StreamExecutionEnvironment是stream program執行的環境,其子類LocalStreamEnvironment會讓程式在當前JJVM中執行,而子類RemoteStreamEnvironment會讓程式在遠程集群中執行, ——Flink官方注釋
首先,我們來看一看一個典型的Flink中的wordcount程式是什么樣的,
public class WordCount {
public static void main(String[] args) throws Exception {
//定義socket的埠號
int port;
try{
ParameterTool parameterTool = ParameterTool.fromArgs(args);
port = parameterTool.getInt("port");
}catch (Exception e){
System.err.println("沒有指定port引數,使用默認值9000");
port = 9000;
}
//?獲取運行環境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//?連接socket獲取輸入的資料
DataStreamSource<String> text = env.socketTextStream("10.192.12.106", port, "\n");
//計算資料
DataStream<WordWithCount> windowCount = text.flatMap(new FlatMapFunction<String, WordWithCount>() {
public void flatMap(String value, Collector<WordWithCount> out) throws Exception {
String[] splits = value.split("\\s");
for (String word:splits) {
out.collect(new WordWithCount(word,1L));
}
}
})//打平操作,把每行的單詞轉為<word,count>型別的資料
.keyBy("word")//針對相同的word資料進行分組
.timeWindow(Time.seconds(2),Time.seconds(1))//指定計算資料的視窗大小和滑動視窗大小
.sum("count");
//把資料列印到控制臺
windowCount.print()
.setParallelism(1);//使用一個并行度
//?因為flink是懶加載的,所以必須呼叫execute方法,上面的代碼才會執行
env.execute("streaming word count");
}請注意看代碼中?標記部分,可見我們Flink程式的第一步就是獲得一個StreamExecutionEnviorment,然后通過SEE提供的方法添加source來獲得第一個DataStream,最后提供SEE提供的execution( )方法執行程式,在這里SEE有三個作用,
在Flink官方注釋中說道:“StreamExecutionEnviorment會提供方法來控制job的執行(比如設定并行度、容錯和檢查點方面的引數)以及與外界交換資料”,那么,SEE類具體是如何實作的呢,本文將從Flink原始碼出發,一步步學習SEE的組成,
從下面的代碼中,我們首先看看SEE有哪些屬性(英文已做翻譯)
/** The default name to use for a streaming job if no other name has been specified.
* 默認JOB名稱 */
public static final String DEFAULT_JOB_NAME = "Flink Streaming Job";
/** The time characteristic that is used if none other is set.
* 默認使用的時間語意:處理時間*/
private static final TimeCharacteristic DEFAULT_TIME_CHARACTERISTIC = TimeCharacteristic.ProcessingTime;
/** The default buffer timeout (max delay of records in the network stack).
* 默認快取延時(資料在網路堆疊中的最大延時) */
private static final long DEFAULT_NETWORK_BUFFER_TIMEOUT = 100L;
/**
* The environment of the context (local by default, cluster if invoked through command line).
* context的enviorment (默認是local,如果是命令列提交則是cluster模式)
*/
private static StreamExecutionEnvironmentFactory contextEnvironmentFactory;
/** The default parallelism used when creating a local environment.
* 創建local enviornment的默認并行度,為當前虛擬機可以獲得的最大可用cpu數量 */
private static int defaultLocalParallelism = Runtime.getRuntime().availableProcessors();
/** ?The execution configuration for this environment. 執行config*/
private final ExecutionConfig config = new ExecutionConfig();
/** ?Settings that control the checkpointing behavior. */
private final CheckpointConfig checkpointCfg = new CheckpointConfig();
/** job中transformation的鏈表集合 */
protected final List<StreamTransformation<?>> transformations = new ArrayList<>();
private long bufferTimeout = DEFAULT_NETWORK_BUFFER_TIMEOUT;
/** 是否可以鏈接chain */
protected boolean isChainingEnabled = true;
/** The state backend used for storing k/v state and state snapshots.
* 存盤kv狀態和狀態快照用的狀態后端 */
private StateBackend defaultStateBackend;
/** The time characteristic used by the data streams. datastream使用的時間語意 */
private TimeCharacteristic timeCharacteristic = DEFAULT_TIME_CHARACTERISTIC;
/** 下面的cacheFile是給taskmanager用的分布式快取 */
protected final List<Tuple2<String, DistributedCache.DistributedCacheEntry>> cacheFile = new ArrayList<>();我們可以看到,除了一些常規的屬性,還有兩個重要屬性:ExecutionConfig和CheckpointConfig (已由?標記出來)
SEE的屬性組成大概可以歸納成下圖

我們再來分別看看這兩個屬性里可以定義哪些引數,首先是ExecutionConfig
private static final long serialVersionUID = 1L;
/**
* The constant to use for the parallelism, if the system should use the number
* of currently available slots. 如果系統需要用當前可以slot數,使用這個常量用于設定
*/
@Deprecated
public static final int PARALLELISM_AUTO_MAX = Integer.MAX_VALUE;
/**
* The flag value indicating use of the default parallelism. This value can
* be used to reset the parallelism back to the default state.
* 指明是否使用默認并行度的flag值,這個值可以用于重設并行度回到默認狀態
*/
public static final int PARALLELISM_DEFAULT = -1;
/**
* The flag value indicating an unknown or unset parallelism. This value is
* not a valid parallelism and indicates that the parallelism should remain
* unchanged.
*/
public static final int PARALLELISM_UNKNOWN = -2;
private static final long DEFAULT_RESTART_DELAY = 10000L;
// --------------------------------------------------------------------------------------------
/** Defines how data exchange happens - batch or pipelined
* 指明資料交換是如何發生的-批處理或流處理*/
private ExecutionMode executionMode = ExecutionMode.PIPELINED;
/** 閉包清理器等級:默認情況下遞回清理所有
*/
private ClosureCleanerLevel closureCleanerLevel = ClosureCleanerLevel.RECURSIVE;
private int parallelism = PARALLELISM_DEFAULT;
/**
* The program wide maximum parallelism used for operators which haven't specified a maximum
* parallelism. The maximum parallelism specifies the upper limit for dynamic scaling and the
* number of key groups used for partitioned state.
*/
private int maxParallelism = -1;
/**
* @deprecated Should no longer be used because it is subsumed by RestartStrategyConfiguration
*/
@Deprecated
private int numberOfExecutionRetries = -1;
private boolean forceKryo = false;
/** Flag to indicate whether generic types (through Kryo) are supported */
private boolean disableGenericTypes = false;
private boolean objectReuse = false;
private boolean autoTypeRegistrationEnabled = true;
private boolean forceAvro = false;
private CodeAnalysisMode codeAnalysisMode = CodeAnalysisMode.DISABLE;
/** If set to true, progress updates are printed to System.out during execution 如果為true,程式動態會被列印到System.out*/
private boolean printProgressDuringExecution = true;
private long autoWatermarkInterval = 0;
/**
* Interval in milliseconds for sending latency tracking marks from the sources to the sinks.
* 發送從source到sink的延遲檢測mark的間隔
*/
private long latencyTrackingInterval = MetricOptions.LATENCY_INTERVAL.defaultValue();
private boolean isLatencyTrackingConfigured = false;
/**
* @deprecated Should no longer be used because it is subsumed by RestartStrategyConfiguration
*/
@Deprecated
private long executionRetryDelay = DEFAULT_RESTART_DELAY;
private RestartStrategies.RestartStrategyConfiguration restartStrategyConfiguration =
new RestartStrategies.FallbackRestartStrategyConfiguration();
private long taskCancellationIntervalMillis = -1;
/**
* Timeout after which an ongoing task cancellation will lead to a fatal
* TaskManager error, usually killing the JVM.
*/
private long taskCancellationTimeoutMillis = -1;
/** This flag defines if we use compression for the state snapshot data or not. Default: false
* 是否對狀態快照壓縮*/
private boolean useSnapshotCompression = false;
/** Determines if a task fails or not if there is an error in writing its checkpoint data. Default: true
* 決定 當做checkpoint時發生了error時task任務是否失敗*/
private boolean failTaskOnCheckpointError = true;
/** The default input dependency constraint to schedule tasks. */
private InputDependencyConstraint defaultInputDependencyConstraint = InputDependencyConstraint.ANY;
// ------------------------------- User code values --------------------------------------------
private GlobalJobParameters globalJobParameters;
// Serializers and types registered with Kryo and the PojoSerializer
// we store them in linked maps/sets to ensure they are registered in order in all kryo instances.
private LinkedHashMap<Class<?>, SerializableSerializer<?>> registeredTypesWithKryoSerializers = new LinkedHashMap<>();
private LinkedHashMap<Class<?>, Class<? extends Serializer<?>>> registeredTypesWithKryoSerializerClasses = new LinkedHashMap<>();
private LinkedHashMap<Class<?>, SerializableSerializer<?>> defaultKryoSerializers = new LinkedHashMap<>();
private LinkedHashMap<Class<?>, Class<? extends Serializer<?>>> defaultKryoSerializerClasses = new LinkedHashMap<>();
private LinkedHashSet<Class<?>> registeredKryoTypes = new LinkedHashSet<>();
private LinkedHashSet<Class<?>> registeredPojoTypes = new LinkedHashSet<>();以上可以看出,ExecutionConfig可以設定的內容包括 程式的默認并行度、執行失敗時的重試次數、重啟嘗試之間的時間間隔、程式的執行模式—流或批、 啟用或禁止“closure cleaner閉包清理器”、 是否允許register 型別和序列化器來提供處理基本型別和POJO型別的效率 等內容,
以下我們再看看checkpointConfig里有什么屬性
private static final long serialVersionUID = -750378776078908147L;
/** The default checkpoint mode: exactly once. 默認checkpoint模式:精準一次 */
public static final CheckpointingMode DEFAULT_MODE = CheckpointingMode.EXACTLY_ONCE;
/** The default timeout of a checkpoint attempt: 10 minutes. 默認一次checkpoint的最長時間 十分鐘*/
public static final long DEFAULT_TIMEOUT = 10 * 60 * 1000;
/** The default minimum pause to be made between checkpoints: none. 兩次checkpint之間的最小間隔*/
public static final long DEFAULT_MIN_PAUSE_BETWEEN_CHECKPOINTS = 0;
/** The default limit of concurrently happening checkpoints: one. 同時執行的最大checkpoint個數 1次*/
public static final int DEFAULT_MAX_CONCURRENT_CHECKPOINTS = 1;
// ------------------------------------------------------------------------
/** Checkpointing mode (exactly-once vs. at-least-once). checkpoint模式*/
private CheckpointingMode checkpointingMode = DEFAULT_MODE;
/** Periodic checkpoint triggering interval. 周期性的checkpoint觸發間隔:默認關閉*/
private long checkpointInterval = -1; // disabled
/** Maximum time checkpoint may take before being discarded. */
private long checkpointTimeout = DEFAULT_TIMEOUT;
/** Minimal pause between checkpointing attempts. checkpoint嘗試的最小間隔*/
private long minPauseBetweenCheckpoints = DEFAULT_MIN_PAUSE_BETWEEN_CHECKPOINTS;
/** Maximum number of checkpoint attempts in progress at the same time. 同時進行的checkpoint嘗試的最大個數*/
private int maxConcurrentCheckpoints = DEFAULT_MAX_CONCURRENT_CHECKPOINTS;
/** Flag to force checkpointing in iterative jobs. */
private boolean forceCheckpointing;
/** Cleanup behaviour for persistent checkpoints. */
private ExternalizedCheckpointCleanup externalizedCheckpointCleanup;
/** Determines if a tasks are failed or not if there is an error in their checkpointing. Default: true */
private boolean failOnCheckpointingErrors = true;可見CheckpointConfig中定義的都是checkpoint相關的引數和策略,
由以上三個類的屬性可見StreamExecutionEnviorment+ExecutionConfig+CheckpointConfig 定義了Flink最頂層的環境配置和策略選擇,
我們再回過頭來看看,SEE中定義了哪些重要方法?(各種get和set方法省略,注釋大部分都翻譯了,重點看?標注的地方)
首先我們看看SEE定義了哪些獲得source的方法
/**
* Creates a new data stream that contains a sequence of numbers. This is a parallel source,
* if you manually set the parallelism to {@code 1}
* (using {@link org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator#setParallelism(int)})
* the generated sequence of elements is in order.
* ?創建一個包含了一系列數字的sequence,如果你設定了大于1的并行度,那么這將是一個并行的source,創建出來的elements是有序的
* @param from
* The number to start at (inclusive) 第一個數字(包含在內)
* @param to
* The number to stop at (inclusive) 最后一個數字(包含在內)
* @return A data stream, containing all number in the [from, to] interval
*/
public DataStreamSource<Long> ?generateSequence(long from, long to) {
if (from > to) {
throw new IllegalArgumentException("Start of sequence must not be greater than the end");
}
return addSource(new StatefulSequenceSource(from, to), "Sequence Source");
//?最后其實是使用了addSource方法
}/**
* Creates a new data stream that contains the given elements. The elements must all be of the
* same type, for example, all of the {@link String} or {@link Integer}.
* ?創建一個包含指定element的datastream,所有的element必須是相同的型別
*
* <p>The framework will try and determine the exact type from the elements. In case of generic
* elements, it may be necessary to manually supply the type information via
* {@link #fromCollection(java.util.Collection, org.apache.flink.api.common.typeinfo.TypeInformation)}.
* 框架會嘗試獲取element的明確type,可能需要手動設定型別資訊
*
* <p>Note that this operation will result in a non-parallel data stream source, i.e. a data
* stream source with a degree of parallelism one.
* 這個方法產生的datastream的并行度為1
*
* @param data
* The array of elements to create the data stream from.
* @param <OUT>
* The type of the returned data stream
* @return The data stream representing the given array of elements
*/
@SafeVarargs
public final <OUT> DataStreamSource<OUT> ?fromElements(OUT... data) {
if (data.length == 0) {
throw new IllegalArgumentException("fromElements needs at least one element as argument");
}
TypeInformation<OUT> typeInfo;
try {
typeInfo = TypeExtractor.getForObject(data[0]);
}
catch (Exception e) {
throw new RuntimeException("Could not create TypeInformation for type " + data[0].getClass().getName()
+ "; please specify the TypeInformation manually via "
+ "StreamExecutionEnvironment#fromElements(Collection, TypeInformation)", e);
}
//?最后實際使用了fromCollection方法
return fromCollection(Arrays.asList(data), typeInfo);
}/**
* Creates a data stream from the given non-empty collection.
* ?從給出的非空collection中創建datastream,datastream的type是collection中element的type
* <p>Note that this operation will result in a non-parallel data stream source,
* i.e., a data stream source with parallelism one. 產生的datastream的并行度為1
*
* @param data
* The collection of elements to create the data stream from
* @param typeInfo
* The TypeInformation for the produced data stream
* @param <OUT>
* The type of the returned data stream
* @return The data stream representing the given collection
*/
public <OUT> DataStreamSource<OUT> ?fromCollection(Collection<OUT> data, TypeInformation<OUT> typeInfo) {
Preconditions.checkNotNull(data, "Collection must not be null");
// must not have null elements and mixed elements
FromElementsFunction.checkCollection(data, typeInfo.getTypeClass());
SourceFunction<OUT> function;
try {
function = new FromElementsFunction<>(typeInfo.createSerializer(getConfig()), data);
}
catch (IOException e) {
throw new RuntimeException(e.getMessage(), e);
}
//?實際使用了addSource方法
return addSource(function, "Collection Source", typeInfo).setParallelism(1);
}/**
* Creates a new data stream that contains elements in the iterator. The iterator is splittable,
* allowing the framework to create a parallel data stream source that returns the elements in
* the iterator.
* ?從iterator中創建包含其中elements的datastream
* iterator是可分割的,允許框架創建并行的回傳iterator中資料的datastream
*
* <p>Because the iterator will remain unmodified until the actual execution happens, the type
* of data returned by the iterator must be given explicitly in the form of the type
* information. This method is useful for cases where the type is generic. In that case, the
* type class (as given in
* {@link #fromParallelCollection(org.apache.flink.util.SplittableIterator, Class)} does not
* supply all type information.
* ?因為iterator直到真正的execution發生之前都會保持不變,所以iterator的回傳型別必須被明確給出(第二個引數)
* 本方法對型別為泛型的情況非常有用
*
* @param iterator
* The iterator that produces the elements of the data stream
* @param typeInfo
* The TypeInformation for the produced data stream.
* @param <OUT>
* The type of the returned data stream
* @return A data stream representing the elements in the iterator
*/
private <OUT> DataStreamSource<OUT> ?fromParallelCollection(SplittableIterator<OUT> iterator, TypeInformation<OUT>
typeInfo, String operatorName) {
//?實際上使用的是addsource
return addSource(new FromSplittableIteratorFunction<>(iterator), operatorName, typeInfo);
}/**
* Creates a new data stream that contains the strings received infinitely from a socket. Received strings are
* decoded by the system's default character set. On the termination of the socket server connection retries can be
* initiated.
* ?創建一個datastream從socket中接收無窮無盡的資料流,用系統默認的charset決議接收的strings
* 只有當socket server連接中斷,才可以啟動重新連接
*
* <p>Let us note that the socket itself does not report on abort and as a consequence retries are only initiated when
* the socket was gracefully terminated.
* 明確一點:socket本身不會報告abort,因此,只有當socket本身被優雅地中止之后才會啟動重試
*
* @param hostname
* The host name which a server socket binds
* @param port
* The port number which a server socket binds. A port number of 0 means that the port number is automatically
* allocated.
* @param delimiter ?分割接收到的string的分隔符
* A string which splits received strings into records
* @param maxRetry 當program等待socket連接時的最大重試間隔(秒級),0代表立即結束,負數代表永遠嘗試重連
* The maximal retry interval in seconds while the program waits for a socket that is temporarily down.
* Reconnection is initiated every second. A number of 0 means that the reader is immediately terminated,
* while a negative value ensures retrying forever.
* @return A data stream containing the strings received from the socket
*/
@PublicEvolving
public DataStreamSource<String> ?socketTextStream(String hostname, int port, String delimiter, long maxRetry) {
//?最后使用的是addSource
return addSource(new SocketTextStreamFunction(hostname, port, delimiter, maxRetry),
"Socket Stream");
}/**
* Reads the given file line-by-line and creates a data stream that contains a string with the
* contents of each such line. The {@link java.nio.charset.Charset} with the given name will be
* used to read the files.
* ?一行行地讀取給定檔案,創建包含這每一行string的datastream,在charsetName中設定讀取格式
*
* <p><b>NOTES ON CHECKPOINTING: 做checkpoint時注意</b> The source monitors the path, creates the
* {@link org.apache.flink.core.fs.FileInputSplit FileInputSplits} to be processed,
* forwards them to the downstream {@link ContinuousFileReaderOperator readers} to read the actual data,
* and exits, without waiting for the readers to finish reading. This implies that no more checkpoint
* barriers are going to be forwarded after the source exits, thus having no checkpoints after that point.
* ?source會監控檔案路徑,創建FileInputSplits,將其傳輸到ContinuousFileReaderOperator readers來讀取真實資料,然后就可以exit了
* 無需等到readers完全讀完資料,exit之后就不會產生barrier,即不會做checkpoint了,
*
* @param filePath
* The path of the file, as a URI (e.g., "file:///some/local/file" or "hdfs://host:port/file/path")
* @param charsetName
* The name of the character set used to read the file
* @return The data stream that represents the data read from the given file as text lines
*/
public DataStreamSource<String> ?readTextFile(String filePath, String charsetName) {
Preconditions.checkArgument(!StringUtils.isNullOrWhitespaceOnly(filePath), "The file path must not be null or blank.");
TextInputFormat format = new TextInputFormat(new Path(filePath));
format.setFilesFilter(FilePathFilter.createDefaultFilter());
TypeInformation<String> typeInfo = BasicTypeInfo.STRING_TYPE_INFO;
format.setCharsetName(charsetName);
//?最終執行的是readFile方法
return readFile(format, filePath, FileProcessingMode.PROCESS_ONCE, -1, typeInfo);
}/**
* Reads the contents of the user-specified {@code filePath} based on the given {@link FileInputFormat}.
* Depending on the provided {@link FileProcessingMode}, the source may periodically monitor (every {@code interval} ms)
* the path for new data ({@link FileProcessingMode#PROCESS_CONTINUOUSLY}), or process once the data currently in the
* path and exit ({@link FileProcessingMode#PROCESS_ONCE}). In addition, if the path contains files not to be processed,
* the user can specify a custom {@link FilePathFilter}. As a default implementation you can use
* {@link FilePathFilter#createDefaultFilter()}.
* 基于給定的FileInputFormat讀取filePath中的內容
* ???根據FileProcessingMode,source有兩種處理策略:
* ??一、PROCESS_CONTINUOUSLY:周期性地在path中掃描新資料
* ??二、PROCESS_ONCE:處理當前contents中的檔案然后退出(只處理一次)
*
* @param inputFormat
* The input format used to create the data stream 用于創建datastream的inputFormat
* @param filePath
* The path of the file, as a URI (e.g., "file:///some/local/file" or "hdfs://host:port/file/path")
* @param watchType 即FileProcessingMode,有PROCESS_CONTINUOUSLY和PROCESS_ONCE兩種
* The mode in which the source should operate, i.e. monitor path and react to new data, or process once and exit
* @param typeInformation
* Information on the type of the elements in the output stream
* @param interval 當FileProcessingMode為有PROCESS_CONTINUOUSLY和PROCESS_ONCE時的掃描檔案間隔
* In the case of periodic path monitoring, this specifies the interval (in millis) between consecutive path scans
* @param <OUT> 回傳的datastream的資料型別
* The type of the returned data stream
* @return The data stream that represents the data read from the given file
*/
@PublicEvolving
public <OUT> DataStreamSource<OUT> ?readFile(FileInputFormat<OUT> inputFormat,
String filePath,
FileProcessingMode watchType,
long interval,
TypeInformation<OUT> typeInformation) {
Preconditions.checkNotNull(inputFormat, "InputFormat must not be null.");
Preconditions.checkArgument(!StringUtils.isNullOrWhitespaceOnly(filePath), "The file path must not be null or blank.");
inputFormat.setFilePath(filePath);
//?最后實際上使用的是createFileInput()方法
return createFileInput(inputFormat, typeInformation, "Custom File Source", watchType, interval);
}根據以上添加source的方法的呼叫關系,我們可以得到下面這張圖
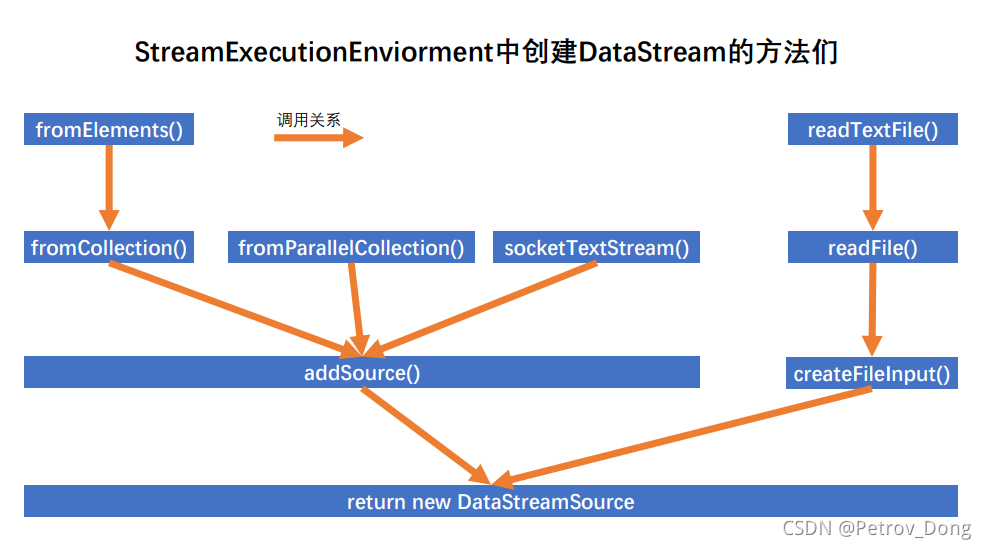
可以看到,最終是通過addSource和createFileInput兩個方法創建了新的DataStream,那么我們再來看看這兩個方法是怎么實作的吧
/**
* Ads a data source with a custom type information thus opening a
* {@link DataStream}. Only in very special cases does the user need to
* support type information. Otherwise use
* {@link #addSource(org.apache.flink.streaming.api.functions.source.SourceFunction)}
* ?使用自定義type創建一個data source以及對應的datastream,如果typeInfo為null,則從SourceFunction中提取type資訊?
*
* @param function
* the user defined function
* @param sourceName
* Name of the data source
* @param <OUT>
* type of the returned stream
* @param typeInfo
* the user defined type information for the stream
* @return the data stream constructed
*/
@SuppressWarnings("unchecked")
public <OUT> DataStreamSource<OUT> ?addSource(SourceFunction<OUT> function, String sourceName, TypeInformation<OUT> typeInfo) {
//?注意:typeInfo是可以為null的,可以從Sourcefunction提取type或者從SourceFunction創建type
if (typeInfo == null) {
if (function instanceof ResultTypeQueryable) {
typeInfo = ((ResultTypeQueryable<OUT>) function).getProducedType();
} else {
try {
typeInfo = TypeExtractor.createTypeInfo(
SourceFunction.class,
function.getClass(), 0, null, null);
} catch (final InvalidTypesException e) {
typeInfo = (TypeInformation<OUT>) new MissingTypeInfo(sourceName, e);
}
}
}
boolean isParallel = function instanceof ParallelSourceFunction;
clean(function);
StreamSource<OUT, ?> sourceOperator;
//?創建SourceOperator
if (function instanceof StoppableFunction) {
sourceOperator = new StoppableStreamSource<>(cast2StoppableSourceFunction(function));
} else {
sourceOperator = new StreamSource<>(function);
}
//?創建DataStream并回傳(注:DataStreamSource是DataStream的子類)
return new DataStreamSource<>(this, typeInfo, sourceOperator, isParallel, sourceName);
}private <OUT> DataStreamSource<OUT> ?createFileInput(FileInputFormat<OUT> inputFormat,
TypeInformation<OUT> typeInfo,
String sourceName,
FileProcessingMode monitoringMode,
long interval) {
//?檢查引數非空
Preconditions.checkNotNull(inputFormat, "Unspecified file input format.");
Preconditions.checkNotNull(typeInfo, "Unspecified output type information.");
Preconditions.checkNotNull(sourceName, "Unspecified name for the source.");
Preconditions.checkNotNull(monitoringMode, "Unspecified monitoring mode.");
//?如果FileProcessingMode是PROCESS_CONTINUOUSLY(只進行一次全量檔案匯入)且 掃描間隔小于規定的最小interval則報錯
//?Preconditions.checkArgument()會檢查第一個引數是否為true,如果不是true則報錯
Preconditions.checkArgument(monitoringMode.equals(FileProcessingMode.PROCESS_ONCE) ||
interval >= ContinuousFileMonitoringFunction.MIN_MONITORING_INTERVAL,
"The path monitoring interval cannot be less than " +
ContinuousFileMonitoringFunction.MIN_MONITORING_INTERVAL + " ms.");
//?封裝引數
ContinuousFileMonitoringFunction<OUT> monitoringFunction =
new ContinuousFileMonitoringFunction<>(inputFormat, monitoringMode, getParallelism(), interval);
ContinuousFileReaderOperator<OUT> reader =
new ContinuousFileReaderOperator<>(inputFormat);
SingleOutputStreamOperator<OUT> source = addSource(monitoringFunction, sourceName)
.transform("Split Reader: " + sourceName, typeInfo, reader);
//?創建和回傳DataStream
return new DataStreamSource<>(source);
}以上,我們介紹完了SEE中創建DataStream的方法,至于最后DataStream的具體實作請見下一篇文章
最后我們再來看看SEE的execute()方法,因為SEE抽象類中定義的execute()方法大多會被具體的子類override,所以我們不看SEE中的該方法,直接看子類的實作,以下我們以SEE的一個子類 LocalStreamEnvironment 來探究execute中做了什么,
/**
* Triggers the program execution. The environment will execute all parts of
* the program that have resulted in a "sink" operation. Sink operations are
* for example printing results or forwarding them to a message queue.
* ?觸發程式的真正執行,enviorment會執行所有的部分(以sink結尾)
* 舉例:sink算子會將結果列印或輸出到訊息佇列中
*
* <p>The program execution will be logged and displayed with the provided name
* ?程式的執行會以jobName為名記載入日志和展示
*
* Executes the JobGraph of the on a mini cluster of CLusterUtil with a user
* specified name. ?在一個mini cluster中執行JobGraph
*
* @param jobName
* name of the job
* @return The result of the job execution, containing elapsed time and accumulators.
*/
@Override
public JobExecutionResult execute(String jobName) throws Exception {
// ?將流轉化為JobGraph
StreamGraph streamGraph = getStreamGraph();
streamGraph.setJobName(jobName);
JobGraph jobGraph = streamGraph.getJobGraph();
jobGraph.setAllowQueuedScheduling(true);
//?封裝配置資訊
Configuration configuration = new Configuration();
configuration.addAll(jobGraph.getJobConfiguration());
configuration.setString(TaskManagerOptions.MANAGED_MEMORY_SIZE, "0");
// ?加載和封裝user定義的設定引數
configuration.addAll(this.configuration);
if (!configuration.contains(RestOptions.BIND_PORT)) {
configuration.setString(RestOptions.BIND_PORT, "0");
}
//?設定每個task manager中的slot數量
int numSlotsPerTaskManager = configuration.getInteger(TaskManagerOptions.NUM_TASK_SLOTS, jobGraph.getMaximumParallelism());
//?配置MiniCluster的引數
MiniClusterConfiguration cfg = new MiniClusterConfiguration.Builder()
.setConfiguration(configuration)
.setNumSlotsPerTaskManager(numSlotsPerTaskManager)
.build();
if (LOG.isInfoEnabled()) {
LOG.info("Running job on local embedded Flink mini cluster");
}
//?創建miniCluster
MiniCluster miniCluster = new MiniCluster(cfg);
//?啟動miniCluster,回傳jobGraph的執行結果
try {
miniCluster.start();
configuration.setInteger(RestOptions.PORT, miniCluster.getRestAddress().get().getPort());
?return miniCluster.executeJobBlocking(jobGraph);
}
finally {
transformations.clear();
miniCluster.close();
}
}由上面的原始碼可見,execute中執行的內容大致就是創建JobGraph、封裝引數資訊、創建cluster、把JobGraph提交到cluster等待回傳執行結果,當然最后別忘了清理記憶體和關閉集群,也就是說在execute之前,都是客戶端在進行flink程式的封裝,只有通過execute()提交到cluster才是程式真正的執行,這也是flink程式懶加載的真相,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/352166.html
標籤:其他
上一篇:大資料熱點圖制作(微重點)
下一篇:Hadoop/Spark大資料 Cloudera CCA Spark and Hadoop certificate CCA175認證