吳恩達《神經網路和深度學習》編程作業—numpy入門,函式向量化實作
- 1 使用numpy構建基本函式
- 1.1 sigmoid function和np.exp()
- 1.2 Sigmoid gradient
- 1.3 重塑陣列
- 1.4 行標準化
- 1.5 廣播和softmax函式
- 2 向量化
- 2.1 向量和矩陣的點積、內積和對應元素逐個相乘運算
- 2.2 實作L1和L2損失函式
做完該作業將掌握的技能:
?? ? \bullet ? 會使用numpy,包括函式呼叫及向量矩陣運算
?? ? \bullet ? 理解Python中“廣播”的概念
?? ? \bullet ? 利用Python代碼實作向量化
1 使用numpy構建基本函式
??Numpy是Python中主要的科學計算包,在本練習中,你將學習一些關鍵的numpy函式,例如np.exp,np.log和np.reshape,
1.1 sigmoid function和np.exp()
??在使用np.exp()之前,你將使用math.exp()實作Sigmoid函式,然后,你將知道為什么np.exp()比math.exp()更可取,
【練習】:構建一個回傳實數
x
x
x 的 sigmoid 的函式,將math.exp(x)用于指數函式,
【提示】: s i g m o i d ( x ) = 1 1 + e ? x sigmoid\left ( x \right )=\frac{1}{1+e^{-x}} sigmoid(x)=1+e?x1?有時也稱為邏輯函式,它是一種非線性函式,即可用于機器學習(邏輯回歸),也能用于深度學習,
【代碼】:
# GRADED FUNCTION: basic_sigmoid
import math
def basic_sigmoid(x):
"""
Compute sigmoid of x.
Arguments:
x -- A scalar
Return:
s -- sigmoid(x)
"""
s = 1 / (1 + math.exp(-x))
return s
result = basic_sigmoid(3)
print("result: " + str(result))
【結果】:
result: 0.9525741268224334
??因為函式的輸入是實數,而深度學習中主要使用的是矩陣和向量,因此很少在深度學習中使用math庫,使用更多的是numpy庫,
??如果對上述代碼稍作修改,把輸入變數 x x x 變成一個向量,如下所示:
【代碼】:
# GRADED FUNCTION: basic_sigmoid
import math
def basic_sigmoid(x):
"""
Compute sigmoid of x.
Arguments:
x -- A scalar
Return:
s -- sigmoid(x)
"""
s = 1 / (1 + math.exp(-x))
return s
# One reason why we use "numpy" instead of "math" in Deep Learning
x = [1, 2, 3]
result = basic_sigmoid(x)
# you will see this give an error when you run it, because x is a vector.
將看到如下報錯資訊:
【結果】:
Traceback (most recent call last):
File "C:\Users\Dell\Desktop\AI_math_ws\2-15\1.py", line 24, in <module>
result = basic_sigmoid(x)
File "C:\Users\Dell\Desktop\AI_math_ws\2-15\1.py", line 17, in basic_sigmoid
s = 1 / (1 + math.exp(-x))
TypeError: bad operand type for unary -: 'list'
??如果
x
=
(
x
1
,
x
2
,
?
?
,
x
n
)
\mathbf{x} = \left ( x_{1},x_{2},\cdots ,x_{n} \right )
x=(x1?,x2?,?,xn?) 是行向量,則 np.exp(x)會將指數函式應用于
x
\mathbf{x}
x 的每個元素, 因此,輸出為:
n
p
.
e
x
p
(
x
)
=
(
e
x
1
,
e
x
2
,
?
?
,
e
x
n
)
np.exp(\mathbf{x})=\left ( e^{x_{1}}, e^{x_{2}}, \cdots , e^{x_{n}}\right )
np.exp(x)=(ex1?,ex2?,?,exn?),
【代碼】:
import numpy as np
# example of np.exp
x = np.array([1, 2, 3])
print(np.exp(x))
# result is (exp(1), exp(2), exp(3))
【結果】:
[ 2.71828183 7.3890561 20.08553692]
??如果 x \mathbf{x} x 是向量,則 s = x + 3 \mathbf{s}=\mathbf{x}+3 s=x+3或 s = 1 x \mathbf{s} = \frac{1}{\mathbf{x}} s=x1? 之類的Python運算將輸出與 x \mathbf{x} x 維度大小相同的向量 s \mathbf{s} s,
【代碼】:
# example of vector operation
x = np.array([1, 2, 3])
print(x + 3)
【結果】:
[4 5 6]
【練習】:使用numpy實作sigmoid函式,
【說明】:
x
x
x 可以是實數,向量或矩陣, 我們在numpy中使用的表示向量、矩陣等的資料結構稱為numpy陣列,
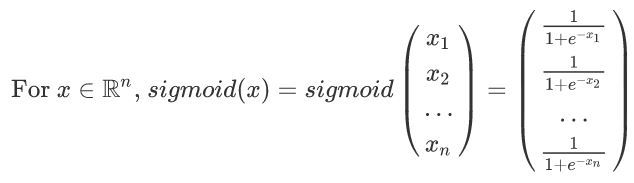
【代碼】:
# GRADED FUNCTION: sigmoid
import numpy as np
def sigmoid(x):
"""
Compute the sigmoid of x
Arguments:
x -- A scalar or numpy array of any size
Return:
s -- sigmoid(x)
"""
s = 1 / (1 + np.exp(-x))
return s
x = np.array([1, 2, 3])
result = sigmoid(x)
print("result: " + str(result))
【結果】:
result: [0.73105858 0.88079708 0.95257413]
1.2 Sigmoid gradient
??正如你在教程中所看到的,我們需要計算梯度來使用反向傳播優化損失函式, 讓我們開始撰寫第一個梯度函式吧,
【練習】:創建函式sigmoid_grad()計算sigmoid函式相對于其輸入
x
x
x 的梯度, 公式為:
s
i
g
m
o
i
d
d
e
r
i
v
a
t
i
v
e
(
x
)
=
σ
′
(
x
)
=
σ
(
x
)
(
1
?
σ
(
x
)
)
sigmoid_derivative(x) = \sigma ^{'}(x) = \sigma (x)(1-\sigma (x))
sigmoidd?erivative(x)=σ′(x)=σ(x)(1?σ(x))
【提示】:我們通常分兩步撰寫此函式代碼:
??(1)將
s
s
s 設為
x
x
x 的sigmoid
??(2)計算
σ
′
(
x
)
=
s
(
1
?
s
)
\sigma ^{'}(x) =s(1-s)
σ′(x)=s(1?s)
【代碼】:
# GRADED FUNCTION: sigmoid
import numpy as np
def sigmoid(x):
"""
Compute the sigmoid of x
Arguments:
x -- A scalar or numpy array of any size
Return:
s -- sigmoid(x)
"""
s = 1 / (1 + np.exp(-x))
return s
# GRADED FUNCTION: sigmoid_derivative
def sigmoid_derivative(x):
"""
Compute the gradient (also called the slope or derivative) of the sigmoid function with respect to its input x.
You can store the output of the sigmoid function into variables and then use it to calculate the gradient.
Arguments:
x -- A scalar or numpy array
Return:
ds -- Your computed gradient.
"""
s = sigmoid(x)
ds = s * (1 - s)
return ds
x = np.array([1, 2, 3])
print("sigmoid_derivative(x) = " + str(sigmoid_derivative(x)))
【結果】:
sigmoid_derivative(x) = [0.19661193 0.10499359 0.04517666]
1.3 重塑陣列
??深度學習中兩個常用的numpy函式是np.shape和np.reshape(),
??
?
\bullet
? X.shape用于獲取矩陣/向量X的shape(維度)
??
?
\bullet
? X.reshape(…)用于將X重塑為其他尺寸
??例如,在計算機科學中,影像由shape為(length, height, depth = 3)的3D陣串列示,但是,當你讀取影像作為演算法的輸入時,會將其轉換為維度為(length*height*3, 1)的向量,換句話說,將3D陣列“展開”或重塑為1D向量,
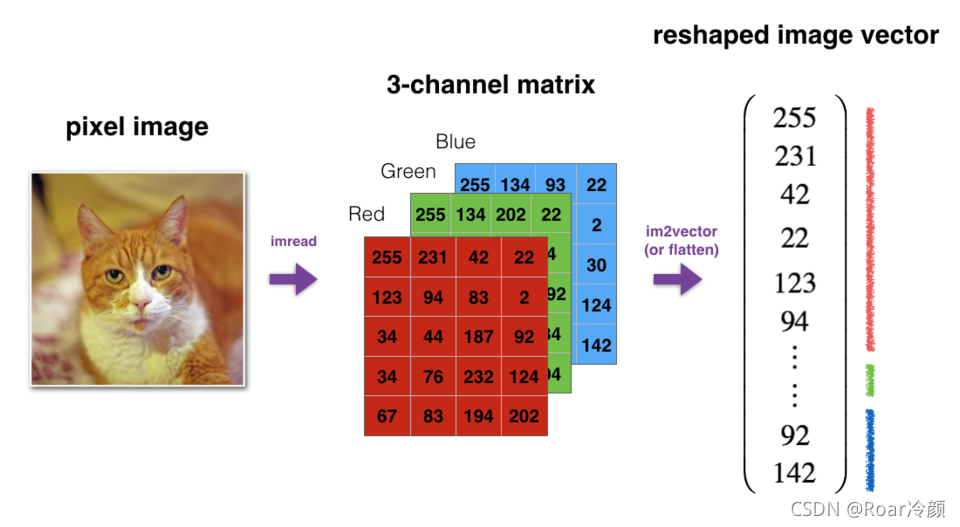
【練習】:實作image2vector(),該輸入采用維度為(length, height, 3)的輸入,并回傳維度為(length*height*3, 1)的向量,
【說明】:例如,如果你想將形為 ( a , b , c ) (a,b,c) (a,b,c)的陣列 v v v 重塑為維度為 ( a ? b , 3 ) (a*b, 3) (a?b,3)的向量,則可以執行以下操作:
v = v.reshape((v.shape[0]*v.shape[1], v.shape[2])) # v.shape[0] = a ; v.shape[1] = b ; v.shape[2] = c
??請不要將影像的尺寸硬編碼為常數,而是通過image.shape[0]等來查找所需的數量,
【代碼】:
# GRADED FUNCTION: image2vector
import numpy as np
def image2vector(image):
"""
Argument:
image -- a numpy array of shape (length, height, depth)
Returns:
v -- a vector of shape (length*height*depth, 1)
"""
v = image.reshape(image.shape[0] * image.shape[1] * image.shape[2], 1)
return v
image = np.array([[[ 0.67826139, 0.29380381],
[ 0.90714982, 0.52835647],
[ 0.4215251 , 0.45017551]],
[[ 0.92814219, 0.96677647],
[ 0.85304703, 0.52351845],
[ 0.19981397, 0.27417313]],
[[ 0.60659855, 0.00533165],
[ 0.10820313, 0.49978937],
[ 0.34144279, 0.94630077]]])
print("image2vector(image) = " + str(image2vector(image)))
【結果】:
image2vector(image) = [[0.67826139]
[0.29380381]
[0.90714982]
[0.52835647]
[0.4215251 ]
[0.45017551]
[0.92814219]
[0.96677647]
[0.85304703]
[0.52351845]
[0.19981397]
[0.27417313]
[0.60659855]
[0.00533165]
[0.10820313]
[0.49978937]
[0.34144279]
[0.94630077]]
1.4 行標準化
??我們在機器學習和深度學習中使用的另一種常見技術是對資料進行標準化, 由于歸一化后梯度下降的收斂速度更快,通常會表現出更好的效果, 通過歸一化,也就是將 x x x 更改為 x ∥ x ∥ \frac{x}{\left \| x \right \|} ∥x∥x?(將 x x x 的每個行向量除以其范數),
??例如:
x
=
[
0
3
4
2
6
4
]
x = \begin{bmatrix} 0 & 3 & 4\\ 2 & 6 & 4 \end{bmatrix}
x=[02?36?44?]
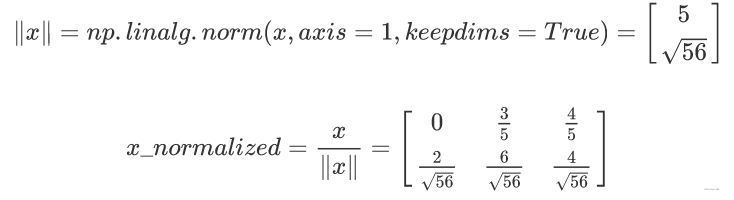
【練習】:執行normalizeRows()來標準化矩陣的行, 將此函式應用于輸入矩陣
x
x
x 之后,
x
x
x 的每一行應為單位長度(即長度為1)向量,
【代碼】:
# GRADED FUNCTION: normalizeRows
import numpy as np
def normalizeRows(x):
"""
Implement a function that normalizes each row of the matrix x (to have unit length).
Argument:
x -- A numpy matrix of shape (n, m)
Returns:
x -- The normalized (by row) numpy matrix. You are allowed to modify x.
"""
# Compute x_norm as the norm 2 of x. Use np.linalg.norm(..., ord = 2, axis = ..., keepdims = True)
x_norm = np.linalg.norm(x, axis=1, keepdims=True)
# Divide x by its norm.
x = x / x_norm
return x
x = np.array([
[0, 3, 4],
[1, 6, 4]])
print("normalizeRows(x) = " + str(normalizeRows(x)))
【結果】:
normalizeRows(x) = [[0. 0.6 0.8 ]
[0.13736056 0.82416338 0.54944226]]
【注意】:在normalizeRows(x)中,你可以嘗試print查看x_norm和
x
x
x 的維度,然后重新運行練習, 你會發現它們具有不同的維度, 鑒于x_norm采用
x
x
x 的每一行的范數,這是正常的,因此,x_norm與
x
x
x 有相同的行數,但只有1列, 那么,當你將
x
x
x 除以x_norm時,它是如何作業的? 這就是所謂的廣播broadcasting,我們現在將討論它!
1.5 廣播和softmax函式
??在numpy中要理解的一個非常重要的概念是“廣播”, 這對于在不同形狀的陣列之間執行數學運算非常有用,有關廣播的完整詳細資訊,你可以閱讀官方的broadcasting documentation.
【練習】:使用numpy實作softmax函式, 你可以將softmax理解為演算法需要對兩個或多個類進行分類時使用的標準化函式,
【說明】:

【代碼】:
# GRADED FUNCTION: softmax
import numpy as np
def softmax(x):
"""Calculates the softmax for each row of the input x.
Your code should work for a row vector and also for matrices of shape (n, m).
Argument:
x -- A numpy matrix of shape (n,m)
Returns:
s -- A numpy matrix equal to the softmax of x, of shape (n,m)
"""
# Apply exp() element-wise to x. Use np.exp(...).
x_exp = np.exp(x)
# Create a vector x_sum that sums each row of x_exp. Use np.sum(..., axis = 1, keepdims = True).
x_sum = np.sum(x_exp, axis=1, keepdims=True)
# Compute softmax(x) by dividing x_exp by x_sum. It should automatically use numpy broadcasting.
s = x_exp / x_sum
return s
x = np.array([
[9, 2, 5, 0, 0],
[7, 5, 0, 0, 0]])
print("softmax(x) = " + str(softmax(x)))
【結果】:
softmax(x) = [[9.80897665e-01 8.94462891e-04 1.79657674e-02 1.21052389e-04
1.21052389e-04]
[8.78679856e-01 1.18916387e-01 8.01252314e-04 8.01252314e-04
8.01252314e-04]]
【注意】:如果你在上方輸出 x_exp,x_sum和s的維度并重新運行練習單元,則會看到x_sum的緯度為
(
2
,
1
)
(2,1)
(2,1),而x_exp和s的維度為
(
2
,
5
)
(2,5)
(2,5), x_exp/x_sum可以使用python廣播,
2 向量化
2.1 向量和矩陣的點積、內積和對應元素逐個相乘運算
??在深度學習中,通常需要處理非常大的資料集, 因此,非計算最佳函式可能會成為演算法中的巨大瓶頸,并可能使模型運行一段時間, 為了確保代碼的高效計算,我們將使用向量化, 在這里,需要重點區分點積(dot product)、外積(outer product)和對應元素逐個相乘(element-wise),
??首先,我們使用for回圈來實作向量和向量以及矩陣和向量的上述三種運算,
【代碼】:
import numpy as np
import time
x1 = [9, 2, 5, 0, 0, 7, 5, 0, 0, 0, 9, 2, 5, 0, 0]
x2 = [9, 2, 2, 9, 0, 9, 2, 5, 0, 0, 9, 2, 5, 0, 0]
### CLASSIC DOT PRODUCT OF VECTORS IMPLEMENTATION ###
tic = time.process_time()
dot = 0
for i in range(len(x1)):
dot += x1[i]*x2[i]
toc = time.process_time()
print("dot = " + str(dot) + "\n ----- Computation time = " + str(1000*(toc - tic)) + "ms")
### CLASSIC OUTER PRODUCT IMPLEMENTATION ###
tic = time.process_time()
outer = np.zeros((len(x1), len(x2))) # we create a len(x1)*len(x2) matrix with only zeros
for i in range(len(x1)):
for j in range(len(x2)):
outer[i, j] = x1[i]*x2[j]
toc = time.process_time()
print("outer = " + str(outer) + "\n ----- Computation time = " + str(1000*(toc - tic)) + "ms")
### CLASSIC ELEMENT-WISE IMPLEMENTATION ###
tic = time.process_time()
mul = np.zeros(len(x1))
for i in range(len(x1)):
mul[i] = x1[i]*x2[i]
toc = time.process_time()
print("elementwise multiplication = " + str(mul) + "\n ----- Computation time = " + str(1000*(toc - tic)) + "ms")
### CLASSIC GENERAL DOT PRODUCT IMPLEMENTATION ###
W = np.random.rand(3, len(x1)) # Random 3*len(x1) numpy array
tic = time.process_time()
gdot = np.zeros(W.shape[0])
for i in range(W.shape[0]):
for j in range(len(x1)):
gdot[i] += W[i, j]*x1[j]
toc = time.process_time()
print("gdot = " + str(gdot) + "\n ----- Computation time = " + str(1000*(toc - tic)) + "ms")
【結果】:
dot = 278
----- Computation time = 0.08447300000002933ms
outer = [[81. 18. 18. 81. 0. 81. 18. 45. 0. 0. 81. 18. 45. 0. 0.]
[18. 4. 4. 18. 0. 18. 4. 10. 0. 0. 18. 4. 10. 0. 0.]
[45. 10. 10. 45. 0. 45. 10. 25. 0. 0. 45. 10. 25. 0. 0.]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[63. 14. 14. 63. 0. 63. 14. 35. 0. 0. 63. 14. 35. 0. 0.]
[45. 10. 10. 45. 0. 45. 10. 25. 0. 0. 45. 10. 25. 0. 0.]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[81. 18. 18. 81. 0. 81. 18. 45. 0. 0. 81. 18. 45. 0. 0.]
[18. 4. 4. 18. 0. 18. 4. 10. 0. 0. 18. 4. 10. 0. 0.]
[45. 10. 10. 45. 0. 45. 10. 25. 0. 0. 45. 10. 25. 0. 0.]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]]
----- Computation time = 0.22404599999992225ms
elementwise multiplication = [81. 4. 10. 0. 0. 63. 10. 0. 0. 0. 81. 4. 25. 0. 0.]
----- Computation time = 0.10582699999994727ms
gdot = [26.19713459 12.20793127 23.40980652]
----- Computation time = 0.15482099999997168ms
??然后,我們使用向量化來實作上述運算,
【代碼】:
import numpy as np
import time
x1 = [9, 2, 5, 0, 0, 7, 5, 0, 0, 0, 9, 2, 5, 0, 0]
x2 = [9, 2, 2, 9, 0, 9, 2, 5, 0, 0, 9, 2, 5, 0, 0]
### VECTORIZED DOT PRODUCT OF VECTORS ###
tic = time.process_time()
dot = np.dot(x1, x2)
toc = time.process_time()
print("dot = " + str(dot) + "\n ----- Computation time = " + str(1000*(toc - tic)) + "ms")
### VECTORIZED OUTER PRODUCT ###
tic = time.process_time()
outer = np.outer(x1, x2)
toc = time.process_time()
print("outer = " + str(outer) + "\n ----- Computation time = " + str(1000*(toc - tic)) + "ms")
### VECTORIZED ELEMENTWISE MULTIPLICATION ###
tic = time.process_time()
mul = np.multiply(x1, x2)
toc = time.process_time()
print("elementwise multiplication = " + str(mul) + "\n ----- Computation time = " + str(1000*(toc - tic)) + "ms")
### VECTORIZED GENERAL DOT PRODUCT ###
W = np.random.rand(3, len(x1))
tic = time.process_time()
dot = np.dot(W, x1)
toc = time.process_time()
print("gdot = " + str(dot) + "\n ----- Computation time = " + str(1000*(toc - tic)) + "ms")
【結果】:
dot = 278
----- Computation time = 0.0ms
outer = [[81 18 18 81 0 81 18 45 0 0 81 18 45 0 0]
[18 4 4 18 0 18 4 10 0 0 18 4 10 0 0]
[45 10 10 45 0 45 10 25 0 0 45 10 25 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[63 14 14 63 0 63 14 35 0 0 63 14 35 0 0]
[45 10 10 45 0 45 10 25 0 0 45 10 25 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[81 18 18 81 0 81 18 45 0 0 81 18 45 0 0]
[18 4 4 18 0 18 4 10 0 0 18 4 10 0 0]
[45 10 10 45 0 45 10 25 0 0 45 10 25 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]]
----- Computation time = 0.0ms
elementwise multiplication = [81 4 10 0 0 63 10 0 0 0 81 4 25 0 0]
----- Computation time = 0.0ms
gdot = [21.71177187 29.73904226 17.07432149]
----- Computation time = 0.0ms
??你可能注意到了,向量化的實作更加簡潔高效,對于更大的向量/矩陣,運行時間的差異變得更大,
2.2 實作L1和L2損失函式
【練習】:實作L1損失函式的Numpy向量化版本, 我們會發現函式abs(x)(
x
x
x 的絕對值)很有用,
【說明】:損失函式用于評估模型的性能, 損失越大,預測值
y
^
\hat{y}
y^? 與真實值
y
y
y 之間的差異也就越大,在深度學習中,我們使用諸如梯度下降演算法(Gradient Descent)之類的優化演算法來訓練模型并最大程度地降低成本,L1損失函式定義為:
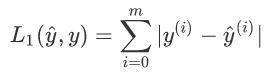
【代碼】:
# GRADED FUNCTION: L1
import numpy as np
def L1(yhat, y):
"""
Arguments:
yhat -- vector of size m (predicted labels)
y -- vector of size m (true labels)
Returns:
loss -- the value of the L1 loss function defined above
"""
loss = np.sum(np.abs(y - yhat))
return loss
yhat = np.array([.9, 0.2, 0.1, .4, .9])
y = np.array([1, 0, 0, 1, 1])
print("L1 = " + str(L1(yhat, y)))
【結果】:
L1 = 1.1
【練習】:實作L2損失函式的Numpy向量化版本,有好幾種方法可以實作L2損失函式,但是還是np.dot()函式更好用,L2損失函式定義為:
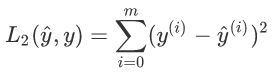
【代碼】:
# GRADED FUNCTION: L2
import numpy as np
def L2(yhat, y):
"""
Arguments:
yhat -- vector of size m (predicted labels)
y -- vector of size m (true labels)
Returns:
loss -- the value of the L2 loss function defined above
"""
loss = np.dot((y - yhat), (y - yhat).T)
return loss
yhat = np.array([.9, 0.2, 0.1, .4, .9])
y = np.array([1, 0, 0, 1, 1])
print("L2 = " + str(L2(yhat, y)))
【結果】:
L2 = 0.43
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/354494.html
標籤:AI