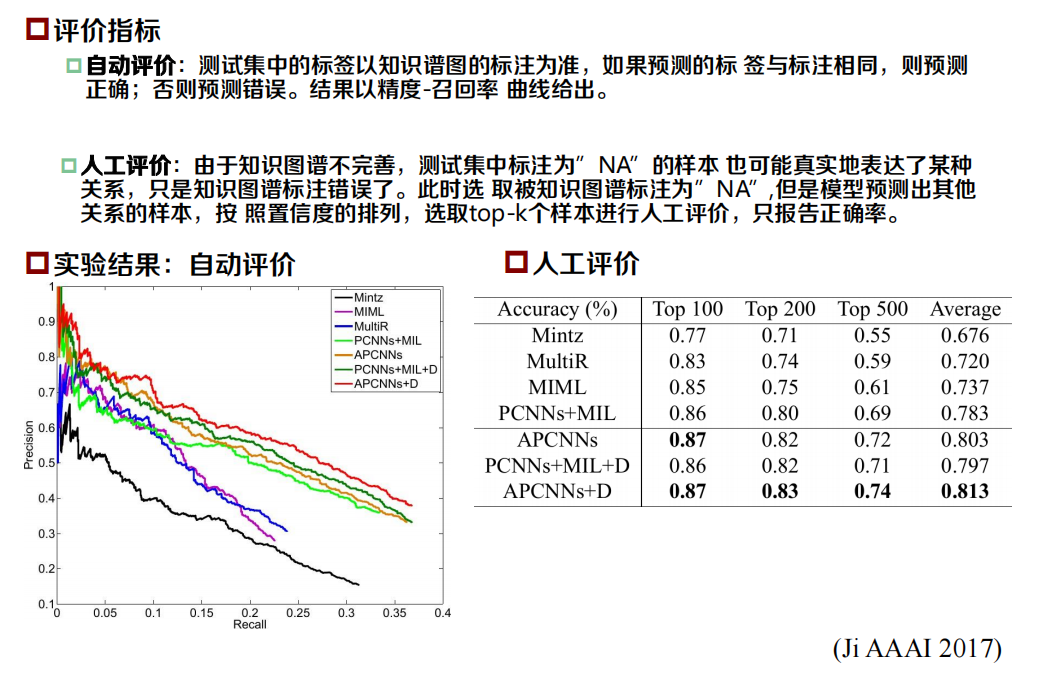
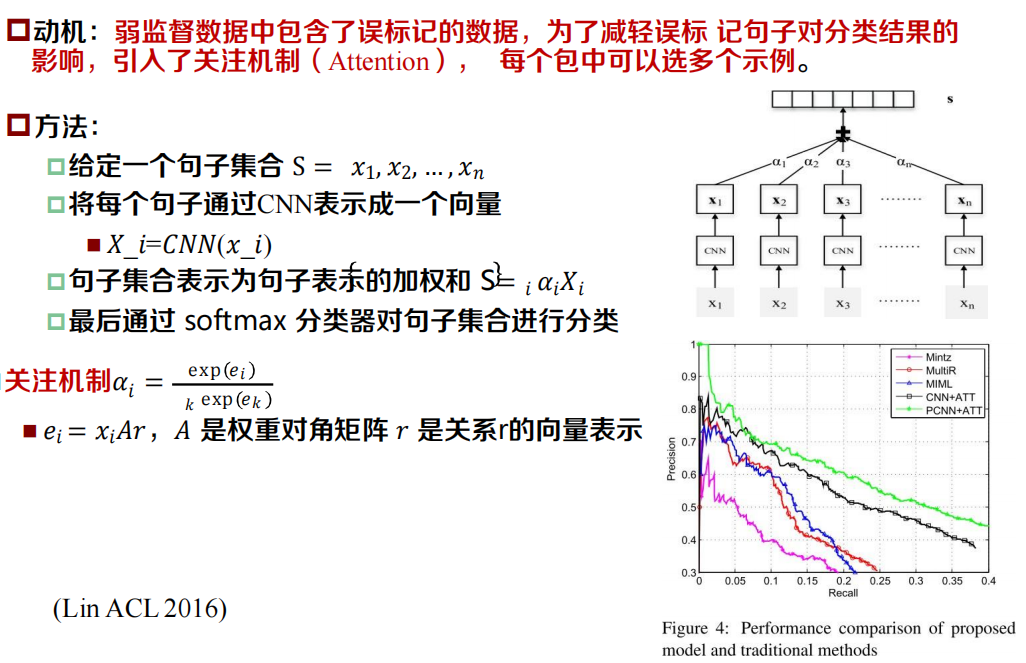
小結
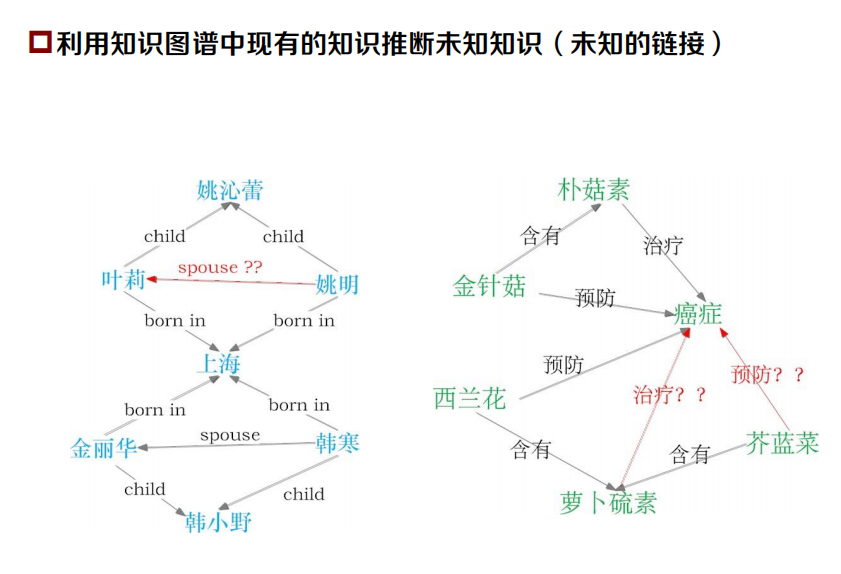
由識別到抽取
- 規范文本–>有噪音、有冗余的海量網路資料
限定類別–>開放類別
難點:關系類別缺乏體系結構
加油!
感謝!
努力!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/352098.html
標籤:AI
上一篇:Python機器學習之垃圾短信分類(用樸素貝葉斯演算法的伯努利模型和多項式模型分類垃圾短信資料集SMSSpamCollection.txt)