《Python深度學習》第一章筆記
- 1.1人工智能、機器學習、深度學習
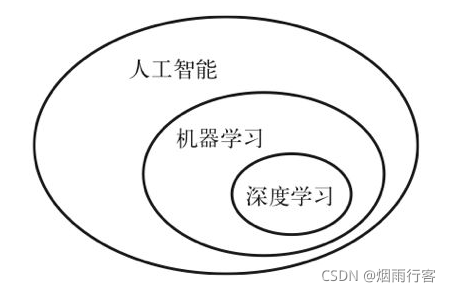
- 人工智能
- 機器學習
- 深度學習
- 深度學習的作業原理
- 1.2深度學習之前:機器學習簡史
- 概率建模
- 早期神經網路
- 核方法
- 決策樹、隨機森林與梯度提升機
- 回到神經網路
1.1人工智能、機器學習、深度學習
什么是人工智能、機器學習與深度學習?這三者之間有什么關系?
人工智能
人工智能誕生于20世紀50年代,人工智能的簡潔定義如下:努力將通常由人類完成的智力任務自動化,人工智能是一個綜合性的領域,不僅包括機器學習與深度學習,還包括更多不涉及學習的方法,
機器學習
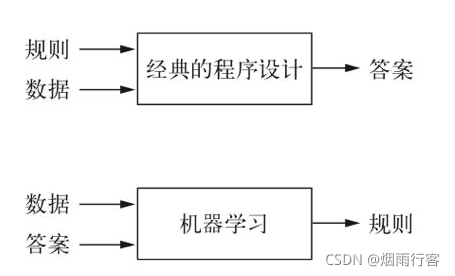
機器學習系統是訓練出來的,人們輸入的是資料和從這些資料中預期得到的答案,系統輸出的是規則,機器學習的技術定義:在預先定義好的可能性空間中,利用反饋信號的指引來尋找輸入資料的有用表示,
在符號人工智能中,人們輸入規則和需要根據這些規則進行處理的資料,系統輸出答案,這種并不屬于機器學習,
深度學習
為了給出深度學習的定義并搞清楚深度學習與其他機器學習方法的區別,我們首先需要知道機器學習在做什么,
我們需要以下三要素來進行機器學習,
- 輸入資料點,例如,你的任務是語音識別,那么這些資料點可能是記錄人們說話的聲音檔案,如果你的任務是為影像添加標簽,那么這些資料點可能是影像,
- 預期輸出的示例,對于語音識別任務來說,這些示例可能是人們根據聲音檔案整理生成的文本,對于影像標記任務來說,預期輸出可能是“狗”“貓”之類的標簽,
- 衡量演算法好壞的方法,這一衡量方法是為了計算演算法的當前輸出與預期輸出的差距,
機器學習和深度學習的核心問題在于有意義地變換資料,在于學習輸入資料的有用表示——這種表示可以讓資料更接近預期輸出,
現在你理解了學習的含義,下面我們來看一下深度學習的特殊之處,
深度學習是機器學習的一個分支領域:它是從資料中學習表示的一種新方法,強調從連續的層(layer)中進行學習,這些層對應于越來越有意義的表示,
“深度學習”中的“深度”是指一系列連續的表示層,資料模型中包含多少層,這被稱為模型的深度(depth),現代深度學習通常包含數十個甚至上百個連續的表示層,這些表示層全都是從訓練資料中自動學習的,
因此,深度學習的技術定義:學習資料表示的多級方法,即利用深層神經網路的機器學習來學習輸入資料的有用表示,
深度學習的作業原理
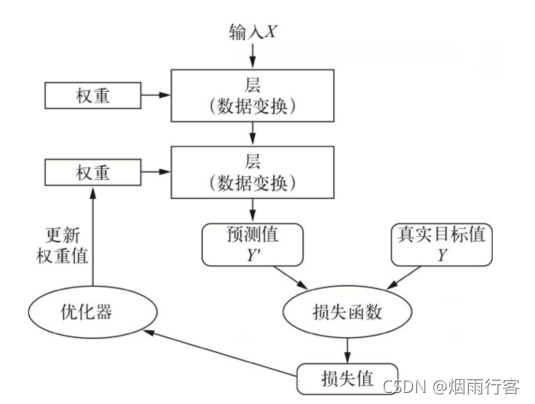
- 首先,深度神經網路通過一系列簡單的資料變換(層)來實作輸入到輸出的映射,神經網路中每層對輸入資料所做的具體操作保存在該層的權重中,每層實作的變換由其權重來引數化,但是一個深度神經網路可能包含數千萬個引數,找到所有引數的正確取值是一項非常艱巨的任務,
- 其次,想要控制一件事物,需要能夠觀察它,想要控制神經網路的輸出,需要能夠衡量該輸出與預期值之間的距離,這是神經網路損失函式的任務,
- 最后,深度學習中的核心演算法——反向傳播演算法,利用損失函式計算出的預測值與真實值之間的距離作為反饋信號實作對權重值的調節,
- 一開始對權重隨機賦值,但隨著網路處理的示例越來越多,權重值也在向正確的方向逐步微調,損失值也逐漸降低,這就是訓練回圈,將這種回圈重復足夠多次,得到的權重值可以使損失函式最小,
1.2深度學習之前:機器學習簡史
下面讓我們簡要回顧經典機器學習方法(具體演算法實作請讀者自行查閱資料進行學習),這樣我們可以將深度學習放入機器學習的大背景中,并更好地理解深度學習的起源以及它為什么如此重要,
概率建模
概率建模是統計學原理在資料分析中的應用,它是最早的機器學習形式之一,至今仍在廣泛使用,其中最有名的演算法之一是樸素貝葉斯演算法,
樸素貝葉斯是一類基于應用貝葉斯定理的機器學習分類器,它假設輸入資料的特征都是獨立的,樸素貝葉斯的思想基礎是這樣的:對于給出的待分類項,求解在此項出現的條件下各個類別出現的概率,哪個最大,就認為此待分類項屬于哪個類別,
另一個模型是logistic回歸,它也是一種分類演算法,而不是回歸演算法,logistic回歸常用于兩分類問題,
早期神經網路
人們早在 20 世紀 50 年代就對神經網路核心思想進行研究,但在很長一段時間內,一直沒有訓練大型神經網路的有效方法,這一點在 20 世紀 80 年代中期發生了變化,當時很多人都獨立地重新發現了反向傳播演算法——一種利用梯度下降優化來訓練一系列引數化運算鏈的方法,并開始將其應用于神經網路,
貝爾實驗室于 1989 年第一次成功實作了神經網路的實踐應用,當時 Yann LeCun 將卷積神經網路的早期思想與反向傳播演算法相結合,并將其應用于手寫數字分類問題,由此得到名為LeNet 的網路,在 20 世紀 90 年代被美國郵政署采用,用于自動讀取信封上的郵政編碼,
核方法
上述神經網路取得了第一次成功,并在 20 世紀 90 年代開始在研究人員中受到一定的重視,但一種新的機器學習方法在這時聲名鵲起,很快就使人們將神經網路拋諸腦后,這種方法就是核方法,核方法是一組分類演算法,其中最有名的就是支持向量機(SVM,support vector machine),
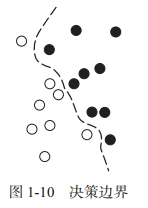
SVM 的目標是通過在屬于兩個不同類別的兩組資料點之間找到良好決策邊界來解決分類問題,決策邊界可以看作一條直線或一個平面,將訓練資料劃分為兩塊空間,分別對應于兩個類別,對于新資料點的分類,只需判斷它位于決策邊界的哪一側,
決策樹、隨機森林與梯度提升機
決策樹(decision tree)是類似于流程圖的結構,可以對輸入資料點進行分類或根據給定輸入來預測輸出值,
 隨機森林(random forest)演算法,是集成學習演算法的一種,它引入了一種健壯且實用的決策樹學習方法,即首先構建許多決策樹,然后將它們的輸出集成在一起,隨機森林適用于各種各樣的問題——對于任何淺層的機器學習任務來說,它幾乎總是第二好的演算法,
隨機森林(random forest)演算法,是集成學習演算法的一種,它引入了一種健壯且實用的決策樹學習方法,即首先構建許多決策樹,然后將它們的輸出集成在一起,隨機森林適用于各種各樣的問題——對于任何淺層的機器學習任務來說,它幾乎總是第二好的演算法,
與隨機森林類似, 梯度提升機(gradient boosting machine)也是將弱預測模型(通常是決策樹,但不限于決策樹)集成的機器學習技術,它使用了梯度提升方法,通過迭代地訓練新模型來專門解決之前模型的弱點,從而改進任何機器學習模型的效果,
回到神經網路
自2012年以來,深度卷積神經網路(DNN)已成為所有計算機視覺任務的首選演算法,與此同時,深度學習也在許多其他問題上得到應用,比如自然語言處理,它已經在大量應用中完全取代了SVM與決策樹,
卷積神經網路(CNN),這是深度學習演算法應用最成功的領域之一,卷積神經網路包括一維卷積神經網路,二維卷積神經網路以及三維卷積神經網路,一維卷積神經網路主要用于序列類的資料處理,二維卷積神經網路常應用于影像類文本的識別,三維卷積神經網路主要應用于醫學影像以及視頻類資料識別,
關于卷積神經網路的CNN的原理,詳情可學習以下鏈接:
https://www.cnblogs.com/charlotte77/p/7759802.html
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/352101.html
標籤:AI
上一篇:【知識圖譜】關系抽取
下一篇:【ICNP2020】A Multi-agent Reinforcement Learning Perspective on Distributed Traffic Engineering