音頻降噪模型匯總
- 前言
- 一、模型全景
- 二、模型簡介
- Conv-TasNet
- DC-U-Net
- DPRNN
- PHASEN
- Demucs
- SuDoRM-RF
- DC-CRN
- DTLN
- Sepformer
- SDD-Net
- DPCRN
前言
從事語音降噪增強演算法開發多年了,上學期間和入行的前段都是做傳統信號處理演算法,19年以后基于深度學習的語音降噪模型憑借其優秀的處理效果,一時風頭無兩,似乎每個人都開始走上了模型降噪的路子,
特別是從2020年微軟開始舉辦的Deep Noise Suppression Challenge – INTERSPEECH 2020(DNS)開始,各個高校、科研院所和相關企業都參與進來施展武藝,后續又舉辦了Deep Noise Suppression Challenge – ICASSP 2021和Deep Noise Suppression Challenge – INTERSPEECH 2021
比賽中多數只關注實時/非實時性,賽道約束的比較少,對模型的引數量和計算量要求比較開放,所以基本上參賽的模型都把自己武裝得很“強壯”,把已知的有用的技巧都融合到自己的模型中,更有一些模型基本是模塊的排列組合,所以本人非常希望主辦方能夠開辟一條小模型賽道,可以迅速應用于現實,提升通話品質,
實際作業中,想要模型落地,考慮的可不止這些,目前端側對演算法開銷要求比較苛刻,PC還好一些,像手機、平板這些設備的演算法落地需要更加嚴格的模型選型和剪枝、量化,
模型選型,需要從模型的效果、引數量、計算量、占用記憶體大小、時延等方面著手開始考慮拆解問題,當然了,如果小模型就可以滿足降噪的效果需求,那恭喜你,可以跳過下面的步驟,去訓練模型、馬上就可以工程化落地了,如果小模型不能work,那就需要根據落地設備的存盤空間和開銷限制,尋找若干個效果遠超降噪效果需求的大模型,然后通過壓縮手段(剪枝、量化等)將模型的引數量和計算量降下來,程序中可能出現效果下降的現象,這就是一個經驗性嘗試的打磨程序了,
本文將近些年的經典網路和最近提出的新網路的關鍵引數、簡介、開源代碼都整理在這里,希望對語音降噪演算法的學習和應用程序有所幫助,如果不準確的地方,請大家批評指正,
干貨分享:歡迎收藏點贊
一、模型全景
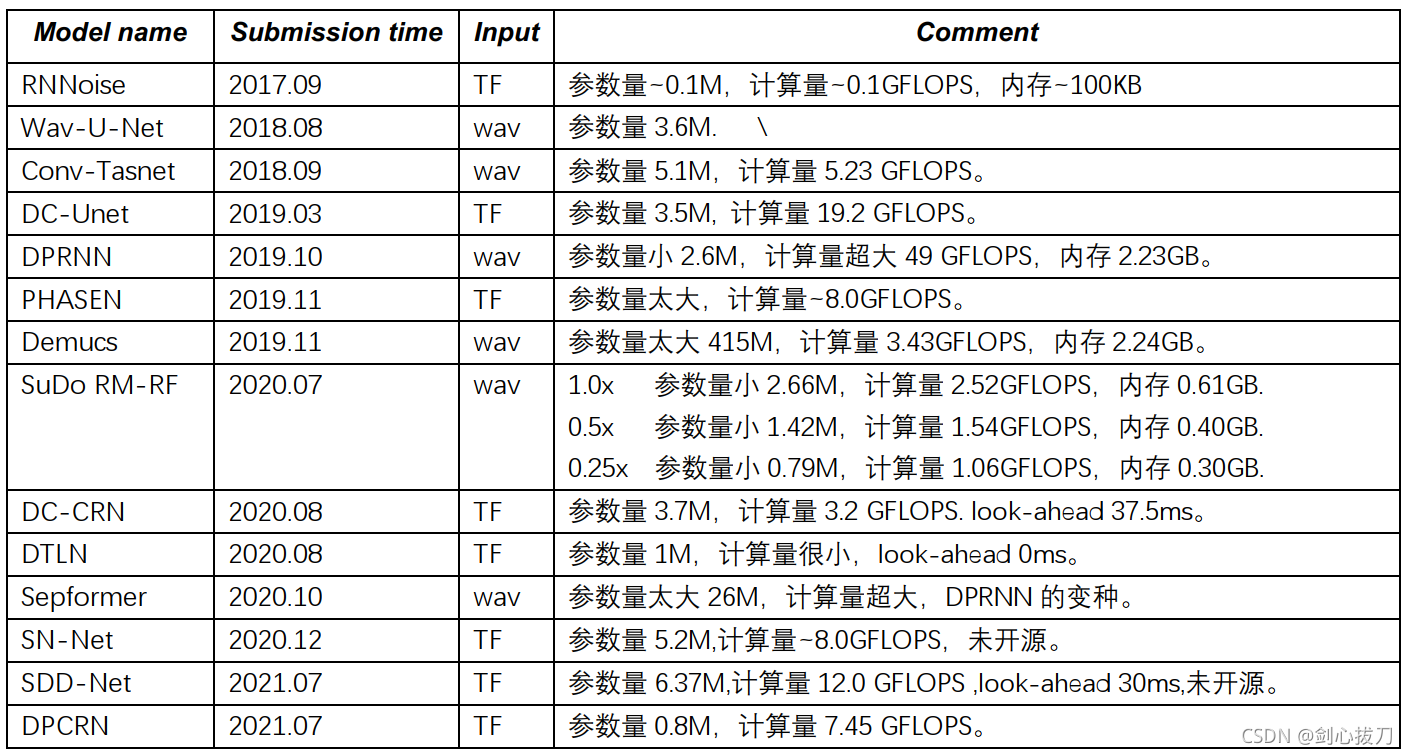
二、模型簡介
Conv-TasNet
Yi Luo, Nima Mesgarani
Conv-TasNet 是Yi Luo在繼2017年提出TasNet之后,又一端到端的語音分離模型,
模型主要由一維空洞卷積的時域卷積網路組成,
1、 模型框圖
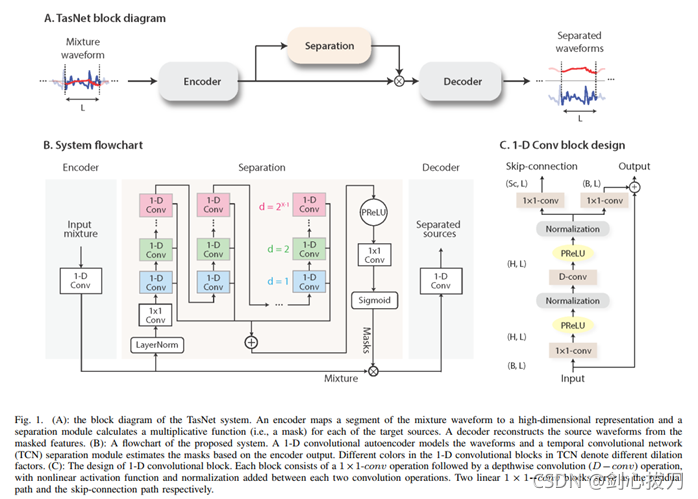
2、 效果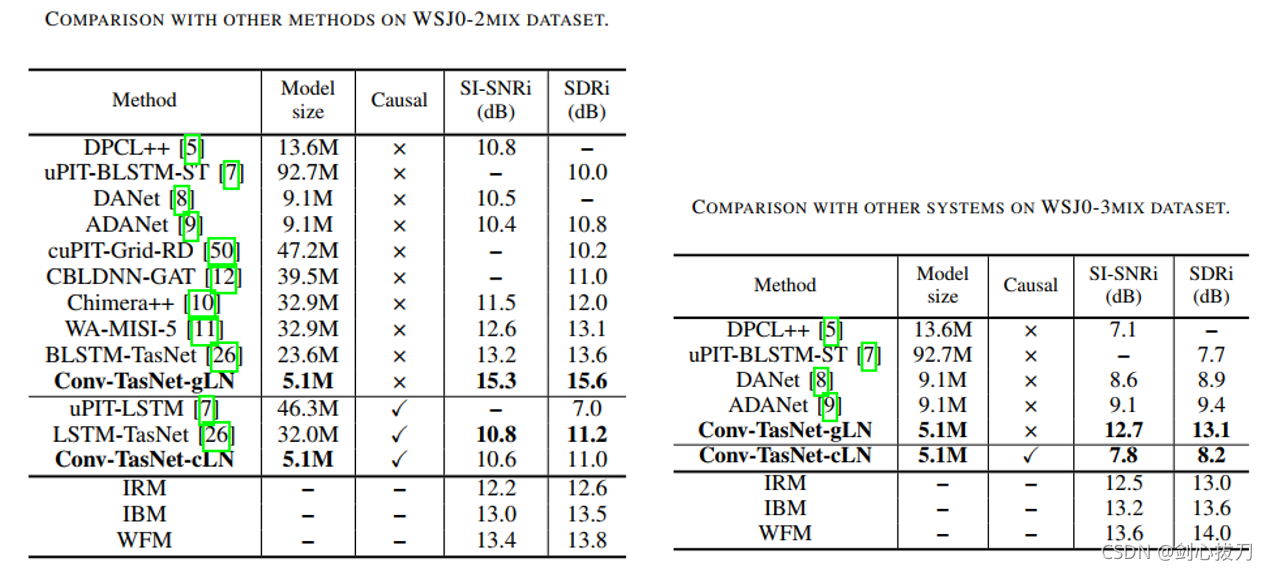 3、代碼
3、代碼
https://github.com/kaituoxu/Conv-TasNet
DC-U-Net
Hyeong-Seok Choi
Department of Transdisciplinary Studies, Seoul National University, Seoul, Korea
DC-Unet結合了深度復數網路和Unet的優點來處理復數值譜圖,利用復數資訊在極坐標系下估計語音的幅值和相位,同時提出了weighted-SDR loss,該方法是通過許多卷積來提取背景關系資訊,從而導致較大的模型和復雜度,
1、 模型框架
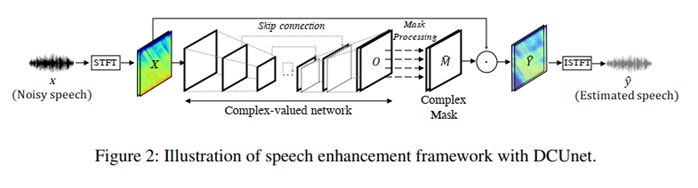
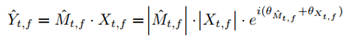
2、weighted-SDR loss

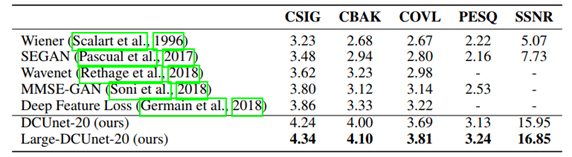
3、效果
4、代碼
https://github.com/chanil1218/DCUnet.pytorch
DPRNN
Yi Luo??, Zhuo Chen?, Takuya Yoshioka?
?Department of Electrical Engineering, Columbia University, NY, USA
?Microsoft, One Microsoft Way, Redmond, WA, USA
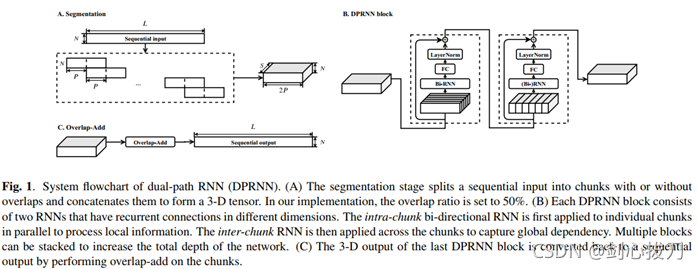
DPRNN將長序列輸入分割為較小的塊,并迭代地應用塊內和塊間RNN,
1、模型框架
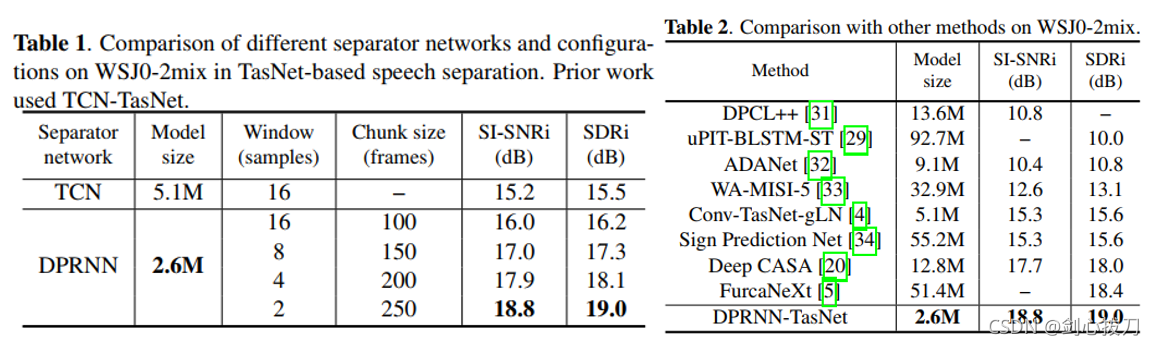
2、效果
3、代碼
https://github.com/ShiZiqiang/dual-path-RNNs-DPRNNs-based-speech-separation
PHASEN
Dacheng Yin1, Chong Luo2, Zhiwei Xiong1, and Wenjun Zeng2
1University of Science and Technology of China
2Microsoft Research Asia
PHASEN可以準確估計信號的幅值和相位資訊,作者設計了一套雙流網路結構(TSB, two-stream block,幅度流和相位流),并且雙流之間有資訊互動,互動發生在TSB模塊結束的部分;設計了FTB(frequency transformation blocks)模塊,用于獲得頻域上的長時間跨度的關系,FTB分布在TSB模塊的開始和結束位置,FTB高效整合全域頻域相關性,尤其是諧波相關性,通過對于 FTB 引數的可視化,我們可以發現 FTB 自發地學到了諧波相關性,,
1、模型框架
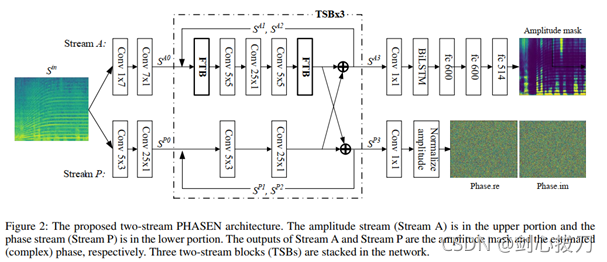
雙流結構由強度流以及相位流構成,其中,強度流主要由卷積操作,頻域變換模塊(FTB)以及雙向 LSTM 組成,而相位流為純卷積網路,強度流的預測結果為幅值掩膜 M,其取值為正的實數,相位流的預測結果是相位譜φ,其取值為復數,由實部和虛部組成,記輸入的時頻表征為 S_in,則輸出 S_out=abs(S_in )?M?φ ,其中,? 代表逐項相乘操作,為了充分利用雙流的資訊,采用 gating 的方式在強度流和相位流之間增加了資訊互動機制,從而讓強度或者相位處理程序中能利用另外一路的資訊作為參考,增加了資訊互動后,把網路的主體劃分為3個 Two Stream Block(TSB),每一個 TSB 的結構相同,在 TSB 的最后,均有一步資訊互動操作,實驗表明,雙向的資訊互動對相位預測至關重要,
在設計強度流的程序中,發現影像處理中常用的小尺寸二維卷積操作無法處理語音信號中的諧波相關性,不同于自然影像,語音信號在轉化為時-頻表征時的相關性不僅有鄰域成分,而且有諧波成分,而這些諧波相關性是一種分布在頻域上的全域相關性,例如:頻率 f_0 傾向于和 2f_0,1/2 f_0,3f_0,3/2 f_0,1/3 f_0,2/3 f_0… 這些諧波相關的頻率同時發生,這些頻率分布在整個頻率軸上,之前的作業中使用的 U-net,空洞卷積等卷積結構都適用于處理鄰域相關性,但是無法高效地感受到這種全域頻域相關性,為此,提出了頻域變換模塊(Frequency Transformation Block, FTB)來處理包括諧波在內的全域頻域相關性,
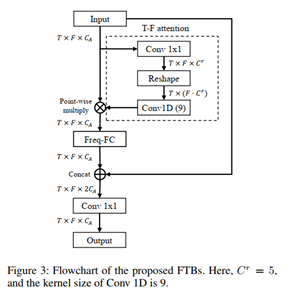
FTB 的結構如上圖所示,簡單來說,它利用注意力(attention)機制來挖掘非鄰域(non-local)相關性,在整體架構中,每一個TSB中強度流的輸入和輸出端各有一個 FTB,確保每一個 TSB 中處理的資訊以及雙流互動的資訊都能關注到諧波相關性,
2、效果
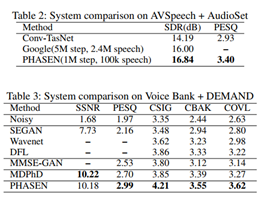
3、代碼
https://github.com/huyanxin/phasen
Demucs
Alexandre Défossez Nicolas Usunier Léon Bottou
Facebook AI Research
Demucs是一個waveform-to-waveform 模型,由U-Net 結構和雙向 LSTM構成,
1、 模型框架
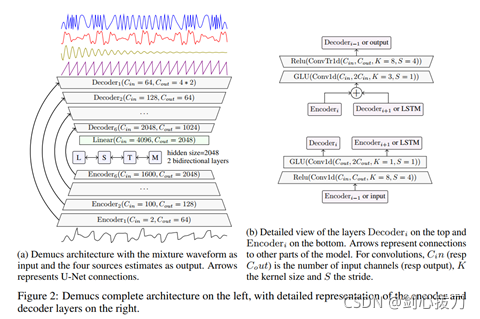
2、效果
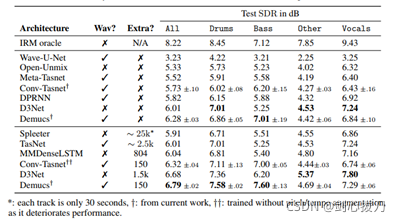
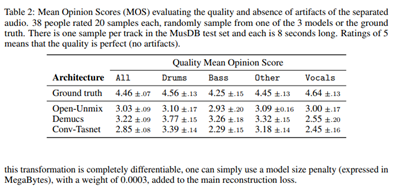
3、代碼
https://github.com/facebookresearch/demucs
SuDoRM-RF
Efthymios Tzinis, Zhepei Wang, Paris Smaragdis
University of Illinois at Urbana-Champaign
Adobe Research
全稱:SUccessive DOwnsampling and Resampling of Multi-Resolution Features多解析度特征的連續下采樣和重采樣,
該模型,a)可以部署在資源有限的設備上,b)訓練速度快,并實作良好的分離性能,c)在增加引數數量時具有良好的擴展性,
適合用于移動設備,能夠在有限的浮點運算次數、記憶體要求和引數數量下獲得高質量的音頻源分離和較小的時延,
1、 模型框架
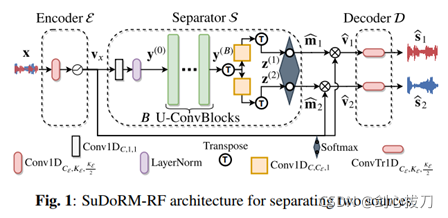
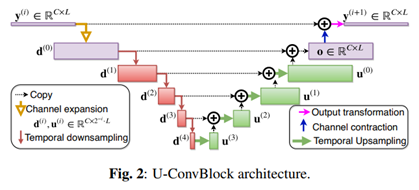
2、效果
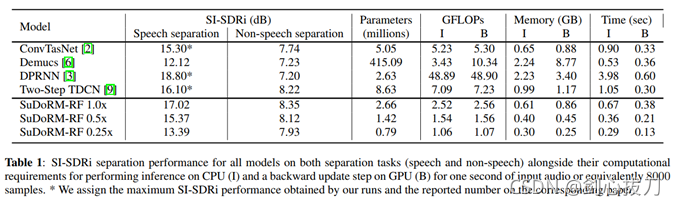
3、代碼
https://github.com/etzinis/sudo_rm_rf
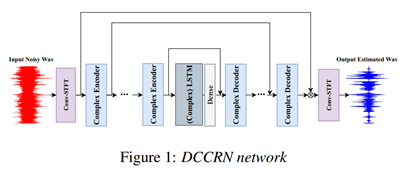
DC-CRN
Yanxin Hu1;?, Yun Liu2;?, Shubo Lv1, Mengtao Xing1, Shimin Zhang1, Yihui Fu1, Jian Wu1, Bihong Zhang2, Lei Xie1
1Audio, Speech and Language Processing Group (ASLP@NPU), School of Computer Science, Northwestern Polytechnical University, Xi’an, China
2AI Interaction Division, Sogou Inc., Beijing, China
DCCRN組合了DCUNET 和CRN的優勢,在相同的模型引數大小情況下,僅用了1/6的DCUNET計算量,就達到了DCUNET的效果,
成就:Interspeech 2020 Deep Noise Suppression (DNS),實時賽道第一名,非實時賽道第二名,
非實時賽道的第一名是Amazon的PoCoNet模型,由于是非實時,就不展開介紹了,
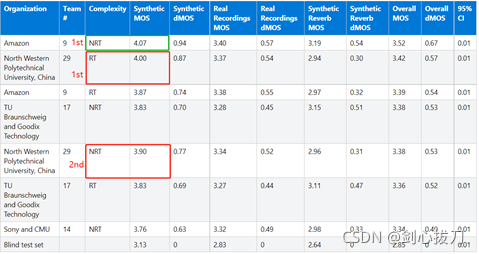
1、 模型框架
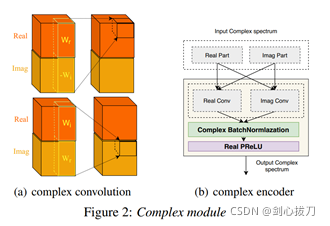
2、效果
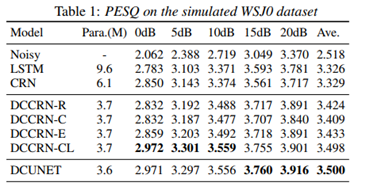
可以看到DCCRN-CL 和DCUNET 引數大小和PESQ指標都很接近,但是DCCRN-CL的計算量是DCUNET的1/6,
3、代碼
https://github.com/huyanxin/DeepComplexCRN
https://github.com/maggie0830/DCCRN
DTLN
Nils L. Westhausen and Bernd T. Meyer
Communication Acoustics & Cluster of Excellence Hearing4all Carl von Ossietzky University, Oldenburg, Germany
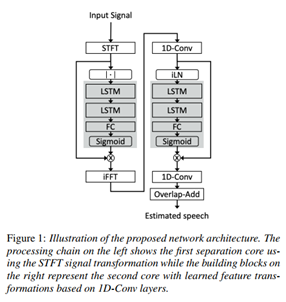
1、 模型框架
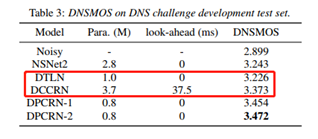
2、效果
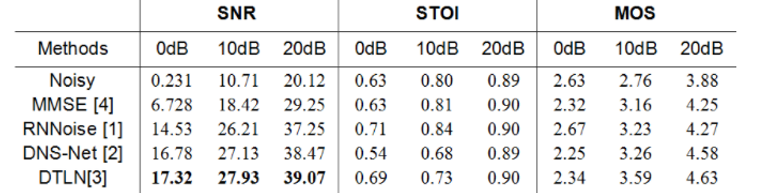
3、代碼
https://github.com/breizhn/DTLN
Sepformer
Cem Subakan1, Mirco Ravanelli1, Samuele Cornell2, Mirko Bronzi1, Jianyuan Zhong3
1Mila-Quebec AI Institute, Canada, 2Universit`a Politecnica delle Marche, Italy 3University of Rochester, USA
是DPRNN的一個變種演算法,主要由multi-head attention 和 feed-forward layers組成,采用了DPRNN引入的雙路徑框架,并將RNN替換為a multiscale pipeline composed of transformers,可以學習短期和長期依賴關系,
1、 模型框架
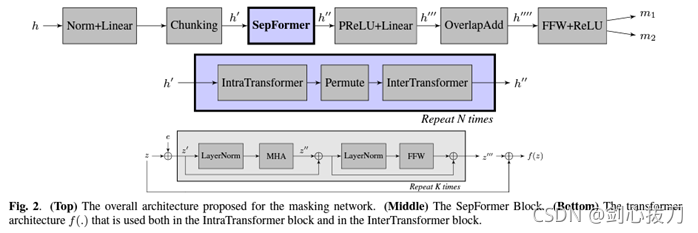
2、效果
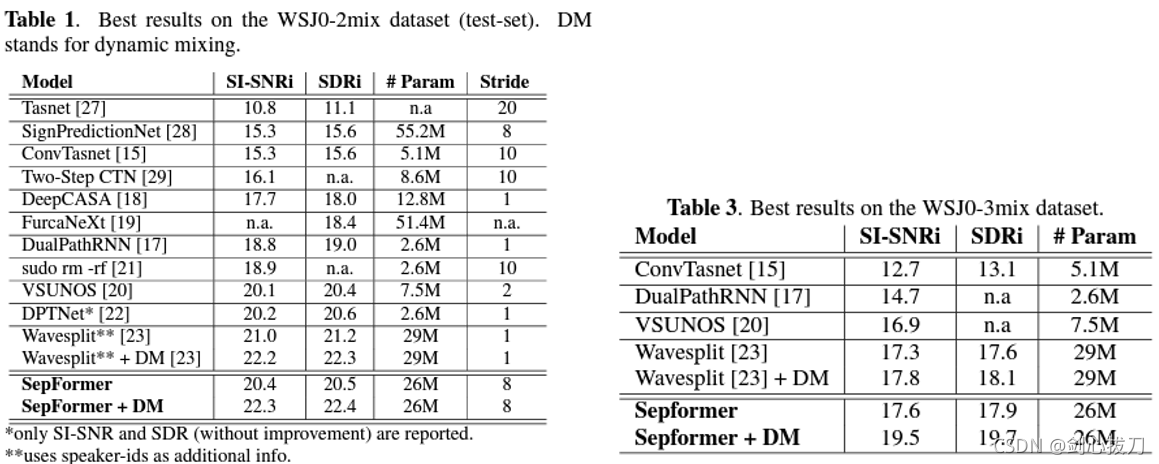
3、代碼
https://github.com/speechbrain/speechbrain/
SDD-Net
Andong Li1;2, Wenzhe Liu1;2, Xiaoxue Luo1;2, Guochen Yu1;3, Chengshi Zheng1;2, Xiaodong Li1;2
1Key Laboratory of Noise and Vibration Research, Institute of Acoustics, Chinese Academy of
Sciences, Beijing, China
2University of Chinese Academy of Sciences, Beijing, China
3Communication University of China, Beijing, China
Deep Noise Suppression Challenge – INTERSPEECH 2021 第一名
1、 模型框架
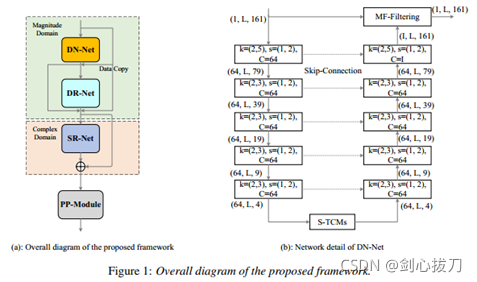
2、效果
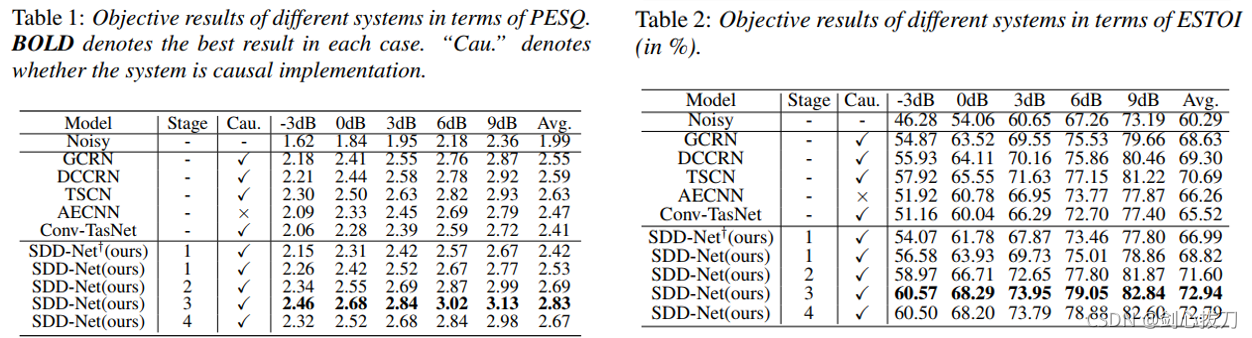
3、未找到開源代碼
DPCRN
Xiaohuai Le1;2;3, Hongsheng Chen1;2;3, Kai Chen1;2;3, Jing Lu1;2;3
1Key Laboratory of Modern Acoustics, Nanjing University, Nanjing 210093, China
2NJU-Horizon Intelligent Audio Lab, Horizon Robotics, Beijing 100094, China
3Nanjing Institute of Advanced Artificial Intelligence, Nanjing 210014, China
Deep Noise Suppression Challenge – INTERSPEECH 2021 第四名
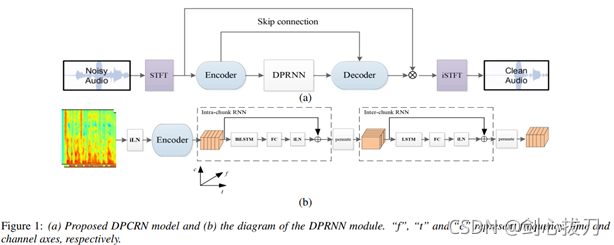
1、 模型框架
2、效果
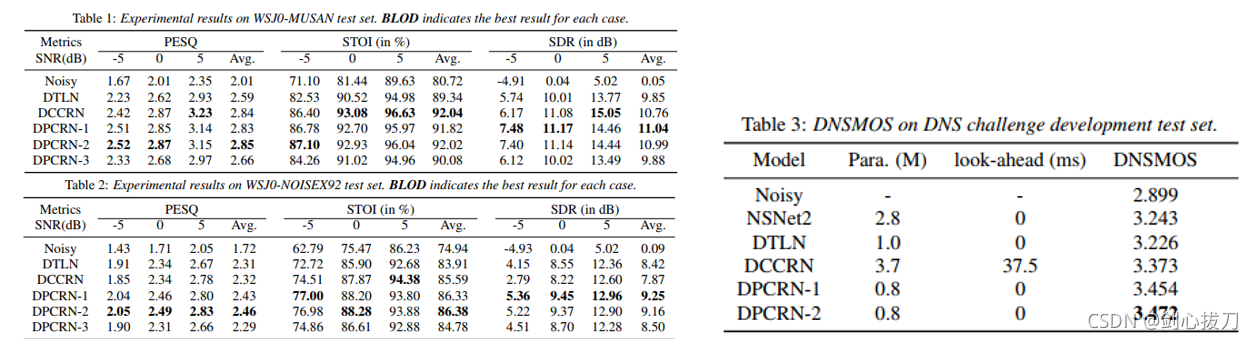
3、代碼
https://github.com/Le-Xiaohuai-speech/DPCRN_DNS3
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/354488.html
標籤:AI